









今天分享一个用Stable Diffusion将图片中不需要的物体去掉,然后将需要的内容添加到图片上的小教程。现在不管是在朋友圈还是在自媒体平台上,我们经常能够看到这样一句话“谁能帮我把什么什么P掉”,目前现在大家常用的方法就是用PS或其他的图片处理工具将图片中不需要的物体去掉,但这方法需要耗费大量时间,且效果可能不尽如人意。
用Stable Diffusion来处理这样的事会简单很多,它可以在图片中精确地去除不需要的物体也可以很自然的添加我们想要添加的物体,同时保持图像的真实和自然。

1 前期准备
-
本文需要用到ControlNet插件,如未安装的需要去安装一下,然后下载相关的模型。(安装方法就不一一介绍啦,如果有任何疑问或问题可以在公众号后台私聊我)
-
Inpaint Anything,用于给图片添加需要的物体,如未安装的需要去安装一下。
安装方法就不介绍啦,如果需要看安装方法,可以看前面发布的一篇文章:
Stable Diffusion|Ai赋能电商 Inpaint Anything
- 准备一张需要处理的图片。

2 去除物体
- 打开Stable Diffusion,“启用”ControlNet并且勾选“完美像素模式”,然后上传图片。
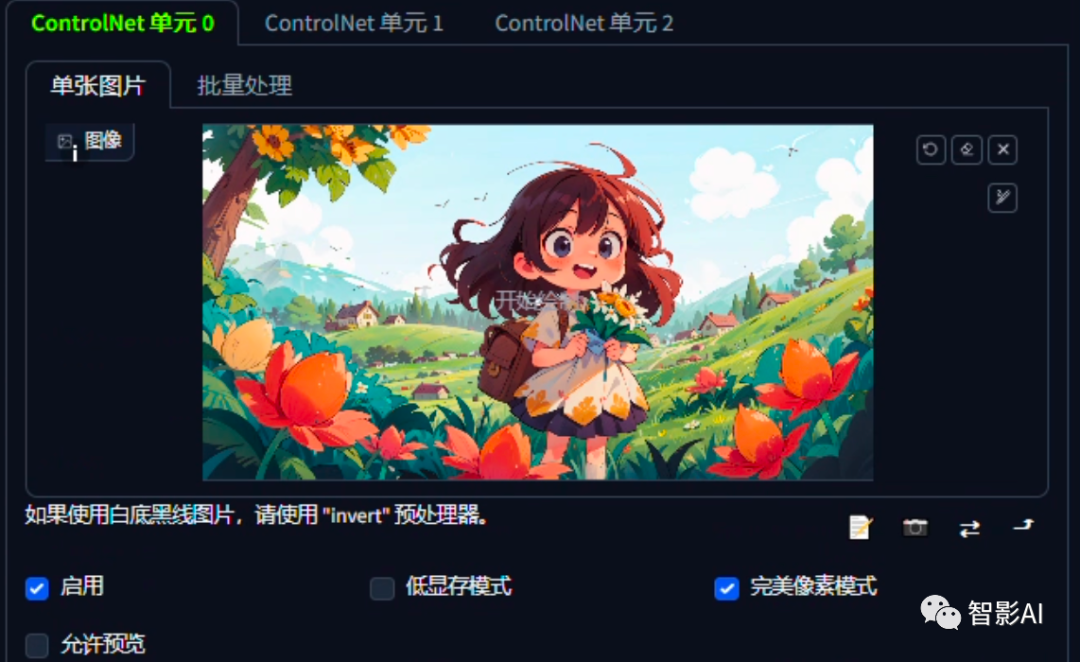
- 在控制类型中选择“局部重绘”,预处理器选择“inpaint_global_harmoniou”,然后模型选择“control_v11p_sd15_inpaint”。
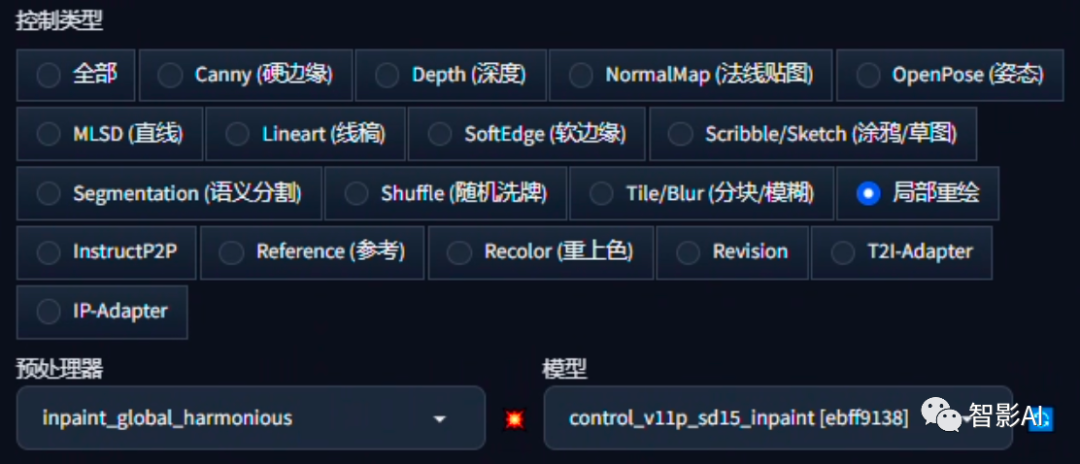
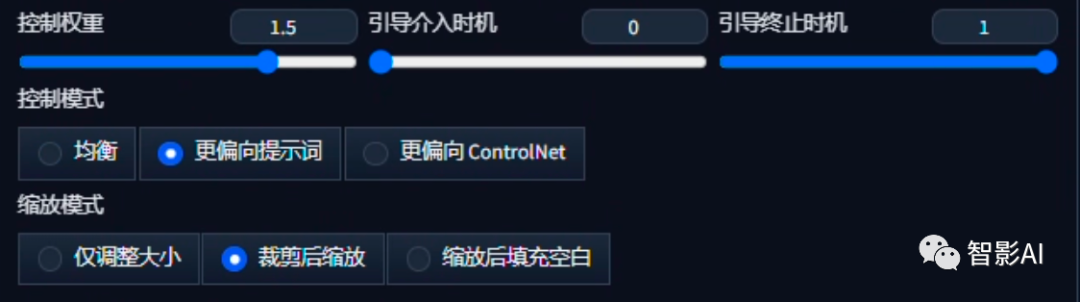
- 可以适当地增加控制权重的值,也可以根据输出的结果来决定是否需要进行调整。在控制模式方面,可以选择“更偏向提示词”选项,这样能够更好地控制输出的结果。
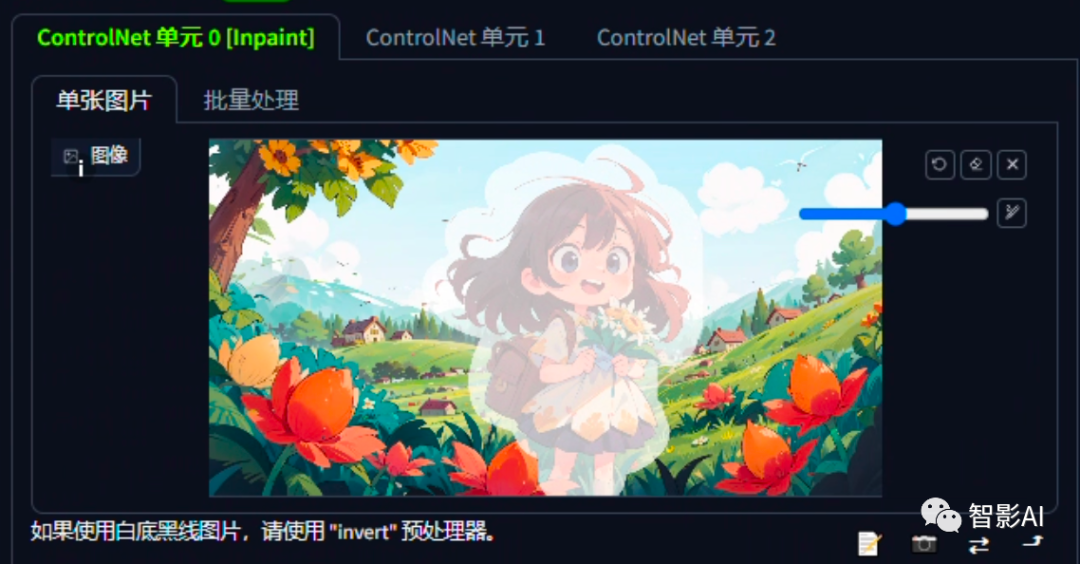
- 在上方图片中,涂抹需要去除的物体。
- 设置好ControlNet之后,选择一个跟图片相关的大模型,写实图片就选择写实大模型,卡通图片就选卡通模型。提示词这里可以描述一下图片的内容(不要写需要去除物体的提示词)。
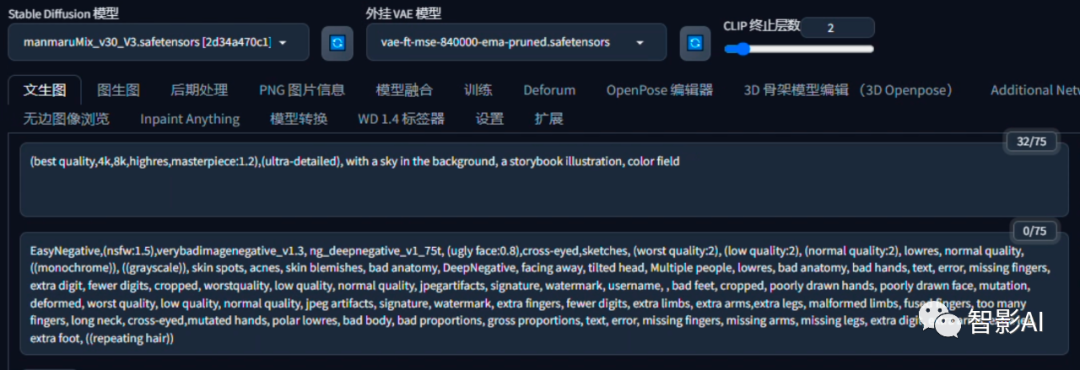
如果不知道怎么写提示词,可以点击图生图,然后上传一下那张图片,点击“CLIP反推”反推一下提示词,然后将需要去除物体的提示词去掉即可。
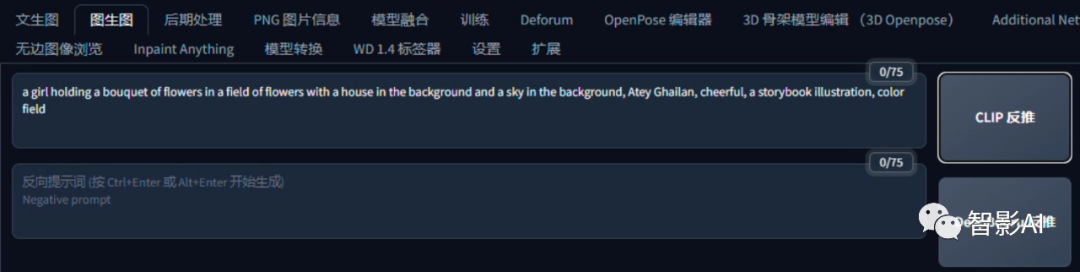
- 设置生成参数,尺寸建议跟上传的图片保持统一比例,其他的可以根据自己的需求调整。
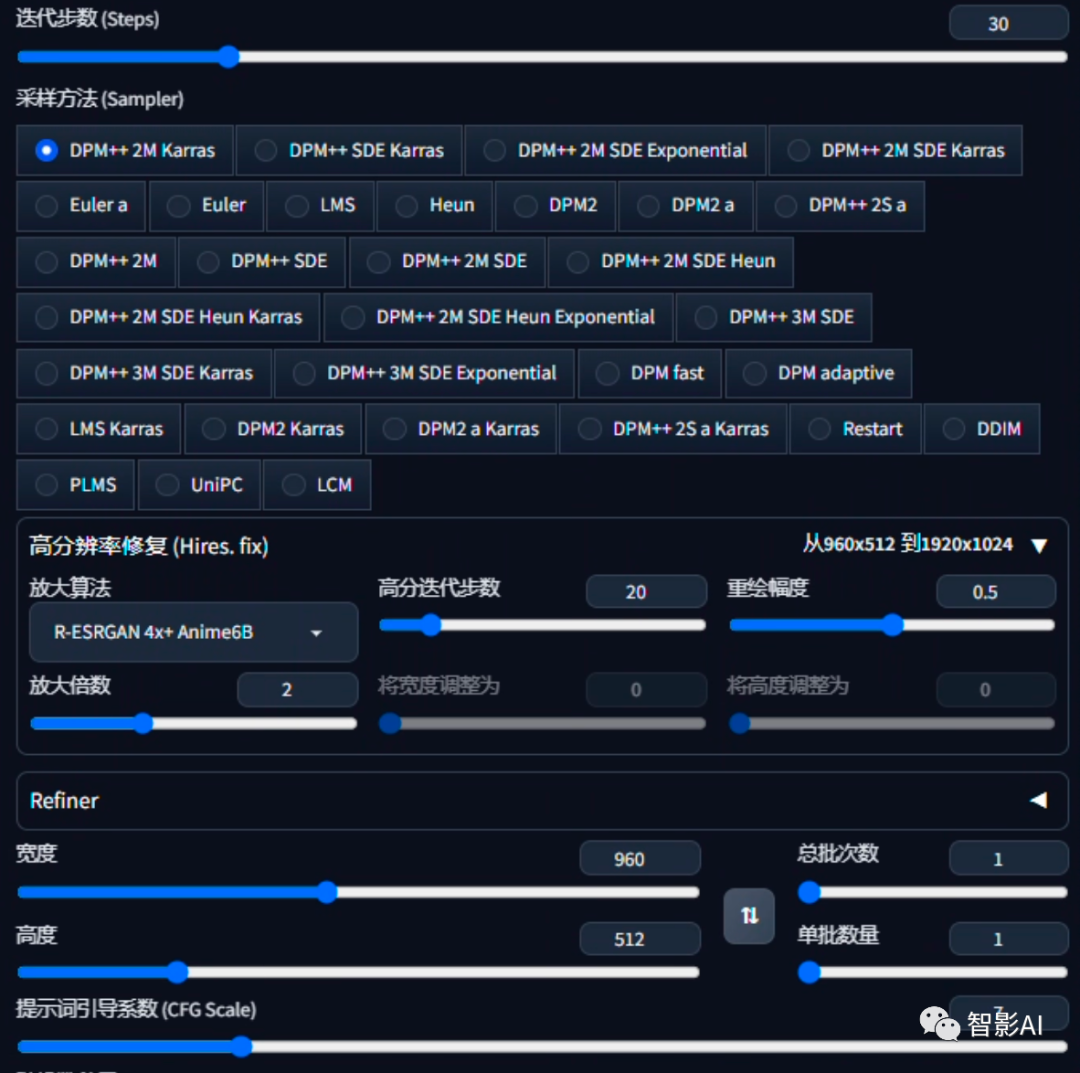
- 以上参数设置完成之后,点击“生成”即可。

我们可以看到图片中的人物很好的去除掉了,且整体画面看起来非常自然。
3 写实照片
接下来我们试一下写实照片。

- ControlNet设置保持一样即可,只需要将图片替换一下,然后将需要去掉的内容涂抹一下即可。
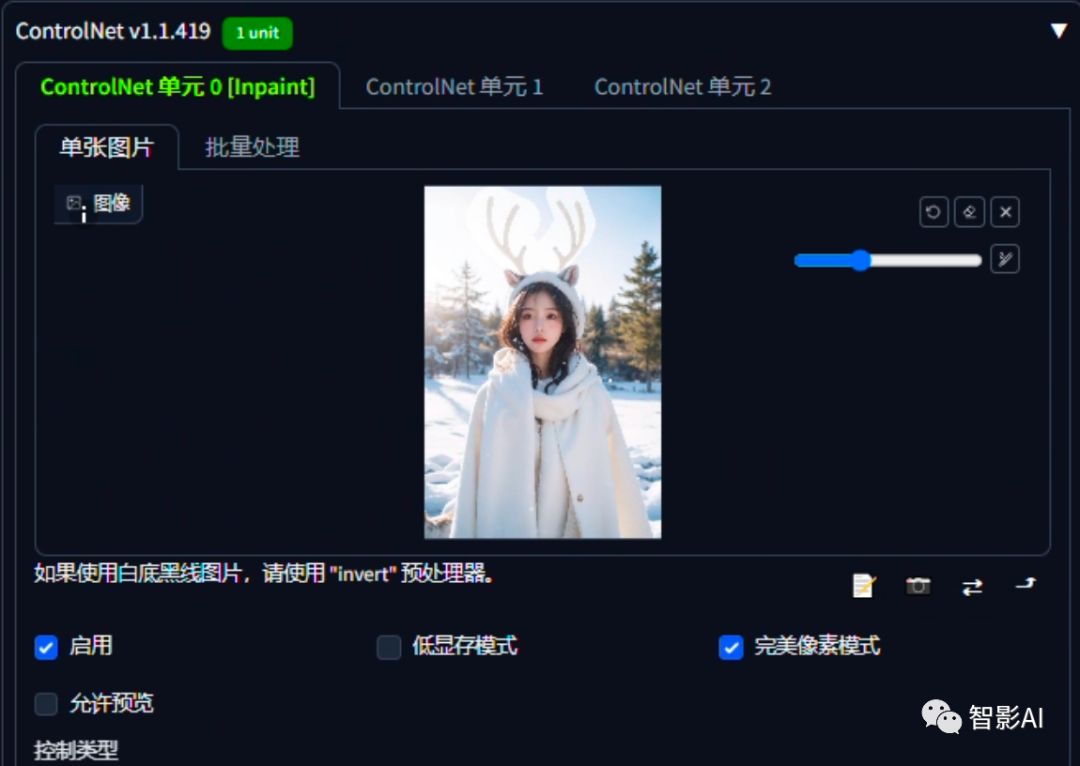
- 模型换成写实模型即可,然后提示词跟刚刚一样,不会写的可以在图生图反推一下,然后将需要去除的提示词去掉即可。
- 设置生成参数,尺寸建议跟上传的图片保持统一比例,其他的可以根据自己的需求调整。
- 以上参数设置完成之后,点击“生成”即可。

我们可以看到,鹿角很自然的去除掉了,且整体画面看起来也自然。
4 给图片添加物体
将图片中的内容去除掉了之后,想添加一些其他的物体,可以接着往下看(需要用到Inpaint Anything插件)。

这里将不会对Inpaint Anything插件做详细的介绍,如需了解,可以看前面发的一篇内容:Stable Diffusion|Ai赋能电商 Inpaint Anything
- 下载刚刚生成的图片,然后使用图片处理工具将所需的物体添加到图片上(例如皇冠)。接下来,打开Stable Diffusion并点击“Inpaint Anything”,上传刚刚准备好的图片,然后在“Segment Anything模型ID”选择一个模型(如果没下载模型的,需要点一下右侧的“下载模型”)并点击“运行 Segment Anything”。
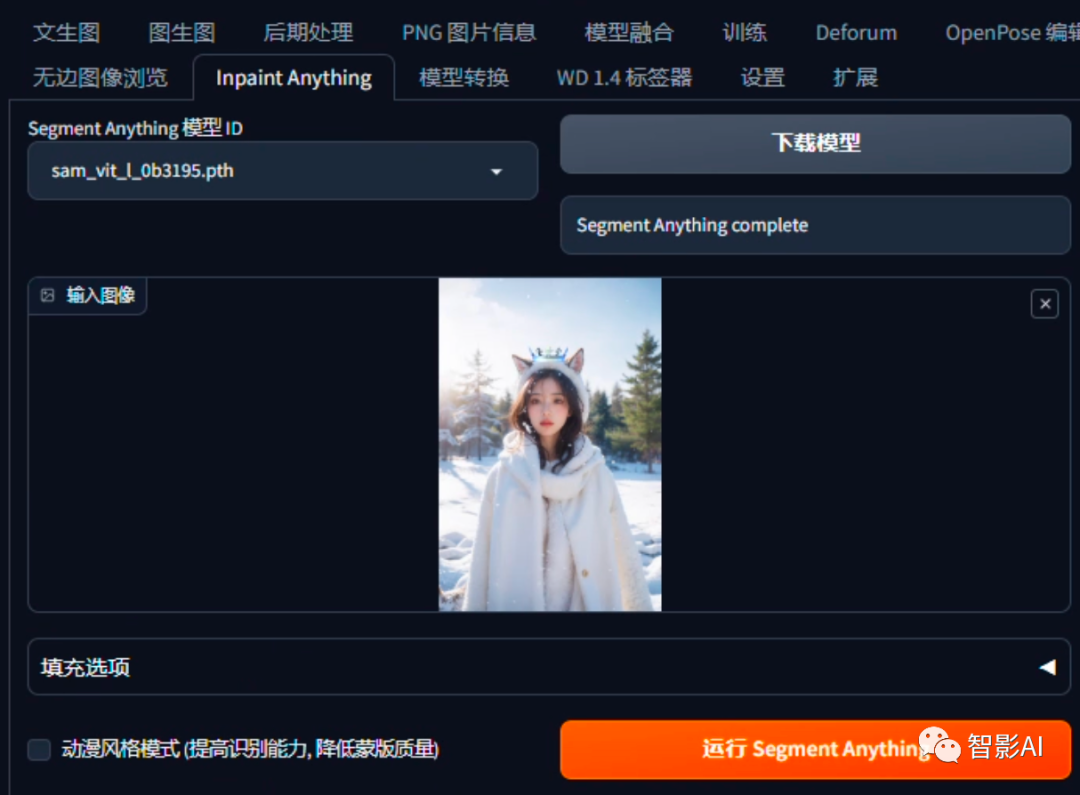
- 在右侧点一下需要融合的物体(例如皇冠),然后点击“创建蒙版”。
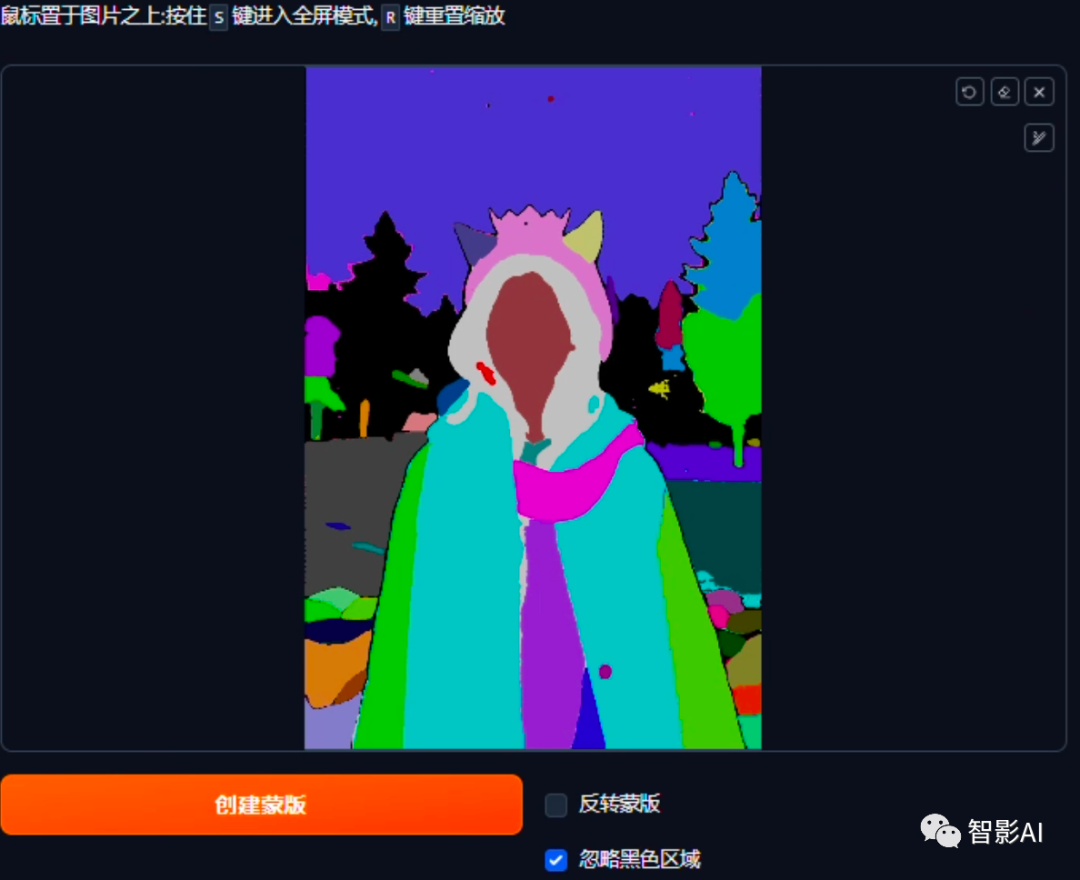
- 蒙版创建好之后,将物体涂抹一下,只需要留下衔接处即可,然后点击“根据草图修剪蒙版”。
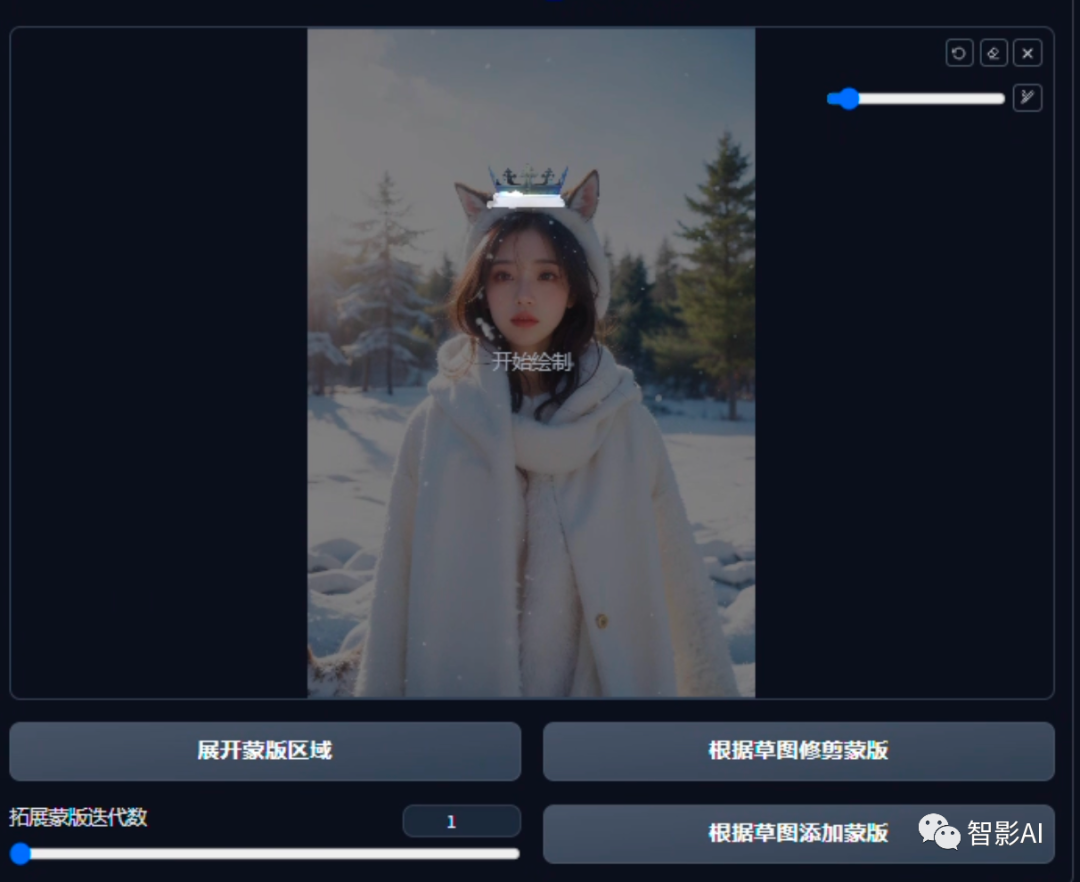
- 点击左侧的“仅蒙版”,在点击“获取蒙版”,然后点击下面的“发送到图生图重绘”按钮,将图片发送到图生图。
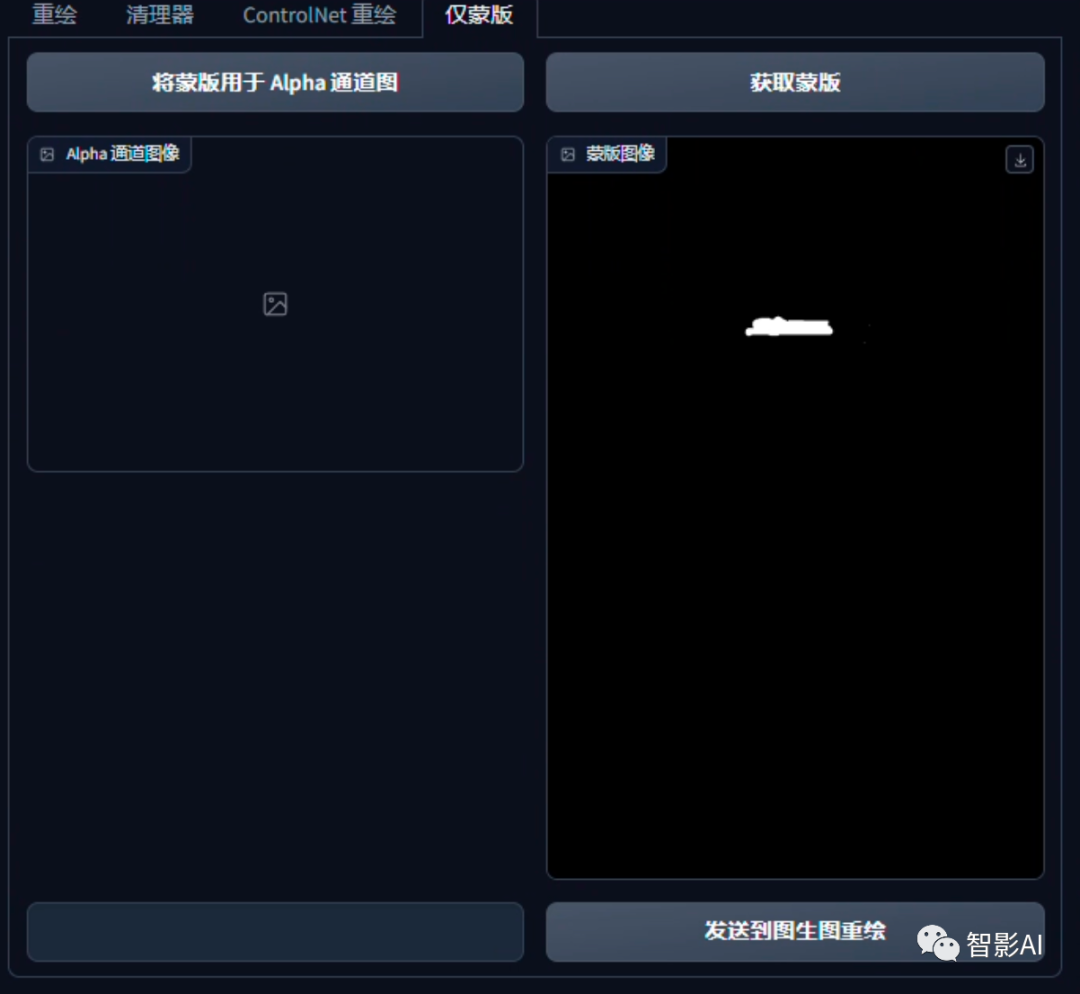
- 蒙版发送到图生图后,设置一下生成参数,尺寸建议跟上传的图片保持统一比例,其他的可以根据自己的需求调整。
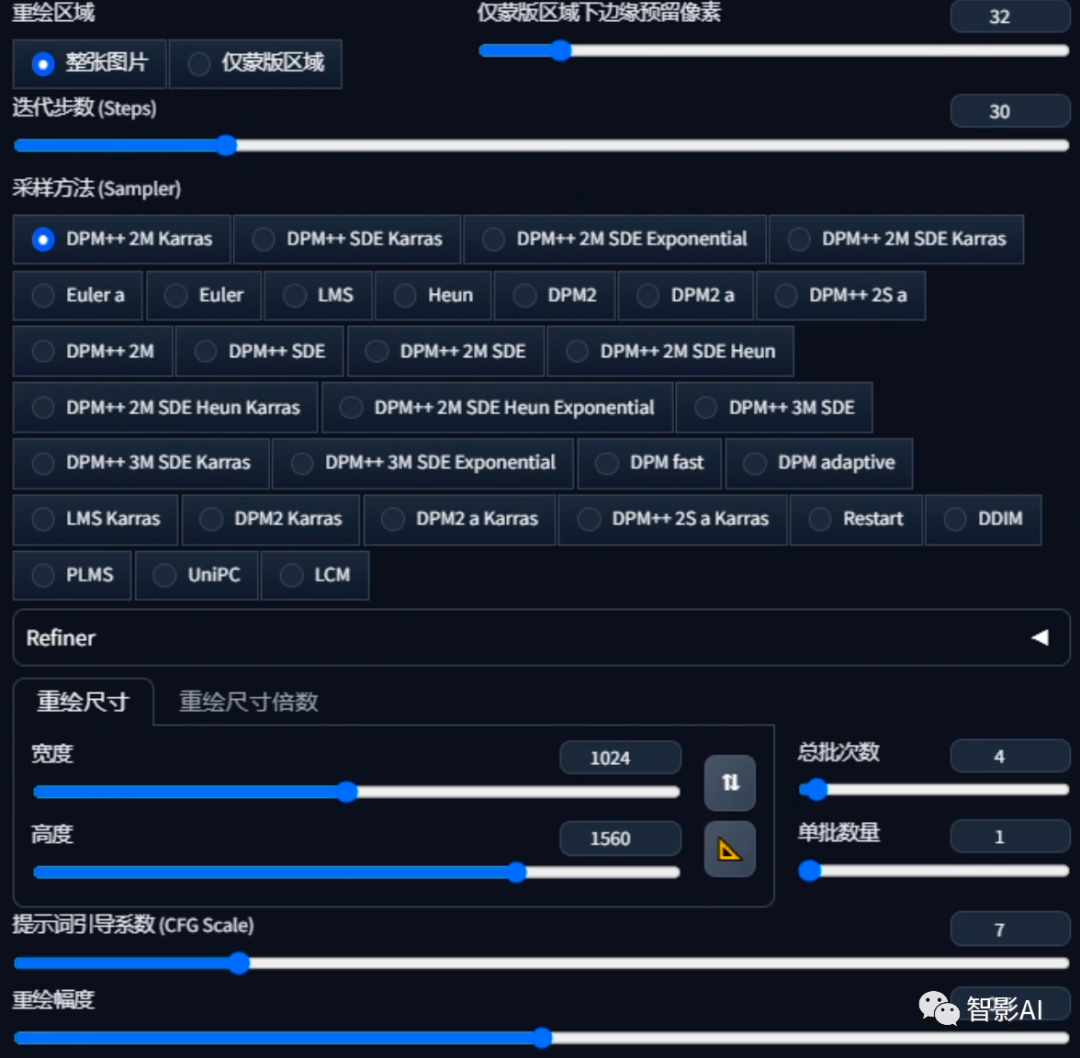
- 设置好参数之后,选择一个大模型,然后输入提示词即可。
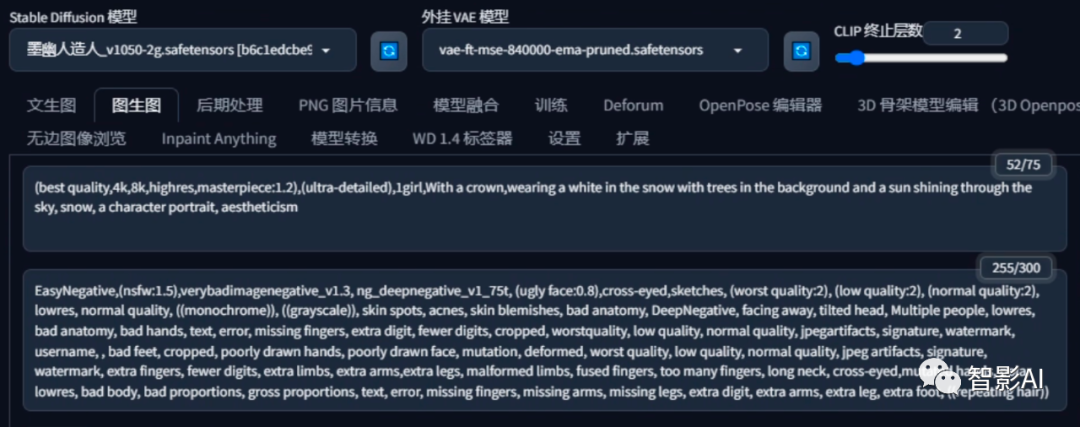
提示词跟上面一样,不会写的可以在图生图反推一下,然后将需要添加的物体提示词添加上即可。
- 设置好以上参数之后,点击“生成”即可。

我们可以看到,皇冠很自然的带到女孩的头上了。
5 最后
以上就是本文的全部介绍,去除和添加物体可以运用到很多的场景,例如,电商、现实拍的照片等等。
如果本文对你有帮助或者给你带来了一些创作灵感,欢迎点赞、在看、转发、关注,谢谢~
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1468
1468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









