







本文出自论文 Gaze Prediction in Dynamic 360° Immersive Videos, 基于时空显著性和历史注视点路径线索,提出了一个深度学习框架来进行未来帧的注视点预测。
基于历史浏览路径和VR视频内容,我们将预测观看者在下一段时间内所观看的位置。在图像内容中,那些显著性的目标更容易吸引观看者的注意力,并且显著性与目标的外观和动作信息有关。本文提出在不同的空间尺度上计算显著性映射:以当前注视点为中心的子图像块,与视野域(FoV)对应的子图像,以及全景图像。接着我们将整个显著性映射和相关的图像输入到一个CNN来提取特征,与此同时,我们也使用一个LSTM结构来编码整个历史浏览路径,接着将CNN特征和LSTM特征结合在一起,对当前时间点和未来时间点之间的注视点位移进行预测。
一、简介
- 在传统视频的注视点预测中,用户被动地观看视频,而在360°沉浸式视频中,用户可以主动的旋转头部和身体,来决定所看的内容位置。在动态场景中,对于每一帧,一个参与者所看的位置点取决于它的起始点和运动方向的决定,因此对于显著性检测来说很难标注ground-truth。
- 在动态360°视频中的注视点预测有利于VR视频数据传输中的压缩过程,一旦我们预测到未来视频帧中的每个参与者的观看区域,我们可以通过为专门观看者制定交互方法,从而来进一步提高人机交互体验。在VR游戏领域,对于不同玩家来有效设计不同难度水平的游戏也是非常重要的。
- 我们利用一个LSTM模块在固定的视野域下去估计观看者的行为,在以当前注视点为中心的区域内,在当前视野域里的视频内容,和整个360°视频场景下,我们考虑了视频内容在不同空间尺度下的显著性程度。然后我们将图像和它们在不同尺度下的显著性映射输入到一个CNN,接着我们将这个CNN特征和LSTM特征结合在一起,来预测从当前场景到下一个场景中的注视点位移。
二、相关工作
- Saliency Detection: 一些工作尝试使用低级别的外观特征和动作线索来作为输入,或者扩展深度学习方法到更加复杂的场景中,例如立体图片或者视频。
- Gaze Prediction on Egocentric Videos: 在这种设置下的注视点预测通常基于摄像头设备的转动速度,移动方向和手的位置。
三、数据集
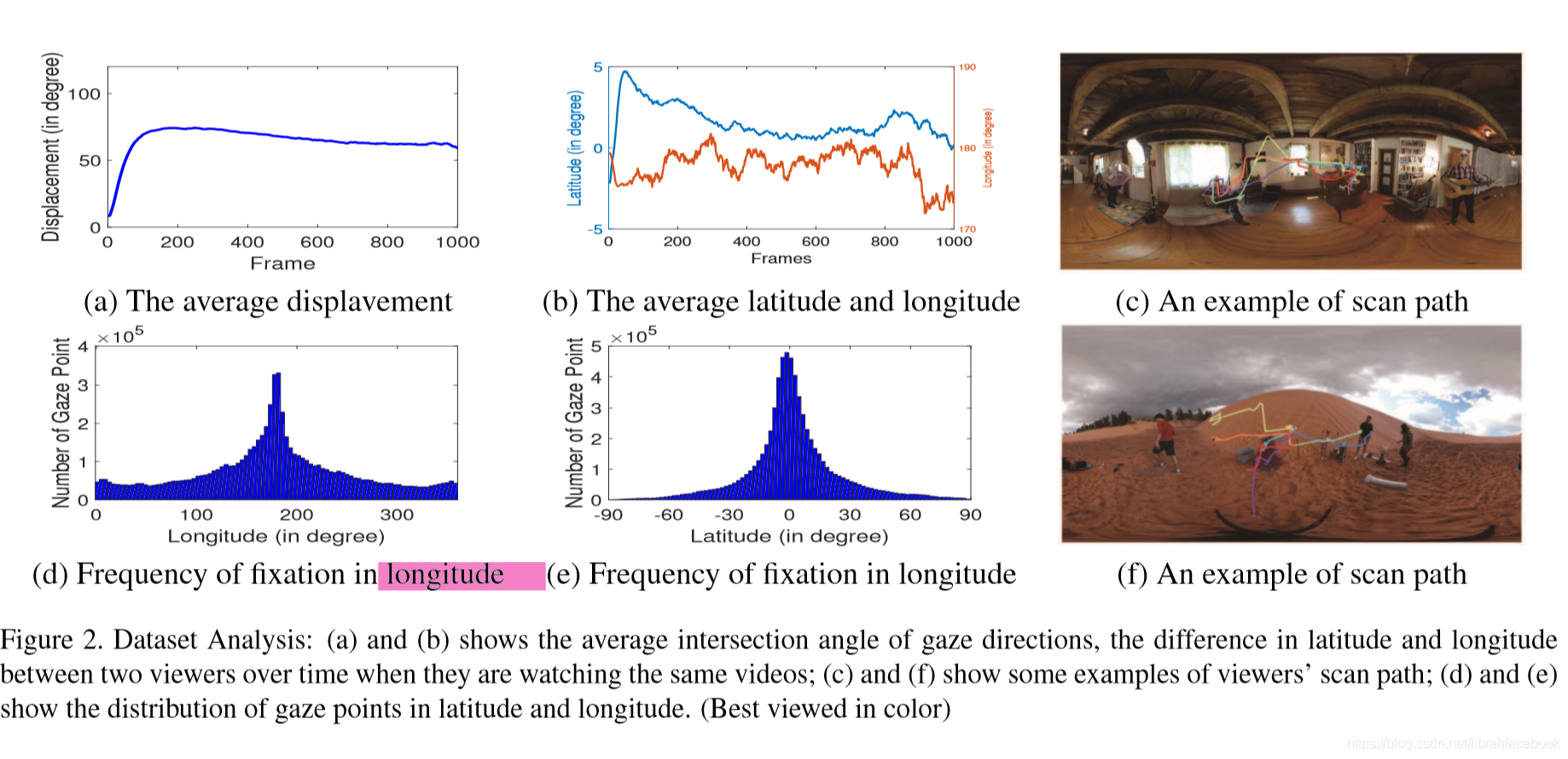
- 注视点和显著性区域的关系:基于在每一帧中的最高或最低显著性值,我们将这些像素点划分成10bins。基于与帧相关联的注视点所在的bins,我们可以获得所有视频的注视点落在不同bins的频率直方图。我们可以看到注视点通常与显著性点所一致。另外注视点和动作线索也有着一致性。
- 相邻帧注视点的角度分布:通常两个连续的相邻注视点之间的位移是很小的,换句话说,下一个帧的注视点落在当前注视点的领域内。


四、方法
-
未来帧注视点影响因素:一方面,注视点很大部分和来自图像内容大的空间显著性有所关系,时间显著性可以从相邻帧之间的光流中推断出来;另一方面,用户的历史注视路径对于预测其未来注视点也很关键,因为不同用户在观看一个场景时有着不同的习惯。注视点预测和其历史注视点路径之间的关系也激励了我们去连续预测每个未来帧的注视点。
-
我们将注视预测作为一个学习非线性映射函数F的任务,将历史注视路径和所关联的图像内容相映射。我们将注视点追踪的目标定义如下: F ∗ = arg min F ∑ t = o b s o b s + T − 1 ∣ ∣ l t + 1 − ( l t + F ( V t : t + 1 , L 1 : t ) ) ∣ ∣ 2 F^*=\mathop{\arg\min}_{F}\sum_{t=obs}^{obs+T-1}||l_{t+1}-(l_t+F(V_{t:t+1},L_{1:t}))||^2 F∗=argminF∑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1330
1330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









