







 本文提出AdaComp算法,解决边缘设备分布式深度学习的带宽压力和设备可靠性问题。AdaComp通过智能压缩更新并结合参数 staleness,降低了PS的入口流量,减少了通信量,同时保持模型精度。实验表明,AdaComp在面对worker故障和异构性能时仍能保持良好精度,为边缘设备上的深度学习训练提供了可行性。
本文提出AdaComp算法,解决边缘设备分布式深度学习的带宽压力和设备可靠性问题。AdaComp通过智能压缩更新并结合参数 staleness,降低了PS的入口流量,减少了通信量,同时保持模型精度。实验表明,AdaComp在面对worker故障和异构性能时仍能保持良好精度,为边缘设备上的深度学习训练提供了可行性。
本文出自论文 Distributed deep learning on edge-devices: feasibility via adaptive compression,主要提出来AdaComp,一种新的算法用于压缩workers对服务器模型的更新。1
在本文中,我们通过以下问题展开研究论述:在广域网连接设备上进行分布式深度学习可行吗?我们展示了这样的设置带来了一些重要挑战,最显著的是承载最新模型的服务器必须维持的入口流量。为了减少这种压力,我们提出了AdaComp,一种新的算法用于压缩workers对服务器模型的更新。这种方法结合了有效的梯度选择和学习率调整,适用于随机梯度下降的方法。我们发现:与标准异步随机梯度下降相比,worker发送到服务器上的数据总量减少了两个数量级,同时又保持了模型的准确性。
一、简介
- 在网络边缘的处理设备数量正在急剧增长,在本文中,我们探索了对于那些密集型任务利用边缘设备的可能性。这种新模式引出了重大的可行性问题,为了说明可行性问题,我们实现了TensorFlow论文中考虑的最大分布场景,使用200台机器来合作学习一个模型。我们的解决方案是引入一个新的压缩技术,使用梯度选择将更新从workers发送到PS。于是我们研究了更新压缩和设备可靠性方面的模型精度。
- 本文的主要贡献点为:(1)在边缘设备配置中公开参数服务器模型含义;(2)提出了AdaComp,一个在PS中减少入口流量的新压缩技术。(3)使用TensorFlow来实验AdaComp,然后在模型精度方面与其他竞争者做比较分析。
二、分布式深度学习
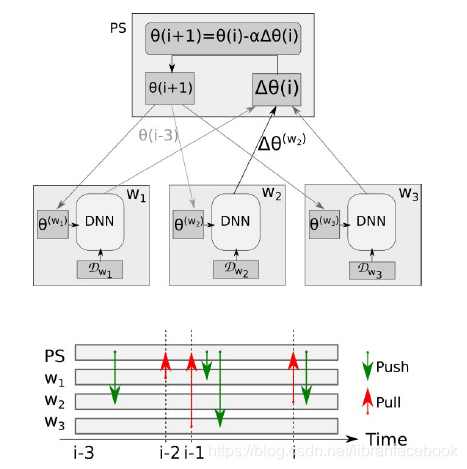
- PS通过初始化要学习的参数向量 开始,训练数据D被划分成工作者w1,w2,w3。每个worker都异步运行,只要有一个准备好了,就从PS中获取参数向量的当前版本,执行SGD步骤并发送向量更新给PS。在图中,w2在i-3次迭代中得到参数 θ \theta θ状态,执行SGD步骤并发送更新给PS。与此同时,w1和w3,在w2之前完成了它们的步骤,并发送了它们的更新。在每个更新接收阶段,PS更新 θ \theta θ,参数 θ \theta θ的时间戳在w1更新被接收后也发生了改变。
- 在PS模型中,n个worker并行地训练它们的本地向量然后发送更新,也称为staleness。对于一个worker来说,其本地向量 θ ( w ) \theta ^{(w)} θ(w)的staleness是 θ \theta θ被涉及到获取w的时间次数。
三、边缘设备上的分布式深度学习
- 我们考虑的执行设置用边缘设备节点和借助Internet的数据中心网络来替代数据中心工作节点,PS处在一个中央位置。正式执行的模型与PS模型保持一致:我们假设workers有足够的内存去拥有 θ \theta θ的复制,数据在n个workers中被打乱,最终它们同意合作完成机器学习任务。
- 减少在PS的入口流量:在边缘设备设置中,设备合作使用一个全局 θ \theta θ的计算,我们认为关键的度量标准是PS处理传入worker更新所需的带宽。由于我们的设置意味着在设备上进行最佳计算,而不是使上行链路饱和,所以workers将发送更
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









