







 本文探讨了在多跳问答任务中,如何使用知识图谱和大型语言模型(LLMs)来克服信息检索的局限性。通过知识图谱作为压缩信息存储,结合图形和文本数据,可以有效地处理需要跨多个文档检索信息的问题。文章介绍了知识图谱的优势,如结构化信息表示、多跳推理和结合结构化与非结构化数据的能力,以提高检索增强生成应用程序的性能。
本文探讨了在多跳问答任务中,如何使用知识图谱和大型语言模型(LLMs)来克服信息检索的局限性。通过知识图谱作为压缩信息存储,结合图形和文本数据,可以有效地处理需要跨多个文档检索信息的问题。文章介绍了知识图谱的优势,如结构化信息表示、多跳推理和结合结构化与非结构化数据的能力,以提高检索增强生成应用程序的性能。
原文地址:knowledge-graphs-llms-multi-hop-question-answering
2023 年 6 月 15 日
这是 Neo4j 的 NaLLM 项目的第三篇博客文章。我们启动这个项目是为了探索、开发和展示这些LLM 与 Neo4j 结合的实际用途。作为该项目的一部分,我们将在GitHub 存储库中构建并公开展示演示,为我们的社区提供观察、学习和贡献的开放空间。此外,我们一直在博客文章中写下我们的发现。您可以在这里查看前两篇博客文章:
Midjourney’s idea of an investigative board
在上一篇博客文章中,我们了解了检索增强方法来克服大型语言模型(LLM)的局限性,例如幻觉和有限的知识。检索增强方法背后的想法是在提问时参考外部数据并将其提供给LLMs,以增强其生成准确且相关答案的能力。
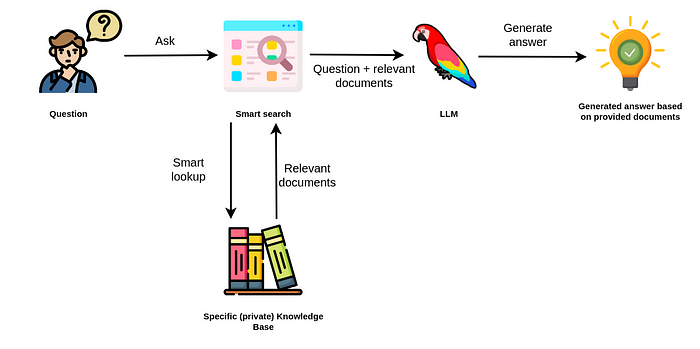
LLM应用的检索增强方法
当用户提出问题时,智能搜索工具会在提供的知识库中查找相关信息。例如,您可能遇到过在 PDF 或公司文档中搜索相关信息的情况。这些示例中的大多数都使用向量相似性搜索来识别哪些文本块可能包含相关数据以准确回答用户的问题。实现相对简单。
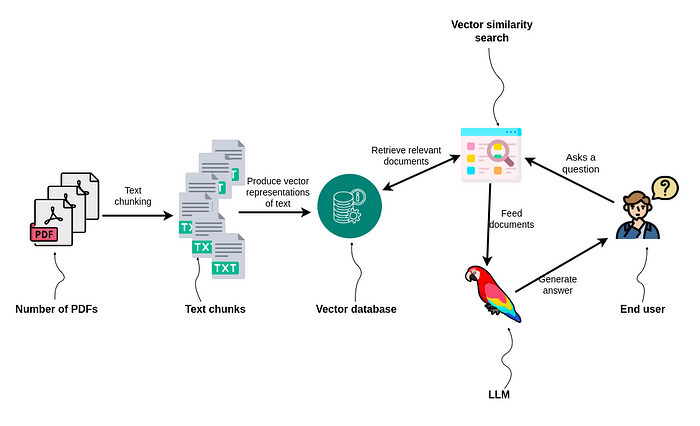
使用向量相似性搜索的 RAG 应用程序
PDF 或文档首先被分割成多个文本块。一些不同的策略包括文本块应该有多大以及它们之间是否应该有重叠。在下一步中&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









