







 本文探讨了大模型LLM与知识图谱KG的结合,如何提升模型的知识处理能力,优化性能,解决实际问题,如对话系统和搜索引擎。涵盖了评估、问题分解、推理框架、知识图谱构建和事实错误检测等多个方面,以及创新的解决方案如Keqing、QuartetLogic和UrbanGenerativeIntelligence等。
本文探讨了大模型LLM与知识图谱KG的结合,如何提升模型的知识处理能力,优化性能,解决实际问题,如对话系统和搜索引擎。涵盖了评估、问题分解、推理框架、知识图谱构建和事实错误检测等多个方面,以及创新的解决方案如Keqing、QuartetLogic和UrbanGenerativeIntelligence等。
大模型LLM与知识图谱KG的结合可以充分发挥两者的优势,例如LLMs的通用知识和语言处理能力,以及KGs的结构化和准确性。这种结合不仅能够提升模型的知识处理能力,还能够在多个层面上优化模型的性能,更好地解决各种现实世界的问题,例如搜索引擎、推荐系统和AI助手等。
今天我就盘点了大模型结合知识图谱最新的35个技术方案,2024年的已经帮同学们分析好了方法和创新点,部分开源代码也都整理了,剩余技术方案和项目代码需要的同学看文末
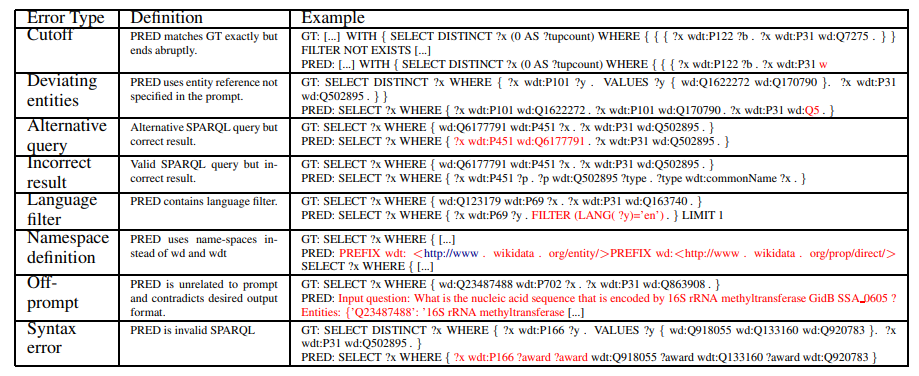
Evaluating Large Language Models in Semantic Parsing for Conversational Question Answering over Knowledge Graphs
「方法:」通过对不同大小和训练目标的LLMs生成的输出进行系统比较,重点关注优化于对话交互的模型。通过广泛的基准数据集,作者评估了模型在从对话中生成SPARQL查询方面的性能,并讨论了它们的个体能力和限制。作者的贡献包括评估四个LLMs的基准研究,利用自动评估和人工评估来识别生成的图查询中的八种常见错误类型,并详细讨论了用于改善模型性能的提示和微调策略。
「创新点:」
-
本文评估了未经过专门训练的大型语言模型在对话语义解析任务上的性能,通过一系列实验比较了不同大小的模型和不同提示技术的性能,并识别了生成输出中的常见问题类型。
-
与之前的模型不同,本文采用了上下文学习和后处理的方法,实现了端到端的结构化查询生成。本文旨在研究大型语言模型在理解对话、解决词汇问题和生成具有正确语法的SPARQL查询方面的性能。
keqing: knowledge-based question answering is a nature chain-of-thought mentor of LLM
「方法:」作者提出了Keqing框架,该框架的主要内容是通过预定义的模板将复杂问题分解为子问题,并在知识图谱上检索候选实体,然后通过推理回答子问题,并生成带有推理路径的回答。实验结果表明,Keqing在知识图谱问答数据集上取得了竞争性的性能,并且能够解释每个问题的回答逻辑。
「创新点:」
-
提出了问题分解模块,将复杂的用户问题根据预定义的问题模板分解为多个子问题。这种设计的思想是,文本形式的问题分解逻辑相对于SQL形式更容易被大型语言模型(LLMs)捕捉到。每个真实世界的问题都可能有多个解决方案(推理路径)来达到潜在的答案候选,而足够的答案候选可以为后续的答案推理过程提供容错能力。
-
提出了候选推理模块,根据分解的子问题的依赖关系,选择正确的实体来回答当前问题,并迭代地得出最终答案。通过问题分解和知识检索,得到了答案候选,然后利用候选推理模块选择正确的实体,并根据子问题的依赖关系逐步得出
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









