







 本文深入探讨大型模型(如LLMs和LMMs)的对齐技术,旨在使这些模型遵循人类价值观和偏好。文章分析了对齐的历史、数学本质和挑战,回顾了强化学习、监督式微调和上下文内学习等方法,讨论了个人对齐和多模态对齐的新兴领域。虽然取得显著进展,但对大模型的对齐仍面临数据成本、可扩展性和潜在风险等问题,对未来的对齐研究提出了展望。
本文深入探讨大型模型(如LLMs和LMMs)的对齐技术,旨在使这些模型遵循人类价值观和偏好。文章分析了对齐的历史、数学本质和挑战,回顾了强化学习、监督式微调和上下文内学习等方法,讨论了个人对齐和多模态对齐的新兴领域。虽然取得显著进展,但对大模型的对齐仍面临数据成本、可扩展性和潜在风险等问题,对未来的对齐研究提出了展望。

大模型在人工智能领域取得了革命性的突破,但它们也可能带来潜在的担忧。为了解决这些担忧,引入了对齐技术,以使这些模型遵循人类的偏好和价值观。尽管过去一年取得了相当大的进展,但在建立最佳对齐策略时仍然存在各种挑战,例如数据成本和可扩展的监督,如何对齐仍然是一个悬而未决的问题。在这篇综述文章中,我们全面调查了价值对齐方法。我们首先解析对齐的历史背景,追溯到20世纪20年代(它来自哪里),然后深入探讨对齐的数学本质(它是什么),揭示了固有的挑战。在此基础上,我们详细检查了现有的对齐方法,这些方法分为三类:强化学习、监督式微调和上下文内学习,并展示了它们之间的内在联系、优势和限制,帮助读者更好地理解这一研究领域。此外,还讨论了两个新兴主题:个人对齐和多模态对齐,作为该领域的新前沿。展望未来,我们讨论了潜在的对齐范式以及它们如何处理剩余的挑战,展望未来对齐的方向。
https://arxiv.org/abs/2403.04204
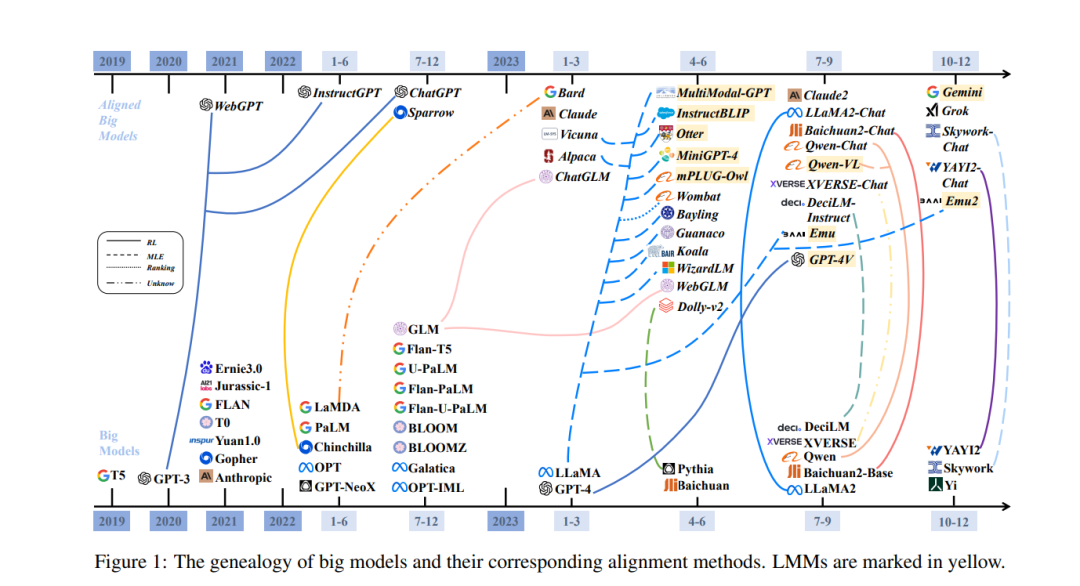
大模型,是指在大量数据上训练并包含超过数十亿参数的神经模型,通常包括 LLMs 和大型多模态模型(LMMs)。LLMs 通常是基于Transformer的大规模语言模型,以自回归方式训练,如GPT-3、PaLM、ChatGPT、Bard和LLaMA。LLMs 的卓越能力也促进了LMMs 的发展,LMMs 能够处理图像(视觉)和自然语言文本(语言),如PaLM-E、LLaVA、DALL-E 3和Gemini。与小模型不同,大模型展示了两个独特特征:规模化法则,阐明了模型规模增长与性能改进之间的一致关系,以及新兴能力显示,当模型规模超过某一阈值时,意外地出现了在小模型中未观察到的新能力,如上下文内学习、指令跟随和跨多种任务和领域的逐步推理,革新了AI的角色。因此,语言模型(LMs)经历了逐步的演化,从统计语言模型(SLMs)和神经语言模型(NLMs)开始,进步到预训练语言模型(PLMs),最终导致LLMs的复杂出现。沿着这样的轨迹,LL
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









