







论文地址:Chain-Of-Verification Reduces Hallucination In Large Language Models
摘要(Abstract)
在大型语言模型中,产生看似合理但实际上错误的事实信息,即幻觉,是一个未解决的问题。我们研究了语言模型在给出回答时进行深思以纠正错误的能力。我们开发了Chain-of-Verification(COVE)方法,该方法首先(i)起草一个初始回答;然后(ii)计划验证问题以对草稿进行事实核查;(iii)独立回答这些问题,以便答案不受其他回答的影响;最后(iv)生成其最终经过验证的回答。在实验中,我们展示了COVE在各种任务中减少了幻觉,包括来自Wikidata的基于列表的问题、封闭书籍的多跨度QA和长篇文本生成。
核心步骤
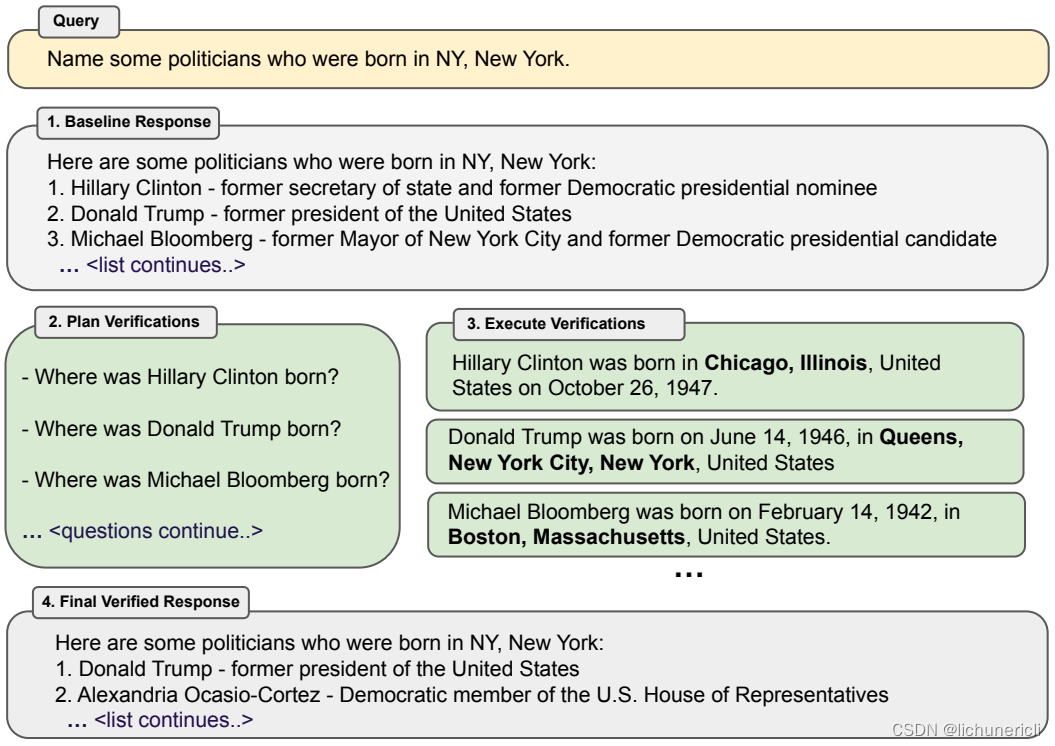

我们的方法假设能够访问一个基础的大型语言模型(LLM),尽管这个模型可能
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1784
1784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









