







 本文介绍了前馈神经网络的基础概念,包括神经元、激活函数、网络结构(输入、隐藏和输出层),以及学习过程中的反向传播和隐藏层的重要性。文章探讨了神经网络如何通过隐藏层处理复杂性,并提到了正则化在去噪方面的应用。最后强调了基础知识和逻辑在深度学习中的关键作用。
本文介绍了前馈神经网络的基础概念,包括神经元、激活函数、网络结构(输入、隐藏和输出层),以及学习过程中的反向传播和隐藏层的重要性。文章探讨了神经网络如何通过隐藏层处理复杂性,并提到了正则化在去噪方面的应用。最后强调了基础知识和逻辑在深度学习中的关键作用。
Jammy@Jetson Orin - Tensorflow & Keras Get Started: Understanding Feedforward Neural Networks
1. 源由
这里我们接着前面一章《Jammy@Jetson Orin - Tensorflow & Keras Get Started: 001 Linear Regression》继续我们的学习。
在本文中,将学习关于前馈神经网络的知识,也被称为深度前馈网络或多层感知器。它们构成了许多重要的神经网络的基础,如卷积神经网络(在计算机视觉应用中广泛使用)、循环神经网络(在自然语言理解和序列学习中广泛使用)等等。
2. 概念
我们先以直观和互动的方式理解涉及的重要概念。
2.1 前馈神经网络
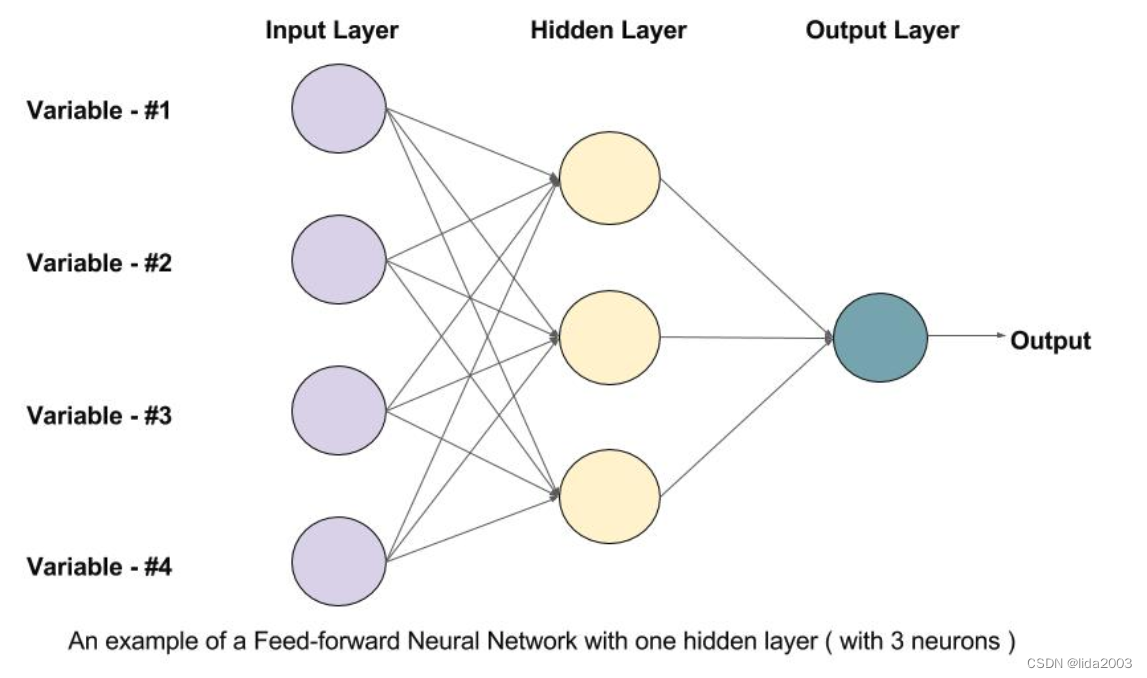 前馈神经网络是一个有向无环图,这意味着网络中没有反馈连接或循环。它包含一个输入层、一个输出层和一个隐藏层。一般来说,可能会有多个隐藏层。每个层中的节点都是一个神经元,可以将其视为神经网络的基本处理单元。
前馈神经网络是一个有向无环图,这意味着网络中没有反馈连接或循环。它包含一个输入层、一个输出层和一个隐藏层。一般来说,可能会有多个隐藏层。每个层中的节点都是一个神经元,可以将其视为神经网络的基本处理单元。
2.2 神经网络元
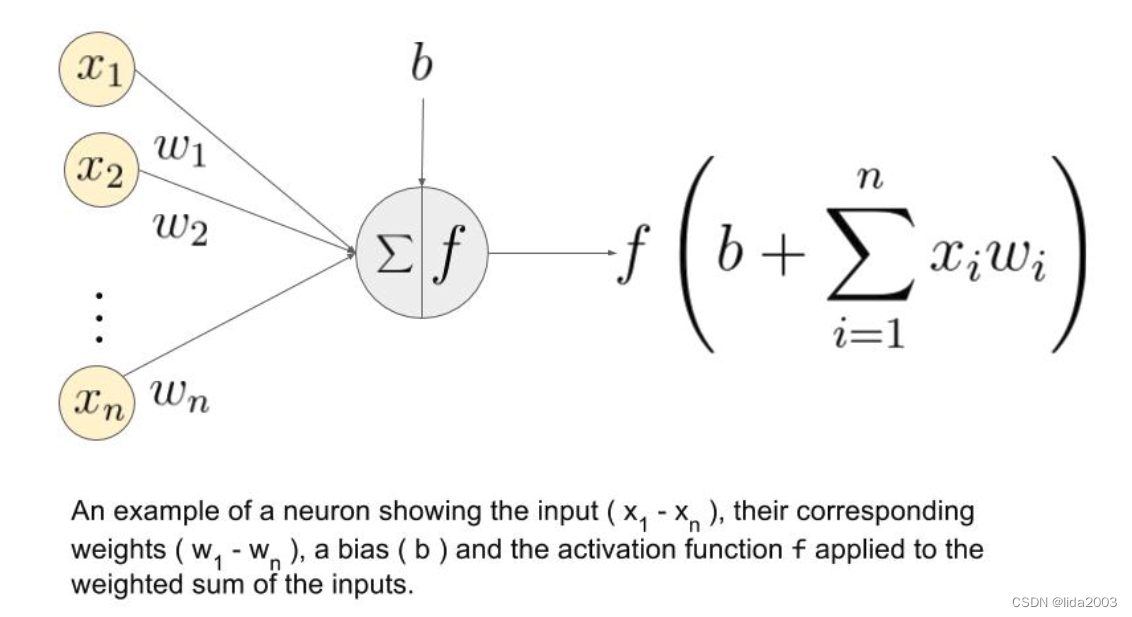
一个人工神经元是神经网络的基本单元。下面是一个神经元的示意图。
分两步工作:首先计算其输入的加权和,然后应用激活函数来归一化这个和。激活函数可以是线性的或非线性的。
此外,每个神经元的输入都有相应的权重。这些是网络在训练阶段需要学习的参数。
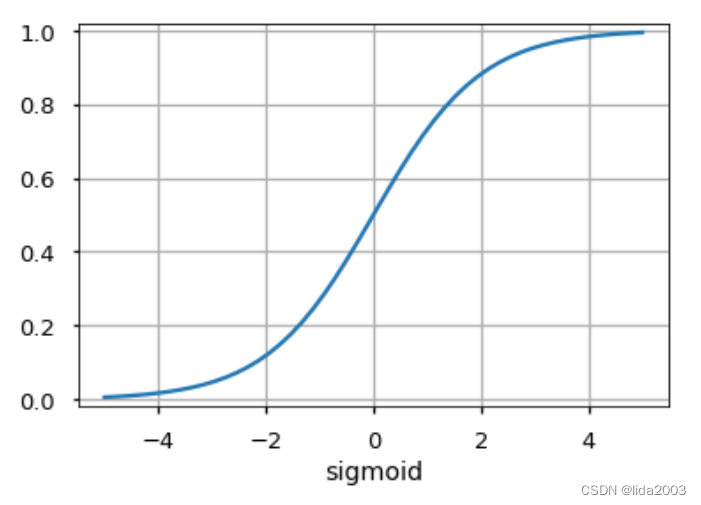
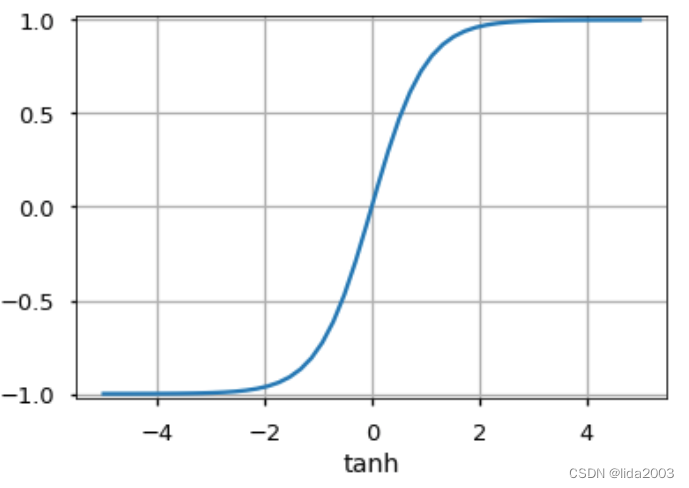
2.3 激活函数
激活函数被用作神经元输出端决策。神经元根据激活函数学习线性或非线性的决策边界。它还对神经元输出产生规范化效应,这可以防止经过多层后神经元输出变得非常大,产生级联效应。
有三种最广泛使用的激活函数:
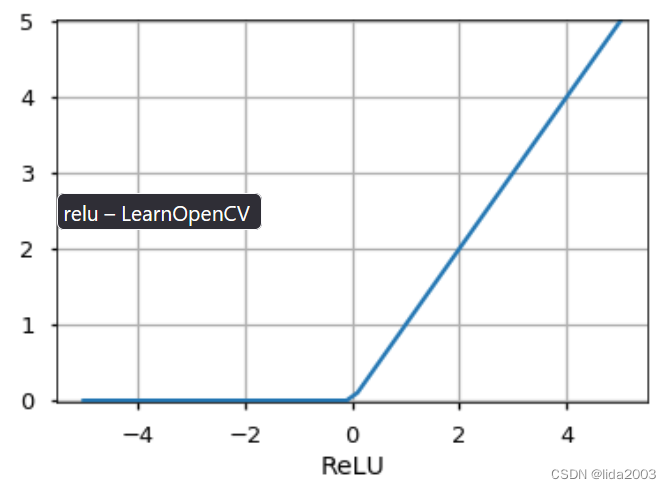
2.4 神经网络分层
2.4.1 输入层
这是神经网络的第一层。它用于向网络提供输入数据或特征。这部分数据从逻辑的角度就需要确保数据有效性。
通常数据’清洗",“修正”,“去噪”等操作都在这层完成,以确保进入模型的数据可靠、稳定、有效。
2.4.2 隐藏层
前馈网络对输入应用一系列函数。通过使用多个隐藏层,我们可以通过级联简单的函数来计算复杂的函数。隐藏单元的选择是机器学习中一个非常活跃的研究领域。隐藏层的类型区分了不同类型的神经网络,如CNN、RNN等。隐藏层的数量被称为神经网络的深度。
一个你可能会问的问题是,一个网络中有多少层才能使它成为深度网络?对此没有正确的答案。一般来说,更深的网络可以学习更复杂的函数。
2.4.3 输出层
这是神经网络中给出预测的层。对于不同的问题,该层所使用的激活函数是不同的。
- 对于二元分类问题,我们希望输出为0或1。因此,使用Sigmoid激活函数。
- 对于多类别分类问题,使用Softmax(将其视为Sigmoid对多个类别的泛化)。
- 对于回归问题,其中输出不是预定义的类别,我们可以简单地使用线性单元。
3. 问题
3.1 前馈神经网络是如何学习的?
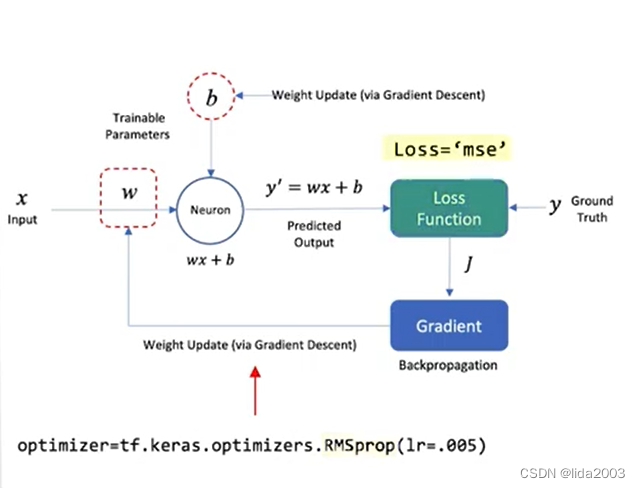
这个学习的概念是Keras的API进行的封装,从逻辑和概念的角度,引用前一章节的图来做一个回顾。
- 训练样本通过网络传递,并将从网络中获得的输出与实际输出进行比较。
- 这个误差被用来改变神经元的权重,使误差逐渐减小。这是通过反向传播算法完成的,也称为反向传播。
- 通过迭代地将数据批次传递到网络中,并更新权重,以使误差减少,这被称为随机梯度下降(SGD)。
- 权重变化的幅度由称为学习率的参数确定。
3.2 为什么需要隐藏层?
这里不做过多的数学推导,也不做过多的解释。用最为通俗易懂的方式,用图来理解。
下面可以非常显而易见的发现,输入参数(特性)的相关性与判别或者分类是有关系的。而神经网络如果具备了隐藏层,那么就具备这种交叉性。如果没有交叉性,权重可以为零。此时,通过学习的方式,算法就能渐进。
随着隐藏层数量的增加,特性相关复杂性就明显增加,多少是好还是不好,这个没有准确的定义。这里就给建模人员的业务知识留下了空间。比如:一个线性回归,一个神经元网络就可以解决问题。
您也可以自己用这个web页面playground.tensorflow.org来尝试区分不同类型的数据:
-
类型1:

-
类型2:

-
类型3:
-
类型4:

3.2.1 X12 X22 - 判别类型1
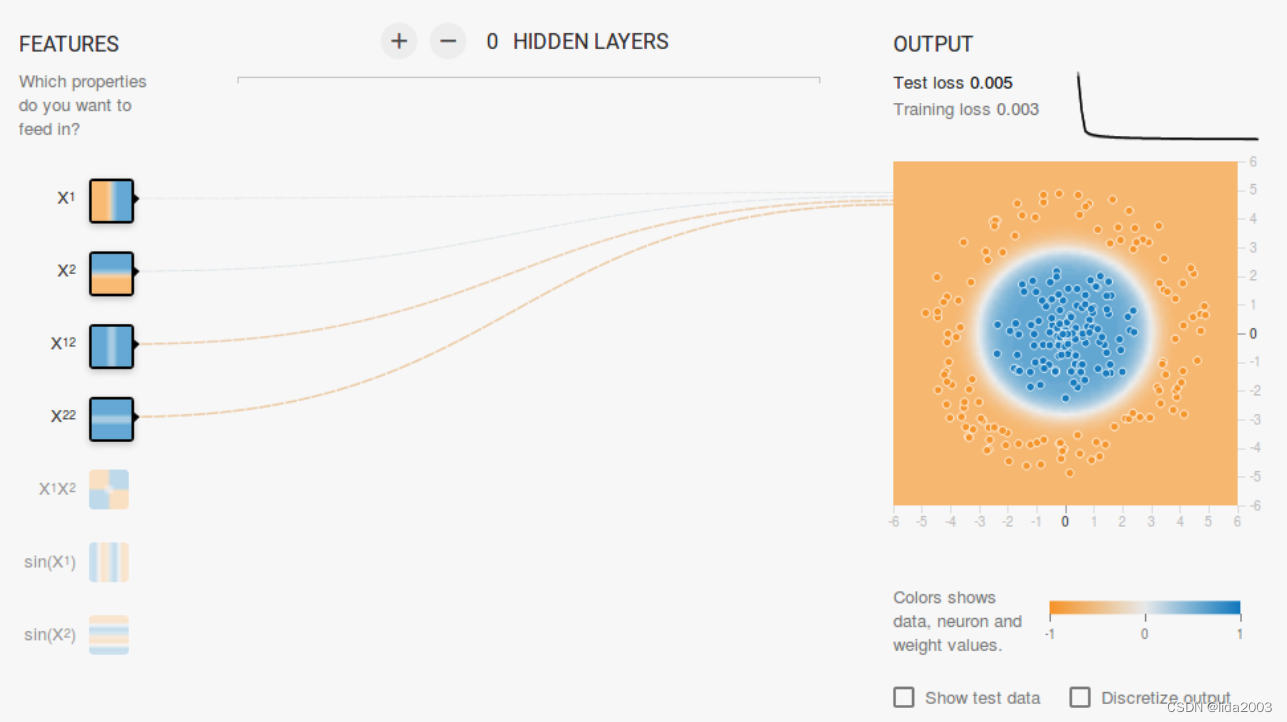
3.2.2 X1 X2 X1X2 - 判别类型2
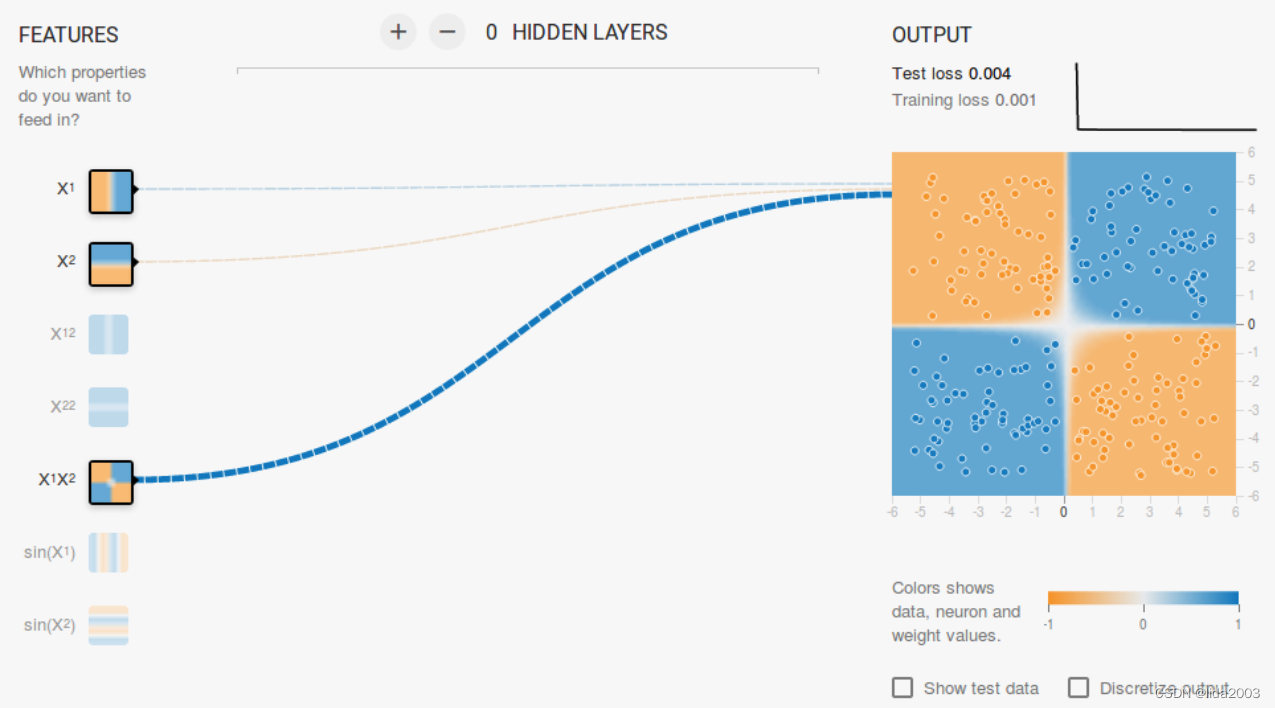
3.2.3 X1 X2 - 判别类型3
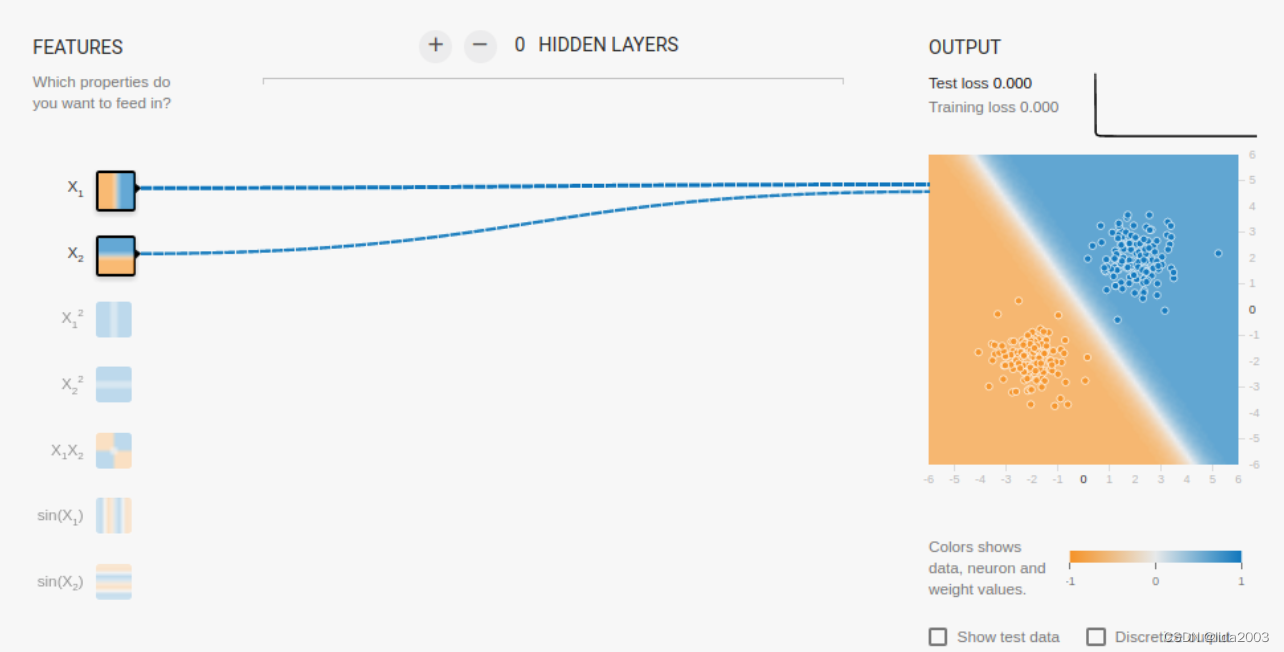
3.3 算法内部是如何去噪的?
除了在输入层特性参数可能存在噪声,需要对数据进行“清洗”,确保有效性以外,系统内部或多或少会
被引入测量误差导致的噪声。
注:干扰的噪声是可以去除的,但是测量的误差是无法去除的。这里所说的测量误差是指由于量具的最小刻度导致的误差。(对这个概念如果感觉需要明晰或者澄清的,可以看下大学物理的课本。)
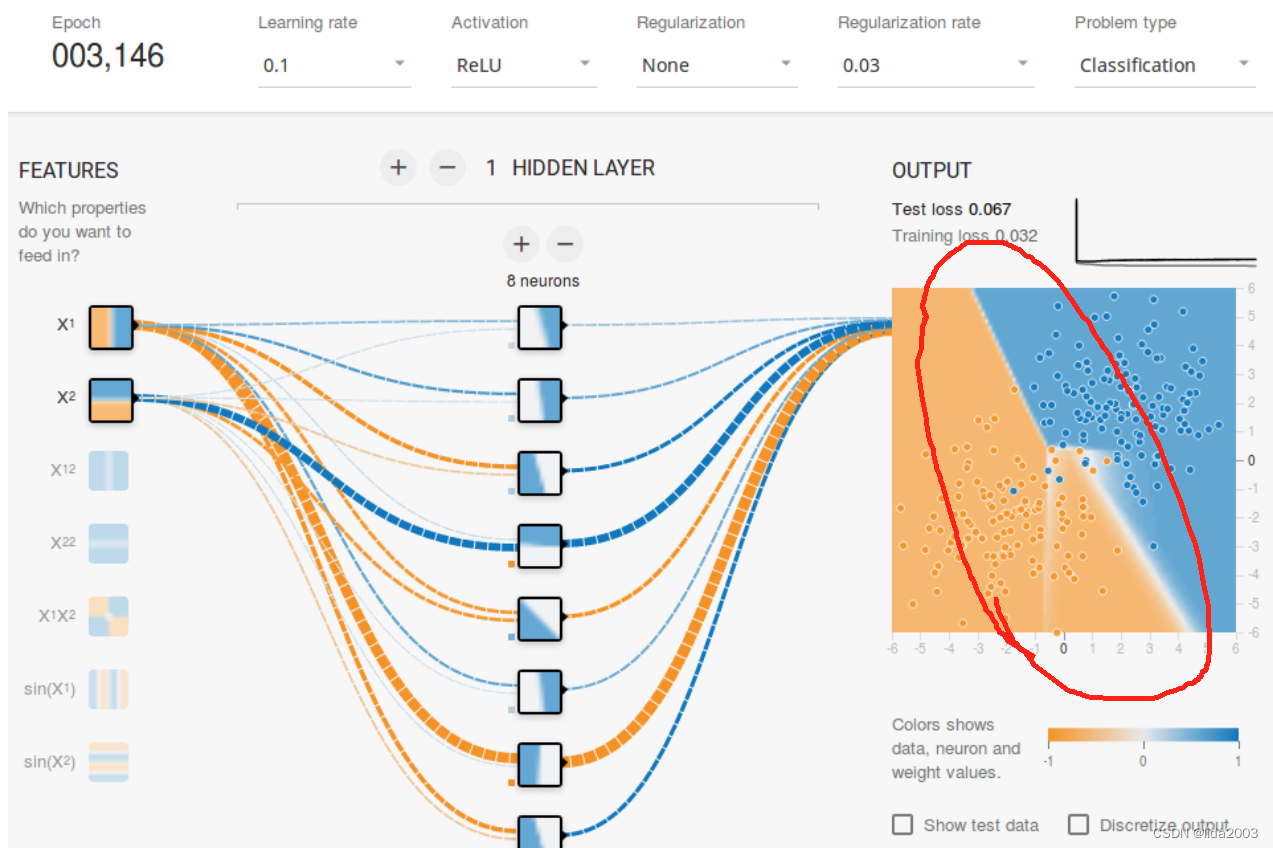
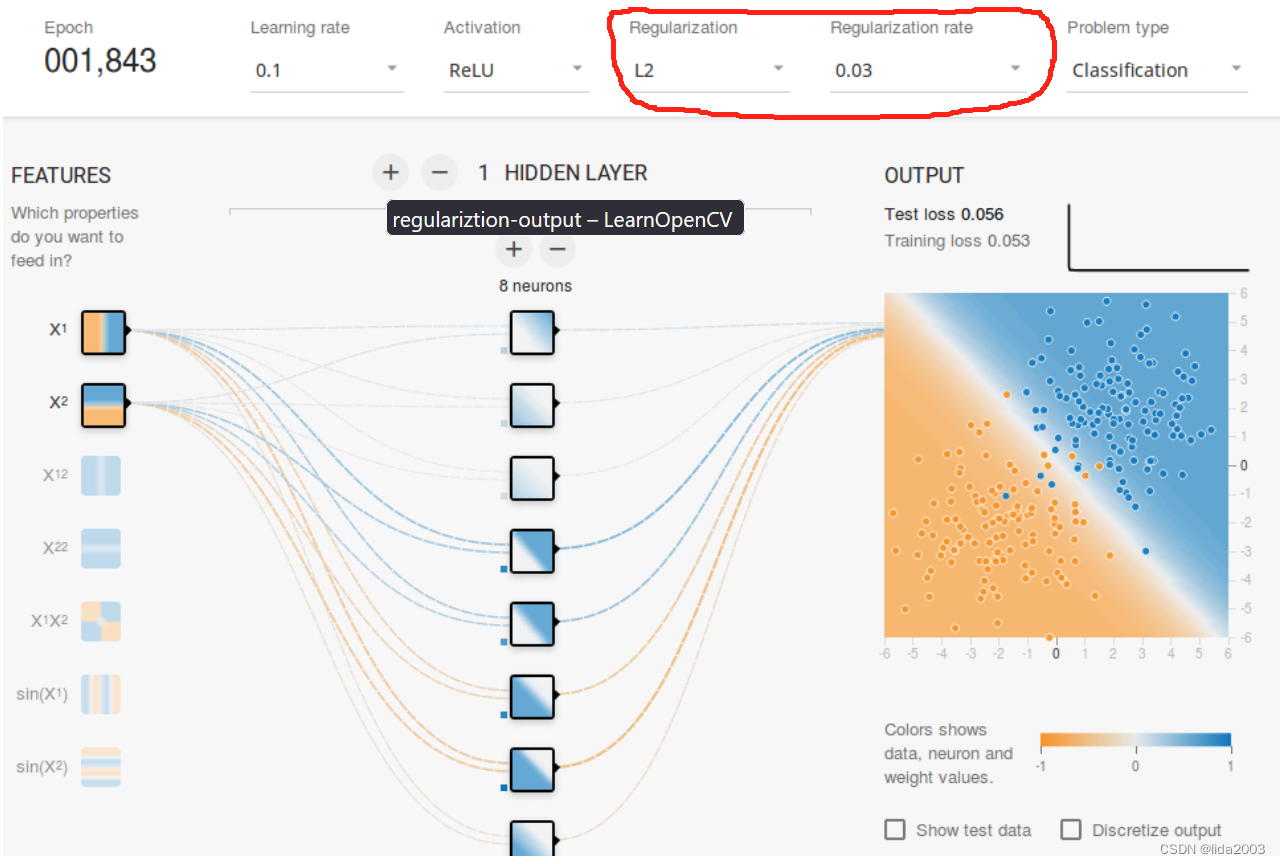
此时,需要从建模业务等领域,对权重进行限制或者处理,对权重值施加一些限制来纠正(比如不允许权重变得非常高),这就是正则化。
-
未加正则化
-
增加正则化(去噪)
4. 总结
通过上面对前馈神经网络的概念和一些问题的讨论,相信大家可能会觉得其实这种方法也并非这么神奇,其实他背后更多的还是逻辑和数学方法。
有了概念,相信后面的研读会更加顺利,切记,基础概念,逻辑一定是重中之重,如果基本概念都搞不清楚,何来后面的学习。
要知道人的一生就在不断地受到监督训练和非监督训练,我们的大脑是天然的神经网络系统,计算机GPU只不过是模拟我们而已,他们还远不能达到我们的水平。
延伸阅读:(计算机还远没有达到人类的认知,虽然ChatGPT确实已经很牛,但是你依然可以通过问题知道,他不是人,而是机器。虽然机器有超过人的很多地方,但是当我尝试去问一些ChatGPT问题,一眼就感觉他不是真的人。)
What we see and what we value: AI with a human perspective (Stanford University)















 8561
8561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









