







Jammy@Jetson Orin - Tensorflow & Keras Get Started: Convolutional Neural Network - A Complete Guide
1. 源由
之前《Jammy@Jetson Orin - Tensorflow & Keras Get Started: 002 Implementing an MLP in TensorFlow & Keras》,使用了一个密集连接的多层感知器(Multilayer Perceptron, MLP)网络来对手写数字进行分类。
由于MLP技术和图像数据的特殊性,在对图像进行分类的时候,将会出现以下三个问题:
- 图像识别训练开销庞大
使用全连接的MLP网络来处理图像的一个问题是图像数据通常相当庞大,这导致可训练参数数量大幅增加。
举例来说,一张尺寸为(224x244x3)的彩色图像。在MLP中,输入层将拥有150,528个神经元。如果我们接着有三个中等大小的隐藏层,每个隐藏层有128个神经元,再加上输入层,那么网络中可训练的参数将超过3000亿个!这样的网络不仅训练时间会非常长,而且由于可训练参数数量庞大
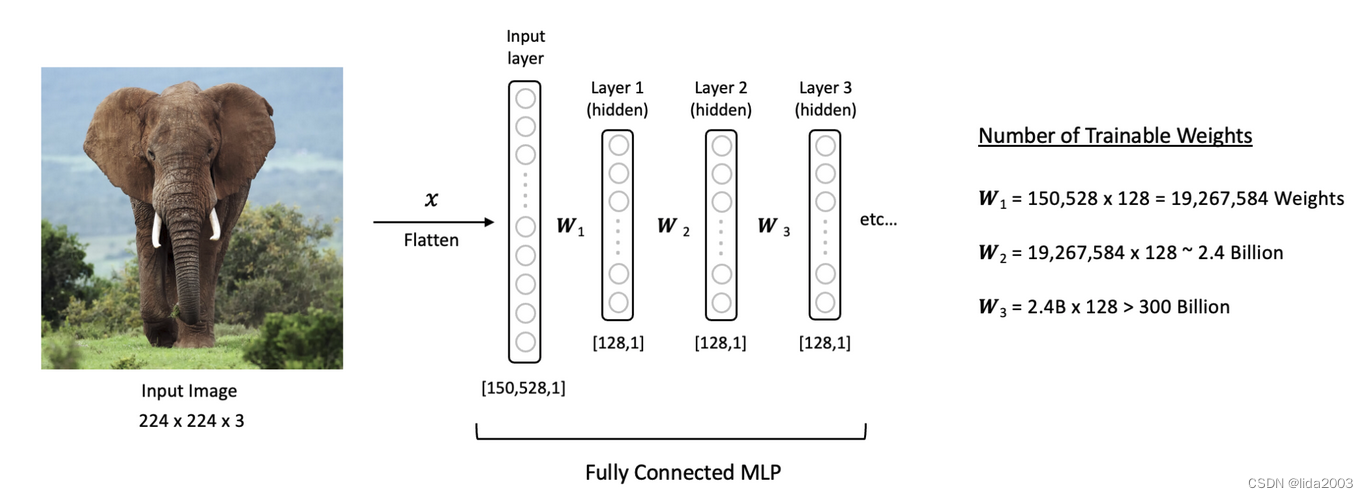
- 容易过拟合
MLP对图像中的每个输入像素使用单个神经元。因此,网络中的权重数量迅速变得难以管理(特别是对于具有多个通道的大型图像),模型也极易过拟合训练数据。
- 不具有平移不变性
使用MLP处理图像数据的一个问题是它们不具有平移不变性。这意味着如果图像的主要内容发生了移动,网络会有不同的反应。由于MLP对移位图像的响应不同,下面的例子说明了这些图像如何使分类问题变得复杂,并产生不可靠的结果。

幸运的是,有更好的方法来处理图像数据。卷积神经网络(CNN)的发展使得处理图像数据更加有效和高效。这在很大程度上归功于使用卷积操作来从图像中提取特征。这是卷积层的一个关键特性,称为参数共享,即相同的权重被用来处理输入图像的不同部分。这使我们能够检测到特征模式,这些模式在卷积核沿着图像移动时是平移不变的。与全连接层相比,这种方法通过显著减少可训练参数的总数来提高模型的效率。
2. 卷积神经网络(CNN)
让我们来看一下VGG-16,以研究其架构组件以及与各个层相关联的操作。
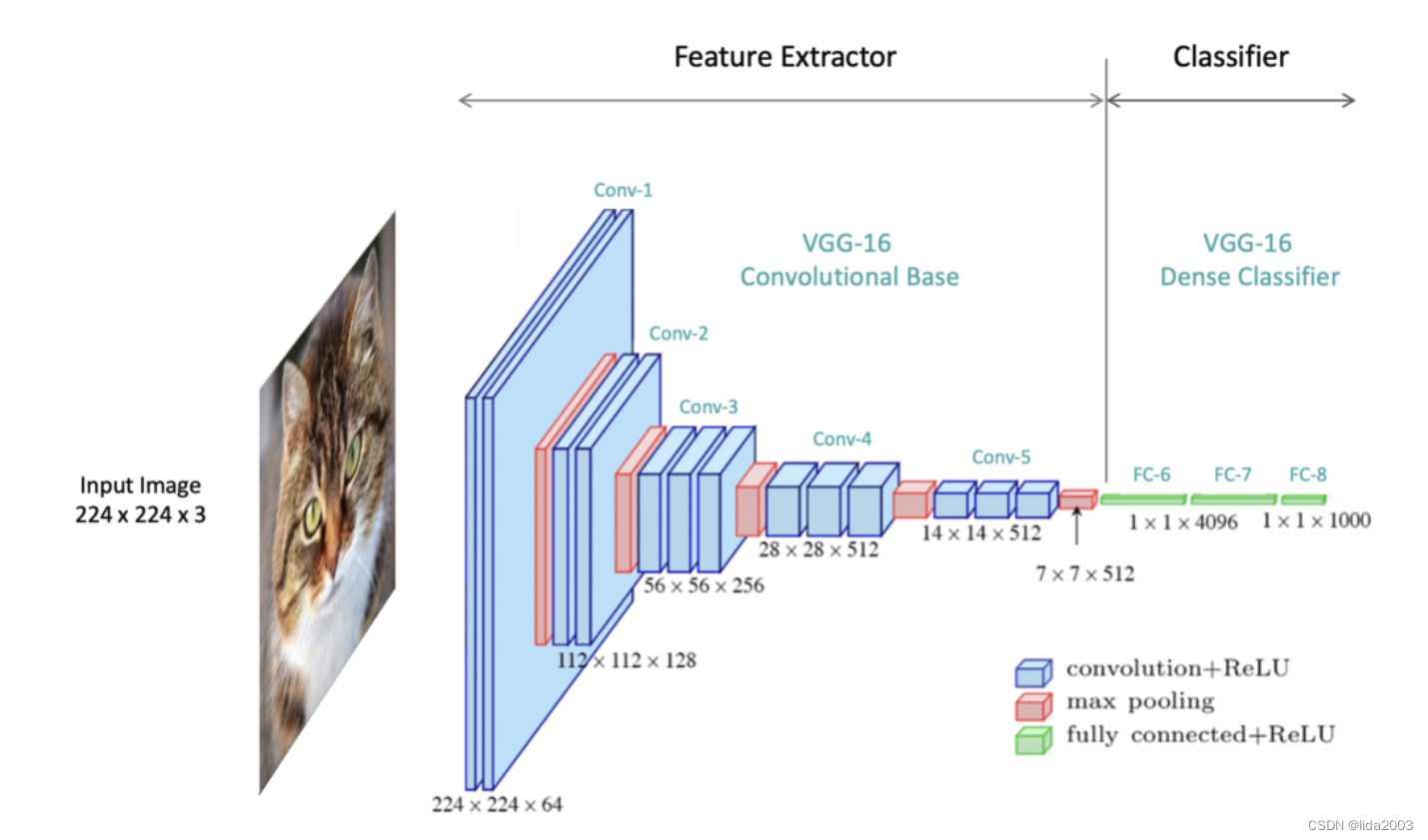 请注意,架构中描绘的每个层都有一个空间维度和一个深度维度。这些维度代表数据在网络中流动时的形状。VGG-16网络专门设计用于接受输入形状为224x224x3的彩色图像,其中3表示RGB颜色通道。随着输入数据通过网络传递,数据的形状会发生变化。空间维度被(有意地)减小,而数据的深度增加。数据的深度被称为通道数。
请注意,架构中描绘的每个层都有一个空间维度和一个深度维度。这些维度代表数据在网络中流动时的形状。VGG-16网络专门设计用于接受输入形状为224x224x3的彩色图像,其中3表示RGB颜色通道。随着输入数据通过网络传递,数据的形状会发生变化。空间维度被(有意地)减小,而数据的深度增加。数据的深度被称为通道数。
CNN的一般结构,通常包括一系列卷积块,后跟若干全连接层。卷积块从输入图像中提取有意义的特征,并通过全连接层进行分类任务。
2.1 卷积层
卷积层可以被看作是CNN的“眼睛”。卷积层中的神经元寻找特定的特征。在最基本的层面上,卷积层的输入是一个二维数组,它可以是网络的输入图像,也可以是网络中前一层的输出。第一个卷积层的输入是输入图像。输入图像通常是灰度图像(单通道)或彩色图像(3个通道)。
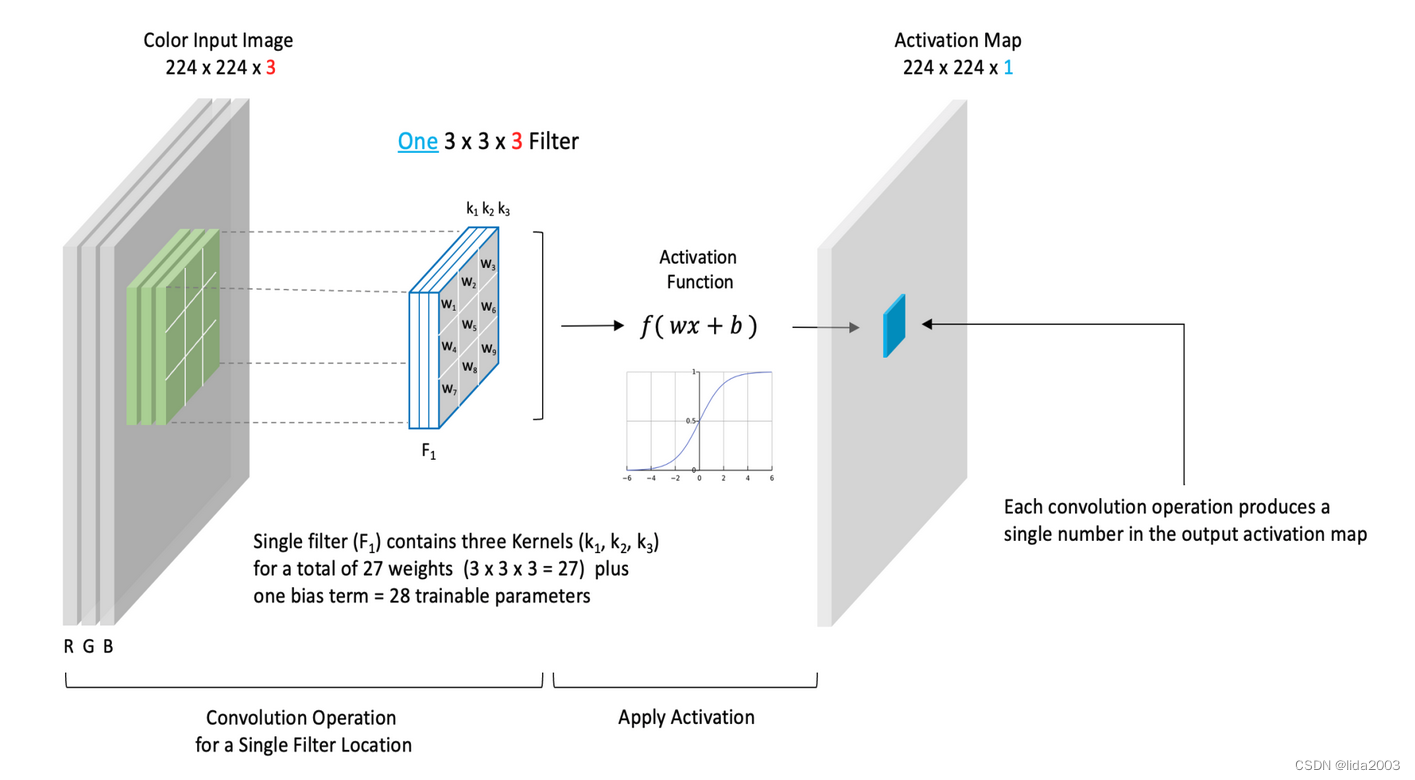
在VGG-16中,输入是一个形状为:(224x224x3)的彩色图像。这里我们描述了卷积层的高层视图。卷积层使用滤波器来处理输入数据。滤波器在输入上移动,在每个滤波器位置上执行卷积操作,产生一个单一的数字。然后,该值经过激活函数处理,激活函数的输出填充到输出中的相应条目,也称为激活图(224x224x1)。您可以将激活图视为通过卷积过程从输入中包含特征摘要。
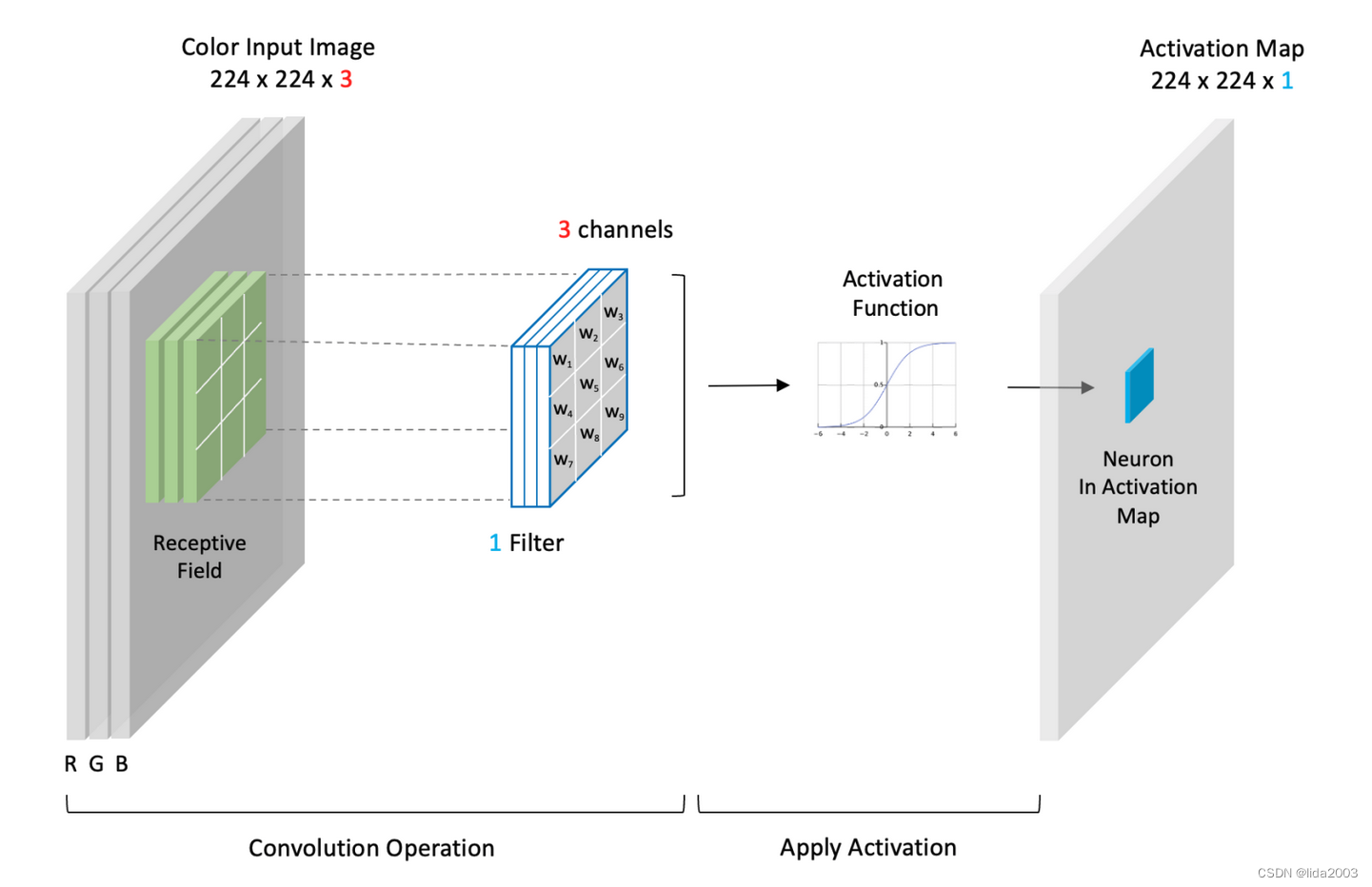
- 卷积层特性
- 滤波器的深度(通道数)必须与输入数据的深度匹配(即输入中的通道数)。
- 滤波器的空间大小是一种设计选择,但3x3是非常常见的(有时也是5x5)。
- 滤波器的数量也是一种设计选择,决定了输出中产生的激活图的数量。
- 有时多个激活图被集体称为“包含多个通道的激活图”。但我们通常将每个通道称为一个激活图。
- 滤波器中的每个通道被称为一个核,因此您可以将滤波器视为核的容器。
- 单通道滤波器只有一个核。因此,在这种情况下,滤波器和核是同一个东西。
- 滤波器/核中的权重被初始化为小的随机值,并在网络训练过程中学习。
- 卷积层中可训练参数的数量取决于滤波器的数量、滤波器大小和输入中的通道数。
回想一下,卷积操作的输出经过激活函数处理,产生所谓的激活图。卷积层通常包含许多滤波器,这意味着每个卷积层会产生多个激活图。当图像数据通过一个卷积块时,其净效应是对数据进行转换和重塑。
- 单一滤波卷积核
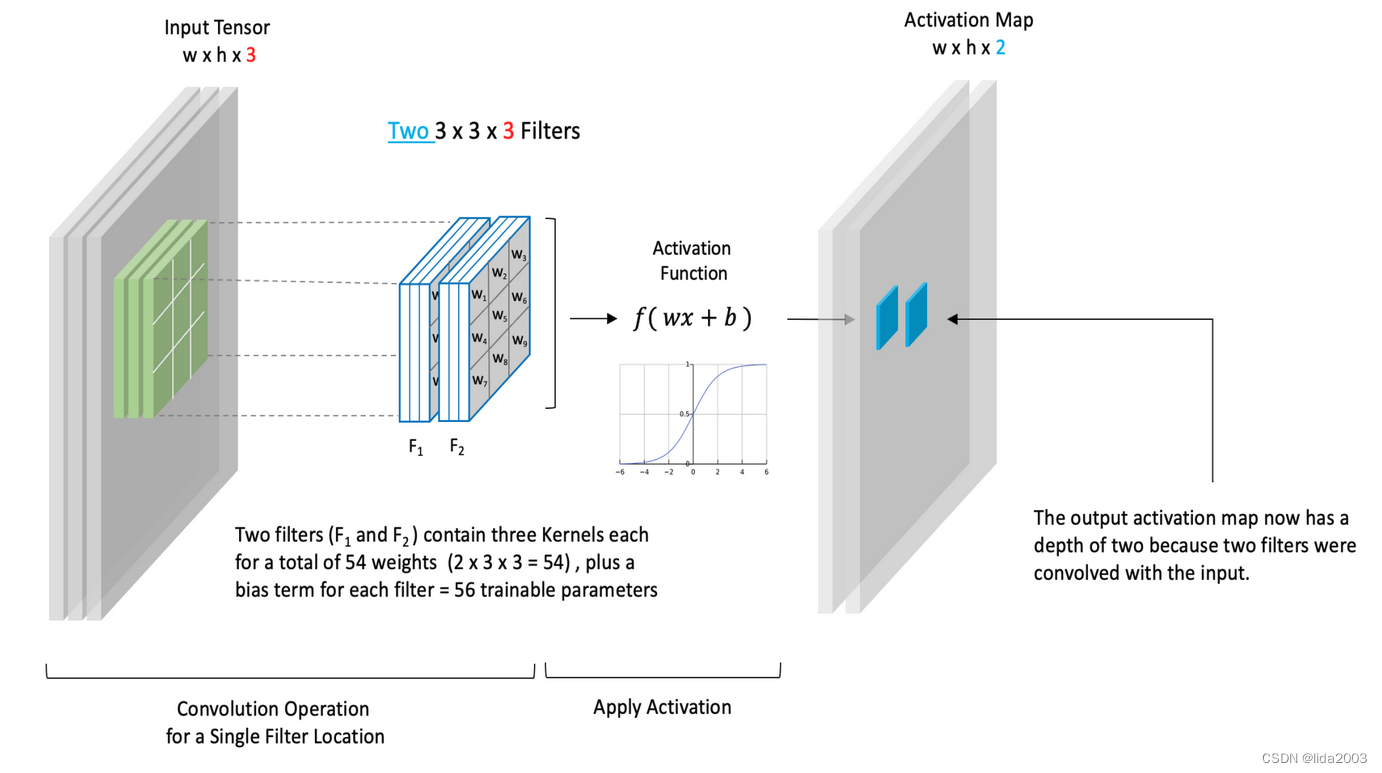
- 双滤波卷积核
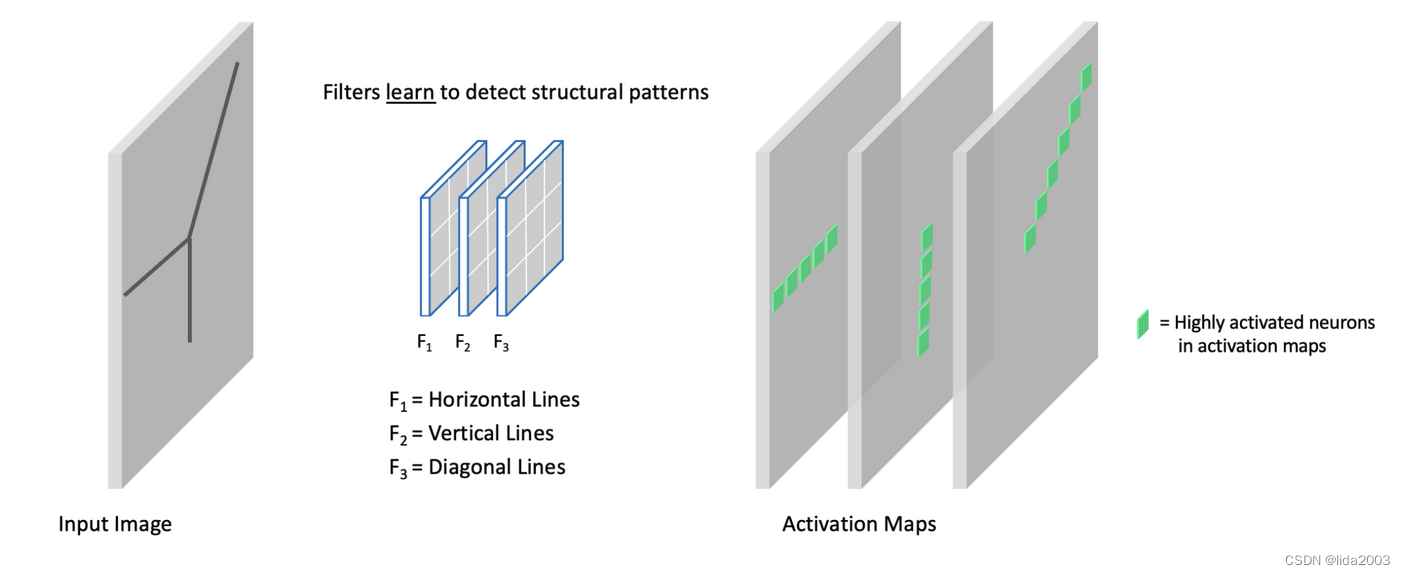
- 示例:多滤波边缘检测
在这个例子中,我们有一个具有三个滤波器的卷积层。每个滤波器学习检测不同的结构元素(即水平线、垂直线和对角线)。更准确地说,这些“线条”代表图像中的边缘结构。在输出激活图中,我们强调了与每个滤波器相关联的高度激活的神经元。
在2013年,一篇具有里程碑意义的论文《Visualizing and Understanding Convolutional Networks》揭示了为什么CNN表现得如此出色。他们引入了一种新颖的可视化技术,可以洞察CNN模型中间层的功能。
2.2 池化层
在CNN架构中,通常通过池化层定期减少数据的空间维度。池化层通常用于一系列卷积层之后,以减少激活图的空间大小。您可以将其视为从激活图中总结特征的一种方式。使用池化层会减少网络中的参数数量,因为后续层的输入尺寸减小了。这是一个理想的效果,因为训练所需的计算量也减少了。此外,使用更少的参数通常有助于减轻过拟合的影响。
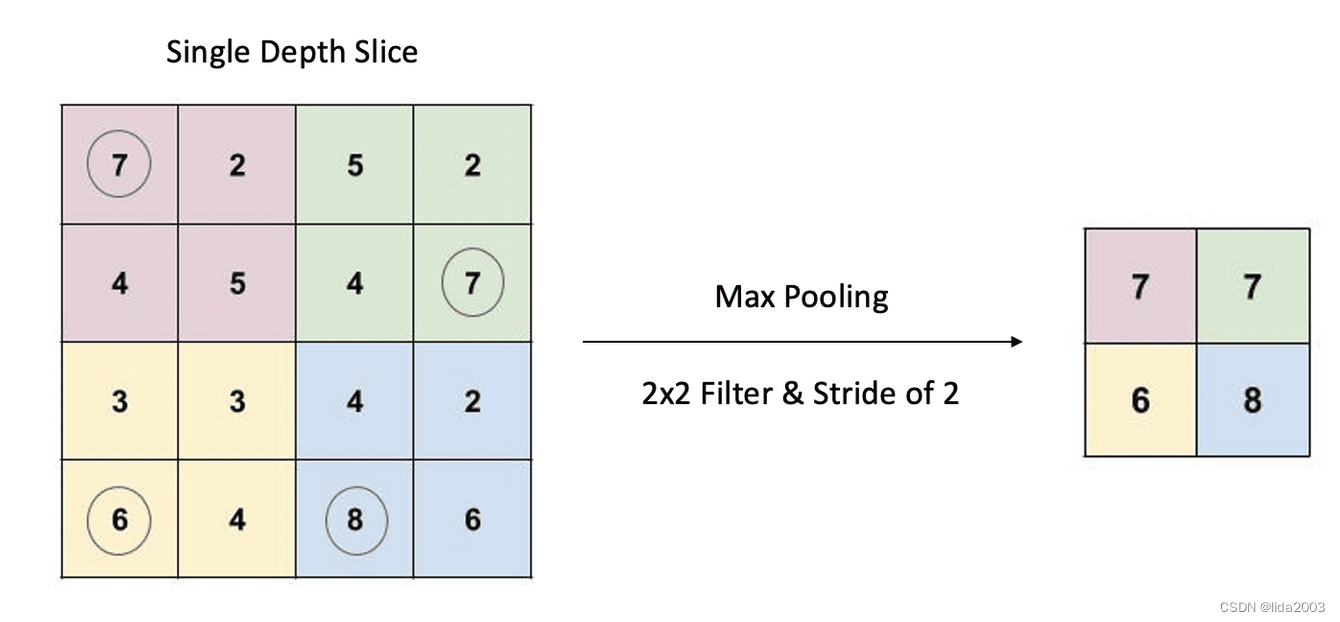
池化是一种使用2D滑动滤波器的缩小形式。根据可配置参数(称为步幅),滤波器在输入切片上移动。步幅是滤波器从一个位置移动到下一个位置时在输入切片上移动的像素数。有两种类型的池化操作:平均池化和最大池化。然而,最大池化是最常见的。
对于任何给定的滤波器位置,输入切片中的相应值经过max()操作。最大值然后记录在输出中。如上面的示例所示,我们有一个4x4的输入切片,一个2x2的滤波器,步幅为2。因此,相应的输出是输入切片的一个2x2缩小表示。
与卷积滤波器相反,池化层中的滤波器没有可训练参数。滤波器指定了用于执行max()操作的窗口大小。
2.3 全连接层
在CNN架构中,全连接(密集)层将特征转换为类别概率。在VGG-16的情况下,最后一个卷积块(Conv-5)的输出是一系列形状为(7x7x512)的激活图。
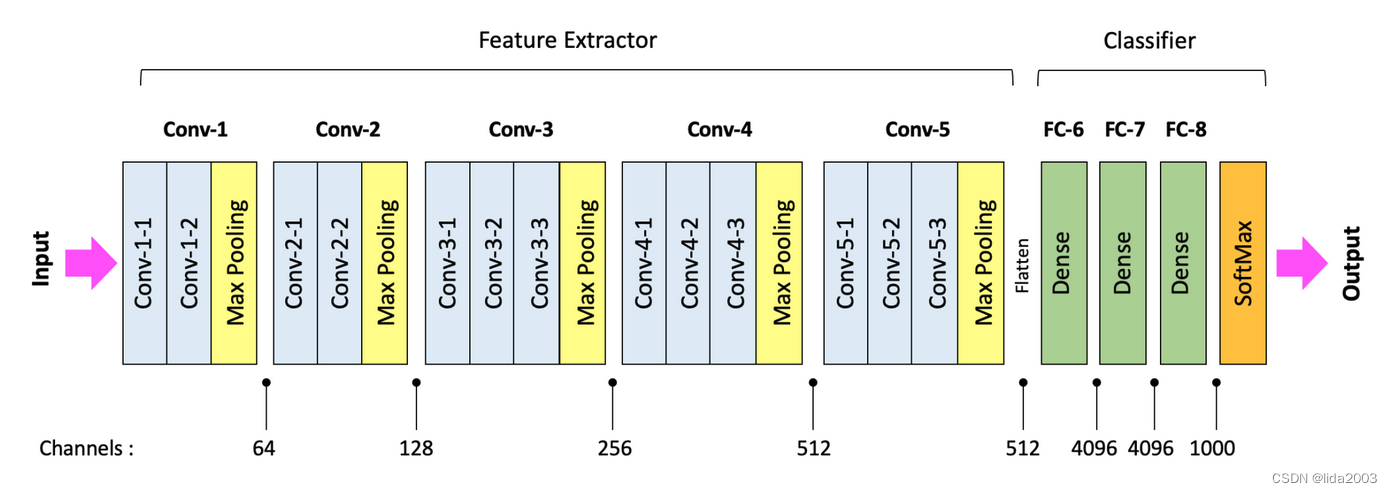
在特征提取器中的最后一个卷积层的数据在流经分类器之前,需要被展平为长度为25,088的一维向量。展平后,这个一维层然后与FC-6完全连接。
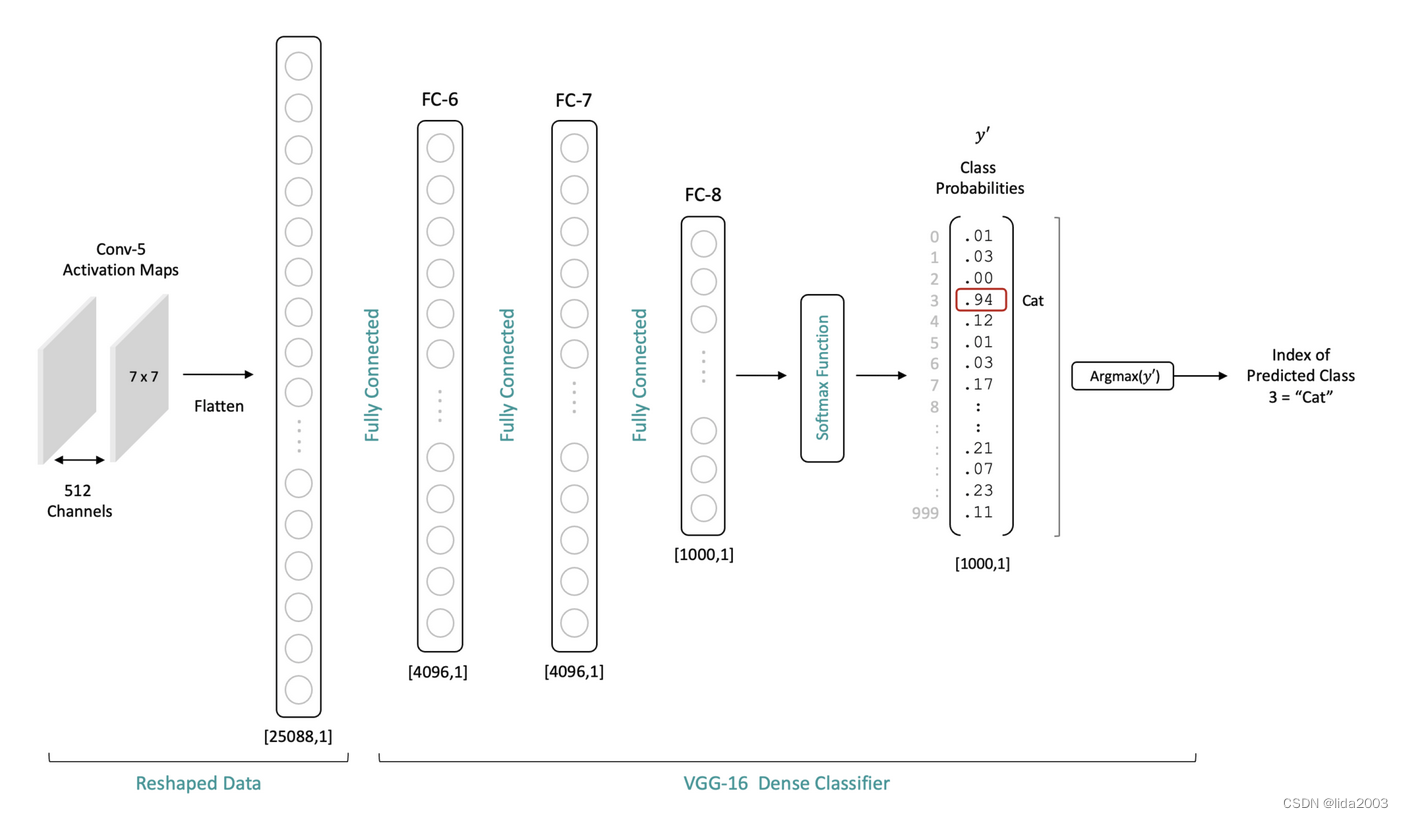
训练过的CNN网络的最后一个卷积层的激活图代表着关于特定图像内容的有意义的信息。请记住,特征图中的每个空间位置与原始输入图像具有空间关系。因此,在分类器中使用全连接层允许分类器处理整个图像的内容。将最后一个卷积层的展平输出以完全连接的方式连接到分类器,使分类器能够考虑整个图像的信息。
注:将Conv-5的输出展平是为了通过分类器处理激活图,但它不会改变数据的原始空间解释。这只是为了处理目的对数据进行重新打包。
2.4 示例
为了更具体地说明这一点,让我们假设我们有一个经过训练的模型(网络中的所有权重都是固定的)。现在考虑一张汽车和一只大象的输入图像。当每个图像的数据通过网络处理时,由于输入图像内容的不同,最后一个卷积层的结果特征图将看起来非常不同。当最终的特征激活图通过分类器处理时,将特征图和训练好的权重相结合,将导致与每种输入图像类型相关联的特定输出神经元产生更高的激活。全连接层之间的(概念上的)虚线代表通向输出神经元最高激活的路径(即,在每一层中具有大权重和高激活的情况)。实际上,在展平的激活图和分类器中的第一个全连接层之间有超过1亿个连接。
值得强调的是,下面两个示例中的权重是相同的(它们代表一个经过训练的网络)。下图中的数据是概念性的,用于说明概念。
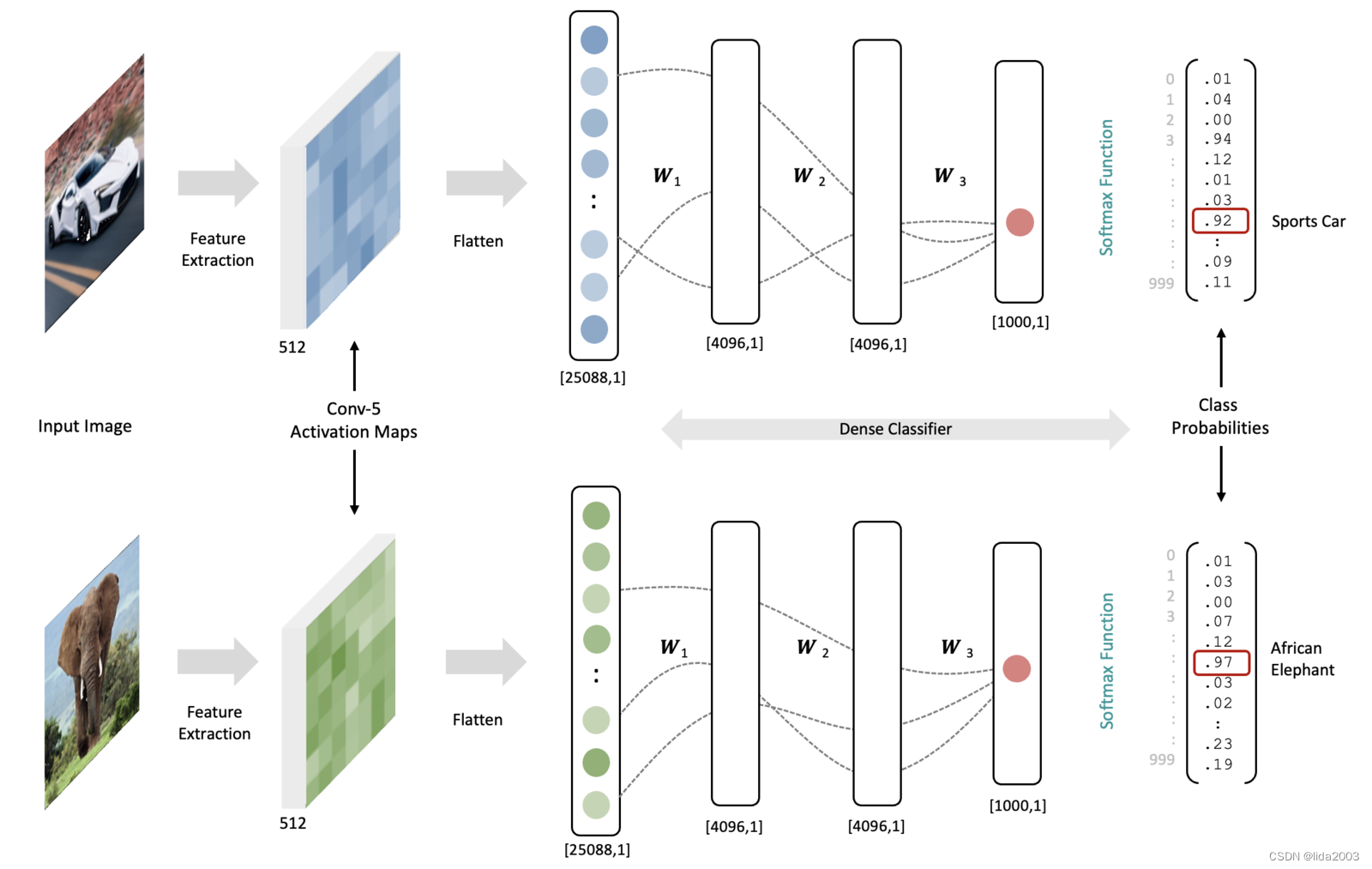
网络中的权重是通过最小化损失函数以有原则的方式训练的,以学习有意义的特征并且“激活”输出层中的适当神经元。这就是这样一个网络将特征映射到类别概率的本质。
3. 总结
从上面的分析和概念,可以看到在全连接层介入之前,更多的是特性提取,更像是从数据中提取特性,这些需要非常专业的知识,而非单纯学习计算机能解决的。
总结一下CCN的主要要点:
- 用于分类任务的CNN包含上游的特征提取器和下游的分类器。
- 特征提取器由具有类似结构的卷积块组成,每个卷积块由一个或多个卷积层后跟一个最大池化层组成。
- 卷积层从前一层中提取特征,并将结果存储在激活图中。
- 卷积层中的滤波器数量是模型架构中的一个设计选择,但滤波器内核的数量由输入张量的深度所决定。
- 卷积层输出的深度(激活图的数量)取决于该层中的滤波器数量。
- 池化层经常用于卷积块的末尾,以缩小激活图。这减少了网络中可训练参数的总数,因此减少了所需的训练时间。此外,这也有助于减轻过拟合。
- 网络的分类器部分使用一个或多个密集连接层将提取的特征转换为类别概率。
- 当类别数量大于两个时,SoftMax层用于将分类器的原始输出归一化到范围[0,1]。这些归一化值可以解释为输入图像对应于每个输出神经元的类别标签的概率。
4. 参考资料
【1】Jammy@Jetson Orin - Tensorflow & Keras Get Started
5. 补充知识 - 卷积核操作
卷积操作是如何执行的。在卷积层中,使用一个小的滤波器来处理输入数据。
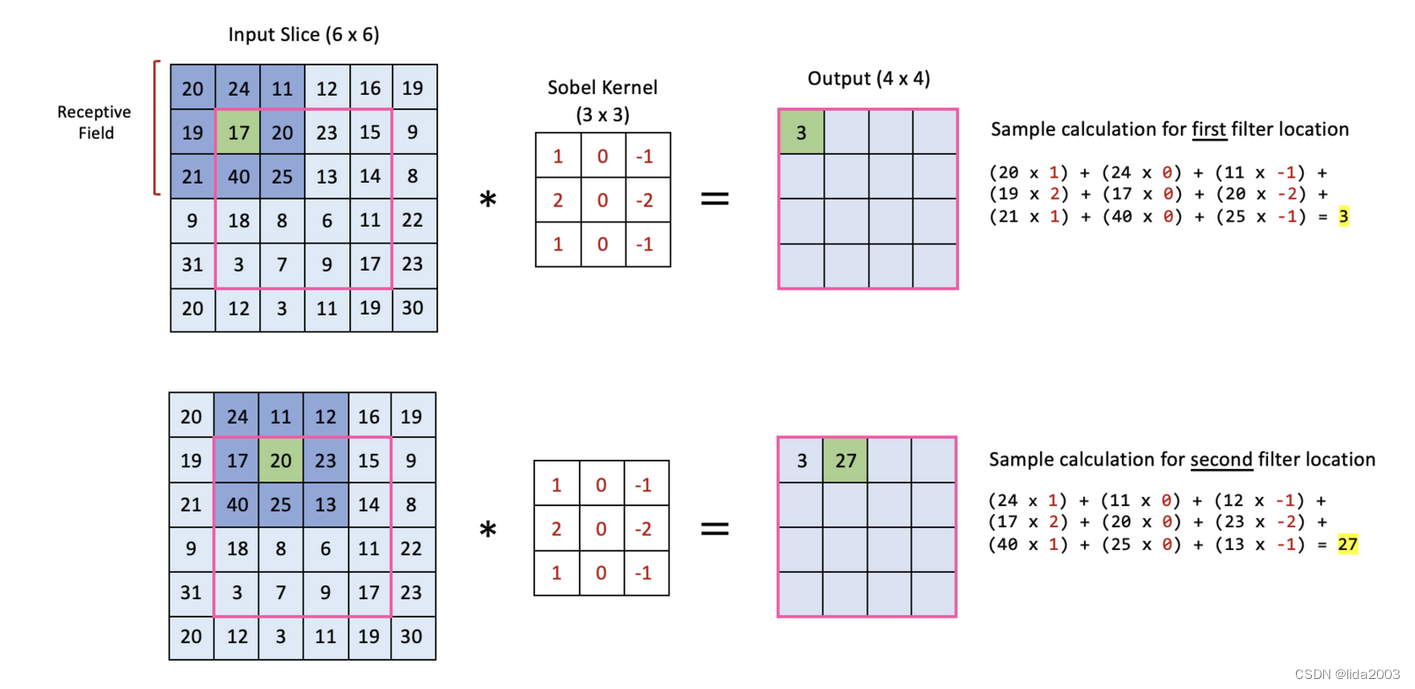
在这个示例中,我们展示了一个(6x6)的输入如何与一个(3x3)的滤波器进行卷积。这里我们展示了在图像处理中经常使用的一个简单滤波器。滤波器中的元素集体称为核。在这里,我们将使用一个在图像处理中经常使用的著名核,称为Sobel核,它被设计用于检测垂直边缘。然而,重要的是要注意,在CNN中,核中的元素是网络在训练期间学习到的权重。
卷积操作包括将核放置在输入的一部分上,并将滤波器的元素与输入的相应元素相乘。得到的值是一个单一的数字,表示给定滤波器位置的卷积操作的输出。该过程通过将滤波器滑动到输入图像上直到滤波器覆盖到每个输入部分为止而重复进行。每次以一像素的步幅滑动滤波器相当于步幅为1。滤波器位置用深蓝色表示。该区域也被称为感受野。请注意,滤波器的中心用绿色标示。在每个滤波器位置执行的卷积操作就是滤波器值与输入数据中感受野中相应值的点积。
以上图例提供了前两个滤波器位置的样本计算,以便您确认对操作的理解。请注意,每个滤波器位置上,操作产生一个单一的数字,放置在输出中的相应位置(即放置在输入切片上的感受野中心对应的输出位置)。
- 卷积操作边缘问题
请注意,卷积的输出具有比输入切片更小的空间尺寸。这与滤波器如何放置在输入上有关,以便它不会延伸到输入的边界之外。然而,通常会使用填充技术来填充输入图像,以使输出与输入的大小相同。使用大于一的步幅也会减小卷积操作的输出大小。然而,在本笔记本的其余部分(为了简单起见),我们将假设填充配置保持卷积层中数据的空间大小不变。所有深度学习框架都提供了处理边界的选项。我们在这里不涵盖这些细节,但您应该知道这些选项是存在的。
- Sobel卷积核示例
展示了网络实例,链接。来看下Sobel核如何检测垂直边缘。
回想一下上面定义的卷积操作是核值与相应输入值的加权和。由于Sobel核在左列具有正值,在中间列为零,在右列具有负值,因此当核从图像的左侧向右移动时,卷积操作是水平方向导数的数值近似,因此产生的输出可以检测到垂直边缘。这是特定核如何检测图像中各种结构(如边缘)的一个例子。其他核可以用来检测水平线/边缘或对角线/边缘。在CNN中,这个概念是泛化的。由于核权重是在训练过程中学习的,因此CNN可以学习检测支持图像分类的许多类型的特征。
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









