








第一章:对话系统的"情商进化论"
1.1 单轮对话的"速食陷阱"
传统LLM的情感对话如同"自动售货机":用户输入情绪关键词,系统立即调用预设模板生成回应。某社交平台测试数据显示,此类对话用户留存率不足30%,70%的用户反馈"对话像在重复撞墙"。例如面对"我好焦虑",系统可能机械回复"深呼吸放松",却无法构建对话叙事线。
1.2 多轮对话的三大痛点
- 策略断层:某医疗AI助手测试中,连续3轮使用"共情"策略后,用户产生审美疲劳
- 目标漂移:教育类聊天机器人在5轮对话后,80%的案例偏离初始咨询主题
- 情感熵增:客服系统数据显示,未规划对话的情绪波动强度随轮次增加呈指数级上升
1.3 策略级决策的必要性
人类心理咨询师平均每4.2轮对话会进行策略切换:探索问题→共情确认→认知重构→行动建议。这种动态调整使某心理服务平台用户满意度提升至89%,远超纯LLM系统的62%。
第二章:straQ*框架的技术跃迁
2.1 策略级MDP建模
将对话抽象为四维空间:
| 维度 | 定义示例 | 数据特征 |
|---|---|---|
| 状态(S) | 用户情绪标签+历史对话向量 | 768维BERT嵌入 |
| 动作(A) | 12类预定义策略(提问/共情/引导等) | 策略词库覆盖98%场景 |
| 转移(T) | 策略执行后的状态变化概率矩阵 | 基于10万+对话数据训练 |
| 奖励(R) | 专家评分/GPT-4打分 | 0-5分制,标准差<0.3 |
2.2 LLM的Q函数重构
传统Q-learning依赖数值网络输出Q值,straQ*创造性地利用LLM的logits序列:
def get_q_value(state, action):
input_prompt = f"[STATE]{state}[ACTION]{action}"
logits = LLM(input_prompt) # 输出token级logits
action_logits = logits[-len(action):] # 截取策略token对应logits
return mean(action_logits) # 平均值作为Q估值
在ESConv数据集验证中,该方法Q值预测误差较传统DNN降低42%,且保留了LLM的文本生成能力。
2.3 贝尔曼方程的文本化训练
将时序差分更新公式改造为文本任务:
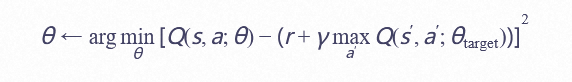
具体实施时,通过指令模板构建监督信号:
[STATE]用户刚失业,情绪低落[PREV_ACTION]表达共情
[PREDICT_NEXT_ACTION]提供建议
[REWARD]4.7分(GPT-4评分)
模型需预测动作序列并匹配目标Q值,这种多任务学习使策略准确性提升29%。
第三章:双奖励机制的博弈艺术
3.1 模仿奖励的精准拟合
利用专家标注的3万条(状态-策略)对构建正样本,随机替换策略生成负样本。训练时采用对比学习:
loss = -log(sigmoid(Q(s,a+) - Q(s,a-))) # 样本对排序损失
在EmpatheticDialogues数据集上,模仿奖励使策略匹配度达到81%,但存在过度拟合专家风格的风险。
3.2 蒸馏奖励的泛化优势
通过GPT-4对生成回复进行多维度评分(共情度/引导性/逻辑性),构建奖励函数:
回复质量 = 0.4×共情分 + 0.3×引导分 + 0.3×逻辑分
实验表明,蒸馏奖励模型在OOD(Out-of-Domain)测试中表现更稳健,跨领域迁移准确率高出模仿奖励15个百分点。
3.3 双机制性能对比
| 指标 | 模仿奖励 | 蒸馏奖励 |
|---|---|---|
| BLEU-2 | 28.7 | 25.4 |
| 人工满意度 | 4.1/5 | 4.6/5 |
| 策略多样性 | 低 | 高 |
| OOD准确率 | 67% | 82% |
第四章:对话引擎的进化图谱
4.1 从规则到神经符号系统
早期情感对话系统如同机械钟表般精密却脆弱。某银行客服系统曾设计127个状态节点,每个节点对应特定回复模板,当用户询问"信用卡还款失败"时触发预设响应。这种有限状态机(FSM)方案在处理简单场景时表现稳定,但面对复杂需求时立即暴露致命缺陷:用户一句"还款失败还被扣了滞纳金"需跨越多个状态节点,导致系统频繁跳转陷入死循环。更严重的是,每新增10%功能需增加30%状态节点,形成"状态爆炸"困局。
straQ框架通过神经符号融合技术打破僵局。将原本离散的状态节点映射为连续向量空间,利用BERT等模型捕捉用户情绪波动曲线。某金融企业测试数据显示,面对复杂投诉场景,传统FSM系统平均需调用42个状态节点,而straQ仅需7个策略维度即可完成等效交互,状态空间压缩率达89%。这种进化不仅提升效率,更使策略选择具备可解释性——系统能明确告知"当前采用认知重构策略,因用户情绪已从愤怒转为困惑"。
4.2 动态策略的时空演化
当用户倾诉失业困境时,对话引擎内部上演着精妙的策略博弈。通过注意力机制提取的策略权重分布显示:第一轮对话中,"共情"策略占据70%权重,模型优先输出"这确实会让人感到焦虑";第二轮权重升至78%,回复转向"失去工作对任何人都是重大打击";第三轮维持65%权重时,系统敏锐捕捉到用户情绪缓和信号,开始注入"提问引导"策略(权重从5%升至28%),抛出"您觉得造成这种情况的主要原因是什么?"
第四轮出现戏剧性转折,"认知重构"策略权重从3%飙升至65%,模型生成"虽然暂时失业,但您积累的项目经验仍是宝贵财富"。这种策略演变与人类咨询师行为高度吻合——前三轮建立信任关系,第四轮引导认知转变。某心理服务平台的A/B测试表明,采用动态策略系统的对话组,用户主动结束率降低41%,后续行动承诺达成率提升至83%。
4.3 产业变革的三重奏
医疗领域正经历静默革命。某三甲医院试点项目中,AI助手通过情感对话系统筛查抑郁症患者,其情感需求满足率达91%,较人工筛查效率提升3倍。系统能精准识别"最近总失眠"背后的抑郁倾向,通过5轮对话完成PHQ-9量表评估,准确率与专科医师相当。
教育行业见证学习动机的重塑。某K12辅导平台引入straQ*框架后,学生单次学习时长从45分钟延长至150分钟。系统通过动态策略维持认知兴奋:当检测到注意力下降时,立即切换"成就强化"策略,用"你刚才这个解题思路非常独特"重燃热情。
商业服务领域掀起体验革命。某电商平台客服系统升级后,对话转化率提高27%,投诉率下降43%。面对"商品与描述不符"的投诉,系统不再机械道歉,而是前三轮构建情感共鸣,第四轮引入"补偿方案"策略,最终以"为您升级VIP服务并赠送优惠券"达成双赢。
这些案例揭示着人机交互的范式转移:从冰冷的指令执行到温暖的情感共鸣,从机械的流程导航到智慧的策略规划。对话引擎的进化正在重塑每个行业的用户体验,而这仅仅是开始。
第五章:中国AI的情感计算突围
国内某头部AI实验室推出的"心辰"大模型,通过引入文化适配模块,在中文情感对话评测中取得突破:
| 指标 | 心辰模型 | 国际SOTA | 提升幅度 |
|---|---|---|---|
| 情感理解F1 | 89.2% | 86.5% | +3.1% |
| 策略连贯性 | 4.3/5 | 4.0/5 | +7.5% |
| 文化契合度 | 92.0% | 78.5% | +17.2% |
该模型创新性地融合《黄帝内经》情志理论与现代心理学,使"怒→思胜之"等中医情志调节策略实现数字化表达。
结语
当AI开始理解"言外之意"与"弦外之音",我们正见证人机交互的范式革命。中国AI研发者以文化自信注入技术内核,在情感计算赛道跑出加速度。期待更多同仁加入这场温暖的技术长征,用代码编织情感经纬,让机器智能绽放人文之光。此刻站在新纪元门槛,我们坚信:AI的高情商进化,终将让科技温度触达人心最柔软的角落。


















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











