




 文章探讨了早期MachineUnlearning中的SISA方法在图神经网络中的局限,并提出GraphEraser框架,通过平衡分片、BLPA和BEKM等策略优化图数据的遗忘学习。着重介绍了基于学习的聚合器LBAggr,以解决传统方法的不足。实验指出有优化空间,尤其是在GCN模型的分片策略上。
文章探讨了早期MachineUnlearning中的SISA方法在图神经网络中的局限,并提出GraphEraser框架,通过平衡分片、BLPA和BEKM等策略优化图数据的遗忘学习。着重介绍了基于学习的聚合器LBAggr,以解决传统方法的不足。实验指出有优化空间,尤其是在GCN模型的分片策略上。
【文章】Graph Unlearning
【来源】ACM SIGSAC 2022
【代码】Github
前言
Unlearning在机器学习中是一个较为“偏门”的方向,与差分隐私这种使用某种噪声算法保护数据隐私的方式不同,Unlearning旨在给出精确节点的确定性遗忘,而与Unlearning正交的差分隐私只能保证用于训练的所有节点的一定概率程度的隐私保证。
也就是说,Unlearning的隐私保护是节点级别的精确的,DP的隐私保护是全数据域级别的近似的。
Machine Unlearning
早年的论文《Machine Unlearning》提出了SISA的思想以实现数据遗忘学习,SISA即分片、孤立、切片、聚合四种思想的结合体。SISA使用了随机分片的概念,保证数据集的每一个分片孤立不相交,对分片再进行切片进行类似统计查询学习的方法迭代进行训练,最后对来自每个分片的后验概率聚合。
现有方法的缺陷
《Graph Unlearning》将SISA引入了图神经网络,并指出了SISA方法的缺陷:
- 随机分片的思想不再适用于图结构数据,甚至会损伤数据集的图结构信息;
- 原有的聚合方法大多是后验概率的平均聚合或多数投票,无法注意到分片相对于全局的重要程度。
本文的方法
文章提出了一个通用的用于图结构数据的遗忘学习框架GraphEraser,如图所示:
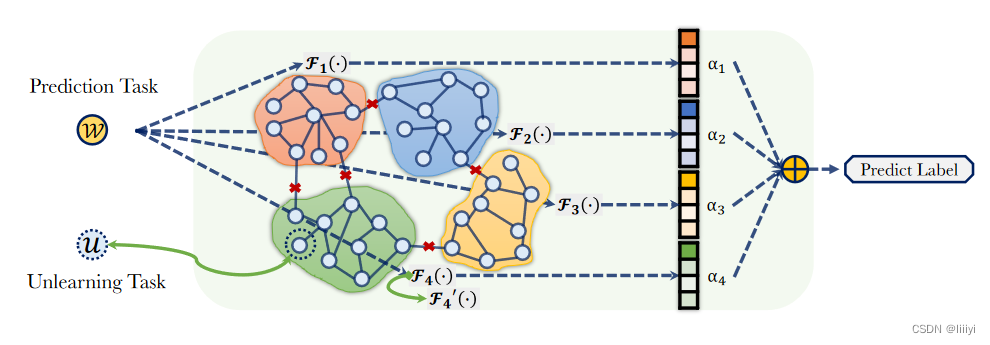
GraphEraser首先将数据平衡分片为
k
k
k个分片,
S
=
{
S
1
,
…
,
S
k
}
S=\{S_1,\dots,S_k\}
S={S1,…,Sk},对每个分片
S
i
S_i
Si训练出一个模型
M
i
M_i
Mi。
- 当一个节点 v i v_i vi产生预测请求时,将节点发送到每一个分片模型。每一个模型会给出当前节点的后验概率,对这些后验概率聚合后得出最终节点分类的预测结果;
- 当一个节点 v u v_u vu产生遗忘请求时,系统首先确定 v u v_u vu所在的分片模型,重新训练该分片模型(如果 v u v_u vu被用于计算分片重要度评分,则会重新计算该项)。
平衡分片
平衡分片旨在控制每个分片的大小一致,使得不会因为某个分片太大或太小而导致对不同节点的遗忘效率相差过大。
文章针对不同的GNN模型提出了不同的分片方法。提出了几种策略:1)只考虑节点特征;2)只考虑图结构信息;3)同时兼顾节点特征和图结构信息。策略1关注传统的多层神经网络,策略2关注GCN,策略3关注除GCN外的其他GNN模型。
BLPA
BLPA是对传统标签传播算法LPA的平衡优化,归属于Community Detection范畴。加入了一个分片的最大承受限度参数。当分片中的节点数量饱和后,本应该分配到该分片的节点将会被分配到节点次临近的分片当中,以此类推。
具体的算法不再赘述。BLPA专为GCN设计,由于GCN完全关注图结构信息,而BLPA也是完全根据图结构信息进行社区发现的,所以作者认为这种方法更适配。(这里笔者复现的实验效果与原文差距过大,这一部分在文章最后讨论)
BEKM
BEKM是对K-Means算法的平衡优化,属于图聚类范畴。同样加入了一个分片的最大承受限度参数,具体原理和BLPA控制分片大小的方法相似。
如算法所示,首先初始化
k
k
k个聚类中心,进行
T
T
T轮分配。每一轮分配中每一个节点都会趋向于寻找自己欧氏距离最近的聚类中心点,如果该聚类簇已达到最大承受限度,则节点会分配到次临近的聚类簇中,以此类推。每完成一轮聚类后对聚类中心点进行重新计算,如果聚类中心点不再变化或达到最大迭代次数
T
T
T后,BEKM算法终止。
基于学习的聚合LBAggr
文章提出了一种基于学习的自适应聚合器,为每个分片模型分配一个重要性分数(权重),通过损失函数进行学习:

其中
X
w
X_w
Xw和
N
w
N_w
Nw分别是训练图中节点
w
w
w的特征向量和邻域,
y
y
y是
w
w
w的真实标签,
F
i
(
⋅
)
F_i (·)
Fi(⋅)表示分片模型
M
i
M_i
Mi,
α
i
α_i
αi是
F
i
(
⋅
)
F_i (·)
Fi(⋅)的重要性分数,
m
m
m是分片的总数。
权重计算本需所有分片的所有节点都参与计算,但会导致每进行一次遗忘操作就需要完全重新计算分片权重,会消耗大量时间。作者发现只使用10%节点计算权重就可以达到全部节点参与计算的效果。
整合
整个框架的算法如下:

首先进行平衡图分片,如果是GCN则使用BLPA,如果是除GCN外的其他GNN模型使用BEKM。随后对每个分片训练一个模型,并计算每个模型的重要度评分
α
\alpha
α。
Evaluation
略。
讨论
- 笔者使用文章中给出的开源链接进行了实验,代码不是很完整,需要自己摸索。笔者遇到了以下一些问题,大部分都解决了:1)文章给出的GNN模型可能有点问题,有的无法运行,有的跑出来F1极低,笔者重新写了GNN模型的代码;2)实验参数略复杂,需要自己研究;3)部分功能需要自己修改(如做图嵌入时使用SAGE的中间层输出结果,这一部分一直报错),有的被注释掉了;4)MIAs攻击的代码貌似有问题,测试集后验的传入数据没有使用,这个笔者研究了下实在弄不懂。
- GraphEraser算是在GNN领域遗忘学习研究的开山之作,是一个较为基础的研究成果,并没有作太多的优化,后续可以在分片方法和聚合方法上进一步优化,解决文中提出的GCN用BEKM方法分片导致F1分数低的问题。
- 笔者使用自己写的GCN模型使用文章的BEKM方法进行分片,使用LBAggr聚合所得到的F1分数与其他模型相当,并没有出现文中分数极低的现象,可能是网络层不一样的缘故??
总之,文章给出的代码着实有些乱套,需要研究一阵子才能知道是怎么一个run的流程,还有许多没有用的py文件杵着。从横向看,这篇文章提出的方法依然属于SISA类别的变种优化,其中的LBAggr可以延伸到非图结构的数据中。

















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









