







目录
2.3. Improving Perceptual Quality
Abstract
从混合图像中分离单个图像层长期以来一直是一项重要且具有挑战性的任务。作者提出一个统一的框架——“深度对抗分解”。作者在对抗训练范式下处理线性和非线性混合。考虑到分离模糊的问题,引入了“分离评论家”——一个判别网络,它被训练来识别输出层是否分离良好,从而进一步改善分离情况。作者提出一个新的损失函数——“crossroad L1”,它以交叉方式计算无序输出与其参考之间的距离,实现像素级的监督,更好地指导训练。实验结果表明,该方法明显优于其他流行的图像分离框架。在没有特定调整的情况下,该方法在多个计算机视觉任务上取得了最先进的结果,包括图像去雨、照片反射去除和图像阴影去除。
论文pdf:Deep Adversarial Decomposition: A Unified Framework for Separating Superimposed Images
1. Introduction
作者认为,在计算机视觉领域,许多任务可以被视为图像层混合/分离问题。 例如:雨天拍照时,得到的图像可以看作是雨痕层和干净的背景层的混合。透过透明玻璃看时,是玻璃外的场景和玻璃反射的场景的混合。(p.s. 这个想法有东西啊,借鉴这种想法,很多东西都变的简单了,学到了学到了)
作者提出新的分离框架,如下图所示,它在统一框架下可以处理透明分离、阴影去除、去雨等所有任务。

常规的图像分离需要先验知识,但这些先验知识没有很好的普适性。所以作者利用GAN实现了从数据获得先验知识,从一个完全不同的角度重新审视先验。作者引入了一个“Separation-Critic”——一个判别网络 ,它被训练来识别输出层是否分离良好。
Crossroad loss函数。除了 Critic 之外,我们还引入了一个层分离器
并对其进行训练,以最小化分离输出与真实参考之间的距离。然而,标准的
或
损失不适用于我们的任务,因为
可以预测无序输出。因此,作者引入了“crossroad
”损失,它以交叉方式计算输出与其参考之间的距离。通过这种方式,可以通过像素级监督来很好地指导训练。
在一些现实世界的图像分离任务中,图像的混合通常是非线性的。例如,反射图像的形成不仅取决于相机与图像平面的相对位置,还取决于光照条件 。此外,过度曝光和噪声可能会进一步增加分离的难度。在这些情况下,人们可能需要在算法中注入“imagination想象力”来恢复退化数据的隐藏结构。作者引入了两个马尔可夫判别器(PatchGAN)来提高输出的感知质量。
实验结果表明,该方法明显优于其他流行的图像分离框架。在没有特别调整的情况下,在三个不同任务的九个数据集上实现了最先进的结果,包括图像去雨、照片反射去除和图像阴影去除。这是解决这些问题的第一个统一框架,因为之前针对这些任务的大多数解决方案都是单独研究和设计的。
2. Methodology
在对抗性损失的帮助下,我们将模型的训练构建为像素级回归过程。 我们的方法由一个图像分离器 、一个分离评价器
和两个马尔可夫鉴别器
和
组成。

2.1 Crossroad 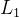 Loss Function
Loss Function
假设 和
代表两个单独的图像,
代表它们的混合。 我们假设操作
是未知的,可以是线性或非线性混合函数。 给定混合输入
,我们的分离器旨在预测两个单独的输出
和
:
我们训练分离器 以最小化其输出 (
,
) 和它们的真实值 (
,
) 之间的距离。标准像素级
或
损失函数不会 适用于我们的任务。 这个问题的解决方案是引入可以处理无序输出的新损失函数。 因此,我们为我们的任务提出了一种称为“crossroad
”损失的新损失函数(通过交换输出的顺序来交叉计算距离),然后将它们的最小值作为最终响应:
我们使用 而不是
,因为
更少的鼓励模糊,因此训练
以最小化整个数据集的
:
表示图像数据的分布
2.2. Separation Critic
考虑到层的模糊性,我们没有将任何手工制作的或基于统计的约束应用于我们的输出空间,而是通过对抗性训练过程先学习分解。因此,我们引入了一个“Separation-Critic” ,它被训练来区分输出
和一对干净的图像
,并且与两个输入的顺序无关。我们将其目标函数表示如下:
请注意,当用假样本训练 时,除了分解的输出
,我们还通过混合两个干净的图像来合成一组假图像
, 具有随机线性权重 α 以增强其对混合图像的判别能力:
在 的输入端,我们简单地在通道维度上将两个图像连接在一起,以对它们的联合概率分布进行建模。
和
的对抗训练本质上是一个极小极大优化过程,其中
试图最小化这个目标,而
试图最大化它:

作者比较了图像分离的不同分解先验,包括“排除损失”、“峰度”和提议的“分离-批评”。 对于三个指标中的任何一个,较低的分数表示较重的混合。 在子图 (a) 中,绘制了给定一组基于等式合成的混合输入的三个指标的响应。 显然,如果一个度量足够好,那么响应应该随着 α 的增加而单调递减。 我们还测试了其他非线性退化,包括 (b) 过度曝光、(c) 随机伽马校正和 (d) 随机色调变换。四个例子说明 Critic 的有效性、鲁棒性,尤其是对于非线性退化。
2.3. Improving Perceptual Quality
为了提高分解图像的感知质量,我们进一步引入了另外两个条件鉴别器 和
来增强高频细节。
和
两个局部感知网络——仅惩罚 patch 规模的结构(又名马尔可夫鉴别器或“PatchGAN”)。
和
尝试分类图像中的每个 N × N 块是原图像(真)还是分解图像(假)。 这种类型的架构可以通过构建一个具有 N × N 感知域的卷积网络来实现。我们将
和
的目标表达如下:
,我们最终的目标函数定义如下:
鉴别器损失前面的系数是为了平衡整个损失函数,我们目标是:
2.4. Implementation Details
在设计分离器 的架构时,遵循 “UNet” 的配置。我们将
、
和
构建为具有 4、3 和 3 个卷积层的三个标准 FCN。
和
的感知域设置为 N = 30。我们将
的输入调整为相对较小的尺寸,例如 64 × 64,以捕获整个图像的语义,而不是添加更多层。 我们不在
中使用批量归一化,因为它可能会引入意外的工件。 作为我们的默认设置,batch_size = 2 和 learning_rate = 0.0001 的 Adam 优化器训练,共200epoch。 我们为前 10 个epoch中
,剩下的epoch中
。
3. Experimental Analysis
本文在四个任务上评估我们的方法:
叠加图像分离

图像去雨

图像反射去除


图像阴影去除

















 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









