






一、引言
在上一篇《DeepSeek-R1 + Open-WebUI 双系统部署全攻略》中,我们完成了从零搭建AI对话平台的“基建工程”——无论是Linux还是Windows环境,你都能一键部署Open-WebUI,开启与AI的交互之旅。但真正的“魔法”,始于你登录系统后的第一眼界面。
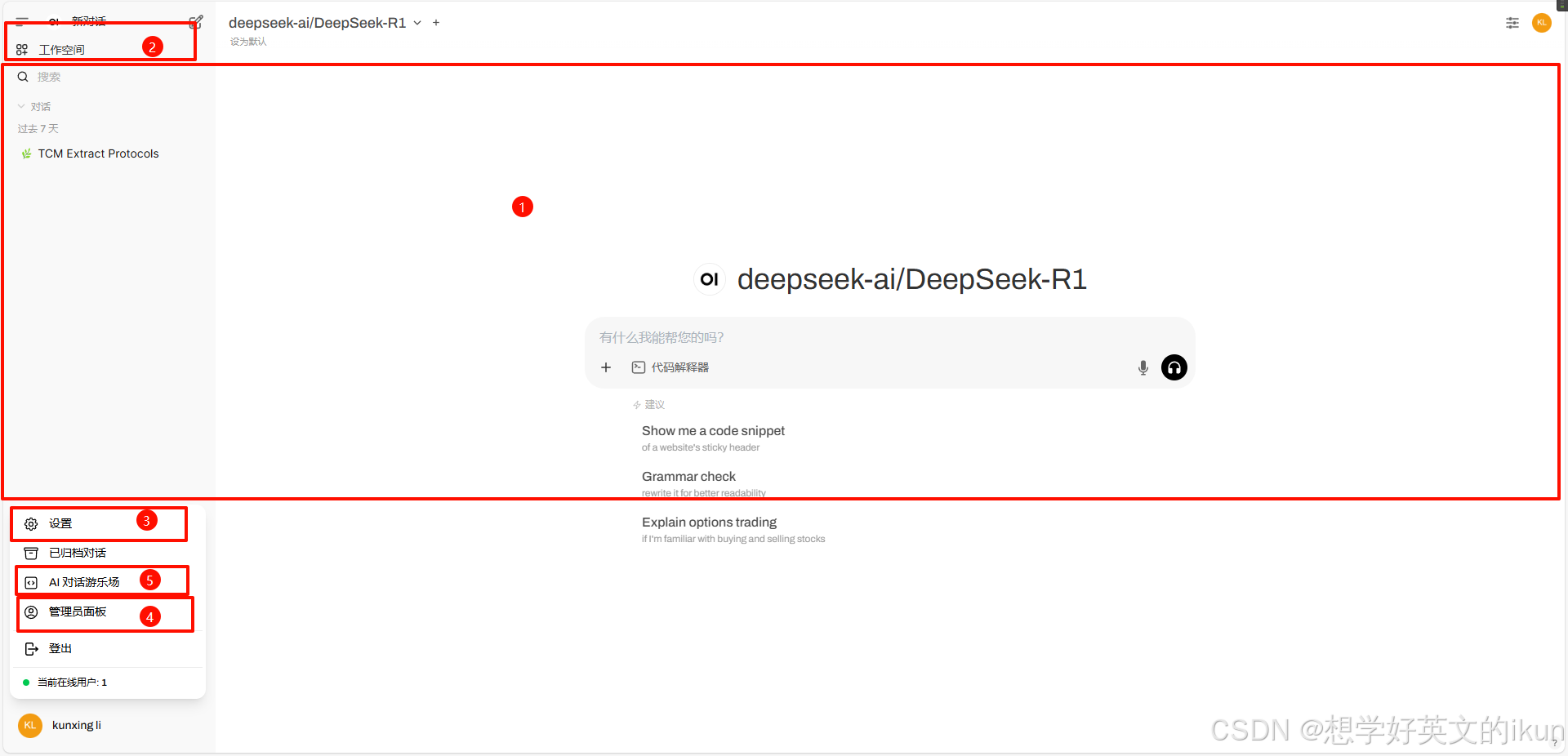
作为一款开源AI对话平台,Open-WebUI 以极简的设计隐藏了强大的功能架构。整个界面可划分为五大核心功能区:
- 💬对话区: 实时交互的主战场,支持多模态输入、历史对话回溯与Prompt工程调试;
- 🧰工作空间区: 文件管理、代码执行、插件扩展的“生产力工具箱”;
- 🎭用户设置区: 个性化角色定义、隐私控制与交互偏好调节;
- 🧠管理员面板: 系统的“中枢神经”,掌控用户权限、模型配置与安全防线;
- 🎪AI对话游乐场: 零代码模型微调与多模型对比测试的实验场。
本文将作为《Open-WebUI五大功能区深度解析》系列的首篇,结合2025年最新版本的功能升级,手把手拆解管理员面板,助你从“能用”进阶到“敢用”,打造安全、高效、可扩展的AI管理后台。
二、用户

2.1 概述
- 用户列表: 展示所有用户信息,支持搜索功能
- 添加用户: 支持手动添加和CSV文件导入

- 删除用户: 支持删除非管理员用户
- 修改用户信息: 支持修改用户名称、密码信息,也可以修改非管理员角色的邮箱
- 查看对话: 支持查看非管理员角色的所有对话信息
2.2 权限组
该权限组主要是管理用户角色的用户权限,所有的用户角色会有一组默认的权限

- 编写默认权限: 支持对默认的权限进行修改
- 创建权限组: 创建一个新的权限组,支持修改权限,添加用户角色的用户;注: 如果一个用户拥有多个权限组,将取权限的并集
三、竞技场评估

竞技场评估是 Open-WebUI 的 “模型质检中心”,通过自动化对抗与量化分析,它能将抽象的模型能力转化为直观的决策依据。无论是新模型上线前的性能验证,还是生产环境中多模型的动态优化,这一功能都能通过自动化对抗测试与量化评估,帮你精准把控模型表现,避免“人工盲目调优”的陷阱。
使用方式: 在聊天过程中,如果您喜欢某个回复,点击竖起大拇指,如果您不喜欢,点击向下大拇指。
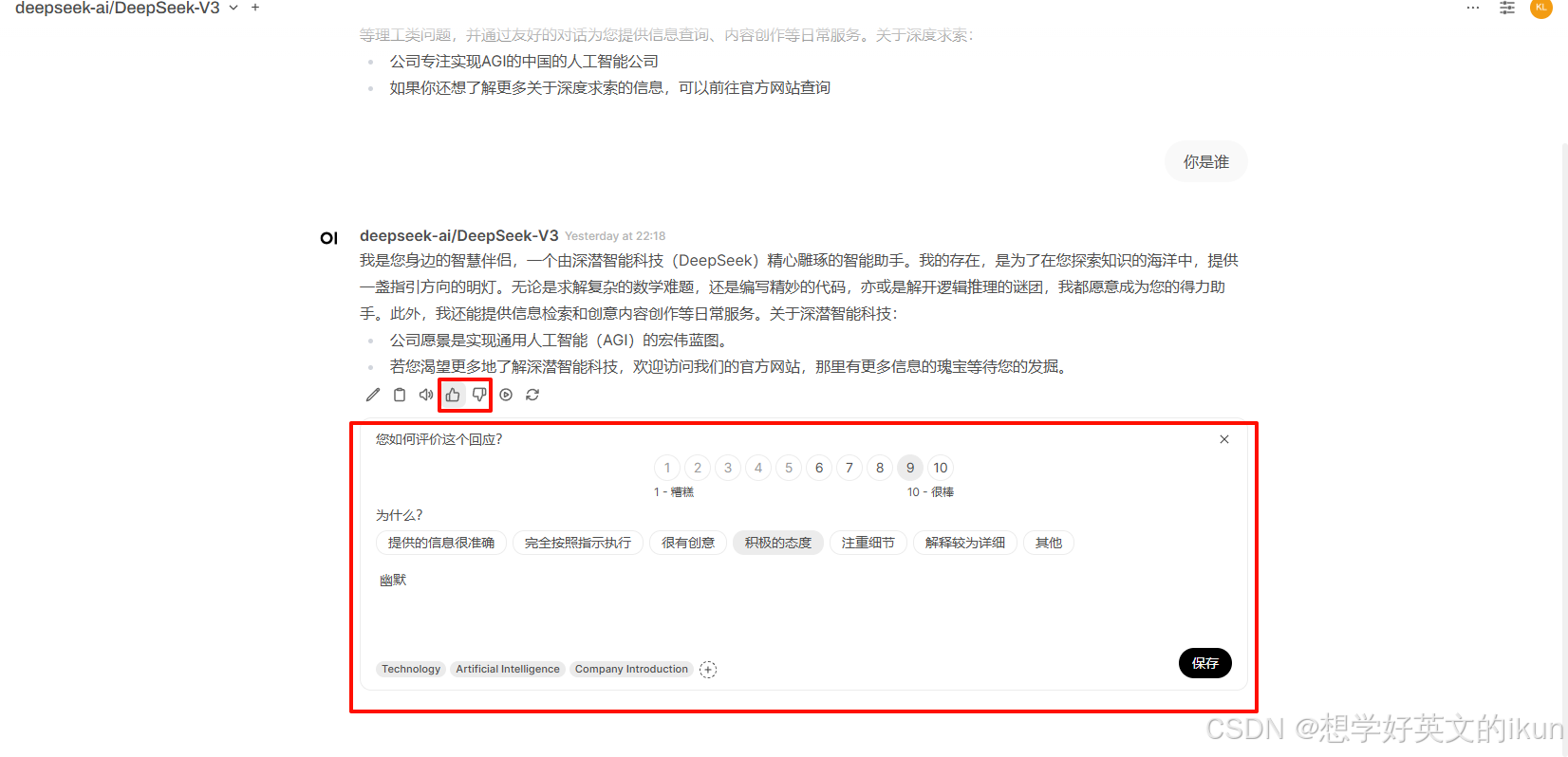
Open-WebUI的官方说明是:

四、函数
函数与工作空间中的工具模块是类似的,属于 Open-WebUI 的增强扩展功能,我们放到工作空间部分一起讲解。
五、设置
5.1 通用
5.1.1 身份验证
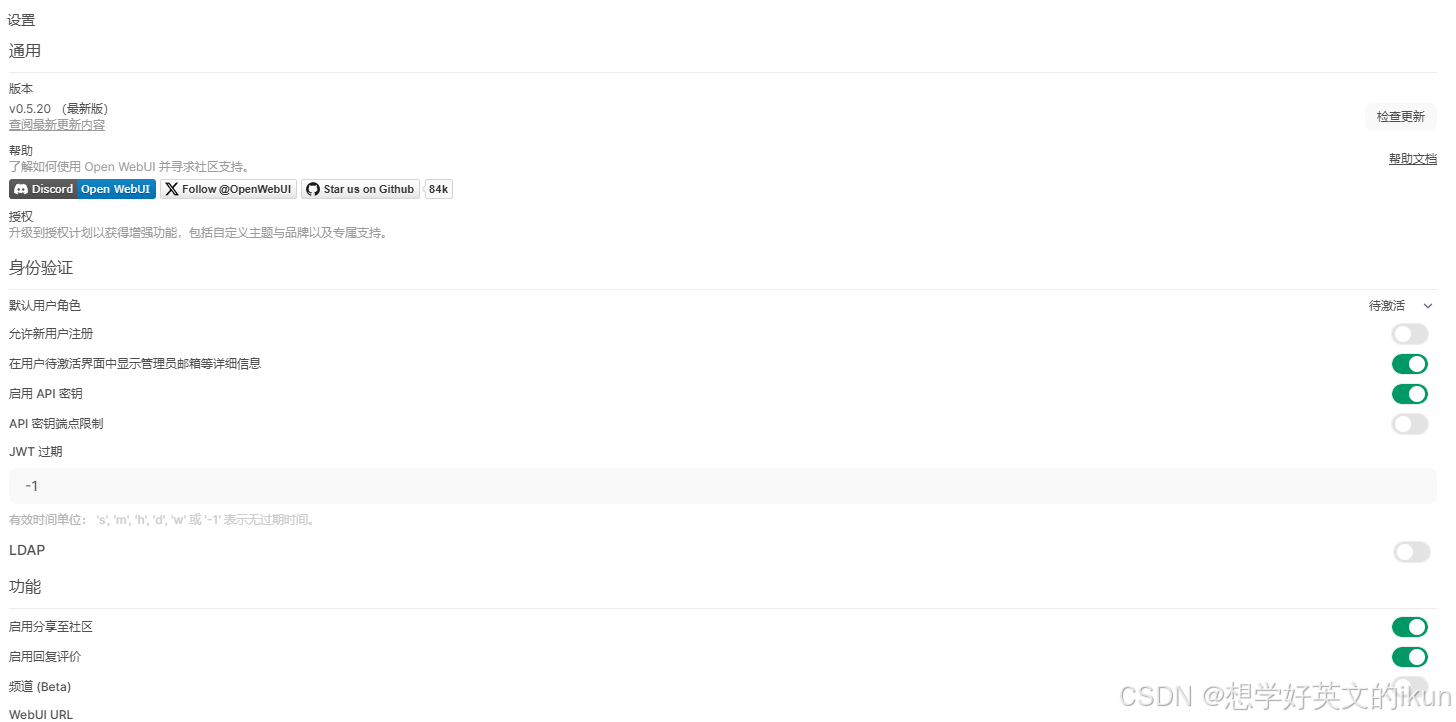
- 默认用户角色: 用户注册时分配的角色,有待激活、用户、管理员三个角色;待激活表示注册后,不能立即使用此系统,需要管理员确认后才能使用;用户表示注册后,能立即使用此系统,但没有管理员权限;管理员表示注册后,拥有所有功能权限;
- 允许新用户注册: 是否允许新用户通过页面注册;如果是内部系统一般是关闭的,只允许管理员手动新增的用户使用;
- 在用户待激活界面中显示管理员邮箱等详细信息: 方便联系管理员进行授权;
- 启用 API 密钥: 控制第三方应用在调用Open-WebUI的API时是否需要加上API秘钥(秘钥在项目启动时设置)
- API 密钥端点限制: 默认对所有API端点启用秘钥限制,可通过该项控制范围;
- 允许的端点: 允许的端点不做秘钥限制,其它端点做秘钥限制;
- JWT 过期: 管理用户登录令牌的有效期、刷新机制,默认-1表示无过期时间;
- LDAP: LDAP(轻量级目录访问协议)是 Open-WebUI 实现企业级用户统一认证的核心模块;
- 标签(Label):用于标识不同的 LDAP 服务器实例(如测试环境与生产环境);如:ad-corp-prod
- 主机(Host):LDAP 服务器地址,支持 IP、域名或完整 LDAP URI;如:ldap://ad.example.com
- 端口(Port):标准值389:常规 LDAP 或 StartTLS 加密(先明文连接后升级加密);
- Application DN(绑定 DN):用于向 LDAP 服务器认证的管理账号 DN,需具备目录搜索权限;如:uid=admin,ou=system,dc=example,dc=com
- Application DN 密码: 一般使用 Vault 或 KMS 动态获取;
- 邮箱属性(Email Attribute): 将 LDAP 中的某属性映射到 Open-WebUI 邮箱属性;如:mail
- 用户名属性(Username Attribute): 将 LDAP 中的某属性映射到 Open-WebUI 用户名属性;如:employeeNumber
- 搜索库(Base DN): 限定用户搜索的起始目录节点,提升查询效率;如:ou=users,dc=example,dc=com
- 搜索过滤器(Search Filter): 基于 LDAP 查询语法,支持逻辑运算符与占位符;如:搜索仅启用状态用户使用(&(objectClass=user)(!(userAccountControl:1.2.840.113556.1.4.803:=2)))
- 传输层安全协议: 是否启用
- 证书路径(Certificate Path): SSL/TLS 连接时验证服务器身份,防止中间人攻击;如:CA 证书的路径等
- 加密算法(Encryption Algorithm): 如 AES-GCM 算法等
5.1.2 功能
- 启用分享至社区: 是否允许将会话内容分享到 Open-WebUI 社区;
- 启用回复评价: 是否允许对模型回复进行评价(喜欢或踩);
- 频道 (Beta): 是否开启频道,频道是 Open-WebUI 2025 版新增的 Beta 功能,用于集成外部消息服务,实现双向通信与自动化事件响应能力;
- Webhook URL: Webhook URL 是 Open-WebUI 向外部系统(需支持 Webhook)推送事件数据(目前只支持推送新用户注册事件)的 HTTP 端点;
- WebUI URL: 当前 Open-WebUI 的访问地址,用于在外部系统消息中生成链接,接收通知后,能快速跳转;
5.2 外部连接

外部连接是 Open-WebUI 与外部/内部大模型连接的核心枢纽,分为与外部大模型连接的OpenAI API 配置和与内部(本地)大模型连接的 Ollama API 配置。
5.2.1 OpenAI API
-
功能定位: 通过 OpenAI 官方 API 或兼容接口(如硅基流动、DeepSeek、讯飞星火等)接入 GPT-4、DeepSeek-R1 等云端模型;如下图:成功接入了硅基流动、DeepSeek、讯飞星火等云端服务;

-
配置画面: 如图
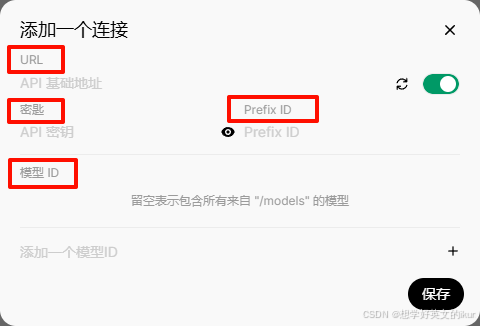
注: 配置完后,点击 “循环按钮” 进行验证,验证通过会出现下图1提示,验证不通过会出现下图2提示;如果出现错误提示,请检查配置是否正确,如果都正确还是报错误提示,说明 Open-WebUI 暂时不兼容该云端平台;


- URL: API 端点地址;例:针对硅基流动的文档说明,配置 /chat/completions 前面的部分 https://api.siliconflow.cn/v1,因为 Open-WebUI在聊天请求URL上默认加 /chat/completions
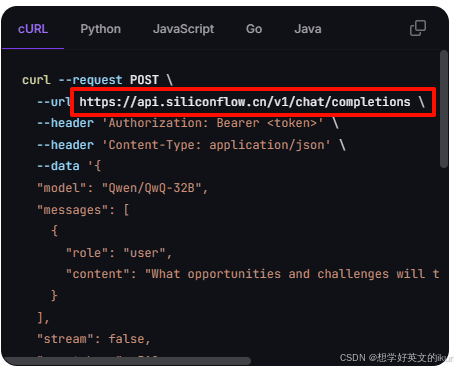
- 秘钥: OpenAI 官方密钥或兼容服务的认证密钥;例:一般为 sk- 开头
- Prefix ID: 用于过滤模型,过滤出带有 Prefix ID 前缀的模型,默认不过滤;
- 模型 ID: 手动添加指定模型,默认添加全部;
- URL: API 端点地址;例:针对硅基流动的文档说明,配置 /chat/completions 前面的部分 https://api.siliconflow.cn/v1,因为 Open-WebUI在聊天请求URL上默认加 /chat/completions
5.2.2 Ollama API
-
功能定位: 管理本地部署的开源模型(如 LLaMA 3、DeepSeek-R1等)

-
配置画面: 如图
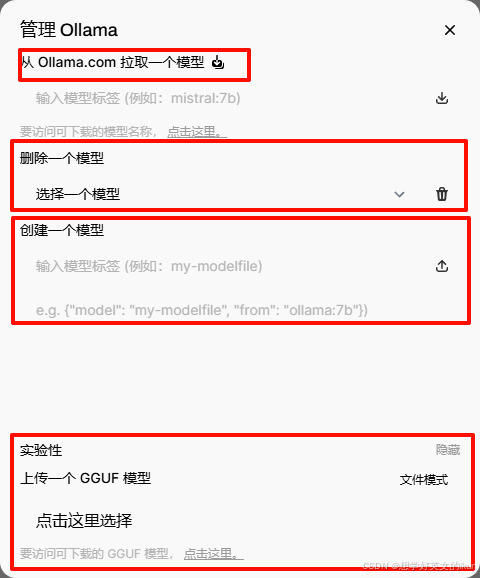
- 拉取模型: 从Ollama官网上实时拉取一个模型,相当于执行了 ollama pull 命令;
- 删除模型: 删除本地的一个模型,相当于执行了 ollama rm 命令;
- 创建模型: 从本地复制一个模型或拉取一个远程模型再复制,相当于执行了 ollama cp 命令;
- 上传GGUP模型: 本地运行一个GGUF文件并创建一个新模型;
5.2.3 直接连接
- 功能定位: 允许其他用户(主要是非管理员角色)连接至其自有的、兼容 OpenAI 的 API 端点。
5.3 模型

- 模型列表: 针对上述 5.2 外部连接 配置的成功连接,管理的所有大模型列表,并支持搜索功能;如:博主配置三个 OpenAI API 与 Ollama API 管理的本地模型一共87个模型
- 模型启用: 是否启用模型,供聊天时选择使用;
- 模型管理: 与上述 5.2.2 Ollama API 配置一致;
- 设置: 手动对模型列表进行排序;
- 模型编辑: 对模型配置扩展属性;
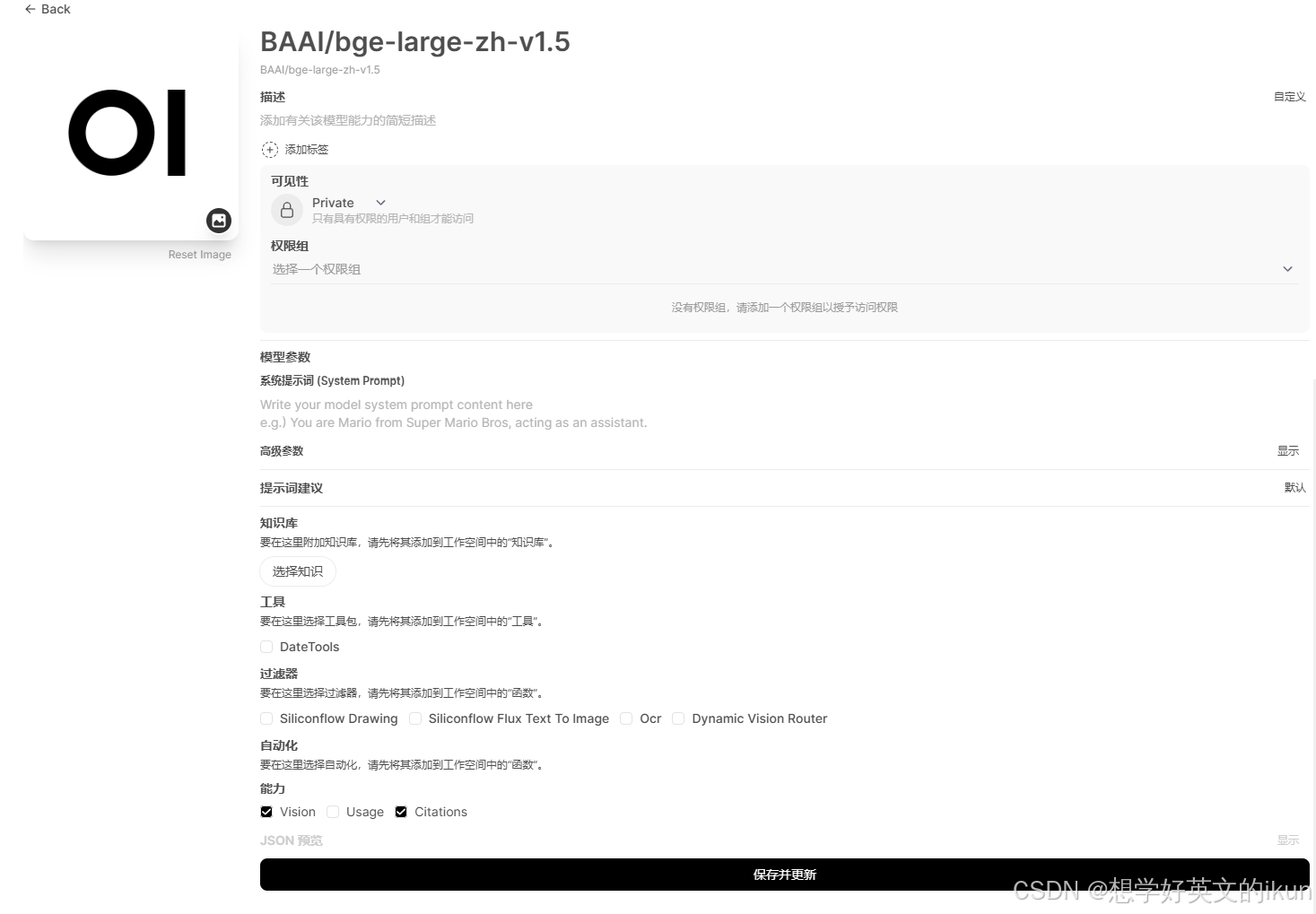
- 更换模型图像: 可上传本地图片替换默认模型图片;
- 更换模型名称: 可修改为自己偏好的模型名称;
- 添加标签: 可对模型添加额外标签,供模型搜索时使用;
- 可见性: public(所有人可见)、 private(与权限组一起使用,不配置权限组将只有管理员可见);
- 系统提示词: 给模型添加系统提示词;
- 高级参数: 与模型聊天时各种调优参数;对话区有相同配置,我们放到对话区一起详细讲解;
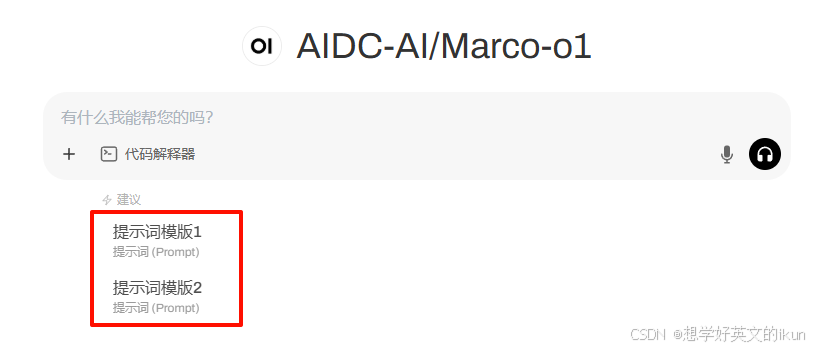
- 提示词建议: 给模型添加默认提示词模版;效果如下:
8. 知识库: 给模型添加关联知识库(知识库配置在工作空间中讲解);使用这个模型时,一定会在关联的知识库中检索内容,作为提问的一部分(RAG);
9. 工具: 给模型添加关联工具(工具配置在工作空间中讲解);使用这个模型时,会选择性使用关联的工具辅助大模型完成回答任务;
10. 过滤器(FILTER): 给模型添加关联过滤器(过滤器是函数的一部分,过滤器配置在工作空间中讲解); 使用这个模型时,一定会使用关联的过滤器(一般对聊天内容进行过滤);
11. 自动化(PIPE): 给模型添加关联操作函数(自动化是函数的一部分,自动化配置在工作空间中讲解);使用这个模型时,一定会使用关联的自动化
12. 能力: Vision(是否支持图像输入)、Usage(是否展示本次响应的 Token 使用信息)、Citations(是否展示知识库引用)
5.4 竞技场评估

- 启用竞技场匿名评价模型: 是否开启模型评价功能(不开启将不展示大拇指功能)
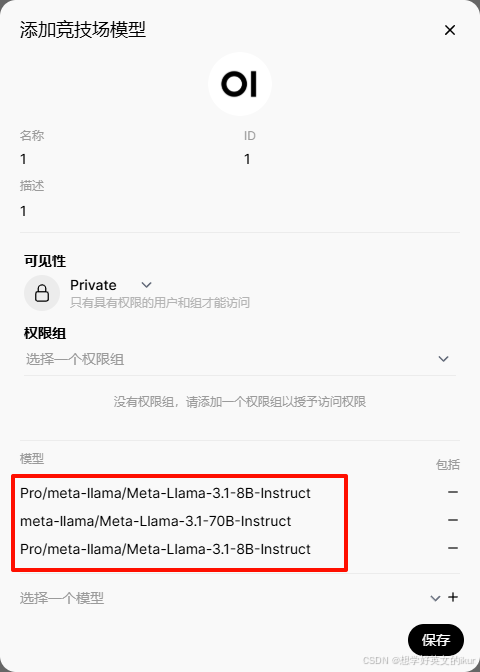
- 添加竞技场模型: 因考虑到模型评价功能有热点倾向,不太公平;故可添加竞技场模型,选中几种模型(图中选中三个),在使用这个新增模型时,会随机选择模型回答,此时看不到具体的模型,这样评价更具有公平性;
5.5 文档(RAG)
5.5.1 通用
- 内容提取引擎:
| 引擎 | 技术原理 | 优势场景 | 限制条件 |
|---|---|---|---|
| 默认 | 基于 Python 标准库解析文本,支持 PDF、DOCX、TXT 等常见格式 | 轻量快速,适合基础文档处理 | 无法处理复杂表格、扫描件图像文字提取 |
| Tika(推荐) | 通过 Java 服务解析 1500+ 种文件格式,支持 OCR 和元数据提取 | 企业级文档处理(如扫描件、邮件存档) | 需部署独立 Tika 服务器,资源消耗较高 |
| Document Intelligence | 微软 Azure 认知服务,提供结构化数据提取(如发票字段、合同条款) | 合规性敏感场景(金融、法律文档解析) | 依赖云端 API,存在数据出境风险 |
注: Tika 服务部署,请使用以下命令
docker run -d --name tika \
-p 9998:9998 \
--restart unless-stopped \
apache/tika:latest-full
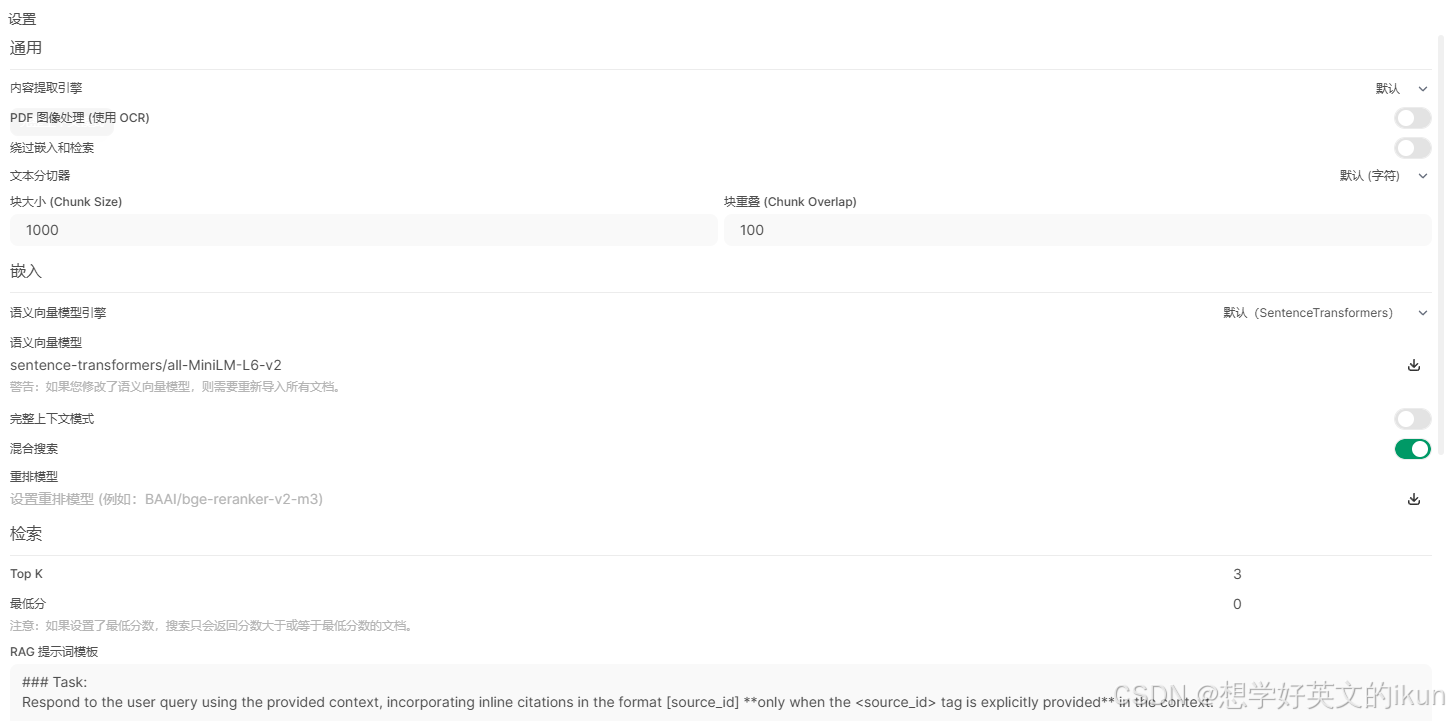
- PDF 图像处理 (使用 OCR): 只有选择默认内容提取引擎时使用(默认引擎无OCR,如文档中有图片,务必开启此项);
- 绕过嵌入和检索: 开启时,不会将文档分块存储为向量,而是在提问时,将整个文档发送给大模型(会有 Token 消耗过大和大模型不支持过多 Token 的风险,一般是在极小文档场景下使用);
- 文本分切器:
| 参数 | 定义 | 计算公式 | 企业级配置示例 |
|---|---|---|---|
| 分切模式 | 默认(字符):按固定字符长度切割 Token(Tiktoken):基于模型分词器(如LLaMA、BGE)的语义边界切割 | Token数 = 块大小 / 平均中文字符长度(≈2) | 中文场景优先选择 Token 分切 |
| 块大小 | 单个文本块的最大长度,需 ≤ 语义向量模型支持的 Max Tokens(如 bge-m3 支持 8192) | - | 中文模型推荐 512-1024 |
| 块重叠 | 相邻块之间的重叠量,用于保留上下文关联性 | 块大小 × 10%~20% | 块大小 1024 → 重叠 100-200 |
5.5.2 嵌入
- 语义向量模型引擎:
| 引擎类型 | 技术栈 | 典型模型 | 延迟/成本 |
|---|---|---|---|
| Ollama | 本地部署,支持私有化向量模型 | bge-m3、nomic-embed-text、Conan-embedding | 低延迟,硬件资源消耗高 |
| SentenceTransformers | Hugging Face 模型库,会到下载到本地cache目录 | all-MiniLM-L6-v2、multilingual-e5 | 下载依赖网络带宽,建议手动下载后放到cache目录中 |
| OpenAI | 云端 API 服务 | text-embedding-3-small/large | 高延迟,按 Token 计费 |
-
语义向量模型: 根据语义向量模型引擎选择填写
-
Ollama: 比如 Ollama 下载了这几个模型,直接使用 bge-m3:latest 即可
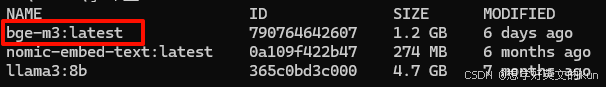

-
SentenceTransformers: 如自己手动下载到本地,务必放到容器内的 /app/backend/data/cache/embedding/models 目录下且以 models-- 命令开头;

-
OpenAI: 比如使用硅基流动的 BAAI/bge-m3 向量(嵌入)模型,配置如下:


注: 如果修改了语义向量模型,则需要重新导入所有文档(重置向量存储/知识)。
-
-
嵌入层批处理大小: 一次性使用向量模型处理文档的数量大小;
-
完整上下文模式: 是否将整篇文档都发送给大模型(会有 Token 消耗过大和大模型不支持过多 Token 的风险,一般是在极小文档场景下使用);
-
混合搜索: 是否开启重排模型;重排模型作用:对语义检索结果的 Top K 条目进行二次排序,解决以下问题:
- 语义漂移: 检索结果与意图表面相似但实际无关;
- 多模态干扰: 图文混合内容中的噪声过滤;
- 长尾分布: 低频但高相关性的内容提升权重;
-
重排模型: 重排模型名称,与上述 SentenceTransformers 模式一致,建议手动下载;
5.5.3 检索
- Top K: 语义检索初步结果数量(需 ≥ 最终输出条目);
- RAG 提示词模板: 整合用户提示词和搜索到的知识库内容,最终发送给大模型的消息内容模版;
5.5.4 文件
- 最大上传大小: 每次聊天中上传的文件最大大小(MB),不影响知识库上传的文件大小;
- 最大上传数量: 每次聊天中上传的文件最大数量,不影响知识库上传的文件数量(由嵌入层批处理大小控制);
5.5.5 集成
-
Google 云端硬盘: 集成 Google OAuth 客户端,拉取客户端中的文件作为知识库(监听文件变动事件,5分钟间隔);
- 创建Google OAuth 客户端: https://support.google.com/cloud/answer/6158849?hl=en;
- 修改 Open-WebUI 配置: 进入 Open-WebUI 内容器的 /app/backend/open_webui 目录下,修改 config.py 文件;
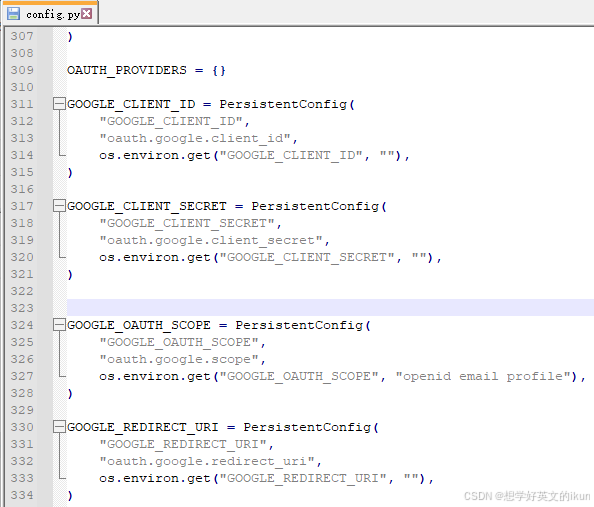
- 重启 Open-WebUI: 使用 docker 命令重启 Open-WebUI 即可;
- 创建Google OAuth 客户端: https://support.google.com/cloud/answer/6158849?hl=en;
-
OneDrive: 集成 OneDrive 客户端,拉取客户端中的文件作为知识库(每日 2:00 全量同步);
5.5.6 危险区域
- 重置上传目录: 删除知识库中所有的目录;
- 重置向量存储/知识: 删除知识库中所有的文档;
5.6 联网搜索
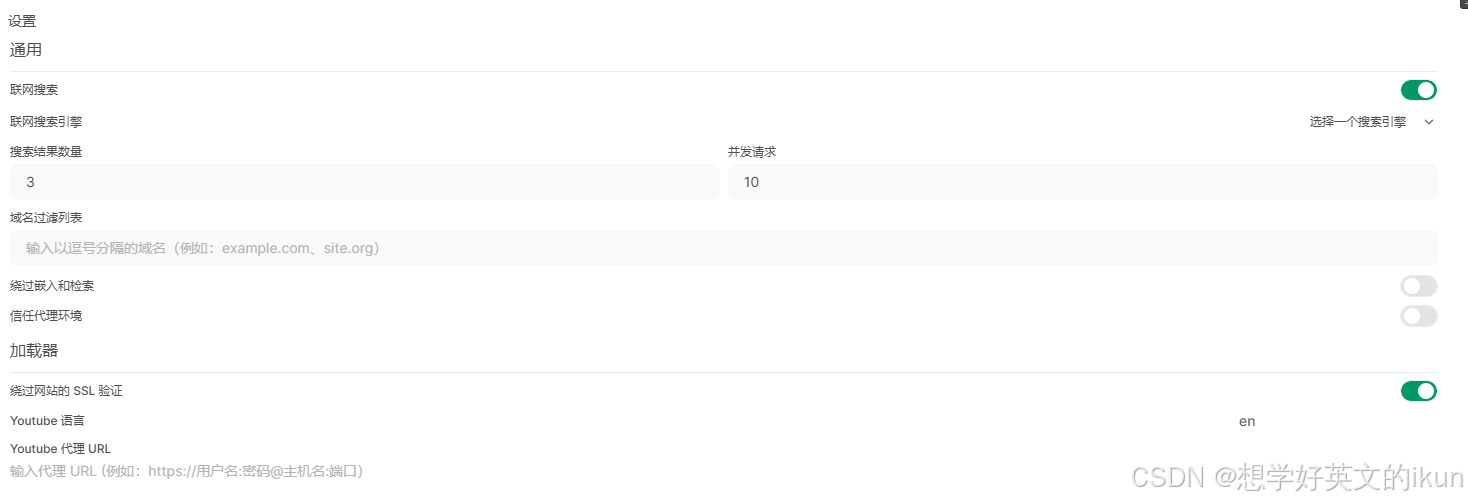
支持丰富的搜索引擎,请参考官方文档;
5.7 代码执行
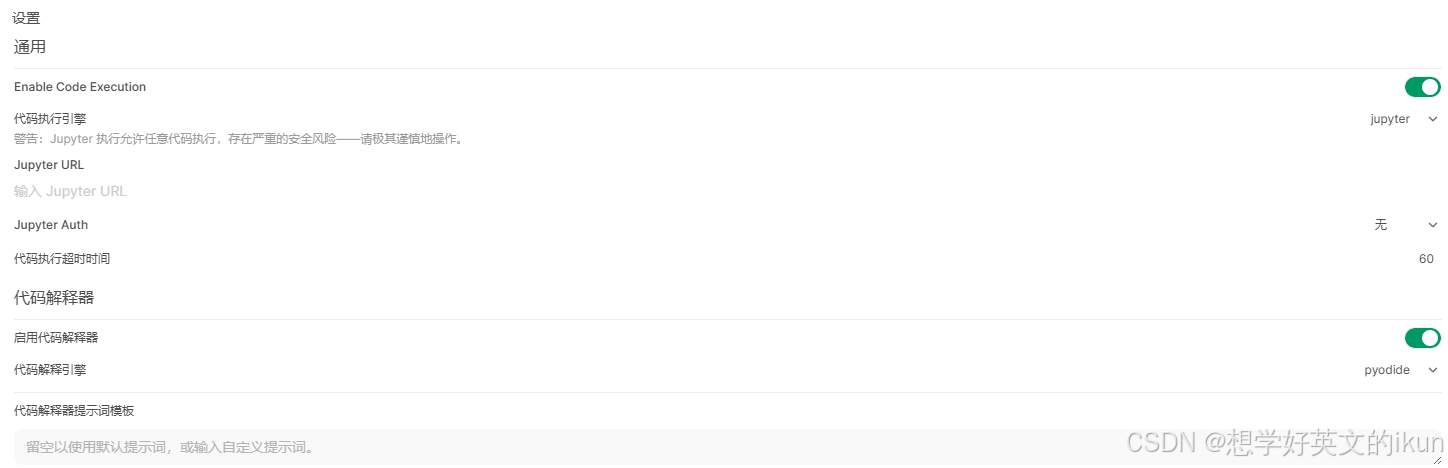
5.7.1 通用
- 功能定位: 用于在AI对话中直接运行大模型回答的代码片段(如Python脚本);
- 启用代码执行器: 是否启用代码执行器;不启用,将隐藏运行按钮;
- 代码执行引擎:
- Pyodide: 基于浏览器的 Python 运行时环境,无需服务器支持;
局限性:无法访问本地文件系统,仅支持纯 Python 库; - Jupyter: 需配置 Jupyter Notebook 服务以实现完整代码执行能力;
优势:支持复杂计算、文件操作及第三方库调用;
注: Jupyter 服务部署,请使用以下命令docker run -p 8888:8888 swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/jupyter/tensorflow-notebook:cuda-latest
- Pyodide: 基于浏览器的 Python 运行时环境,无需服务器支持;
- 代码执行超时时间: 达到超时时间(S),将终止代码运行;
5.7.2 代码解释器
-
功能定位: 用于解析AI生成的代码逻辑(如数学运算、数据处理);
-
启用代码解释器: 是否启用代码解释器;不启用,将隐藏代码解释器按钮;
-
代码解释引擎:
- Pyodide: 快速解析简单代码片段;
- Jupyter: 需连接服务以处理复杂逻辑分析;
-
代码解释器提示词模板: 预置的提示词模板用于规范AI生成代码的格式与交互逻辑;示例模版:
def user_code(): {user_input} # 用户代码占位符 result = user_code() print(result)
5.8 界面

5.8.1 任务
-
设置任务模型: 用于对话标题和 Web 搜索查询生成等任务的默认模型设置;它的默认模版为:
### Task: Generate a concise, 3-5 word title with an emoji summarizing the chat history. ### Guidelines: - The title should clearly represent the main theme or subject of the conversation. - Use emojis that enhance understanding of the topic, but avoid quotation marks or special formatting. - Write the title in the chat's primary language; default to English if multilingual. - Prioritize accuracy over excessive creativity; keep it clear and simple. ### Output: JSON format: { "title": "your concise title here" } ### Examples: - { "title": "📉 Stock Market Trends" }, - { "title": "🍪 Perfect Chocolate Chip Recipe" }, - { "title": "Evolution of Music Streaming" }, - { "title": "Remote Work Productivity Tips" }, - { "title": "Artificial Intelligence in Healthcare" }, - { "title": "🎮 Video Game Development Insights" } ### Chat History: <chat_history> {{MESSAGES:END:2}} </chat_history>- 本地模型: 选择一个 Ollama 部署的本地模型;
- 外部模型: 选择与 OpenAI 兼容的终端节点外部模型;
-
标题生成: 是否开启对话标题自动生成功能;
-
用于自动生成标题的提示词: 自动生成对话标题的提示词模版,也就是修改上述任务的默认模版;
-
标签生成: 是否开启对话标签自动生成功能;它的默认模版为:
### Task: Generate 1-3 broad tags categorizing the main themes of the chat history, along with 1-3 more specific subtopic tags. ### Guidelines: - Start with high-level domains (e.g. Science, Technology, Philosophy, Arts, Politics, Business, Health, Sports, Entertainment, Education) - Consider including relevant subfields/subdomains if they are strongly represented throughout the conversation - If content is too short (less than 3 messages) or too diverse, use only ["General"] - Use the chat's primary language; default to English if multilingual - Prioritize accuracy over specificity ### Output: JSON format: { "tags": ["tag1", "tag2", "tag3"] } ### Chat History: <chat_history> {{MESSAGES:END:6}} </chat_history> -
标签生成提示词: 自动生成对话标签的提示词模版,也就是修改上述标签的默认模版;
-
检索查询生成: 是否开启文档检索(RAG)功能;
-
网页搜索关键词生成: 是否开启联网搜索查询功能;
-
查询生成提示词: 用于根据对话内容检测是否需要进行联网搜索功能;它的默认模版为:
### Task: Analyze the chat history to determine the necessity of generating search queries, in the given language. By default, **prioritize generating 1-3 broad and relevant search queries** unless it is absolutely certain that no additional information is required. The aim is to retrieve comprehensive, updated, and valuable information even with minimal uncertainty. If no search is unequivocally needed, return an empty list. ### Guidelines: - Respond **EXCLUSIVELY** with a JSON object. Any form of extra commentary, explanation, or additional text is strictly prohibited. - When generating search queries, respond in the format: { "queries": ["query1", "query2"] }, ensuring each query is distinct, concise, and relevant to the topic. - If and only if it is entirely certain that no useful results can be retrieved by a search, return: { "queries": [] }. - Err on the side of suggesting search queries if there is **any chance** they might provide useful or updated information. - Be concise and focused on composing high-quality search queries, avoiding unnecessary elaboration, commentary, or assumptions. - Today's date is: {{CURRENT_DATE}}. - Always prioritize providing actionable and broad queries that maximize informational coverage. ### Output: Strictly return in JSON format: { "queries": ["query1", "query2"] } ### Chat History: <chat_history> {{MESSAGES:END:6}} </chat_history> -
输入框内容猜测补全: 是否开启输入框内容自动补全功能;

-
输入框内容猜测补全输入最大长度: 自动生成自动完成的输入长度;-1 表示无限制,正整数表示具体限制;
-
用于生成图像提示词的提示词: 用于根据对话内容检测是否需要生成图像功能;它的默认模版为:
### Task: Generate a detailed prompt for am image generation task based on the given language and context. Describe the image as if you were explaining it to someone who cannot see it. Include relevant details, colors, shapes, and any other important elements. ### Guidelines: - Be descriptive and detailed, focusing on the most important aspects of the image. - Avoid making assumptions or adding information not present in the image. - Use the chat's primary language; default to English if multilingual. - If the image is too complex, focus on the most prominent elements. ### Output: Strictly return in JSON format: { "prompt": "Your detailed description here." } ### Chat History: <chat_history> {{MESSAGES:END:6}} </chat_history> -
工具函数调用提示词: 用于根据对话内容检测是否需要调用工具和函数功能;它的默认模版为:
Available Tools: {{TOOLS}} Your task is to choose and return the correct tool(s) from the list of available tools based on the query. Follow these guidelines: - Return only the JSON object, without any additional text or explanation. - If no tools match the query, return an empty array: { "tool_calls": [] } - If one or more tools match the query, construct a JSON response containing a "tool_calls" array with objects that include: - "name": The tool's name. - "parameters": A dictionary of required parameters and their corresponding values. The format for the JSON response is strictly: { "tool_calls": [ {"name": "toolName1", "parameters": {"key1": "value1"}}, {"name": "toolName2", "parameters": {"key2": "value2"}} ] }
5.8.2 界面
- 公告横幅: 主页面的横幅提示配置(Markdown语法),效果如下:

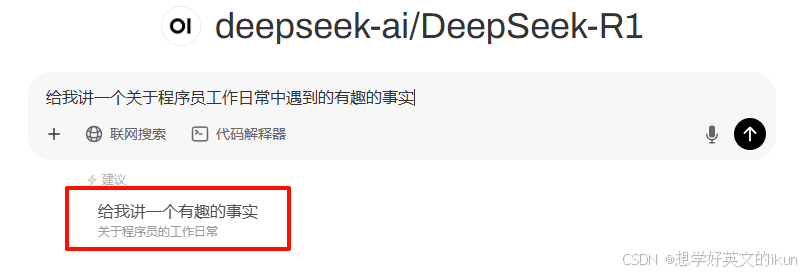
- 默认提示词建议: 用于开启新会话时,默认提示词模版建议,效果如下:

5.9 语音
5.9.1 语音转文本设置
- 语音转文本引擎:
- Whisper(本地): Open WebUI 内置了 faster-whisper,可查看Hugging Face使用相关模型:
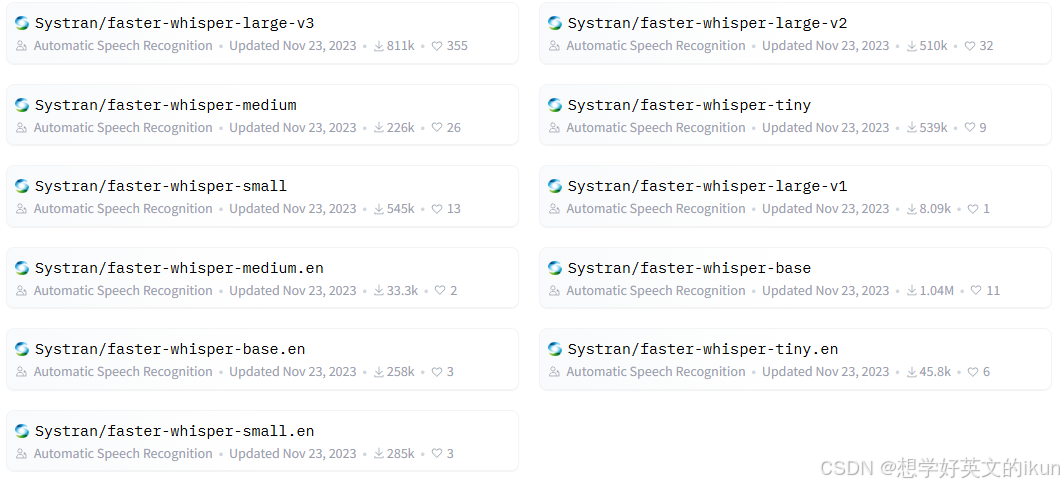
建议手动下载到本地,然后放到到容器内的 /app/backend/data/cache/whisper/models 目录下且以 models–Systran–faster–whisper 命令开头;

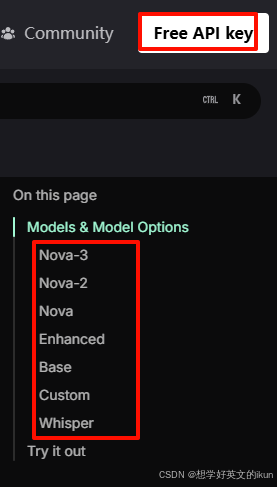
- Deepgram: 实时流式处理语音平台,可在 DeepGram官网 申请免费API key 和选择模型;
- OpenAI: 通过 OpenAI 官方 API 或兼容接口(如硅基流动、讯飞星火等)接入云端模型;
- 网页API: 使用当前浏览器的语音转文本功能,需浏览器授权麦克风权限;
- Whisper(本地): Open WebUI 内置了 faster-whisper,可查看Hugging Face使用相关模型:
5.9.2 文本转语音设置
- 文本转语音引擎:
- 网页API: 使用当前浏览器的文本转语音功能,需选择音色;
- Transformers(本地): Open WebUI 集成了 SpeechT5 和 CMU Arctic speaker embedding,可在 SpeechT5 和 CMU Arctic speaker embedding 选择模型;
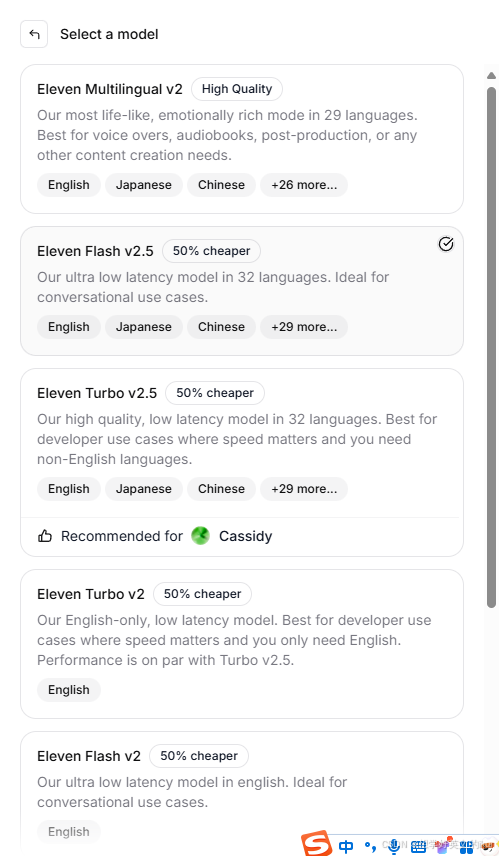
- ElevenLabs: 可在ElevenLabs官网 申请API key 和选择模型;
- Azure AI: 可在Azure官网 申请API key 和选择模型;
- OpenAI: 通过 OpenAI 官方 API 或兼容接口(如硅基流动、讯飞星火等)接入云端模型;
5.9.3 拆分回复
| 拆分模式 | 处理逻辑 | 适用场景 | API限制规避 |
|---|---|---|---|
| Punctuation | 按。!?切分 | 实时对话 | 避免单次请求超30s |
| Paragraphs | 按空行切分 | 长文本朗读 | 符合章节结构 |
| 无 | 原始文本 | 技术文档 | 需前置分句处理 |
5.10 图像

- 图像生成: 是否开启在对话中生成图像功能;
- 图像提示词生成: 是否开启生成图像提示词模版;开启,将使用模版判断是否生成图像;不开启,通过大模型判断,这种情况,大模型需是多模态的;
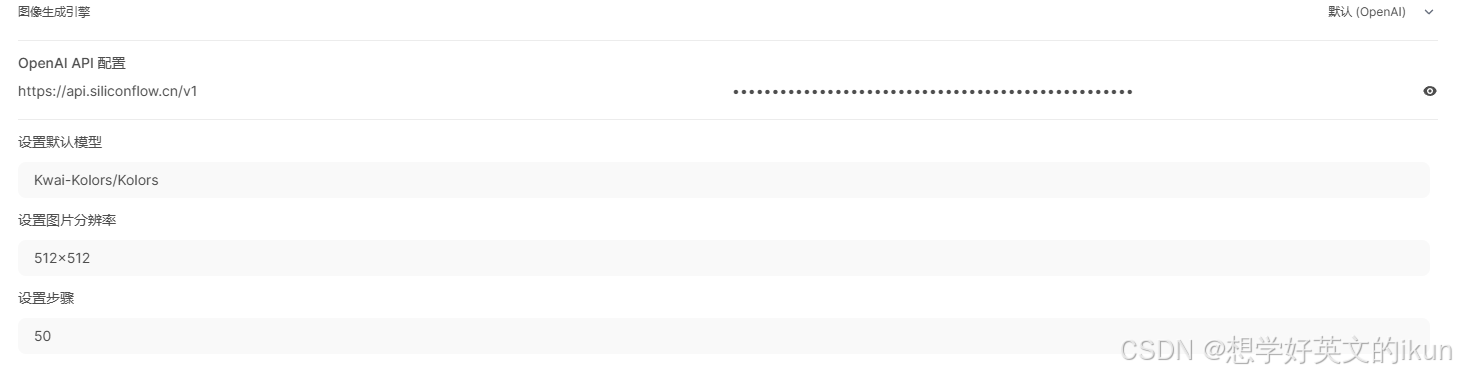
- 图像生成引擎: 可根据不同的引擎,配置参数,如下图采用硅基流动的生图模型配置为:
5.11 Pipeline
- Pipeline是本地开发函数与工具的调试窗口,我们放到工作空间部分一起讲解。
5.12 数据库

这里的数据库主要是完成数据迁移功能,比如前期搭建了 Open-WebUI 测试环境且完成了配置调试,现在开始搭建正式环境且需要将测试环境中的配置数据同步到正式环境中;此时,先在测试环境中的数据库栏选择《导出配置信息至JSON文件中》会下载一个JSON文件,然后在正式环境中的数据库栏选择《导入JSON文件中的配置信息》选择刚才导出的JSON文件,即可完成配置迁移;
六、总结
管理员面板的配置内容就到这里了,经过详细配置,你的AI管理中枢已解锁🎉🎉🎉
💡 趣味冷知识
当你在配置页面点了第100次"保存"时,后台代码会偷偷播放一段《黑客帝国》经典BGM —— 不信试试看?🎵
🚧 下一站预告
《【2025保姆级】Open-WebUI五大功能区首曝!第二篇:工作空间区打造AI协作中枢,手把手搭建多模态作战室&团队协作全流程拆解》 即将上线!

















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









