









由于工作忙,好久没有更新博客啦,最近在做对象检测方面的项目,现将知识在此梳理下。
刚开始接触Yolov3是在Ubuntu环境下跑的官方demo,然后训练自己的数据集,得到权重文件,网上相关教程很多,不难实现。但是由于项目在Windows上实现的,因此特地在Win10环境下使用C++、OpenCV进一步实现。
实验环境:Win10+VS2015+OpenCV3.4.5
一、原理介绍
(1)OpenCV3.3.1版本开始正式支持Darknet网络结构,并且支持Yolov1,Yolov2以及Yolov3 Tiny网络模型的导入与使用,支持C/C++/Python,但是在OpenCV中,YOLO只是前馈网络,只支持预测,不能训练,是一种比SSD还要快的对象检测网络模型,该算法的作者在其论文中提到其FPS是Fast R-CNN的100倍。是一种端到端的目标检测模型,算法基本思想是:首先通过特征提取网络对输入图像提取特征,得到特定大小的特征图输出。输入图像分成13×13的grid cell,接着如果真实框中某个object的中心坐标落在某个grid cell中,那么就由该grid cell来预测该object。每个object有固定数量的bounding box,YOLO v3中有三个bounding box,使用逻辑回归确定用来预测的回归框。它是one-stage系检检测算法的鼻祖,即只通过一个stage就直接输出bbox和类别标签:
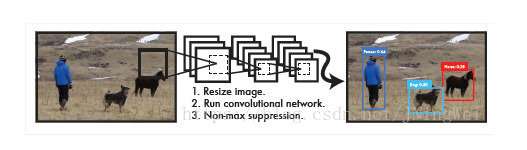
(2) YOLOv3仅仅是作者近一年的一个工作报告(TECH REPORT),不算是一个完整的paper,因为他们实际上是把其它论文的一些工作在YOLO上尝试了一下。相比YOLOv2,我觉得YOLOv3最大的变化包括两点:使用残差模型和采用FPN架构。YOLOv3的特征提取器是一个残差模型,因为包含53个卷积层,所以称为Darknet-53,从网络结构上看,相比Darknet-19网络使用了残差单元,所以可以构建得更深。另外一个点是采用FPN架构(Feature Pyramid Networks for Object Detection)来实现多尺度检测。YOLOv3采用了3个尺度的特征图(当输入为416×416时):(13×13) ,(26×26) ,(52×52)。
(3)从YOLO的三代变革中可以看到,在目标检测领域比较好的策略包含:设置先验框,采用全卷积做预测,采用残差网络,采用多尺度特征图做预测。
二、基于OpenCV实现YOLOv3
- 加载网络模型和分类信息
//Give the configuration and weight files for the model
String modelConfiguration = "..\\model\\yolov3.cfg";
String modelWeights = "..\\model\\yolov3.weights";
// Load names of classes
string classesFile = "..\\model\\coco.names";
ifstream ifs(classesFile.c_str());
string line;
while(getline(ifs, line))
{
classes.push_back(line);
}
//Load the network
Net net = readNetFromDarknet(modelConfiguration, modelWeights);- 加载测试图像
//Load test image
Mat frame = imread("..\\image\\test2.jpg");
//start time
start = clock();
//Create a 4D blob from a frame. 创建神经网络输入图像
blobFromImage(frame, blob, 1 / 255.0, cvSize(inpWidth, inpHeight), Scalar(0, 0, 0), true, false); blobFromImage()函数主要用来对图片进行预处理。包含两个主要过程:
(1)整体像素值减去平均值(mean)
(2)通过缩放系数(scalefactor)对图片像素值进行缩放
3. 将测试图片输入网络
//Sets the input to the network 设置输出
net.setInput(blob);- 检测显示与保存
//Runs the forward pass to get output of the output layers 获取输出层结果
vector<Mat> outs;
net.forward(outs, getOutputsNames(net));
//Remove the bounding boxes with low confidence
postprocess(frame, outs);
finish = clock();
cout << "Run time is " << double(finish - start) / CLOCKS_PER_SEC << endl;
//Put efficiency information. The function getPerfProfile returns the overall time for inference(t) and the timings for each of the layers(in layersTimes)
//输出前向传播的时间
vector<double> layersTimes;
double freq = getTickFrequency() / 1000;
double t = net.getPerfProfile(layersTimes) / freq;
string label = format("Inference time for a frame : %.2f ms", t);
putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 255));
imshow("result", frame);
//保存图像
imwrite("..\\image\\result.jpg", frame);5.运行效果

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











