






新的优化框架有助于将公平性约束纳入机器学习模型中。

公平是一个非常主观的概念,在机器学习方面也是如此。 通常,我们认为裁判在失去一场近场比赛时对我们最喜欢的球队"不公平",或者当我们走上终点时,任何结果都是极其"公平"的。 鉴于机器学习模型不能依赖主观性,我们需要一种有效的方法来量化公平性。 在这一领域已经进行了很多研究,其中大多数将公平性作为结果优化问题。 最近,Google AI研究开放了Tensor Flow Constrained Optimization Library(TFCO)的开源,该优化框架可用于优化机器学习模型(包括公平性)的不同目标。
引入公平性的问题是机器学习模型远非易事。 在最近的Apple Card案例中可以看到一个非常公开的例子,其中算法显示出强烈的性别偏见。 考虑处理银行贷款申请的类似模型。 该模型是否应根据错误的标准进行优化,以向可能支付或最小化拒绝贷款的客户发放贷款。 哪个标准成本更高? 模型能否针对两个结果进行优化? 这些问题是TFCO设计的核心。
TFCO理论
TFCO的工作方式是围绕给定模型的目标强加"公平约束"。 在我们的银行贷款示例TFCO中,我们将选择一个目标函数,该函数对奖励给将要偿还贷款的人的贷款模型进行奖励,并且还将施加公平性约束,以防止它不公平地拒绝向某些受保护的人群提供贷款。 TFCO通过利用称为"代理拉格朗日优化"的高度复杂的博弈论来实现这一目标。
Google Research和康奈尔大学最近的合作概述了代理拉格朗日优化技术的思想。 核心原则侧重于优化模型中的拉格朗日乘数。 这些乘数是一种策略的基础,该策略用于寻找受等式约束(即,必须通过所选变量值精确满足一个或多个方程式的条件)的函数的局部最大值和最小值。 基本思想是将约束问题转换为某种形式,以便仍然可以应用无约束问题的导数检验。
拉格朗日乘子定理粗略地指出,在也满足等式约束的函数的任何固定点上,该点处函数的梯度可以表示为该点处约束梯度的线性组合,并带有拉格朗日乘子 充当系数。
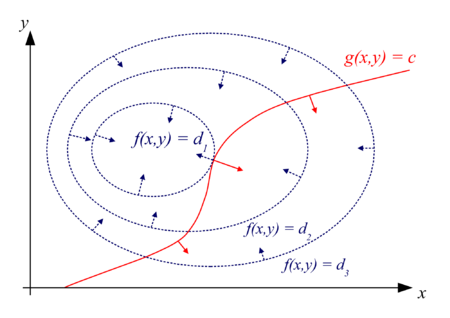
TFCO扩展了拉格朗日乘数的概念,将一个优化问题建模为一个两人游戏,该游戏由寻求对模型参数进行优化的玩家与希望对拉格朗日乘数进行最大化的玩家之间进行。 我。 第一个参与者通过易于优化的"代理约束"将外部遗憾最小化,而第二个参与者通过使交换后悔最小化来实施原始约束。 换句话说,第一个玩家选择第二个玩家应该惩罚(可区分的)代理约束多少,但是这样做是为了满足原始约束。
为了说明TFCO的原理,让我们基于一对带有两个受保护组的传统分类器的可视化效果:蓝色和橙色。 指示TFCO最小化线性模型(没有公平约束)的学习分类器的总体错误率,可能会产生如下所示的决策边界:
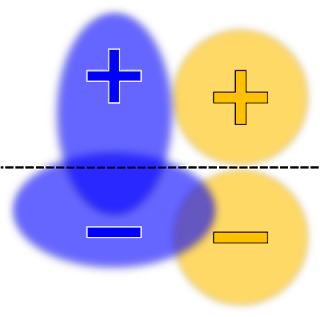
在不同情况下,该模型可以被认为是不公平的。 例如,带有正标记的蓝色示例比具有正标记的橙色示例更有可能收到负面预测。 可以添加使机会均等或真实正比率最大化的约束,从而将模型更改为以下分布:
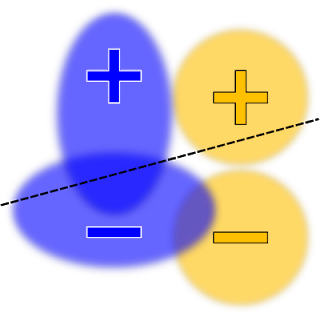
可以同时优化真实肯定比率和错误肯定比率约束的类似优化如下所示:
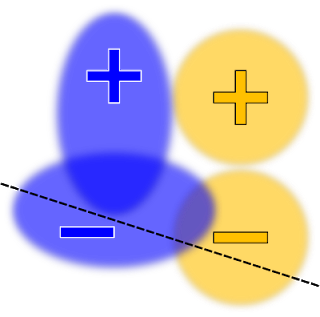
最终,选择正确的约束条件是一项复杂的工作,高度取决于策略目标和机器学习问题的特定性质。 例如,假设一个人将训练限制为四个组具有相同的准确性,但是这些组之一很难分类。 在这种情况下,满足约束条件的唯一方法可能是降低三个较容易组的准确性,以使它们与第四组的低准确性匹配。 这可能不是理想的结果。 为了应对这一挑战,TFCO包括一系列计划的优化问题。
从开发人员体验的角度来看,使用TFCO是相对简单的体验。 第一步是导入TFCO库:
import tensorflow as tf
import tensorflow_constrained_optimization as tfco
之后,我们需要将模型表示为优化问题,如以下代码所示。
# Create variables containing the model parameters.
weights=tf.Variable(tf.zeros(dimension), dtype=tf.float32, name="weights")
threshold=tf.Variable(0.0, dtype=tf.float32, name="threshold")
# Create the optimization problem.
constant_labels=tf.constant(labels, dtype=tf.float32)
constant_features=tf.constant(features, dtype=tf.float32)
def predictions():
return tf.tensordot(constant_features, weights, axes=(1, 0)) - threshold
最终,TFCO专注于优化按照比率线性组合编写的约束问题,其中"比率"是指发生事件的训练示例的比例(例如,假阳性率,即标有负号的示例数)。 该模型可以做出肯定的预测,然后除以带有负面标签的示例数)。 一旦我们将模型表示为优化问题,就可以使用TFCO创建不同的优化,例如:
# Like the predictions, in eager mode, the labels should be a nullary function
# returning a Tensor. In graph mode, you can drop the lambda.
context=tfco.rate_context(predictions, labels=lambda: constant_labels)
problem=tfco.RateMinimizationProblem( tfco.error_rate(context), [tfco.recall(context) >=recall_lower_bound])
TFCO是一个初始版本,仍然需要大量的优化知识。 但是,它为将公平性约束纳入机器学习模型提供了非常灵活的基础。 看看TensorFlow社区在其之上构建的内容将会很有趣。

















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









