






I.前言
学校有门公共课作业就是让我们写篇创新实践小论文,于是就用深度学习写了个气温预测模型交了上去。(PS:本人也才接触深度学习没多久,模型还有很多不完善的地方,欢迎大家指出)
CNN-LSTM模型通常用于处理时间序列数据,该模型结合了三种不同结构的神经网络层,其中卷积神经网络(CNN)能够很好的检测时间序列数据中的局部特征;而长短时记忆网络(LSTM)测可以记忆并学习数据中的全局特征和长期的事件依赖性。
本文将利用PyTorrch框架搭建模型实现一个简单的气温预测任务。
II.数据获取与预处理
数据获取
数据源自美国NOAA官方网站公布的全球每日气象数据,里面包括了中国各个气象站的每日气象数据。
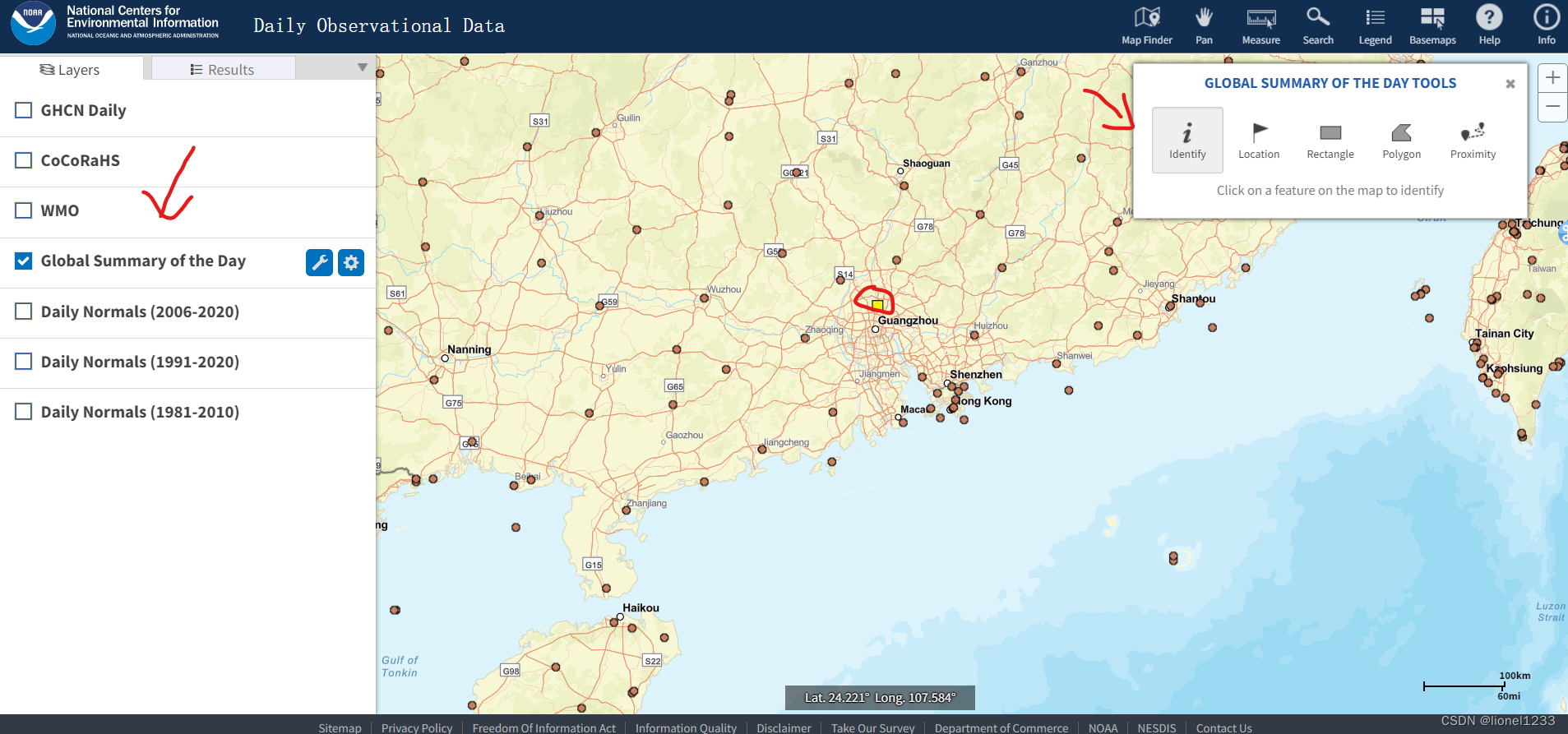
进去之后先点击左边的“Global Summary of the Day”,然后点旁边的扳手。之后右上角会出现一个各个工具,再点击第一个“Identity”,将箭头点击你想要的气象站(也就是地图上橙色的圆点)的数据,这里选择的是广州白云机场气象站的数据,然后点击左上角的“Results”
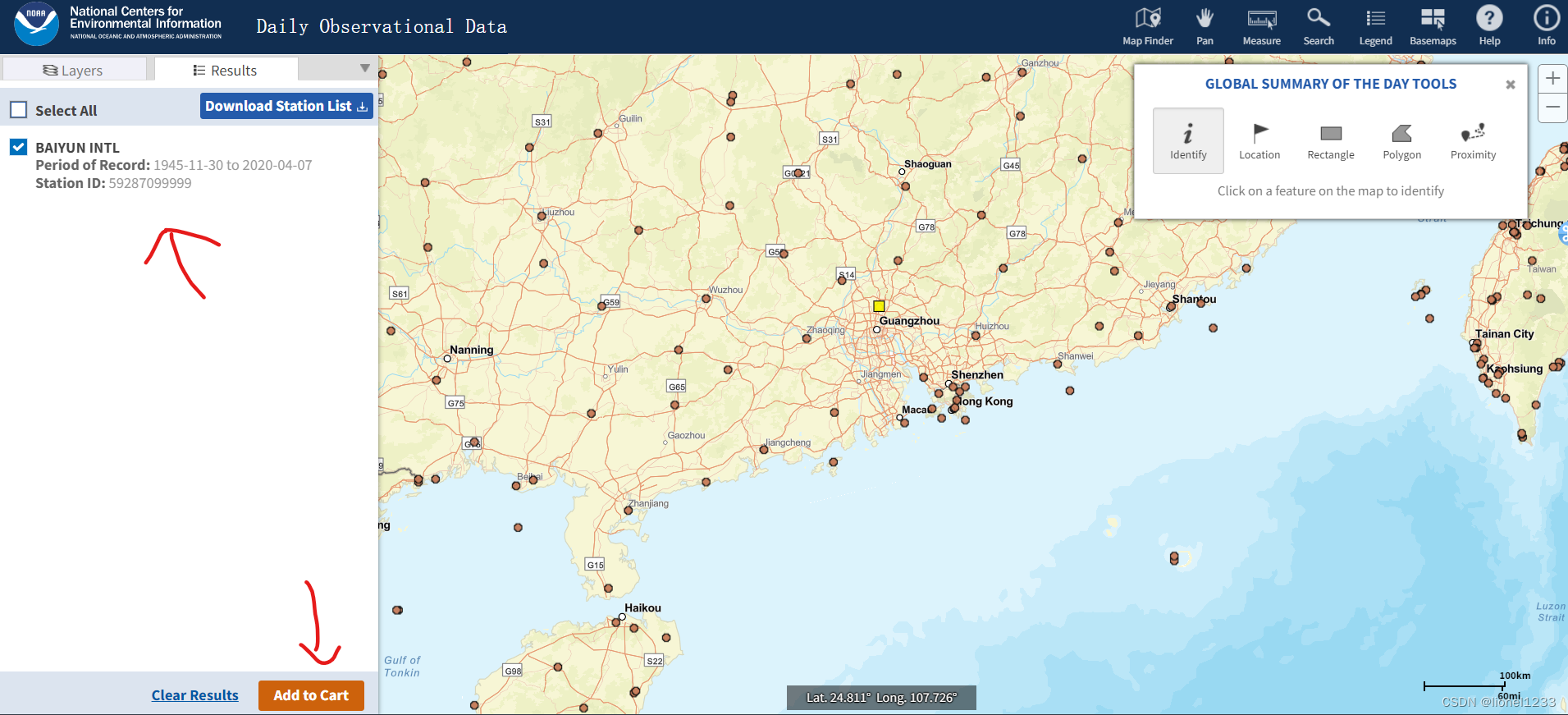
将选择的气象站勾选,再点击左下角的“Add to Cart”
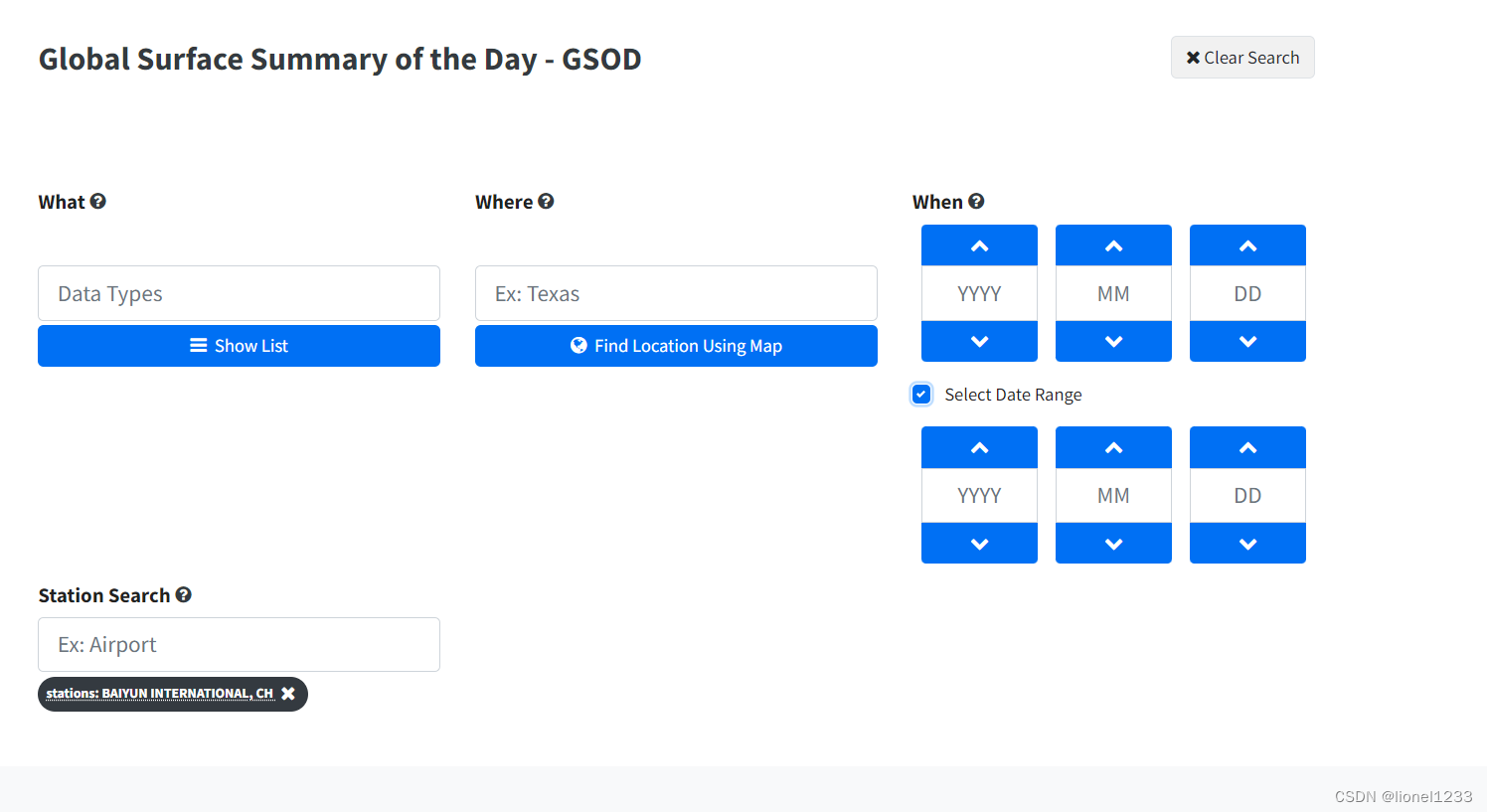
这里可以选择根据需要选择需要的数据类型(Data Types),包括平均温度,降水量等等,右边可以选择你需要的时间范围。
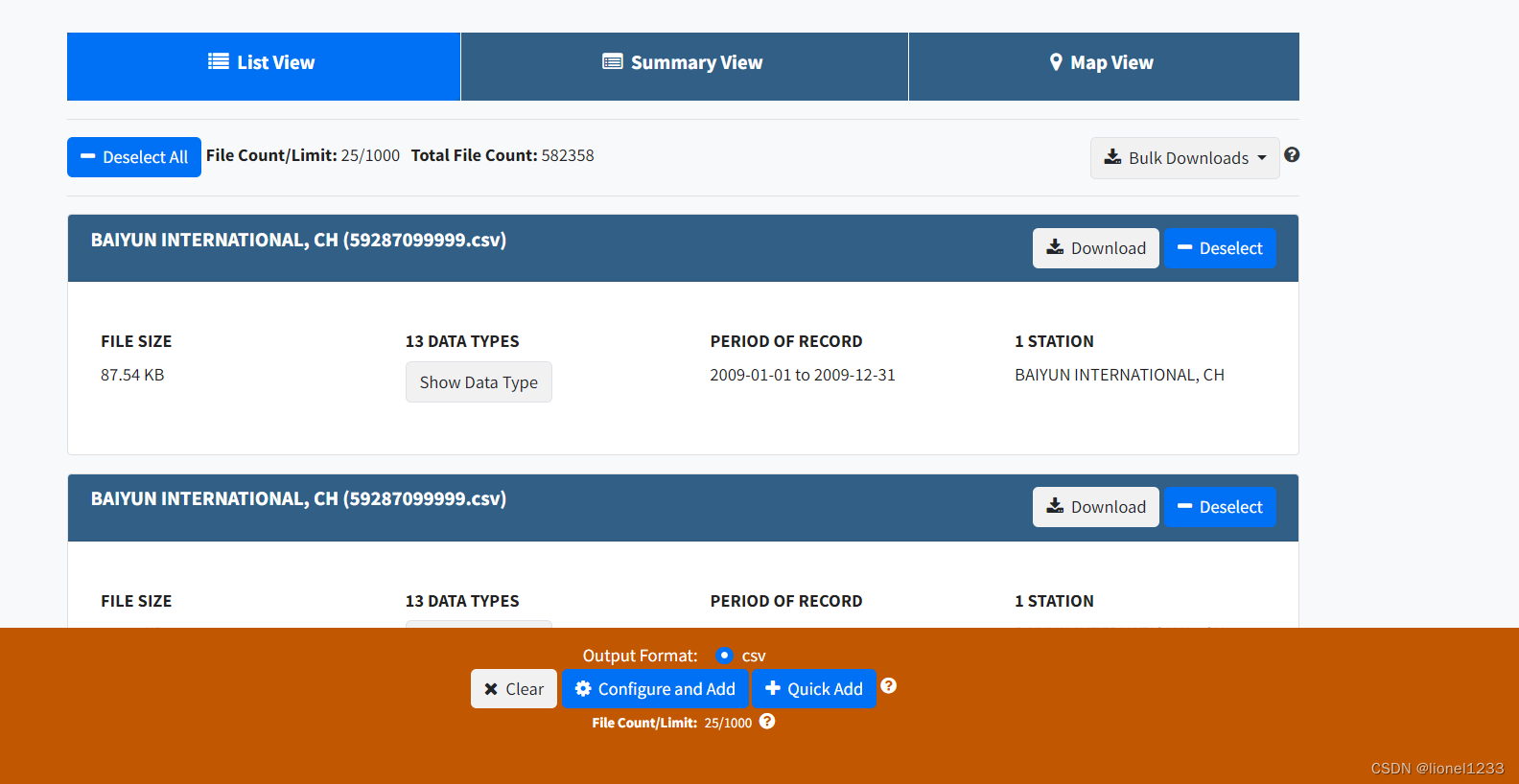
点击数据列表左上角的Select All,再点击下面的Quick Add,然后再点击右上角的Cart,就能看到自己选择的数据了
然后在右边填写你的邮箱,数据就会发送到你的邮箱里了。
因为获取后的数据类型名称是缩写的,所以看不懂的话这里有每个缩写的解释以及每个数据的计量单位:
GHCND_documentation.pdf (noaa.gov)
ncei.noaa.gov/data/global-summary-of-the-day/doc/readme.txt
数据预处理
对数据进行整合后,得到了以下11个特征
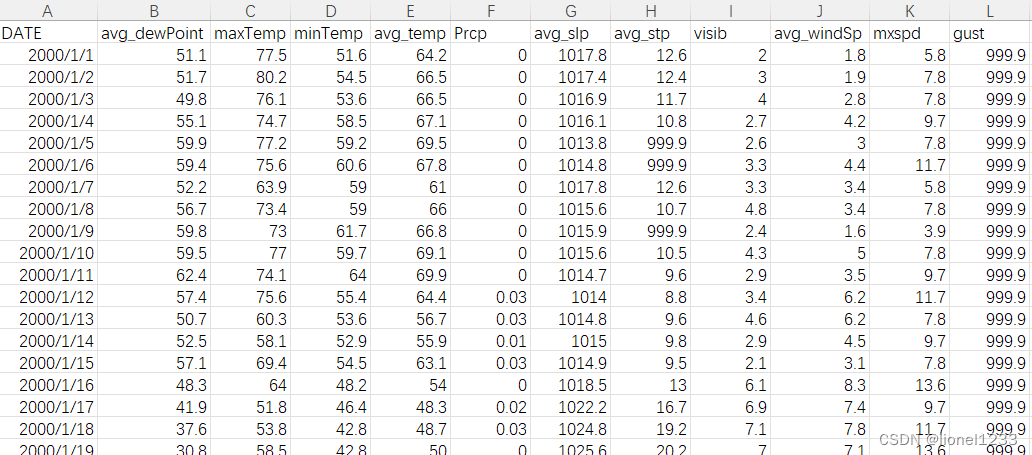
DATE:日期
avg_dewPoint:平均露点
maxTemp:最大温度
minTemp:最低温度
avg_Temp:平均温度
Prcp:降水量
avg_slp:平均海平面压力
avg_stp:平均站压
visib:可见度
avg_windSp:平均风速
mxspd:最大持续风速
gust:最大阵风
注意,数据缺失值会用999表示,而且这里温度用的是华氏度(℉),风速用的是节(knot,每小时一海里),但没关系,后面我们会对数据进行归一化处理,将其变为无量纲数。
下面来看看数据的描述统计。
#先导入需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#读取数据
df = pd.read_csv('climate_total.csv')
#查看描述统计
df.describe().style.background_gradient(cmap = 'Oranges')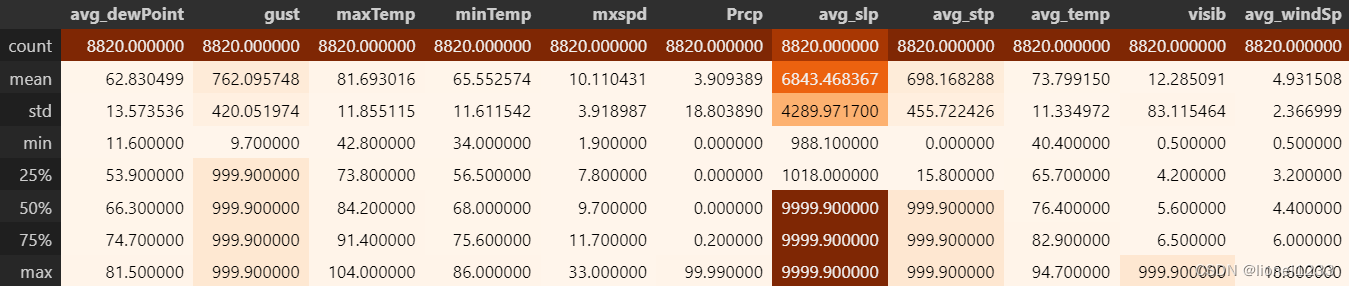
可以看到gust、avg_slp、avg_stp这三个特征的缺失值是比较多的,占比都在50%以上,所以为了避免缺失值对模型预测造成影响,所以将这三列特征删去。
df.drop(['avg_slp', 'avg_stp', 'gust'], axis=1, inplace=True)然后再对剩下的特征进行处理
#将日期转化为时间戳格式
df['DATE'] = pd.to_datetime(df['DATE'])
#从日期中提取特征
df['Day_of_Week'] = df['DATE'].dt.dayofweek
df['month'] = df['DATE'].dt.month
df['day'] = df['DATE'].dt.day
#添加一个新特征,每天温度的极差,即温度最大值减去最小值
df['min_max_diff'] = df['maxTemp'] - df['minTemp']另外因为我们的目的是用以往的数据来预测将来的温度,所以我们要把当前数据整体向后移动一行
cols = [col for col in df.columns if col not in ['DATE', 'avg_temp', 'month', 'day', 'Day_of_Week']]
df_shifted = df[cols].shift(1)
df = pd.concat([df[['avg_temp', 'month', 'day', 'Day_of_Week', 'DATE']], df_shifted], axis=1)
df = df[1:]下面对数据进行归一化处理
from sklearn.preprocessing import MinMaxScaler
#选择特征列
features = ['avg_dewPoint', 'maxTemp', 'minTemp', 'mxspd', 'Prcp', 'visib', 'avg_windSp', 'min_max_diff', 'month', 'day', 'Day_of_Week', 'avg_temp']
#进行归一化处理
scaler = MinMaxScaler()
df_scaled = scaler.fit_transform(df[features].values.astype('float32'))因为我们是时间序列数据,所以序列数据前后的值是具有一定关联的,为了让模型更好地捕捉到这些关联规律,我们将创建一个时间窗口,对于每一个样本数据,模型将在这个时间窗口内进行分析、训练,这在时间序列预测中是一个很常见的方法。
def create_dataset(dataset, lookback):
X, y = [], []
for i in range(len(dataset)-lookback):
feature = dataset[:,:11][i:i+lookback]
target = dataset[:, 11][i+lookback-1]
X.append(feature)
y.append(target)
return X, y
X_lookback, y_looback = create_dataset(df_scaled, lookback=lookback)其中lookback参数就是我们的时间窗口长度,经过多次测试,我选择14作为时间窗口长度,也就是说对于每个模型输入数据,除了包含了这一天的样本数据,还包含了除了这一天往前的13天的样本数据。
最后再划分训练集和测试集,我们将使用2023年1月1日之前的数据作为训练集,将2023年1月1日及之后的数据作为测试集,同时以2022年1月1日作为分界来划分训练集与验证集。
X_lookback, y_lookback = create_dataset(df_scaled, lookback=lookback)
idx_test = df.loc[df['DATE'] == '2023-01-01'].index[0]
idx_val = df.loc[df['DATE'] == '2022-01-01'].index[0]
X_train, y_train = torch.tensor(X_lookback[:(idx_test-lookback)]), torch.tensor(y_lookback[:(idx_test-lookback)]) #因为使用的时间窗口是lookback天,故实际上训练数据的第一个样本是从第lookback天开始的
X_test, y_test = torch.tensor(X_lookback[(idx_test - lookback):]), torch.tensor(y_lookback[(idx_test - lookback):])
X_val, y_val = torch.tensor(X_lookback[(idx_val - lookback):(idx_test-lookback)]), torch.tensor(y_lookback[(idx_val - lookback):(idx_test-lookback)])我们将上述处理操作编写出一个函数,方便后面调用。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
def create_dataset(dataset, lookback):
X, y = [], []
for i in range(len(dataset)-lookback):
feature = dataset[:,:11][i:i+lookback]
target = dataset[:, 11][i+lookback-1]
X.append(feature)
y.append(target)
return X, y
def create_train_data(lookback):
df = pd.read_csv("climate_total.csv")
df.drop(['avg_slp', 'avg_stp', 'gust'], axis=1, inplace=True)
df['DATE'] = pd.to_datetime(df['DATE'])
df['Day_of_Week'] = df['DATE'].dt.dayofweek
df['month'] = df['DATE'].dt.month
df['day'] = df['DATE'].dt.day
df['min_max_diff'] = df['maxTemp'] - df['minTemp']
cols = [col for col in df.columns if col not in ['DATE', 'avg_temp', 'month', 'day', 'Day_of_Week']]
df_shifted = df[cols].shift(1)
df = pd.concat([df[['avg_temp', 'year', 'month', 'day', 'Day_of_Week', 'DATE']], df_shifted], axis=1)
df = df[1:]
features = ['avg_dewPoint', 'maxTemp', 'minTemp', 'mxspd', 'Prcp', 'visib', 'avg_windSp', 'min_max_diff', 'month', 'day', 'Day_of_Week', 'avg_temp']
scaler = MinMaxScaler()
df_scaled = scaler.fit_transform(df[features].values.astype('float32'))
X_lookback, y_lookback = create_dataset(df_scaled, lookback=lookback)
idx_test = df.loc[df['DATE'] == '2023-01-01'].index[0]
idx_val = df.loc[df['DATE'] == '2022-01-01'].index[0]
X_train, y_train = torch.tensor(X_lookback[:(idx_test-lookback)]), torch.tensor(y_lookback[:(idx_test-lookback)]) #因为使用的时间窗口是lookback天,故实际上训练数据的第一个样本是从第lookback天开始的
X_test, y_test = torch.tensor(X_lookback[(idx_test - lookback):]), torch.tensor(y_lookback[(idx_test - lookback):])
X_val, y_val = torch.tensor(X_lookback[(idx_val - lookback):(idx_test-lookback)]), torch.tensor(y_lookback[(idx_val - lookback):(idx_test-lookback)])
return X_train, y_train, X_val, y_val, X_test, y_test, scaler最后返回的值除了训练集,验证集和测试集之外,还有一个scaler实例化对象,方便后面我们评估时进行反向归一化。
III.CNN-LSTM模型构建
数据集处理好之后,就可以开始构建模型了。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv1d(in_channels=11, out_channels=64, kernel_size=3, padding=1)
self.conv2 = nn.Conv1d(in_channels=64, out_channels=128, kernel_size=3, padding=1)
self.maxpool = nn.MaxPool1d(2)
self.lstm1 = nn.LSTM(input_size=64, hidden_size=128,batch_first=True)
self.dropout1 = nn.Dropout(0.2)
self.bidirectional = nn.LSTM(128, 128, bidirectional=True, batch_first=True)
self.dropout2 = nn.Dropout(0.2)
self.dense1 = nn.Linear(128 * 2, 64)
self.dense2 = nn.Linear(64, 8)
self.dense3 = nn.Linear(8, 1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = self.maxpool(x.permute(0, 2, 1))
x, _ = self.lstm1(x)
x = self.dropout1(x)
x, _ = self.bidirectional(x)
x = x[:, -1, :]
x = self.dropout2(x)
x = F.sigmoid(self.dense1(x))
x = self.dense2(x)
x = self.dense3(x)
return x可以看到,模型主要有两层CNN,一层LSTM和一层双向LSTM组成,并且使用了ReLu函数作为卷积层的激活函数。同时在卷积完成后,还加入了一层最大池化层,这样能够减少卷积后数据的维度,进而减少模型复杂度。
另外在每次通过LSTM层之后,还加入了丢弃(dropout)层。丢弃层会在训练过程中随机将一部分神经元关闭,使其不参与前向与反向传播,这样能够防止模型过拟合,从而提高模型泛化能力。
最后使用了三个线形层作为全连接层来输出最终的结果,并且在第一个线性层使用了sigmoid激活函数。
我们可以使用summary方法来查看模型总体架构。
from torchinfo import summary
Torchmodel = Net()
summary(Torchmodel, input_size=(8, 11, 14))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
Net [8, 1] --
├─Conv1d: 1-1 [8, 64, 14] 2,176
├─Conv1d: 1-2 [8, 128, 14] 24,704
├─MaxPool1d: 1-3 [8, 14, 64] --
├─LSTM: 1-4 [8, 14, 128] 99,328
├─Dropout: 1-5 [8, 14, 128] --
├─LSTM: 1-6 [8, 14, 256] 264,192
├─Dropout: 1-7 [8, 256] --
├─Linear: 1-8 [8, 64] 16,448
├─Linear: 1-9 [8, 8] 520
├─Linear: 1-10 [8, 1] 9
==========================================================================================
Total params: 407,377
Trainable params: 407,377
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 43.86
==========================================================================================
Input size (MB): 0.01
Forward/backward pass size (MB): 0.52
Params size (MB): 1.63
Estimated Total Size (MB): 2.16
==========================================================================================结果会显示每一层最后输出数据的格式,以及每一层的参数数量。我们的输入数据格式为(8, 11, 14),其中8为批量大小 ,11为特征数,14为序列长度(即时间窗口长度)。
模型构建完成之后,就可以开始训练模型了,但在此之前,我们先定义一个早停机制。
#定义早停机制
class CustomEarlyStopping:
def __init__(self, patience=10, delta=0, verbose=False):
self.patience = patience
self.delta = delta
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
def __call__(self, val_loss):
score = -val_loss
if self.best_score is None:
self.best_score = score
elif score < self.best_score + self.delta:
self.counter += 1
if self.verbose:
print(f'EarlyStopping counter: {self.counter} out of {self.patience}, score: {self.best_score}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.counter = 0使用早停机制(EarlyStopping),可以使模型在数据集上的损失不再减小,或者说减小的程度小于某个阈值时停止训练。我们训练模型时通常要设置epoch的大小,如果epoch太小,那么模型就有可能欠拟合;如果epoch太大,模型就又有可能过拟合,同时训练的时间成本也会大大增加。而早停机制则可以帮我们解决epoch的设置问题。
同时,另一个机制“学习率调整器”也是一个十分有用的训练技巧。当模型的损失在一定的epoch次数内不再衰退时,学习率调整器会将学习率的值减小。将早停机制与学习率调整器结合,能够一定程度上解决过拟合问题,防止学习率过大而导致的不收敛。
# 学习率调整器
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=5)上面这个学习率调整器意味着当损失值连续五个epoch不再减小时,便把学习率减小到原来的一半
下面我们开始完整地编写模型的训练代码。
#导入torch库
import torch.utils.data as data
from torch.optim.lr_scheduler import ReduceLROnPlateau
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn.model_selection import train_test_split
def train_model_no_attention(X_train, y_train, X_val, y_val):
#定义早停机制
class CustomEarlyStopping:
def __init__(self, patience=10, delta=0, verbose=False):
self.patience = patience
self.delta = delta
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
def __call__(self, val_loss):
score = -val_loss
if self.best_score is None:
self.best_score = score
elif score < self.best_score + self.delta:
self.counter += 1
if self.verbose:
print(f'EarlyStopping counter: {self.counter} out of {self.patience}, score: {self.best_score}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.counter = 0
#定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv1d(in_channels=11, out_channels=64, kernel_size=3, padding=1)
self.conv2 = nn.Conv1d(in_channels=64, out_channels=128, kernel_size=3, padding=1)
self.maxpool = nn.MaxPool1d(2)
self.lstm1 = nn.LSTM(input_size=64, hidden_size=128,batch_first=True)
self.dropout1 = nn.Dropout(0.2)
self.bidirectional = nn.LSTM(128, 128, bidirectional=True, batch_first=True)
self.dropout2 = nn.Dropout(0.2)
self.dense1 = nn.Linear(128 * 2, 64)
self.dense2 = nn.Linear(64, 8)
self.dense3 = nn.Linear(8, 1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = self.maxpool(x.permute(0, 2, 1))
x, _ = self.lstm1(x)
x = self.dropout1(x)
x, _ = self.bidirectional(x)
x = x[:, -1, :]
x = self.dropout2(x)
x = F.sigmoid(self.dense1(x))
x = self.dense2(x)
x = self.dense3(x)
return x
#用来计算验证集的rmse
def calculate_rmse(model, X, y, criterion):
with torch.no_grad():
y_pred = model(X.permute(0, 2, 1)).detach()
rmse = np.sqrt(criterion(y_pred.cpu(), y.unsqueeze(1).detach()))
return rmse
# 创建模型实例
Torchmodel = Net()
# 定义损失函数和优化器,这类使用的是MSE损失函数和AdamW优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(Torchmodel.parameters(), lr=1e-3, weight_decay=1e-5)
# 定义学习率调整器
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=5)
# 将数据、模型和损失函数转移到GPU上
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
Torchmodel = Torchmodel.to(device)
criterion = criterion.to(device)
# 模型定义完成后,开始训练模型
# 定义训练参数
loader = data.DataLoader(data.TensorDataset(X_train, y_train),
batch_size = 8, shuffle = True)
X_val = X_val.to(device)
#创建早停机制实例
early_stopping = CustomEarlyStopping(patience=10, verbose=True)
#用来存储训练和验证损失
train_losses = []
val_losses = []
epochs = 300
for epoch in range(epochs):
Torchmodel.train()
train_loss = 0
for X_batch, y_batch in loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
y_pred = Torchmodel(X_batch.permute(0, 2, 1))
loss = criterion(y_pred, y_batch.unsqueeze(1))
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
train_loss += loss.item() # 累加每个batch的损失
train_loss /= len(loader) # 计算平均训练损失
train_losses.append(np.sqrt(train_loss)) # 保存训练损失
Torchmodel.eval()
val_rmse = calculate_rmse(Torchmodel, X_val, y_val, criterion)
val_losses.append(val_rmse.item()) # 保存验证损失
scheduler.step(val_rmse)
early_stopping(val_rmse)
# 应用早停机制,确定是否停止训练
if early_stopping.early_stop:
print("Early stopping")
break
if epoch % 10 == 0:
print('*'*10, 'Epoch: ', epoch, '\ train RMSE: ', np.sqrt(train_loss), '\ val RMSE', val_rmse.item())
return Torchmodel, train_losses, val_losses这个函数输入训练集与测试集,最终返回模型与训练集、验证集在每个epoch上的损失。
值得留意的是,卷积层Conv1d接收的数据格式为(batch_size, num_features, seq_len),而我们一开始创建的数据格式为(batch_size, seq_len, num_features),所以我们在将数据输入进神经网络之前,需要使用permute方法将输入数据的第二个维度与第三个维度进行调换。而在使用最大池化层的时候我们希望对卷积后的数据进行一定程度的降维,另外LSTM层接收的数据格式也是(batch_size, seq_len, num_features),因此我们又需要使用permute方法将第二、第三个维度重新调换一次。同时因为LSTM层最后会输出多个时间序列的预测温度,而我们只需要最后一个时间序列(也就是我们需要预测的当天的温度),因此在前向传播函数中使用x[:,-1,:]提取最后一个时间序列。
对这个神经网络传播步骤不清楚的朋友,可以在前向传播函数中的每一个步骤后面都输出一遍x的数据格式:
然后开始训练模型,并将得到的损失绘制成图像
X_train, y_train, X_val, y_val, X_test, y_test, scaler = create_train_data(lookback=14)
Torchmodel, train_losses, val_losses= train_model_no_attention(X_train, y_train, X_val, y_val)
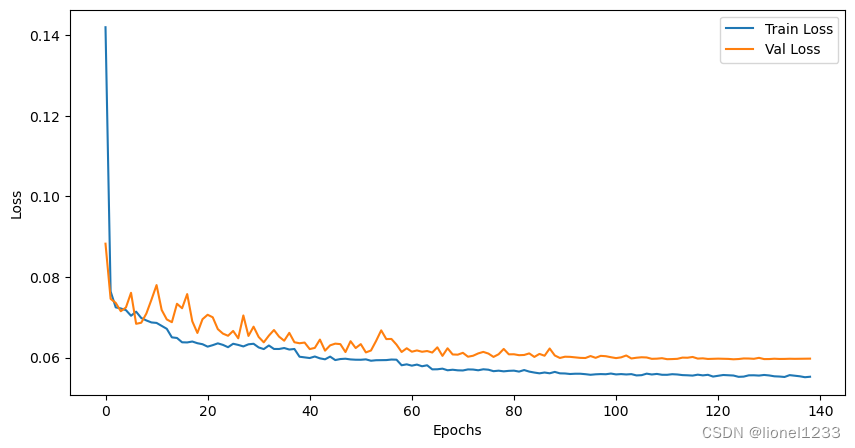
plt.figure(figsize=(10, 5))
plt.plot(train_losses, label='Train Loss')
plt.plot(val_losses, label='Val Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()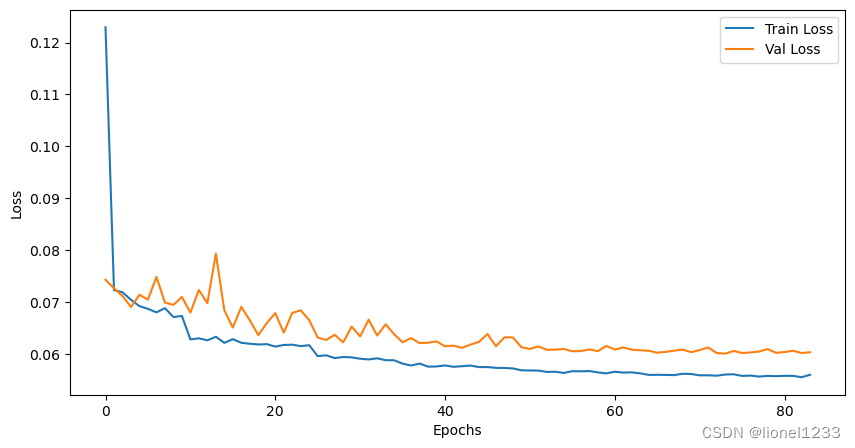
可以看到,训练损失和测试损失在大概在epoch为30之后的时候趋于平稳,最后的损失大概稳定在0.6左右 。
再用训练好的模型在测试集上进行预测,我们这里选择R²得分、均方根误差(RSME)和平均绝对百分比误差(MAPE)作为评估指标。
Torchmodel.eval()
with torch.no_grad():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
X_test = X_test.to(device)
predict = Torchmodel(X_test.permute(0, 2, 1)).cpu().detach()
#为了便于进行方向归一化处理,我们这里将预测值与测试集数据合并在一起
predict_sum = np.concatenate((X_test[:, -1, :].cpu().numpy(), predict), axis=1)
test_sum = np.concatenate((X_test[:, -1, :].cpu().numpy(), y_test.cpu().numpy().reshape(-1, 1)), axis=1)
predict_sum = scaler.inverse_transform(predict_sum)
test_sum = scaler.inverse_transform(test_sum)
r2 = r2_score(test_sum[:, -1], predict_sum[:, -1])
rmse = np.sqrt(mean_squared_error(test_sum[:, -1], predict_sum[:, -1]))
print("R² Score:", r2)
print("RMSE:", np.sqrt(mean_squared_error(test_sum[:, -1], predict_sum[:,-1])))
print("MAPE:", mean_absolute_percentage_error(test_sum[:, -1], predict_sum[:,-1]))R² Score: 0.892337485594729
RMSE: 3.8498504
MAPE: 0.04413565绘制预测温度与真实温度的图像。
import plotly.graph_objects as go
eval_df = pd.concat([pd.DataFrame(test_sum[:, -1]),
pd.Series(predict_sum[:,-1].reshape(-1).tolist())],axis=1)
eval_df.columns = ['real_meantemp', 'pred_meantemp']
fig = go.Figure(data = [
go.Line(x = eval_df.index, y = eval_df['real_meantemp'], name = "Actual"),
go.Line(x = eval_df.index, y = eval_df['pred_meantemp'], name="Predict"),
])
fig.update_layout(
font = dict(size=17,family="Franklin Gothic"),
template = 'simple_white',
title = 'Real & Predicted Temp')
fig.show() 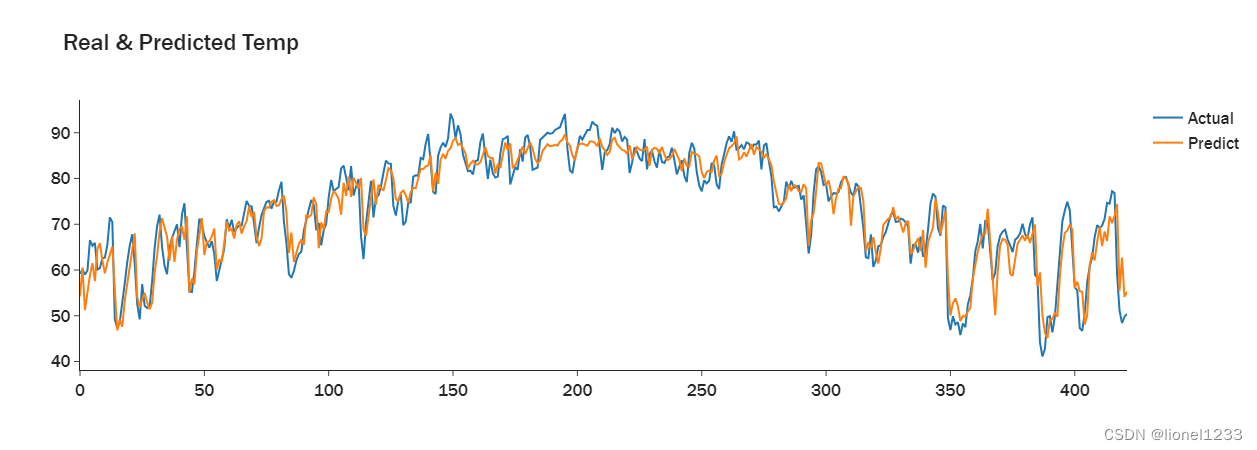
可以看到模型的预测效果还算不错。
IV.使用贝叶斯优化
贝叶斯优化是一种较为常见的优化方法,主要用来解决黑盒优化问题。它使用贝叶斯定理来指导搜索以找到目标函数的最小值或最大值,即利用之前的搜索点来确定下一步搜索点,并用高斯过程来建立目标函数的前验和后验模型。
事实上,官方提供了BoTorch和GPyTorch库来帮助我们在PyTorch框架下实现贝叶斯优化的过程,这里主要参考的是BoTorch提供的使用教程。
在编写代码之前,除了BoTorch和GPyTorch库之外,我们还需要安装Ax库。
pip install botorch
pip install gpyTorch
pip install ax-platform
注意:Ax库需要3.9及以上的 Python版本,这是官方手册。
下面是实现贝叶斯优化的代码:
#先将之前定义的模型训练函数进行修改,用于输入贝叶斯优化的参数
def train_with_bayesian(X_train, y_train, X_val, y_val, params):
#定义早停机制
class CustomEarlyStopping:
def __init__(self, patience=10, delta=0, verbose=False):
self.patience = patience
self.delta = delta
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
def __call__(self, val_loss):
score = -val_loss
if self.best_score is None:
self.best_score = score
elif score < self.best_score + self.delta:
self.counter += 1
if self.verbose:
print(f'EarlyStopping counter: {self.counter} out of {self.patience}, score: {self.best_score}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.counter = 0
class Net(nn.Module):
def __init__(self, conv1_out_channels, conv2_out_channels, lstm_hidden_size, dropout):
super(Net, self).__init__()
self.conv1 = nn.Conv1d(in_channels=11, out_channels=conv1_out_channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv1d(in_channels=conv1_out_channels, out_channels=conv2_out_channels, kernel_size=3, padding=1)
self.maxpool = nn.MaxPool1d(2)
self.lstm1 = nn.LSTM(input_size=int(conv2_out_channels * 0.5), hidden_size=lstm_hidden_size,batch_first=True)
self.dropout1 = nn.Dropout(dropout)
self.bidirectional = nn.LSTM(lstm_hidden_size, lstm_hidden_size, bidirectional=True, batch_first=True)
self.dropout2 = nn.Dropout(dropout)
self.dense1 = nn.Linear(lstm_hidden_size * 2, 64)
self.dense2 = nn.Linear(64, 8)
self.dense3 = nn.Linear(8, 1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = self.maxpool(x.permute(0, 2, 1))
x, _ = self.lstm1(x)
x = self.dropout1(x)
x, _ = self.bidirectional(x)
x = x[:, -1, :]
x = self.dropout2(x)
x = F.sigmoid(self.dense1(x))
x = self.dense2(x)
x = self.dense3(x)
return x
# 转换为整数,因为贝叶斯优化库会将输入作为浮点数处理
conv1_out_channels = int(params['conv1_out_channels'])
conv2_out_channels = int(params['conv2_out_channels'])
lstm_hidden_size = int(params['lstm_hidden_size'])
dropout = float(params['dropout'])
# 创建模型、损失函数和优化器
Torchmodel = Net(conv1_out_channels, conv2_out_channels, lstm_hidden_size, dropout)
criterion = nn.MSELoss() # 使用MSE作为损失函数
optimizer = torch.optim.Adam(Torchmodel.parameters(), lr=1e-3, weight_decay=1e-5)
# 定义学习率调整器
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=5)
#使用GPU加速
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Torchmodel.to(device)
criterion = criterion.to(device)
loader = data.DataLoader(data.TensorDataset(X_train, y_train),
batch_size = 8, shuffle = True)
early_stopping = CustomEarlyStopping(patience=10, verbose=True)
total_loss = 0
# 训练模型
epochs = 300
for epoch in range(epochs):
model.train()
for X_batch, y_batch in loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model(X_batch.permute(0, 2, 1))
loss = criterion(y_pred, y_batch.unsqueeze(1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
X_val = X_val.to(device)
y_pred = model(X_val.permute(0, 2, 1)).cpu().detach()
val_rmse = np.sqrt(criterion(y_pred, y_val.unsqueeze(1).cpu().detach()))
total_loss += val_rmse.item()
scheduler.step(val_rmse)
early_stopping(val_rmse)
if early_stopping.early_stop:
print("Early stopping")
break
if epoch % 10 == 0:
print('*'*10, 'Epoch: ', epoch, '\ test RMSE', val_rmse)
return total_loss / epoch #返回平均RMSE值最后返回的评估值是所有训练周期的平均RMSE值,当然也可以尝试只返回最后一个周期的验证损失值,不过这样会有过拟合的风险。
然后设置贝叶斯优化所需要的参数:
from ax.models.torch.botorch_modular.model import BoTorchModel
from ax.models.torch.botorch_modular.surrogate import Surrogate
from ax.modelbridge.generation_strategy import GenerationStep, GenerationStrategy
from ax.modelbridge.registry import Models
from ax.service.ax_client import AxClient
from ax.service.utils.instantiation import ObjectiveProperties
from botorch.models.gpytorch import GPyTorchModel
from gpytorch.distributions import MultivariateNormal
from gpytorch.kernels import RBFKernel, ScaleKernel
from gpytorch.likelihoods import GaussianLikelihood
from gpytorch.means import ConstantMean
from gpytorch.models import ExactGP
from gpytorch.mlls import ExactMarginalLogLikelihood
NUM_EVALS = 10
#定义一个高斯过程模型
class SimpleCustomGP(ExactGP, GPyTorchModel):
_num_outputs = 1 # 通知 GPyTorchModel API
def __init__(self, train_X, train_Y):
super().__init__(train_X, train_Y.squeeze(-1), GaussianLikelihood())
self.mean_module = ConstantMean()
self.covar_module = ScaleKernel(
base_kernel=RBFKernel(ard_num_dims=train_X.shape[-1]),
)
self.to(train_X)
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return MultivariateNormal(mean_x, covar_x)
ax_model = BoTorchModel(
surrogate=Surrogate(
# 使用model类
botorch_model_class=SimpleCustomGP,
# 可选的,用于优化模型参数的 MLL 类
mll_class=ExactMarginalLogLikelihood,
# 可选,模型构造函数的关键字参数字典
# model_options={}
),
)
gs = GenerationStrategy(
steps=[
# 随机初始化
GenerationStep(
model=Models.SOBOL,
num_trials=5, # 设置五个实验
),
# 贝叶斯优化
GenerationStep(
model=Models.BOTORCH_MODULAR,
num_trials=-1, # 这一步中不设实验
#设置替代函数
model_kwargs={
"surrogate": Surrogate(SimpleCustomGP),
},
),
]
)
ax_client = AxClient(generation_strategy=gs)
#设置实验参数
ax_client.create_experiment(
name="branin_test_experiment",
parameters=[
{
"name": "conv1_out_channels",
"type": "range",
"bounds": [64.0, 512.0],
},
{
"name": "conv2_out_channels",
"type": "range",
"bounds": [64.0, 512.0],
},
{
"name": "lstm_hidden_size",
"type": "range",
"bounds": [128.0, 512.0],
},
{
"name": "dropout",
"type": "range",
"bounds": [0.1, 0.5],
}
],
parameter_constraints=["conv1_out_channels <= conv2_out_channels"],
objectives={
"branin": ObjectiveProperties(minimize=True),
},
) 然后开始进行迭代循环(循环次数可依个人设置):
X_train, y_train, X_val, y_val, X_test, y_test, scaler = create_train_data(lookback=14)
for i in range(NUM_EVALS):
parameters, trial_index = ax_client.get_next_trial()
ax_client.complete_trial(trial_index=trial_index, raw_data=train_with_bayesian(X_train, y_train, X_val, y_val, parameters))优化完成后可查看每次实验的信息
ax_client.get_trials_data_frame()然后获得最优参数:
best_parameter, _ = ax_client.get_best_parameters()
print(best_parameter){'conv1_out_channels': 126.35120717868156, 'conv2_out_channels': 459.56422107834254, 'lstm_hidden_size': 128.0, 'dropout': 0.25688549430951335}我们再用得到的最优参数重新训练神经网络
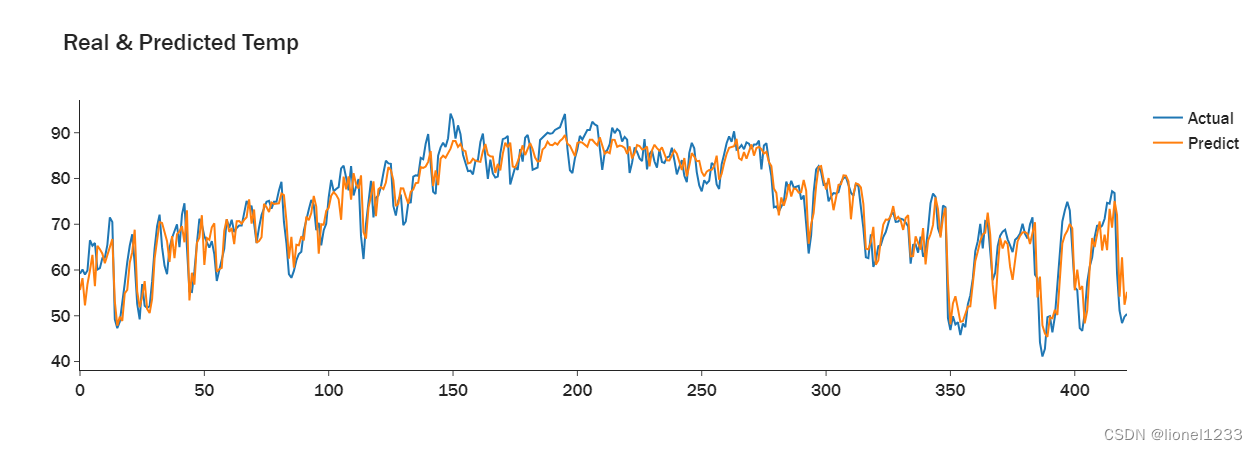
R² Score: 0.8938988129350603
RMSE: 3.8218331
MAPE: 0.04344975可以看到最终的RMSE值有所减小,由于时间问题我这里的贝叶斯优化循环次数只有10次,大家可以自行增加循环次数以获取更优的参数,不过训练时间也会相应地增加
V.结尾
由于本文只是简单地搭建了一个气温预测模型,所以有很多地方可能还不是很完善,大家可以自己尝试着对模型进行调整,例如加入注意力(Attention)机制,又或是在验证数据集的时候使用TimeSeriesSplit交叉验证方法,这是一种时间序列特有的交叉验证方法。
如果对你有帮助的话请点个赞哦!

















 1673
1673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









