






1、模型的应用
一般分为:客服、个人助手、行业应用。
开源模型到这种应用之间,还是存在一定的差距的。在这个应用中还是需要很多的工具和框架。比如开发一个这样的应用需要的一般步骤:
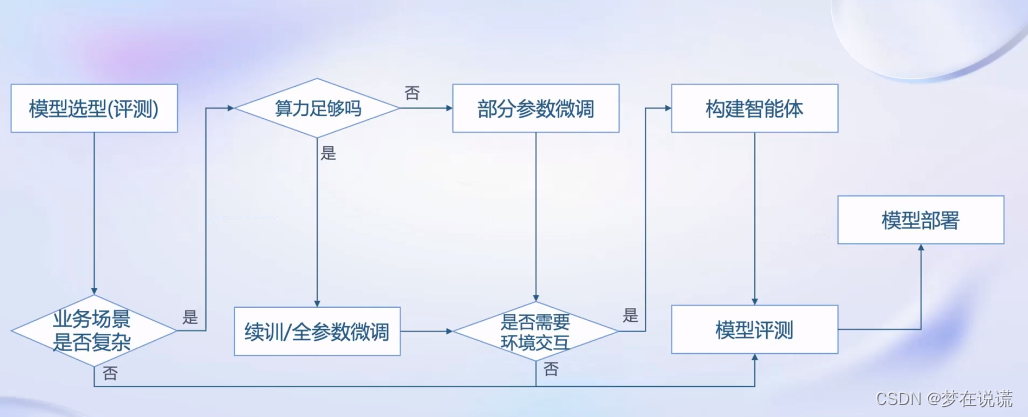
1、首先去对模型进行评估选型。
2、判断业务场景是否复杂,是否能够简单地通过prompt engineering的方式完成。
3、复杂场景:算力是否足够
4、是否需要和外界环境进行交互。构建智能体进行调用工具、分解任务等。
5、对该模型进行评测。
6、模型部署
2、开源社区的体系
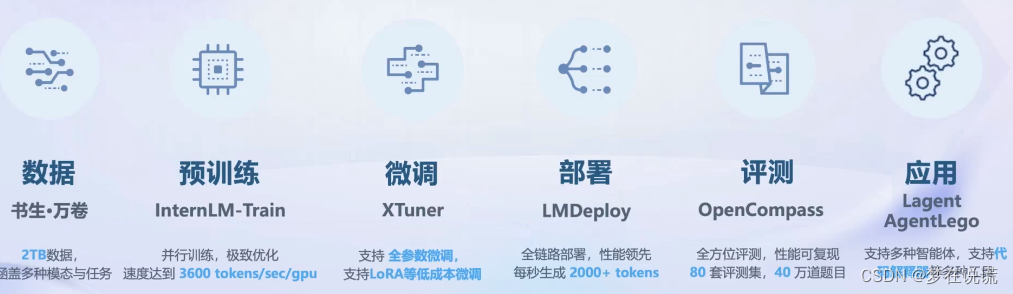
主要包含了六个方面:
2.1、书生万卷的详细介绍
官网链接:OpenDataLab 引领AI大模型时代的开放数据平台
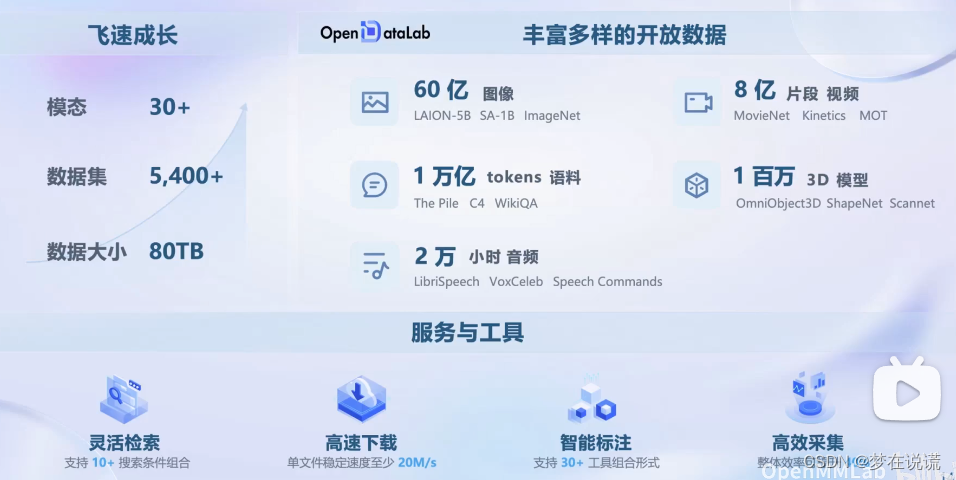
书生万卷的数据是2TB

书生·万卷图文数据集1.0数据主要来自公开网页,经处理后形成图文交错文档。文档总量超过2200万个,数据大小超过140GB(不含图片),覆盖新闻事件、人物、自然景观、社会生活等多个领域。
其他数据
2、预训练
可以采用InternLM-train进行预训练,支持多卡训练和加速。
https://github.com/InternLM/InternLM/blob/main/README-zh-Hans.md

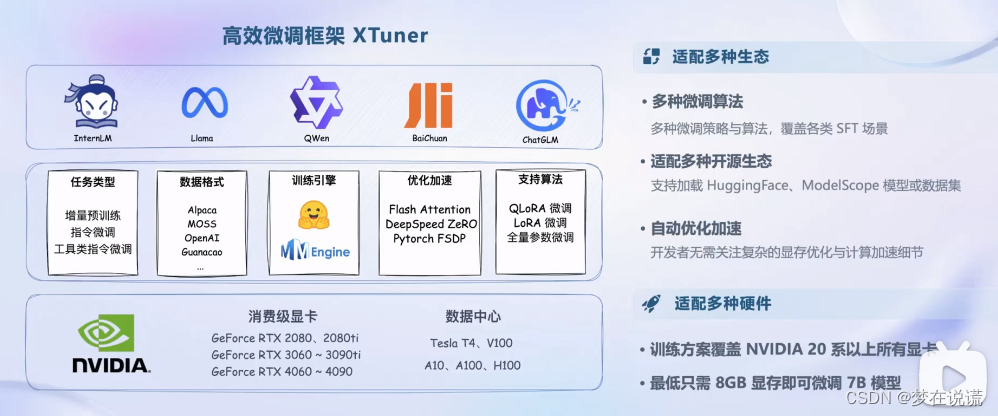
3、微调
https://github.com/InternLM/xtuner/blob/main/README_zh-CN.md

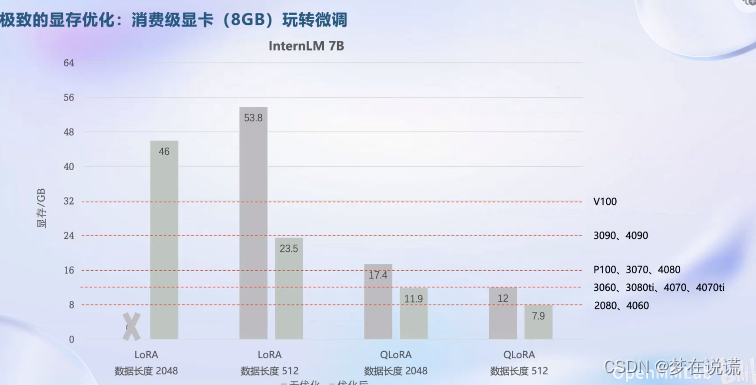
评测


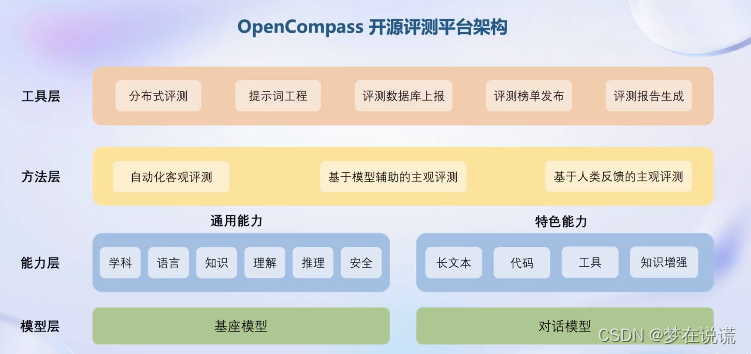
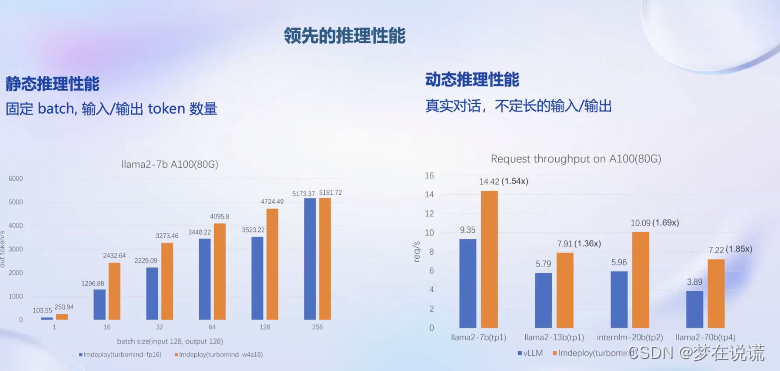
部署


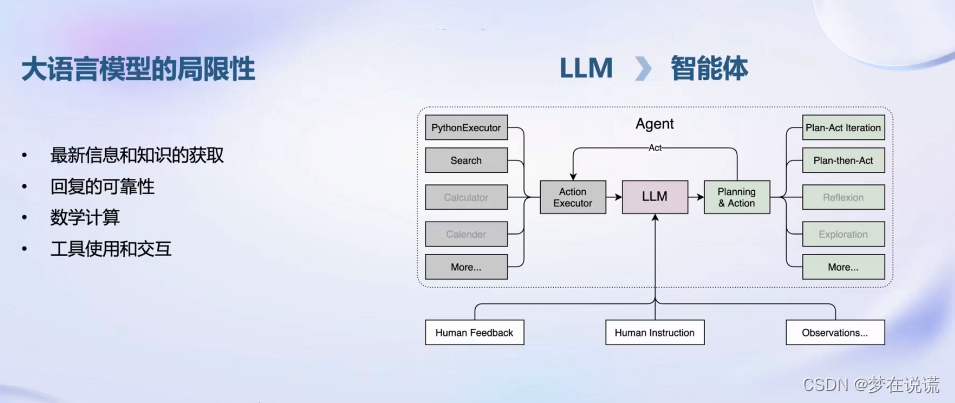
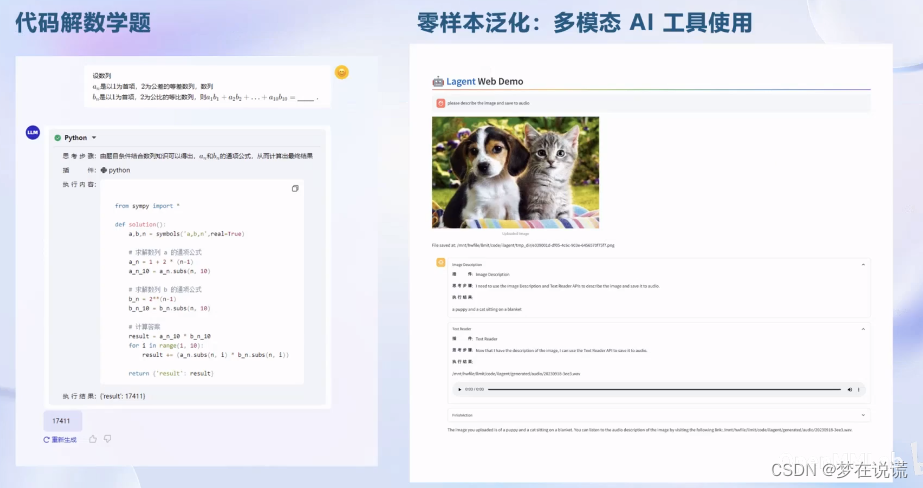
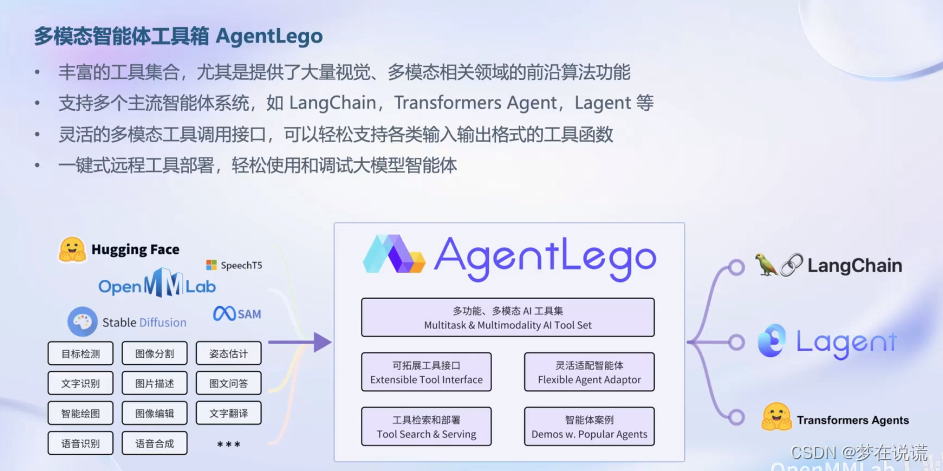
智能体
















 1302
1302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









