









 本文深入探讨神经网络机器翻译(NMT)方法,对比传统SMT,介绍seq2seq模型,包括Encoder-Decoder结构、注意力机制、输入反馈方法、处理[UNK]单词的策略。NMT利用RNN或LSTM解决变长序列问题,通过注意力机制提高翻译质量,解决生词问题。
本文深入探讨神经网络机器翻译(NMT)方法,对比传统SMT,介绍seq2seq模型,包括Encoder-Decoder结构、注意力机制、输入反馈方法、处理[UNK]单词的策略。NMT利用RNN或LSTM解决变长序列问题,通过注意力机制提高翻译质量,解决生词问题。
点击下方图片查看HappyChart专业绘图软件

神经网络机器翻译(Neural Machine Translation, NMT)是最近几年提出来的一种机器翻译方法。相比于传统的统计机器翻译(SMT)而言,NMT能够训练一张能够从一个序列映射到另一个序列的神经网络,输出的可以是一个变长的序列,这在翻译、对话和文字概括方面能够获得非常好的表现。NMT其实是一个encoder-decoder系统,encoder把源语言序列进行编码,并提取源语言中信息,通过decoder再把这种信息转换到另一种语言即目标语言中来,从而完成对语言的翻译。
神经网络的seq2seq学习
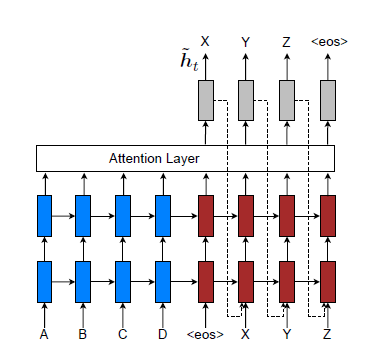
序列对序列的学习,顾名思义,假设有一个中文句子“我也爱你”和一个对应英文句子“I love you too”,那么序列的输入就是“我也爱你”,而序列的输出就是“I love you too”,从而对这个序列对进行训练。对于深度学习而言,如果要学习一个序列,一个重要的困难就是这个序列的长度是变化的,而深度学习的输入和输出的维度一般是固定的,不过,有了RNN结构,这个问题就可以解决了,一般在应用的时候encoder和decoder使用的是LSTM或GRU结构。

如上图,输入一个句子ABC以及句子的终结符号< EOS>,输出的结果为XYZ及终结符号< EOS>。在encoder中,每一时间步输入一个单词直到输入终结符为止,然后由encoder的最后一个隐藏层
h
t
h_t
ht作为decoder的输入,在decoder中,最初的输入为encoder的最后一个隐藏层,输出为目标序列词X,然后把该隐藏层以及它的输出X作为下一时间步的输入来生成目标序列中第二个词Y,这样依次进行直到< EOS>。下面看它详细的模型。
给定一个输入序列
(
x
1
,
⋯
,
x
T
)
(x_1,\cdots, x_T)
(x1,⋯,xT),经过下面的方程迭代生成输出序列
(
y
1
,
⋯
,
y
T
′
)
(y_1,\cdots, y_{T^{'}})
(y1,⋯,yT′):
h
t
=
f
(
W
h
x
x
t
+
W
h
h
h
t
−
1
)
y
t
=
W
y
h
h
t
(1)
h_t = f(W^{hx}x_t + W^{hh}h_{t-1})\tag{1}\\ y_t = W^{yh}h_t
ht=f(Whxxt+Whhht−1)yt=Wyhht(1)
其中,
W
h
x
W^{hx}
Whx为输入到隐藏层的权重,
W
h
h
W^{hh}
Whh为隐藏层到隐藏层的权重,
h
t
h_t
ht为隐藏结点,$ W^{yh}
为隐藏层到输出的权重。在这个结构中,我们的目标是估计条件概率
为隐藏层到输出的权重。 在这个结构中,我们的目标是估计条件概率
为隐藏层到输出的权重。在这个结构中,我们的目标是估计条件概率p(y_1,\cdots,y_{T{'}}|x_1,\cdots,x_T)$,首先通过encoder的最后一个隐藏层获得$(x_1,\cdots,x_T)$的固定维度的向量表示$v$,然后通过decoder进行计算$y_1,\cdots,y_{T{'}}
的概率,这里的初始隐藏层设置为向量
的概率,这里的初始隐藏层设置为向量
的概率,这里的初始隐藏层设置为向量v$:
p
(
y
1
,
⋯
,
y
T
′
∣
x
1
,
⋯
,
x
T
)
=
Π
t
=
1
T
′
p
(
y
t
∣
v
,
y
1
,
⋯
,
y
t
−
1
)
(2)
p(y_1,\cdots,y_{T^{'}}|x_1,\cdots,x_T) = \Pi^{T^{'}}_{t=1}p(y_t|v,y_1,\cdots,y_{t-1})\tag{2}
p(y1,⋯,yT′∣x1,⋯,xT)=Πt=1T′p(yt∣v,y1,⋯,yt−1)(2)
在这个方程中,每个
p
(
y
t
∣
v
,
y
1
,
⋯
,
y
t
−
1
)
p(y_t|v,y_1,\cdots,y_{t-1})
p(yt∣v,y1,⋯,yt−1)为一个softmax函数。
Sutskever等人在实际建模中有三点与上述描述不同:
- 使用两个LSTM模型,一个是用于encoder的,另一个用于decoder
- 由于深层模型比浅层模型表现要好,所以使用了4层LSTM结构
- 对输入序列进行翻转,即由原来的输入ABC变成CBA。假设目标语言是XYZ,则LSTM把CBA映射为XYZ,之所以这样做是因为A在位置上与X相近,B、C分别于Y、Z相近,实际上使用了短期依赖,这样易于优化
#带注意力机制的seq2seq学习
Bahdanau等人在Sutskever研究的基础上又提出了注意力机制,这种机制的主要作用就是在预测一个目标词汇的时候,它会自动的查找源语言序列中哪一部分与它相对应,并且在后续的查找生词中可以直接复制相对应的源语言词,这在后面再讲。
Encoder
Bahdanau等人使用的encoder是一个双向RNN(bi-directional RNN),双向RNN有前向和后向RNN组成,前向RNN f → \overrightarrow{f} f正向读取输入序列(从 x 1 x_1 x1到 x T x_T xT),并计算前向隐藏层状态 ( h 1 → , ⋯ , h T → ) (\overrightarrow{h_1},\cdots,\overrightarrow{h_T}) (h1,⋯,hT),而后向RNN f ← \overleftarrow{f} f从反向读取输入序列(从 x T x_T xT到 x 1 x_1 x1),并计算反向隐藏状态 ( h 1 ← , ⋯ , h T ← ) (\overleftarrow{h_1},\cdots,\overleftarrow{h_T}) (h1,⋯,hT)。对于每个单词 x j x_j xj,我们把它对应的前向隐藏状态向量 h j → \overrightarrow{h_j} hj和后向隐藏状态向量 h j ← \overleftarrow{h_j} hj拼接起来来表示对 x j x_j xj的注解(annotation,就还是个隐藏向量呗),例如 h j = [ h j → ; h j ← ] h_j=[\overrightarrow{h_j}; \overleftarrow{h_j}] hj=[hj;hj],这样,注解 h j h_j hj就包含了所有词的信息。由于RNN对最近的输入表达较好,所以注解 h j h_j hj主要反映了 x j x_j xj周围的信息。
Decoder
在这个新的结构中,定义条件概率:
p
(
y
)
=
Π
t
=
1
T
′
p
(
y
t
∣
{
y
1
,
⋯
,
y
t
−
1
}
,
c
)
p
(
y
t
∣
{
y
1
,
⋯
,
y
t
−
1
}
,
c
)
=
g
(
y
t
−
1
,
s
t
,
c
)
(3)
p(y)=\Pi^{T^{'}}_{t=1}p(y_t|\{y_1,\cdots,y_{t-1}\},c)\tag{3}\\ p(y_t|\{y_1,\cdots,y_{t-1}\},c)=g(y_{t-1},s_t,c)
p(y)=Πt=1T′p(yt∣{y1,⋯,yt−1},c)p(yt∣{y1,⋯,yt−1},c)=g(yt−1,st,c)(3)
其中,
g
g
g为非线性函数,
s
t
s_t
st是decoder的隐藏状态,
c
c
c是由encoder的隐藏序列产生的上下文向量,这个具体是什么等一会说。
把(3)式的条件概率写为:
p
(
y
i
∣
y
1
,
⋯
,
y
i
−
1
,
x
)
=
g
(
y
i
−
1
,
s
i
,
c
i
)
(4)
p(y_i|y_1,\cdots,y_{i-1},x)=g(y_{i-1},s_i,c_i)\tag{4}
p(yi∣y1,⋯,yi−1,x)=g(yi−1,si,ci)(4)
其中,
s
i
s_i
si是时间步
i
i
i的隐藏状态,可由下式来计算:
s
i
=
f
(
s
i
−
1
,
y
i
−
1
,
c
i
)
s_i = f(s_{i-1}, y_{i-1},c_i)
si=f(si−1,yi−1,ci)
下面来说说这个
c
i
c_i
ci是怎么出来的。上下文向量
c
i
c_i
ci依赖于一系列的注解
(
h
1
,
⋯
,
h
T
)
(h_1,\cdots,h_T)
(h1,⋯,hT),这些注解上面我们已经讲过。上下文向量是由这些注解
h
j
h_j
hj加权求和算出来的:
c
i
=
Σ
j
=
1
T
α
i
j
h
j
(5)
c_i = \Sigma_{j=1}^T\alpha_{ij}h_j\tag{5}
ci=Σj=1Tαijhj(5)
每个注解
h
j
h_j
hj的权重
α
i
j
\alpha_{ij}
αij由下式计算:
α
i
j
=
e
x
p
(
e
i
j
)
Σ
k
=
1
T
e
x
p
(
e
i
k
)
(6)
\alpha_{ij} = \frac{exp(e_{ij})}{\Sigma_{k=1}^Texp(e_{ik})}\tag{6}
αij=Σk=1Texp(eik)exp(eij)(6)
其中,
e
i
j
=
a
(
s
i
−
1
,
h
j
)
e_{ij}=a(s_{i-1},h_j)
eij=a(si−1,hj)为对位模型(alignment model),由于它计算位置
j
j
j周围的输入与位置
i
i
i的输出相匹配的得分,所以又称为得分函数。而向量
α
i
=
(
α
i
1
,
α
i
2
,
⋯
,
α
i
T
)
\alpha_i=(\alpha_{i1},\alpha_{i2},\cdots,\alpha_{iT})
αi=(αi1,αi2,⋯,αiT)为注意力向量,又为词对位向量。
整个过程的图示如下:

训练
训练集WMT’14 英语-法语,字典30000常用词,不在字典中的生词用[unk]表示,没有改变大小写,没有进行词干化。
- 两个模型,一个RNN encoder-decoder模型(RNNencdec),另一个为建议模型(RNNsearch),训练两次,一次句子长度最大30,另一次最大50
- RNNencdec的encoder和decoder各有1000个隐藏单元。RNNsearch的encoder前后向RNN各1000隐藏单元,decoder1000个隐藏单元
- 输出使用maxout函数,L2正则化损失函数
- 带有Adadelta( ϵ = 1 0 − 6 , ρ = 095 \epsilon=10^{-6},\rho = 095 ϵ=10−6,ρ=095)的minbatch SGD,min-batch=80
Bahdanau与Sutskever的几点不同:
- 在结构上,Sutskever使用了单向的RNN,而Bahdanau使用了双向的RNN
- Sutskever使用了encoder的最后一个隐藏状态来作为decoder的输入并且后续的过程中不再把decoder的隐藏层作为下一时间步的输入,而Bahdanau使用了所有的encoder的隐藏状态并经过注意力机制与decoder的隐藏层一起作为decoder的初始输入,并且在后续中前一decoder的隐藏层和输出作为下一时间步的输入
- Bahdanau加入了注意力机制,获得了注意力向量
α
i
=
(
α
i
1
,
α
i
2
,
⋯
,
α
i
T
)
\alpha_i=(\alpha_{i1},\alpha_{i2},\cdots,\alpha_{iT})
αi=(αi1,αi2,⋯,αiT)
##注意力机制的改进
在Bahdanau提出注意力机制后不久,Luong又在其基础上把注意力机制分为全局注意力(globale attention)机制和局部注意力(local attention)机制。简单的来说,是使用全部的encoder的隐藏层还是部分。要进行预测,首先还是要获得这个上下文向量 c t c_t ct,这个上下文向量用来捕获源语言的相关信息来预测目标词 y t y_t yt,然后把decoder的隐藏状态 s t s_t st与这个上下文向量 c t c_t ct拼接起来通过非线性函数产生注意力隐藏状态(attentional hidden state):
h t ~ = t a n h ( W c [ c t ; s t ] ) (7) \tilde{h_t} = tanh(W_c[c_t;s_t])\tag{7} ht~=tanh(Wc[ct;st])(7)
最后,使用softmax函数进行预测:
p ( y t ∣ y < t , x ) = s o f t m a x ( W s h t ~ ) (8) p(y_t|y_{<t},x)=softmax(W_s\tilde{h_t})\tag{8} p(yt∣y<t,x)=softmax(Wsht~)(8)
现在的重点还是怎么获得上下文向量 c t c_t ct。
###Global Attention
其实global attention与Bahdanau的一样,都是使用了全部的encoder的隐藏状态。在模型中,注意力向量 α t = ( α t 1 , α t 2 , ⋯ , α t T ) \alpha_t=(\alpha_{t1},\alpha_{t2},\cdots,\alpha_{tT}) αt=(αt1,αt2,⋯,αtT),每一个 α t j = e x p ( e t j ) Σ k = 1 T e x p ( e t k ) \alpha_{tj}=\frac{exp(e_{tj})}{\Sigma_{k=1}^Texp(e_{tk})} αtj=Σk=1Texp(etk)exp(etj),而
e t j = { s t ′ h j , d o t s t ′ W α h j , g e n e r a l v α ′ t a n h ( W α [ s t ; h j ] ) , c o n c a t (9) e_{tj}=\begin{cases}s_t^{'}h_j, & dot\\ s_t^{'}W_\alpha h_j, & general\\ v_\alpha^{'}tanh(W_\alpha[s_t;h_j]), & concat \end{cases}\tag{9} etj=⎩ ⎨ ⎧st′hj,st′Wαhj,vα′tanh(Wα[st;hj]),dotgeneralconcat(9)
其中, e t j e_{tj} etj就是上面所说的对应模型,也是得分函数,而 s t ′ s_t^{'} st′为decoder第t时间步隐藏层状态的转置, h j h_j hj为encoder的第 j j j时间步的隐藏状态,$W_\alpha,v_\alpha 是可训练参数。最后算出 是可训练参数。 最后算出 是可训练参数。最后算出c_t$:
c t = Σ j = 1 T α t j h j c_t = \Sigma_{j=1}^T\alpha_{tj}h_j ct=Σj=1Tαtjhj
(这里注意一点,不要认为计算 e t j e_{tj} etj的时候应该用 s t − 1 s_{t-1} st−1,因为这个模型在计算计算 s t s_t st的时候没有用到 c t c_t ct,要与Bahdanau的相区别)
global attention的图示如下:

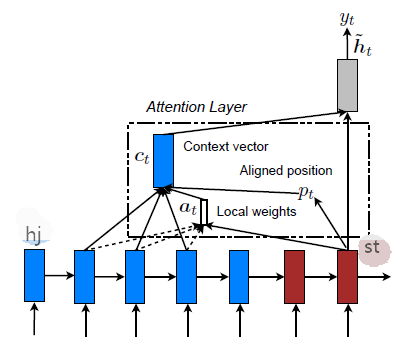
Local Attention
Local attention就是选择一个较小的上下文向量窗口,具体来说,模型在时间步 t t t首先为每个目标词产生一个对应位置 p t p_t pt,而这个 c t c_t ct就是在这个对应位置上下文窗口 [ p t − D , p t + D ] [p_t-D, p_t+D] [pt−D,pt+D]中encoder的隐藏状态的加权平均,这个 D D D是自己选择的(如果这个窗口到达了句子的边界,那么只考虑在窗口中词,忽略其他部分)。不同于global attention的 α t \alpha_t αt,local attention的 α t \alpha_t αt是一个固定维度的向量,即 ∈ R 2 D + 1 \in R^{2D+1} ∈R2D+1。而local attention又有两个变体:
- Monotonic alignment(local-m),即认为目标序列与源序列是单调对应的,所以设置 p t = t p_t=t pt=t,然后计算 α t \alpha_t αt
- Predictive alignment(local-p),此方法是预测一个对应位置:
p t = L ∗ s i g m o i d ( v p ′ t a n h ( W p s t ) ) (10) p_t = L*sigmoid(v_p^{'}tanh(W_ps_t))\tag{10} pt=L∗sigmoid(vp′tanh(Wpst))(10)
其中, W p 和 v p W_p和v_p Wp和vp是预测未知的参数,可用梯度下降法计算, L L L为源语言句子的长度, p t ∈ [ 0 , L ] p_t\in [0,L] pt∈[0,L]。然后Luong使用了一个高斯分布来修正词对位权重 α t \alpha_t αt:
α t = : α t e x p ( − ( x − p t ) 2 2 σ 2 ) \alpha_t =: \alpha_texp(-\frac{(x-p_t)^2}{2\sigma^2}) αt=:αtexp(−2σ2(x−pt)2)
其中,设置的标准差为 σ = D / 2 \sigma=D/2 σ=D/2,注意, p t p_t pt是一个实数,而 x x x是以 p t p_t pt为中心窗口内的整数。
具体的local attention结构表示图如下:
Input-feeding方法
其实这一步与Bahdanau的方法一样,是把最后的注意力隐藏状态
h
t
~
\tilde{h_t}
ht~与输出拼接后作为下一时间步的输入,这样模型能有效获得前面的对位信息,图示如下:
训练
Luong的训练使用的是WMT’14训练集,两种语言字典大小50K,不在字典内的词用< unk>表示
- 过滤掉超过50字的句子并进行混洗
- 4层LSTM,每层1000个cell,1000维度的词向量
- 参数使用均匀分布[-0.1,0.1]初始化
- 使用SGD训练10轮
- 首先用学习率1开始,5轮后,每轮对学习率减半
- min-batch大小为128
- dropout=0.2,使用dropout时,进行12轮,8轮后每轮对学习率减半
- 对于local attention模型,设置D为10
Luong与Bahdanau模型的不同之处:
- 使用结构不同,Bahdanau使用双向RNN,而Luong又变为单向的RNN。
- Luong在Bahdanau的基础上把注意力机制分为global attention和local attention方法
- 在计算decoder的 s t s_t st的时候,Bahdanau使用了 s t − 1 , y t − 1 , c t s_{t-1}, y_{t-1},c_t st−1,yt−1,ct,而Luong用了 s t − 1 , y t − 1 , h ~ t − 1 s_{t-1},y_{t-1},\tilde{h}_{t-1} st−1,yt−1,h~t−1,没有用 c t c_t ct,这在前面计算Luong的得分 e t j e_{tj} etj的时候也说了
- 在计算输出概率的时候,Bahdanau是把上下文向量
c
t
c_t
ct与decoder的隐藏状态
s
t
s_t
st直接作为参数经过非线性变换得到概率
p
(
y
t
∣
y
1
,
⋯
,
y
t
−
1
,
x
)
p(y_t|y_1,\cdots,y_{t-1},x)
p(yt∣y1,⋯,yt−1,x),而Luong是先把
c
t
c_t
ct和
s
t
s_t
st拼接在一起,经过非线性变换得到注意力隐藏向量
h
t
~
\tilde{h_t}
ht~,最后再经过softmax函数进行预测
##神经网络机器翻译的几个问题
神经网络机器翻译相比于其他统计机器翻译有很多的优势,例如NMT需要很少的领域知识,整个系统可以一起优化以及占用内存较小等。尽管有很多优点,但还有一些其他问题困扰着NMT,例如目标词汇数量可能受到限制,这是由于训练的复杂性而引起的。实践中大多使用的目标词汇为30000至80000,其他生词用[UNK]表示,但如果翻译后的目标语言中有[UNK]怎么处理呢。对于这个问题一般有两种解法:一是仍然使用大的目标词汇字典,但可使用不同的方法提高运算效率,把最后的softmax改成别的函数,如NCE(Noise Contrastive Estimation)、Hierarchical softmax等;二是仍然使用有限的字典,不过是要处理翻译出的[UNK],例如基于字符的方法,混合的方法等。本次主要讲两种方法,一种是使用大的目标字典的方法,另一种是解决输出[UNK]的方法。
##基于大的目标字典的方法
Jean根据Bahdanau的模型使用了一个非常大的目标字典来训练NMT,但是由于输出的概率是使用softmax计算,如下式:
p ( y t ∣ y < t , x ) = 1 Z e x p { w t ′ ϕ ( y t − 1 , s t , c t ) + b t } (11) p(y_t|y_{<t},x)=\frac{1}{Z}exp\{w_t^{'}\phi(y_{t-1},s_t,c_t)+b_t\}\tag{11} p(yt∣y<t,x)=Z1exp{wt′ϕ(yt−1,st,ct)+bt}(11)
而计算成本最高的就是softmax的正则化项 Z Z Z,所以Jean在大目字典上提出了一种近似学习方法
首先考虑对(11)式求对数梯度:
▽ l o g p ( y t ∣ y < t , x ) = ▽ ϵ ( y t ) − Σ k : y k ∈ V p ( y k ∣ y < t , x ) ▽ ϵ ( y k ) (12) \bigtriangledown logp(y_t|y_{<t},x)=\bigtriangledown\epsilon(y_t)-\Sigma_{k:y_k\in V}p(y_k|y_{<t},x)\bigtriangledown\epsilon(y_k)\tag{12} ▽logp(yt∣y<t,x)=▽ϵ(yt)−Σk:yk∈Vp(yk∣y<t,x)▽ϵ(yk)(12)
其中,能量函数 ϵ ( y j ) = w j ′ ϕ ( y j − 1 , s j , c j ) + b j \epsilon(y_j)=w_j^{'}\phi(y_{j-1},s_j,c_j)+b_j ϵ(yj)=wj′ϕ(yj−1,sj,cj)+bj
公式(12)右边的第二项就是能量函数梯度的期望:
E P [ ▽ ϵ ( y ) ] (13) E_P[\bigtriangledown\epsilon(y)]\tag{13} EP[▽ϵ(y)](13)
其中, P P P表示为 p ( y ∣ y < t , x ) p(y|y_{<t},x) p(y∣y<t,x)
现在是怎样估计或近似这个期望Jean使用了重要性抽样(importance sampling)方法,即找到一个提议分布(proposal distribution) Q Q Q和从提议分布中抽取的样本 V s V^{s} Vs,那么可由下式近似估计(13)式:
E P [ ▽ ϵ ( y ) ] ≈ Σ k : y k ∈ V s ω k Σ k ′ : y k ′ ∈ V s ω k ′ [ ▽ ϵ ( y k ) ] (14) E_P[\bigtriangledown\epsilon(y)]\thickapprox \Sigma_{k:y_k\in V^{s}}\frac{\omega_k}{\Sigma_{k^{'}:y_{k^{'}}\in V^{s}}\omega_{k^{'}}}[\bigtriangledown\epsilon(y_k)]\tag{14} EP[▽ϵ(y)]≈Σk:yk∈VsΣk′:yk′∈Vsωk′ωk[▽ϵ(yk)](14)
其中:
ω k = e x p { ϵ ( y k ) − l o g Q ( y k ) } (15) \omega_k=exp\{\epsilon(y_k)-logQ(y_k)\}\tag{15} ωk=exp{ϵ(yk)−logQ(yk)}(15)
在这里只是使用了一个目标字典的较小的一个子集 V s V^{s} Vs就能计算出正则项。但是怎么选择这个提议分布呢?首先Jean在实践中把训练语料进行分区,在训练前,对每个分区定义一个目标词汇子集 V ′ V^{'} V′,然后顺序扫描句子,抽取不同的单词,直到到达一个阈值 τ = ∣ V ′ ∣ \tau=|V^{'}| τ=∣V′∣,这些句子就作为一个分区,而这个词汇子集就用于这个分区的训练,重复上述过程直到把训练目标句子分区完。假设第 i i i个分区用的目标词典为 V i ′ V_i^{'} Vi′,对于每一个分区都对应一个 Q i Q_i Qi,在 V i ′ V_i^{'} Vi′内,每一个目标词都具有相同的概率,而不在 V i ′ V_i^{'} Vi′内的概率为0:
Q i ( y k ) = { 1 ∣ V i ′ ∣ i f y t ∈ V i ′ 0 o t h e r w i s e (16) Q_i(y_k)=\begin{cases} \frac{1}{|V_i^{'}|} & if\quad y_t\in V_i^{'}\\ 0 & otherwise \end{cases}\tag{16} Qi(yk)={∣Vi′∣10ifyt∈Vi′otherwise(16)
而这个提议分布可以抵消(15)式的校正项 − l o g Q ( y k ) -logQ(y_k) −logQ(yk),非常简单,我们来推导一下:
ω k = e x p { ϵ ( y k ) − l o g Q ( y k ) } = e x p { ϵ ( y k ) − l o g 1 ∣ V i ′ ∣ } = e x p { ϵ ( y k ) + l o g ∣ V i ′ ∣ } = e x p { ϵ ( y k ) + l o g τ } \omega_k = exp\{\epsilon(y_k)-logQ(y_k)\}\\ =exp\{\epsilon(y_k)-log\frac{1}{|V_i^{'}|}\}\\ =exp\{\epsilon(y_k)+log|V_i^{'}|\}\\ =exp\{\epsilon(y_k)+log\tau\} ωk=exp{ϵ(yk)−logQ(yk)}=exp{ϵ(yk)−log∣Vi′∣1}=exp{ϵ(yk)+log∣Vi′∣}=exp{ϵ(yk)+logτ}
最后得到与(11)式近似的概率:
p ( y t ∣ y < t , x ) = e x p { w t ′ ϕ ( y t − 1 , s t , c t ) + b t } Σ k : y k ∈ V ′ e x p { w k ′ ϕ ( y t − 1 , s t , c t ) + b k } (17) p(y_t|y_{<t},x)=\frac{exp\{w_t^{'}\phi(y_{t-1},s_t,c_t)+b_t\}}{\Sigma_{k:y_k\in V^{'}}exp\{w_k^{'}\phi(y_{t-1},s_t,c_t)+b_k\}}\tag{17} p(yt∣y<t,x)=Σk:yk∈V′exp{wk′ϕ(yt−1,st,ct)+bk}exp{wt′ϕ(yt−1,st,ct)+bt}(17)
这里的 V ′ V^{'} V′就是 V i ′ V_i^{'} Vi′,注意,提议分布 Q Q Q得到的估计式有偏的。
在解码的时候,我们可以使用整个目标字典,但是计算成本很大,一个自然地想法就是使用一部分目标字典而不是整个,Jean使用了一个候选列表(candidate list)构建字典子集,这个候选列表包括两部分:一部分是在训练集中使用词对位模型(Bahdanau模型,
α
i
j
\alpha_{ij}
αij越大,则第i个目标词与第j个源语言词对位的概率越大)对应源语言和目标语言的单词,并构建一个字典,根据这个字典,找到每个源语言句子的每个单词的前
K
′
K^{'}
K′个最相近的目标词;第二部分是对每一个源语言句子,构建一个由前
K
K
K个最大频率词(可以根据一元模型计算)组成的目标词汇集(在这里每个句子的前
K
K
K个最大频率词应该是一样的)。如下图表示:

处理[UNK]单词
不管是使用大的目标词字典还是小的目标词字典,总会有出现的生词,而在翻译中生词都是表示为[UNK]字符,这会造成信息的缺失,所以还原单词信息是翻译中非常重要的一步。
对于这种问题,Gulcehre认为要么是从源语言中直接复制单词过去要么是用模型进行解码生成单词。如下图所示:

他们把这两种方式整合到一个模型中去。所以他们提出了pointer softmax模型。
他们额模型仍然以Bahdanau为基础,对输出概率形式进行改进。Gulcehre的模型使用两种softmax,shortlist softmax和location softmax,前一种就是普通的softmax,每一维度对应一个字典中的词,后一种是每一个输出维度对应源语言序列一个单词的位置,然后把该单词复制过去。关键是怎么选择这两种softmax,Gulcehre使用的是一个开关网络,它输出的是一个二元变量
z
t
z_t
zt,其表明是使用shortlist softmax(当
z
t
=
1
z_t=1
zt=1)还是使用location softmax(当
z
t
=
0
z_t=0
zt=0),如果时间步中期望产生的单词既不在字典中,也没有复制源语言句子的单词,那么开关网络就选择shortlist softmax,这样会产生一个[UNK]。整个示意图如下:

具体来说,给定一个输入序列
x
=
(
x
1
,
x
2
,
⋯
,
x
T
)
x = (x_1,x_2,\cdots,x_{T})
x=(x1,x2,⋯,xT),我们的目标就是最大化目标单词序列
y
=
(
y
1
,
y
2
,
⋯
,
y
T
′
)
y=(y_1,y_2,\cdots, y_{T^{'}})
y=(y1,y2,⋯,yT′)和单词生成
z
=
(
z
1
,
z
2
,
⋯
,
z
T
′
)
z=(z_1,z_2,\cdots, z_{T^{'}})
z=(z1,z2,⋯,zT′):
p
θ
(
y
,
z
∣
x
)
=
Π
t
=
1
T
′
p
θ
(
y
t
,
z
t
∣
y
<
t
,
z
<
t
,
x
)
(18)
p_\theta(y,z|x)=\Pi^{T^{'}}_{t=1}p_\theta(y_t,z_t|y_{<t},z_{<t},x)\tag{18}
pθ(y,z∣x)=Πt=1T′pθ(yt,zt∣y<t,z<t,x)(18)
其中,产生的
y
t
y_t
yt可以是shortlist softmax产生的单词
w
t
w_t
wt,也可以是location softmax产生的位置
l
t
l_t
lt(这个
l
t
l_t
lt就是前面所说的词对应权重
α
t
\alpha_t
αt)。
把上式因式分解:
p
(
y
,
z
∣
x
)
=
Π
t
∈
T
w
p
(
w
t
,
z
t
∣
(
y
,
z
)
<
t
,
x
)
×
Π
t
′
∈
T
l
p
(
l
t
′
,
z
t
′
∣
(
y
,
z
)
<
t
′
,
x
)
(19)
p(y,z|x)=\Pi_{t\in T_w}p(w_t,z_t|(y,z)_{<t},x)\times \Pi_{t^{'}\in T_l}p(l_{t^{'}},z_{t^{'}}|(y,z)_{<t^{'}},x)\tag{19}
p(y,z∣x)=Πt∈Twp(wt,zt∣(y,z)<t,x)×Πt′∈Tlp(lt′,zt′∣(y,z)<t′,x)(19)
其中,
T
w
T_w
Tw是
z
t
=
1
z_t=1
zt=1的时间步集合,
T
l
T_l
Tl是
z
t
=
0
z_t=0
zt=0的时间步集合,
T
w
⋃
T
l
=
{
1
,
2
,
⋯
,
T
′
}
T_w\bigcup T_l=\{1,2,\cdots, T^{'}\}
Tw⋃Tl={1,2,⋯,T′},
T
w
⋂
T
l
=
∅
T_w\bigcap T_l=\emptyset
Tw⋂Tl=∅
等式右边的概率可以分别表示如下:
p
(
w
t
,
z
t
∣
(
y
,
z
)
<
t
)
=
p
(
w
t
∣
z
t
,
(
y
,
z
)
<
t
)
×
p
(
z
t
=
1
∣
(
y
,
z
)
<
t
)
(20)
p(w_t,z_t|(y,z)_{<t})=p(w_t|z_t,(y,z)_{<t})\times p(z_t=1|(y,z)_{<t})\tag{20}
p(wt,zt∣(y,z)<t)=p(wt∣zt,(y,z)<t)×p(zt=1∣(y,z)<t)(20)
p
(
l
t
,
z
t
∣
(
y
,
z
)
<
t
)
=
p
(
l
t
∣
z
t
=
0
,
(
y
,
z
)
<
t
)
×
p
(
z
t
=
0
∣
(
y
,
z
)
<
t
)
(21)
p(l_t,z_t|(y,z)_{<t})=p(l_t|z_t=0,(y,z)_{<t})\times p(z_t=0|(y,z)_{<t})\tag{21}
p(lt,zt∣(y,z)<t)=p(lt∣zt=0,(y,z)<t)×p(zt=0∣(y,z)<t)(21)
这里都省略了
x
x
x,其中,
p
(
w
t
∣
z
t
,
(
y
,
z
)
<
t
,
x
)
p(w_t|z_t,(y,z)_{<t},x)
p(wt∣zt,(y,z)<t,x)为shortlist softmax,
p
(
l
t
∣
z
t
=
0
,
(
y
,
z
)
<
t
)
p(l_t|z_t=0,(y,z)_{<t})
p(lt∣zt=0,(y,z)<t)为location softmax。而开关概率可以作为一个有二元输出的多层感知机:
p
(
z
t
=
1
∣
(
y
,
z
)
<
t
,
x
)
=
σ
(
f
(
x
,
h
t
−
1
;
θ
)
)
(22)
p(z_t=1|(y,z)_{<t},x)=\sigma(f(x,h_{t-1};\theta))\tag{22}
p(zt=1∣(y,z)<t,x)=σ(f(x,ht−1;θ))(22)
p
(
z
t
=
0
∣
(
y
,
z
)
<
t
,
x
)
=
1
−
σ
(
f
(
x
,
h
t
−
1
;
θ
)
)
(23)
p(z_t=0|(y,z)_{<t},x)=1-\sigma(f(x,h_{t-1};\theta))\tag{23}
p(zt=0∣(y,z)<t,x)=1−σ(f(x,ht−1;θ))(23)
其中,
σ
\sigma
σ为sigmoid函数。
那么,给定
N
N
N个源语言句子和目标语言句子对,训练的目标就是最大化下式:
m
a
x
1
N
Σ
n
=
1
N
l
o
g
p
θ
(
y
n
,
z
n
∣
x
n
)
(24)
max\quad \frac{1}{N}\Sigma^N_{n=1}logp_\theta(y_n,z_n|x_n)\tag{24}
maxN1Σn=1Nlogpθ(yn,zn∣xn)(24)
使用Google的一篇文章对它的评价作为结束:
this approach is both unreliable at scale — the attention mechanism is unstable when the network is deep — and copying may not always be the best strategy for rare words —sometimes transliteration is more appropriate
主要参考文献
【Ilya Sutskever, Oriol Vinyals, Quoc V. Le】Sequence to Sequence Learning with Neural Networks
【Dzmitry Bahdanau, KyungHyun Cho, Yoshua Bengio】NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
【Minh-Thang Luong, Hieu Pham, Christopher D. Manning】Effective Approaches to Attention-based Neural Machine Translation
【S´ebastien Jean, Kyunghyun Cho, Roland Memisevic, Yoshua Bengio】On Using Very Large Target Vocabulary for Neural Machine Translation
【Caglar Gulcehre, Sungjin Ahn, Ramesh Nallapati, Bowen Zhou, Yoshua Bengio】Pointing the Unknown Words

















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









