




mask-rcnn
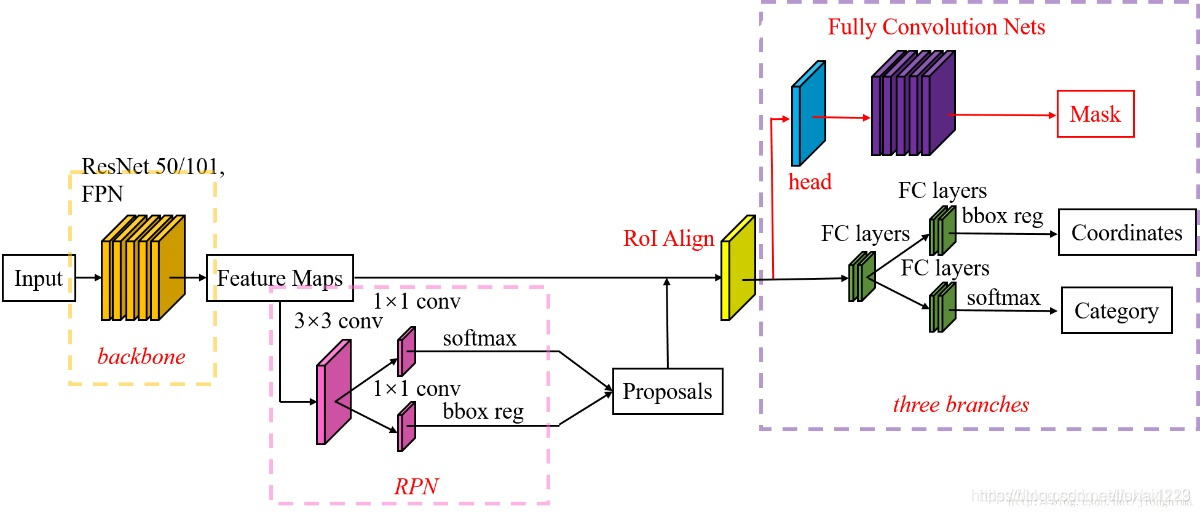
Mask RCNN沿用了Faster RCNN的思想,特征提取采用ResNet-FPN的架构,另外多加了一个Mask预测分支,ResNet-FPN+Fast RCNN+Mask,实际上就是Mask RCNN。
Faster RCNN本身的细节非常多。如果对Faster RCNN算法不熟悉,想了解更多的可以看这篇文章:一文读懂Faster RCNN,这是我看过的解释得最清晰的文章。
一、mask-rcnn整体结构图
结合物体检测和图像分割为一体的网络结构
二、ResNet-FPN特征提取
详细结构图如下
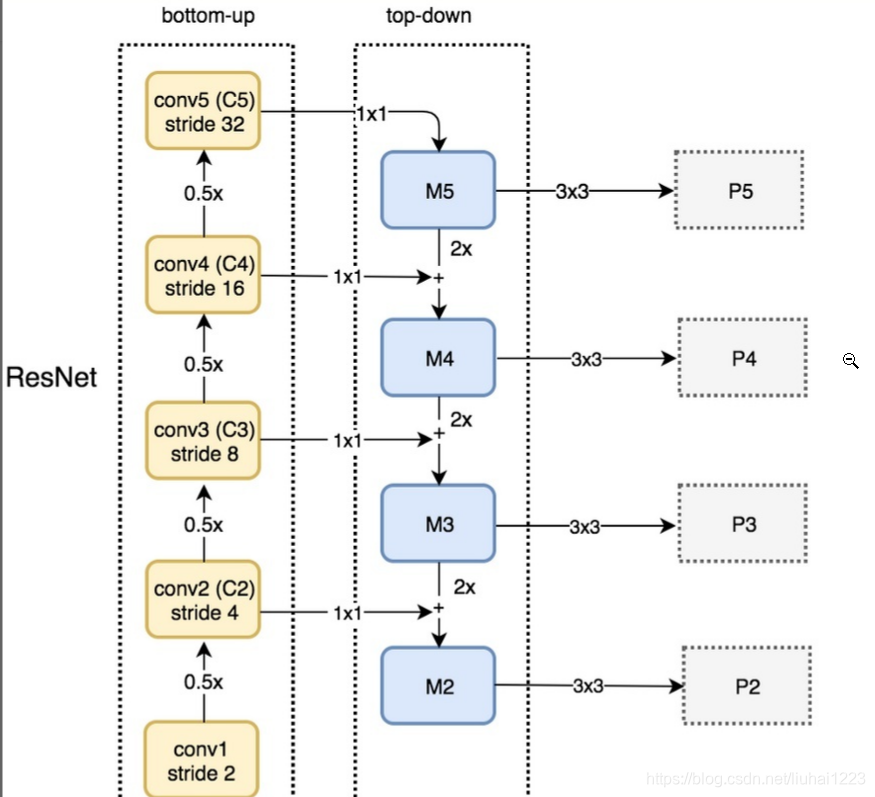
M 经过 3*3卷积核生成 channel 256 的特征图
生成特征图【p2,p3,p4,p5,p6】
那各个特征图对应到原图的步长依次为[P2,P3,P4,P5,P6]=>[4,8,16,32,64]
将P5进行步长为2的最大池化操作得到:16 * 16 * 256,记为P6
三、anchor的生成
四、rpn网络
4.1生成rpn网络数据集
在上一步已经生成了26188个Anchor锚框,需要借助这些Anchors建立RPN网络训练时的正类和负类
- 计算每个Anchors与该图片上标注的真实框ground truth之间的IOU
-
如果anchor box与ground truth的IoU值最大,标记为正样本,label=1
-
如果anchor box与ground truth的IoU>0.7,标记为正样本,label=1
-
如果anchor box与ground truth的IoU<0.3,标记为负样本,label=-1
-
剩下的既不是正样本也不是负样本,不用于最终训练,label=0
-
同时,保证正样本为128个,负样本为128个
2.计算anchor box与ground truth之间的偏移量
4.2 rpn训练
该部分主要根据上面的到的特征图rpn_feature_maps=[P2,P3,P4,P5,P6]生成以下数据:
rpn_class_logits:[batch_size,H * W * anchors_per_location,2] anchors分类器logits(在softmax之前)
rpn_probs:[batch_size,H * W * anchors_per_location,2] anchors分类器概率。
rpn_bbox:[batch_size,H * W * anchors_per_location,(dy,dx,log(dh),log(dw))] anchors的坐标偏移量
五、ProposalLayer
ProposalLayer的作用主要:
这一部分对应着总网络图中的ProposalLayer层,取出一定量的Anchors作为ROI,这个量由源码中参数POST_NMS_ROIS_TRAINING确定,假设这个参数在训练的时候设置为2000,则我们这里需要从261888个Anchors中取出2000个作为ROI
- 将rpn网路的输出应用到得到的anchors,首先对输出的概率进行排序(概率就是上一步得到的rpn_probs表示正样本和负样本的置信度),获取score靠前的前6000个anchor
- 利用rpn_bbox对anchors进行修正
- 舍弃掉修正后边框超过图片大小的anchor,由于我们的anchor的坐标的大小是归一化的,只要坐标不超过0 1区间即可
- 利用非极大抑制的方法获得最后的2000个anchor
六、DetectionTargetLayer
这一部分主要是生成RCNN网络数据集,最后DetectionTargetLayer层返回400个正、负样本,400个位移偏移量(其中300个由0填充),400个掩码mask信息(其中300个由0填充)

七、ROI Align 和RCNN网络的类别分类、回归、mask掩码分类
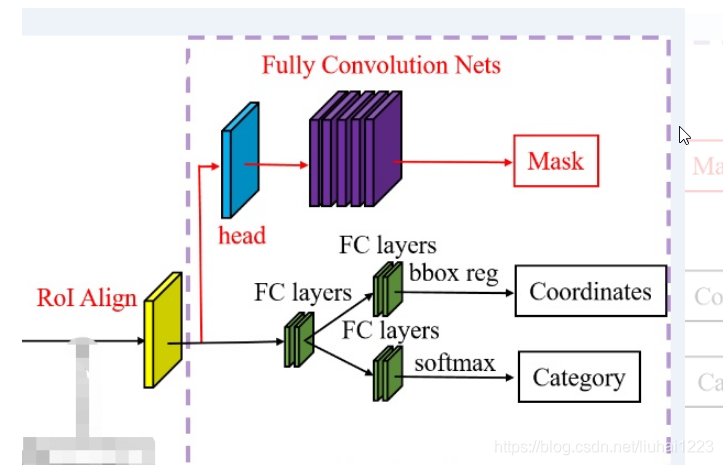
ROI Align 是在Mask-RCNN这篇论文里提出的一种区域特征聚集方式, 很好地解决了ROI Pooling操作中两次量化造成的区域不匹配(mis-alignment)的问题。
①RCNN网络的类别分类和回归与RPN网络中的分类和回归是一样的,损失函数也都是基于Softmax交叉熵和SmoothL1Loss,只是RPN网络中只分前景(正类)、背景(负类),而RCNN网络中的分类是要具体到某个类别(多类别分类)
②mask掩码分类

















 1536
1536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









