






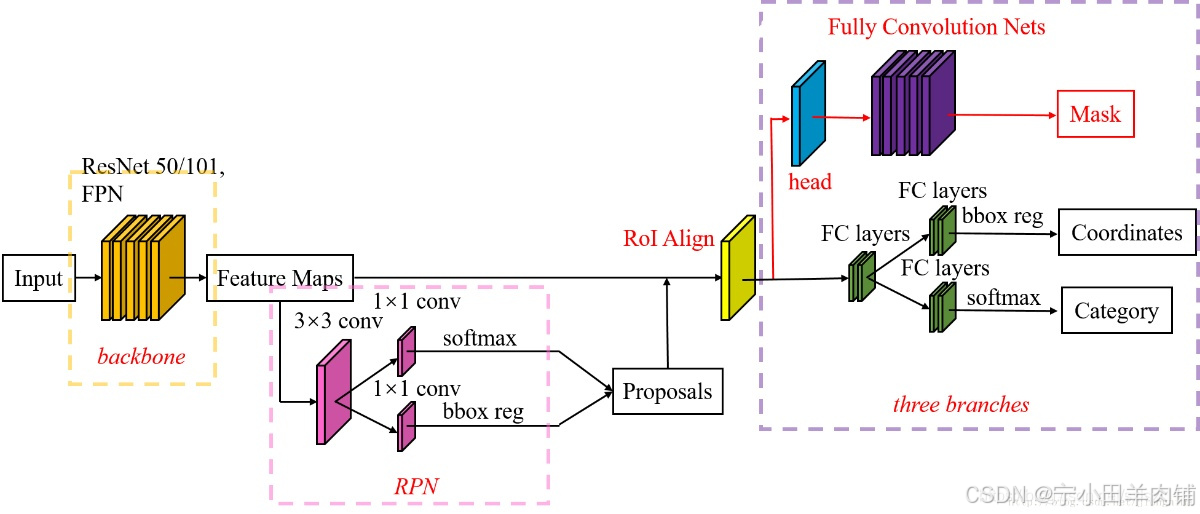
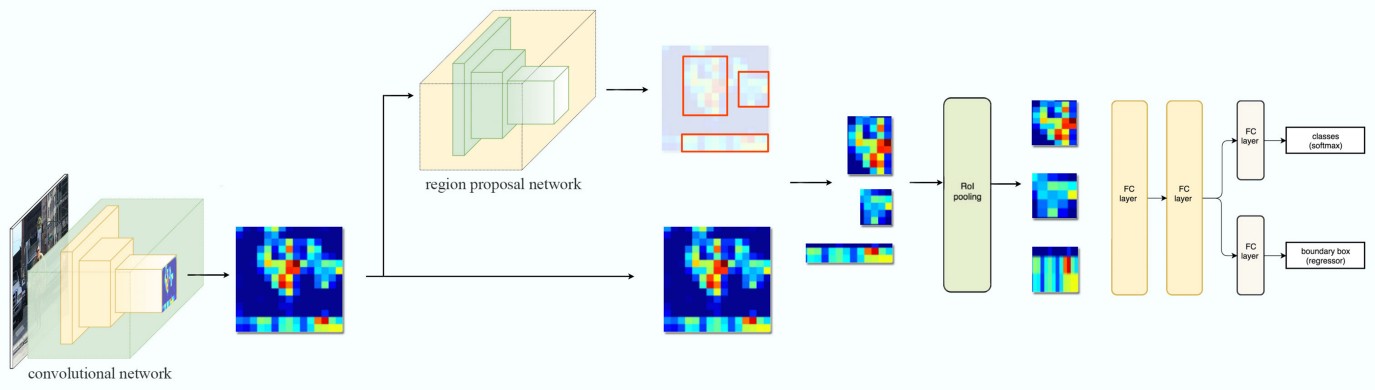
下面这张图是MaskRCNN算法结构图:
下面这张图是我根据代码画出来的(class MaskRCNN())代码逻辑结构图,有些地方确实不太好用简洁的方式表示,只把它当作大概的结构图看就行。

从上图可以看到,代码共分了7个部分,分别包括:
1,从下到上层
2,从上到下层与横向连接,
3,RPN
4,ProposalLayer
5,DetectionTargetLayer
6,头网络 Network Heads
7,计算各部分的损失
下面简要说一下各个部分分别完成了什么功能:
1,从下到上层
该层调用 BACKBONE = "resnet101"或者 BACKBONE = "resnet50"完成从原图到[C1, C2, C3, C4, C5] 5个特征图的操作。
该层的代码和逻辑关系如下图所示:

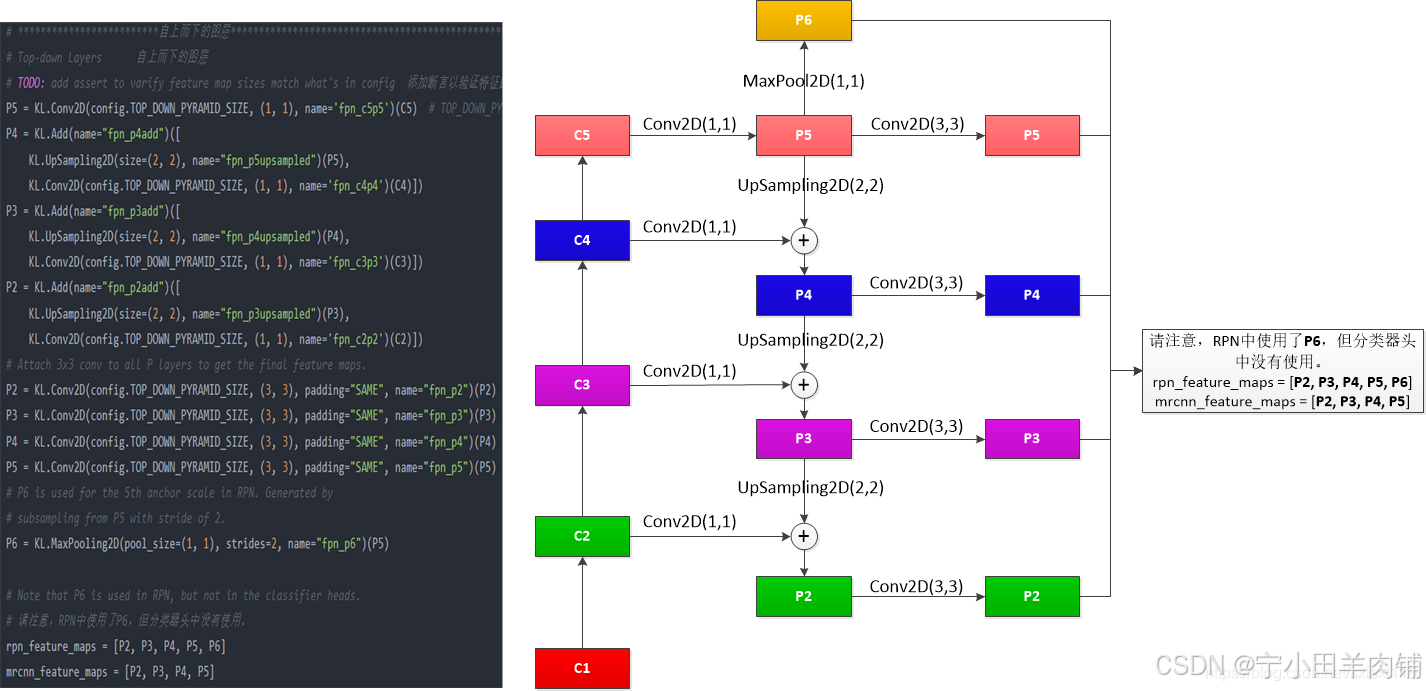
2,从上到下层与横向连接
基于从下到上得到的结果[C1, C2, C3, C4, C5],采用从上到下与横向连接的方式得到后面用到的特征图。其中:
P6由P5经过MaxPool而来,
P5由C5通过(1,1)的卷积核卷积而来,
P4由P5上采样结果与C4通过(1,1)的卷积核卷积结果相加得到,P4再由P4通过(3,3)的卷积核得到(目的是消除上采样带来的混叠效应)
P3由P4上采样结果与C3通过(1,1)的卷积核卷积结果相加得到,P3再由P3通过(3,3)的卷积核得到(目的是消除上采样带来的混叠效应)
P2由P3上采样结果与C2通过(1,1)的卷积核卷积结果相加得到,P2再由P2通过(3,3)的卷积核得到(目的是消除上采样带来的混叠效应)
最后由[P2,P3,P4,P5,P6]组成rpn_feature_maps用于RPN网络中,由[P2,P3,P4,P5]组成mrcnn_feature_maps用于后续的操作。
代码中在自下而上层后,RPN网络前会生成anchors:
anchors = input_anchors # 261888=256*256*3(P2)+128*128*3(P3)+64*64*3(P4)+32*32*3(P3)+16*16*3
3,RPN
该部分主要根据上面的到的特征图rpn_feature_maps=[P2,P3,P4,P5,P6]生成以下数据:
# rpn_class_logits:[batch_size,H * W * anchors_per_location,2] anchors分类器logits(在softmax之前)
# rpn_probs:[batch_size,H * W * anchors_per_location,2] anchors分类器概率。
# rpn_bbox:[batch_size,H * W * anchors_per_location,(dy,dx,log(dh),log(dw))] anchors的坐标偏移量
4,ProposalLayer
该部分 将第3步RPN网路的输出应用到第2步得到的anchors,
# ProposalLayer的作用主要
# 1. 根据rpn网络,获取score靠前的前6000个anchor
# 2. 利用rpn_bbox对anchors进行修正
# 3. 舍弃掉修正后边框超过图片大小的anchor,由于我们的anchor的坐标的大小是归一化的,只要坐标不超过0 1区间即可
# 4. 利用非极大抑制的方法获得最后的2000个anchor
5,DetectionTargetLayer
该部分将第5步得到的结果进行再次筛选,得到最终用于训练的200个正负样本。
# DetectionTargetLayer的输入包含了:target_rois, input_gt_class_ids, gt_boxes, input_gt_masks。
# 其中target_rois是第5步ProposalLayer输出的结果。
# 首先,计算target_rois中的每一个rois和哪一个真实的框gt_boxes iou值,
# 如果最大的iou大于0.5,则被认为是正样本,负样本是iou小于0.5并且和crowd box相交不大的anchor,
# 选择出了正负样本,还要保证样本的均衡性,具体可以在配置文件中进行配置。
# 最后计算了正样本中的anchor和哪一个真实的框最接近,用真实的框和anchor计算出偏移值,
# 并且将mask的大小resize成28 * 28 的(我猜测利用的是双线性差值的方式,因为mask的值不是0就是1,0是背景,一是前景)
# 这些都是后面的分类和mask网络要用到的真实的值
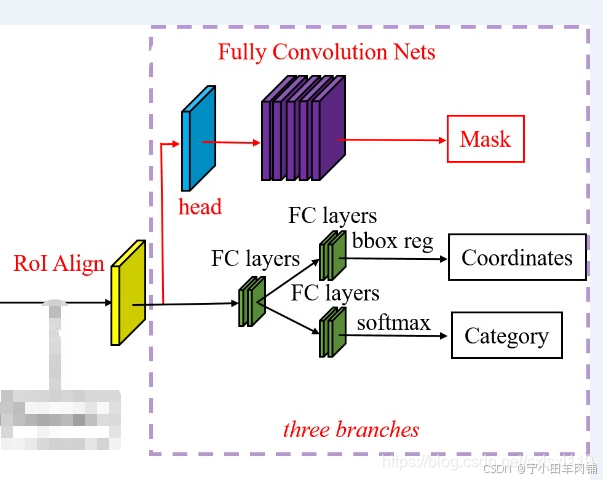
6,头网络 Network Heads
该部分包括3个分支,分别是 分类、回归操作、mask操作。对应算法结构图的以下部分。
7,计算各部分的损失
# maskrcnn中总共有五个损失函数,分别是rpn网络的两个损失,分类的两个损失,以及mask分支的损失函数。
# 前四个损失函数与fasterrcnn的损失函数一样,最后的mask损失函数的采用的是mask分支对于每个RoI有K*m^2维度的输出。
# k个(类别数)分辨率为m * m的二值mask。
# 因此作者利用了aper - pixelsigmoid,并且定义Lmask为平均二值交叉熵损失(the average binary cross - entropy loss).
# 对于一个属于第k个类别的RoI, Lmask仅仅考虑第k个mask(其他的掩模输入不会贡献到损失函数中)。
# 这样的定义会允许对每个类别都会生成掩模,并且不会存在类间竞争。
三,进一步解析:
下面会对各个部分的代码进行解析,不过拆成7个部分有点太碎了点,所以代码解析将按下面4块进行:
A),特征图与anchors生成
1,从下到上层
2,从上到下层与横向连接,anchors生成
B),RPN、ProposalLayer、DetectionTargetLayer
3,RPN
4,ProposalLayer
5,DetectionTargetLayer
C),头网络解析
6,头网络 Network Heads
D),损失部分解析
7,计算各部分的损失
一、实例分割
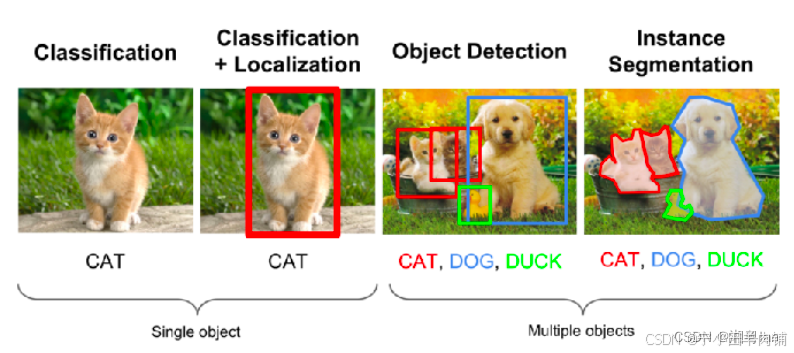
1.1 从分类到实例分割
Classification(分类):只对图像中的主要目标进行分类。
Classification + Localization(分类+定位):我们也想知道主要目标的边界框。
Objection Detection(目标检测):图像中有多个目标,我们想知道在已知类别中,每个目标的类别及边界框位置。
Instance Segmentation(实例分割):得到单个目标的分类结果,并得到每个目标的边界框位置。
1.2 实例分割的背景
语义分割通过对输入图像中每个像素的标签进行预测,给出了较好的推理,例如是前景还是背景。每个像素都根据其所在的对象类进行标记。为了进一步发展,实例分割为属于同一类的对象的单独实例提供了不同的标签。
目标检测:可以区分个体但不够准确。
语义分割:可以划分像素但不可以区分个体。
而实例分割则可以结合二者的优点,对个体的分类及定位更加精准。因此,实例分割可以定义为同时解决目标检测问题和语义分割问题的技术。
二、从RCNN、Fast RCNN、Faster RCNN,到Mask RCNN
入门计算机视觉的目标检测,那么RCNN、Fast RCNN,Faster RCNN的文章是无法避而不谈的。要很好地理解 Mask R-CNN 网络架构,最好从R-CNN来理解。
以下仅仅是对RCNN,Fast RCNN,Faster RCNN的简单回顾,如果需要详细了解,可以学习这篇博客。
2.1 RCNN
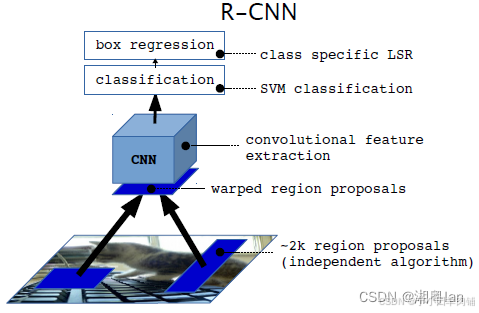
在网络的底部,基于非深度学习的选择性搜索 (SS) 用于特征提取以生成 2k 区域建议。
每个riigion proposall(区域提案) 都经过扭曲并通过卷积神经网络(CNN)和最后的支持向量机(SVM),输出分类和边界框。(因此效率很低)
(如果感兴趣,可以阅读《Faster RCNN超详细入门 01-准备篇-背景 RCNN,SPPnet,Fast RCNN,RoI Pooling》)
2.2 Fast RCNN
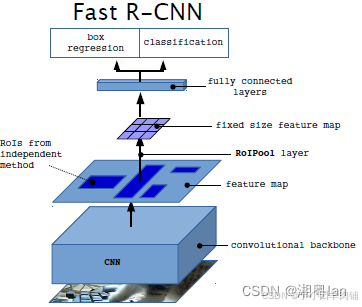
在Fast R-CNN中,区域提议部分仍然使用基于非深度学习的 SS 方法,SS 仍然用于生成 2k 个区域建议。
但是,与R-CNN不同的是,输入整张图像(而非每一个区域)经过 CNN 进行特征提取以生成特征图(这样就相当于共享了参数,提高了速度)。之后根据每个区域提议共享这些特征图以用于 RoI 池化。
对于每个区域提案,在提案上执行 RoI 池化,最终通过网络,即全连接(FC)层。并且不再使用 SVM。
最后,在全连接(FC)层的输出端输出分类和边界框。
2.3 Faster RCNN
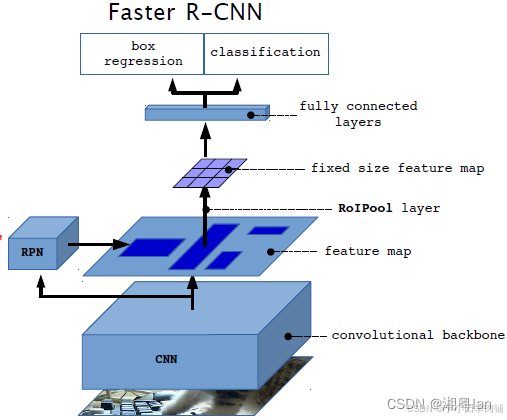
在Faster RCNN中,输入图像通过 CNN。这些特征图将用于区域提议网络(RPN)以生成区域提议,并用于生成特征图以用于稍后的 RoI 池化。
不再使用SS。 因此,整个网络是一个端到端的深度学习网络,对于梯度传播提高目标检测精度至关重要。
与Fast RCNN类似,对于每个 region proposal,RoI pooling 都在proposal 上进行,最后通过网络,即全连接层。最后,输出分类和边界框。
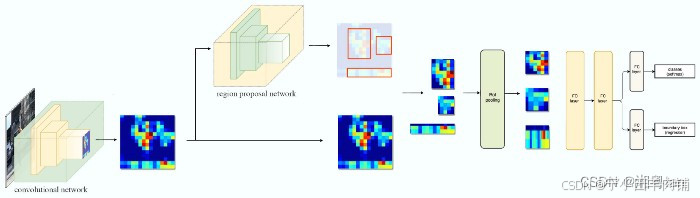
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
results = detector2(patch)
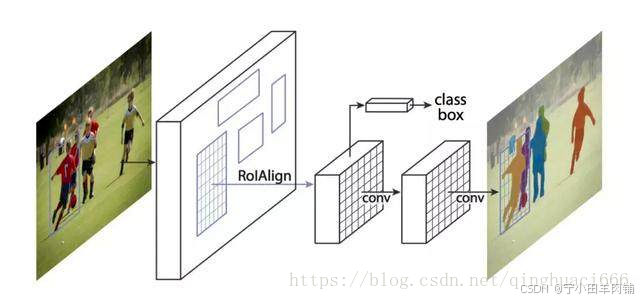
2.4 Mask RCNN
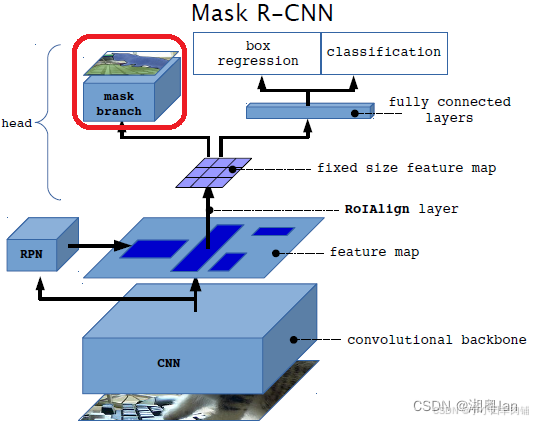
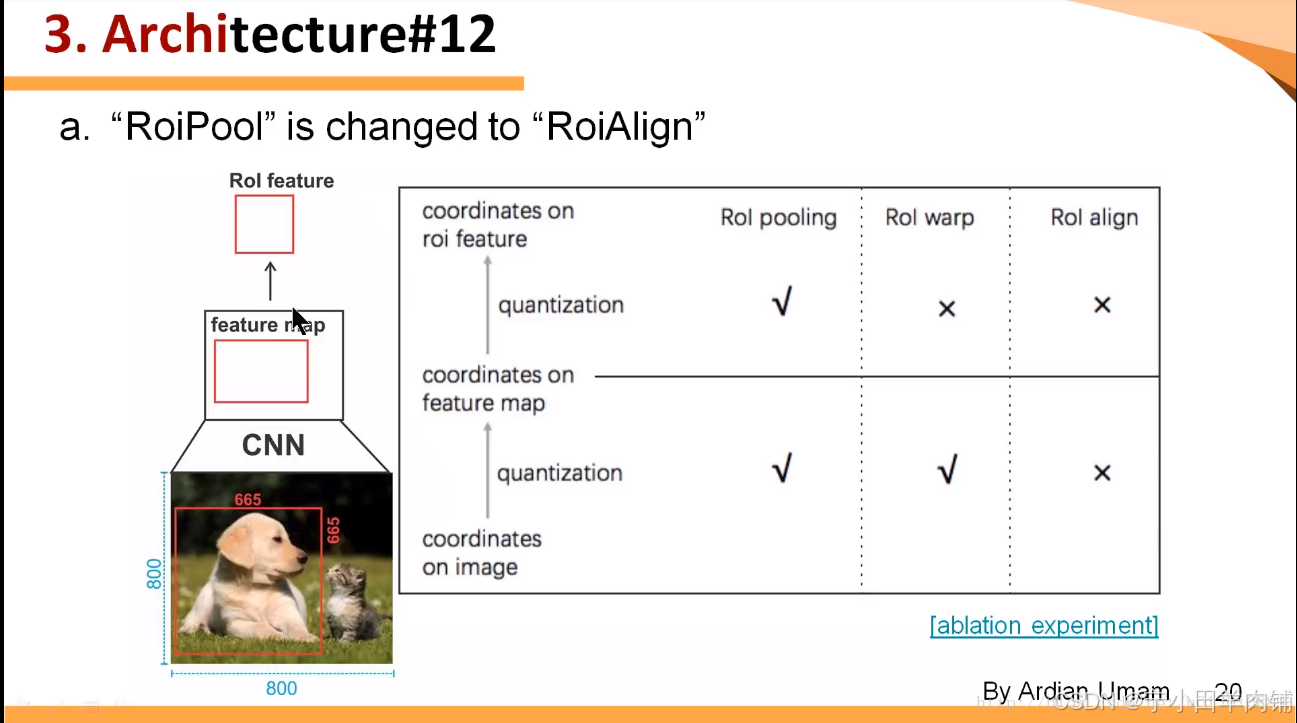
Mask RCNN,架构非常接近Faster RCNN。主要区别在于,在网络的末端,还有另一个头,即上图中的掩码分支,用于生成掩码进行实例分割。还有把Faster RCNN中的ROI Pooling换成了ROIAlign。(3.3会提到)
三、Mask RCNN网络概述
3.1 架构
两阶段
第一阶段:区域提案网络(RPN),提议候选对象边界框。每个区域提案都将经过第二阶段。
第二阶段:对于每个区域提议,第一阶段提出的特征图根据区域进行RoI池化,并通过剩余的网络,输出类别、边界框以及二进制掩码。(在 ROI 池化之后,作者又添加 2 个卷积层来构建掩码。
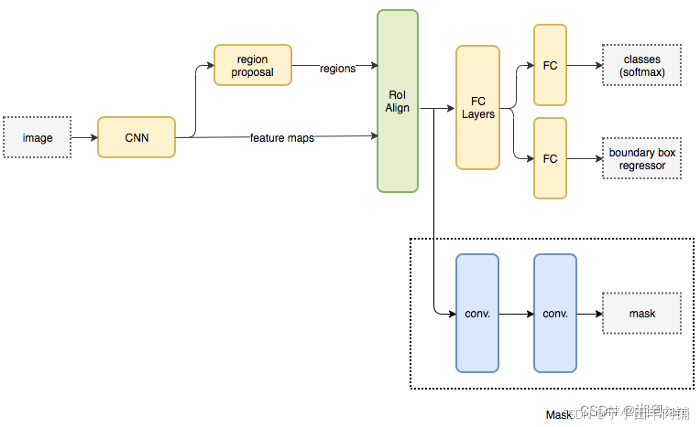
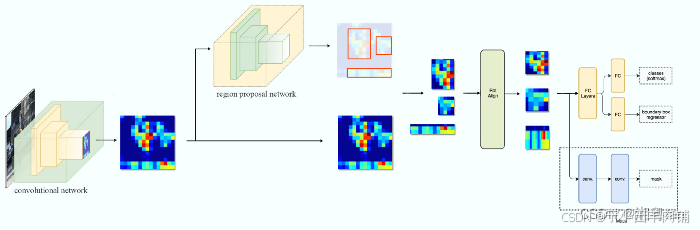
细节

RoI Align 网络输出多个边界框,而不是一个确定的边界框,并将它们扭曲成一个固定的维度(利用SSP net)。
然后将扭曲的特征输入全连接层,使用 softmax 进行分类,并使用回归模型进一步细化边界框预测。
扭曲的特征也被输入到 Mask 分类器中,该分类器由两个 CNN 组成,为每个 RoI 输出一个二进制掩码。掩码分类器允许网络为每个类生成掩码,而不会在类之间进行竞争。
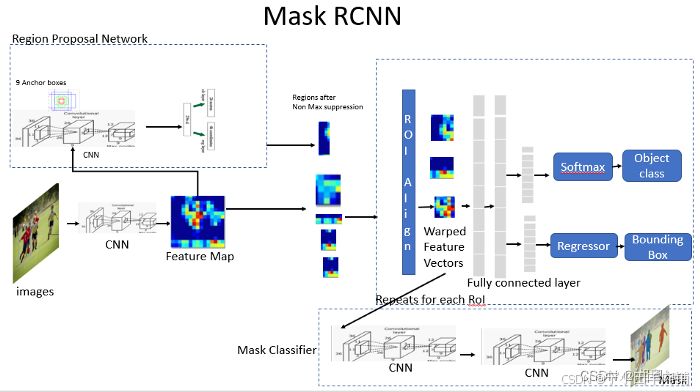
3.2 Loss Function(损失函数)
多任务损失函数:
![]()


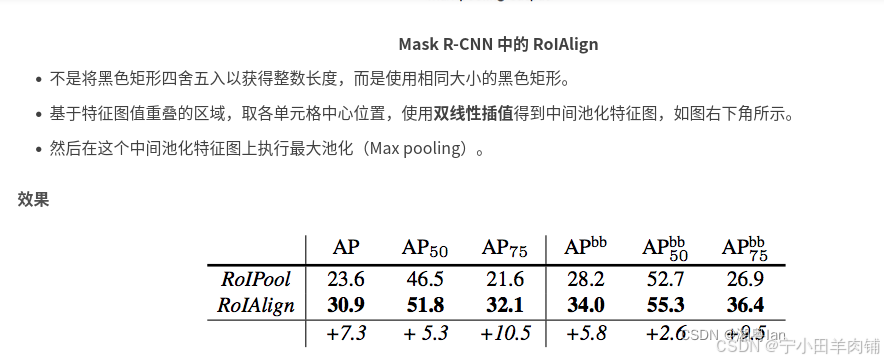
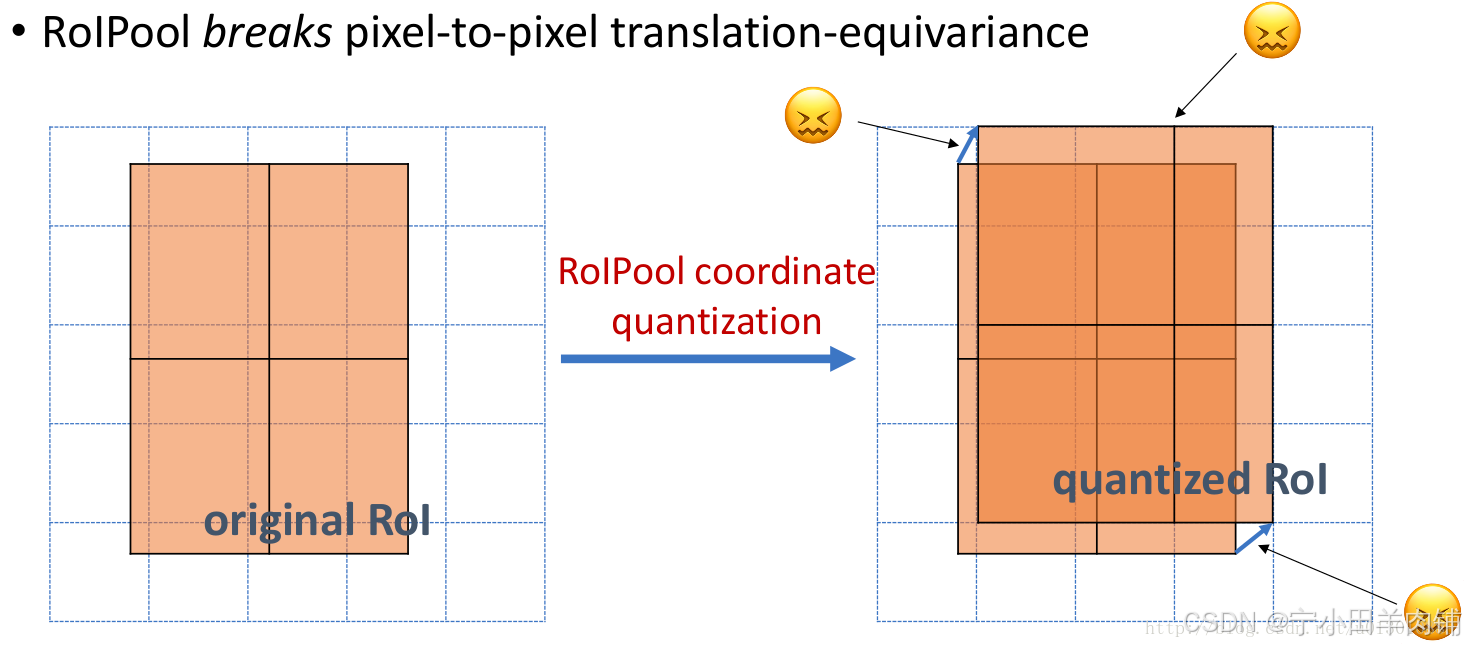
Mask R-CNN 的另一个主要贡献是对 ROI pooling的改进。在 ROI 中,卷积图被数字化(上图左上图):目标特征图的单元边界被迫与输入特征图的边界重新对齐。因此,每个目标单元格的大小可能不同(左下图),而这使得物体的预测边框与真实边框存在一个差距,这个差距在大物体检测时,误差可以接受,但在小物体检测时,误差就显得尤为难以接受。Mask R-CNN 使用ROI Align,它不会取整单元格的边界(右上)并使每个目标单元具有相同的大小(右下)。它还应用插值来更好地计算单元格内的特征图值。例如,通过应用插值,现在左上角的最大特征值从 0.8 变为 0.88。
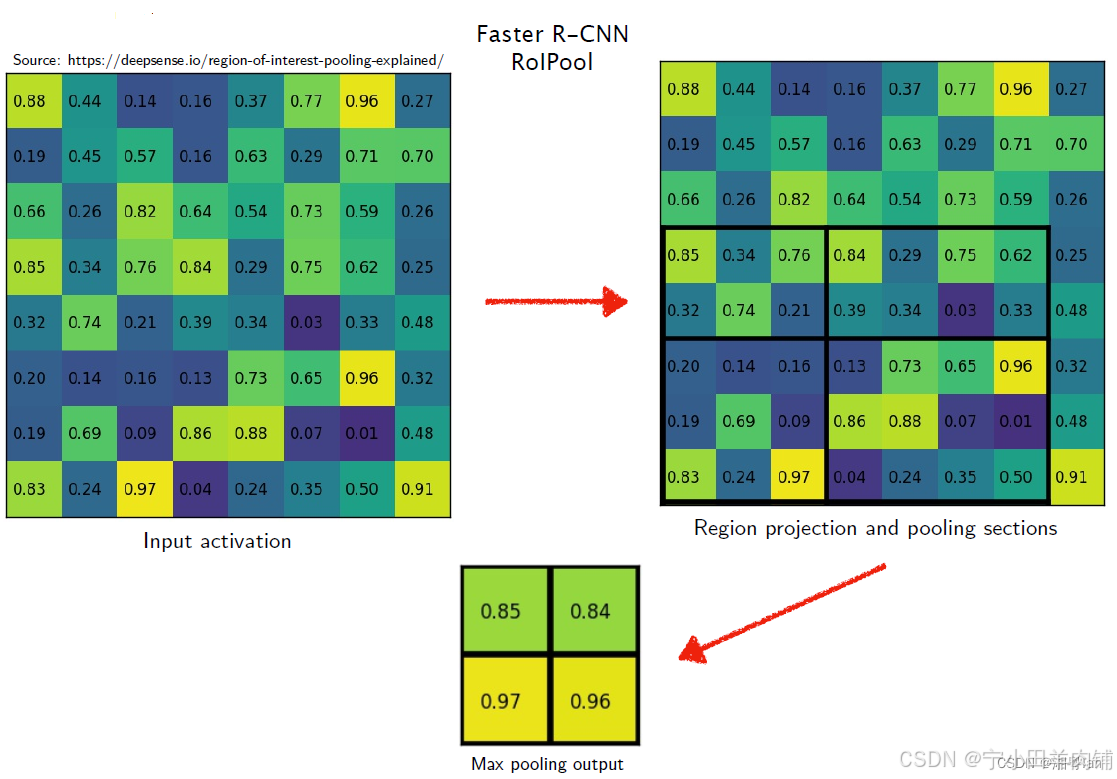
Roi Pooling vs Roi Align

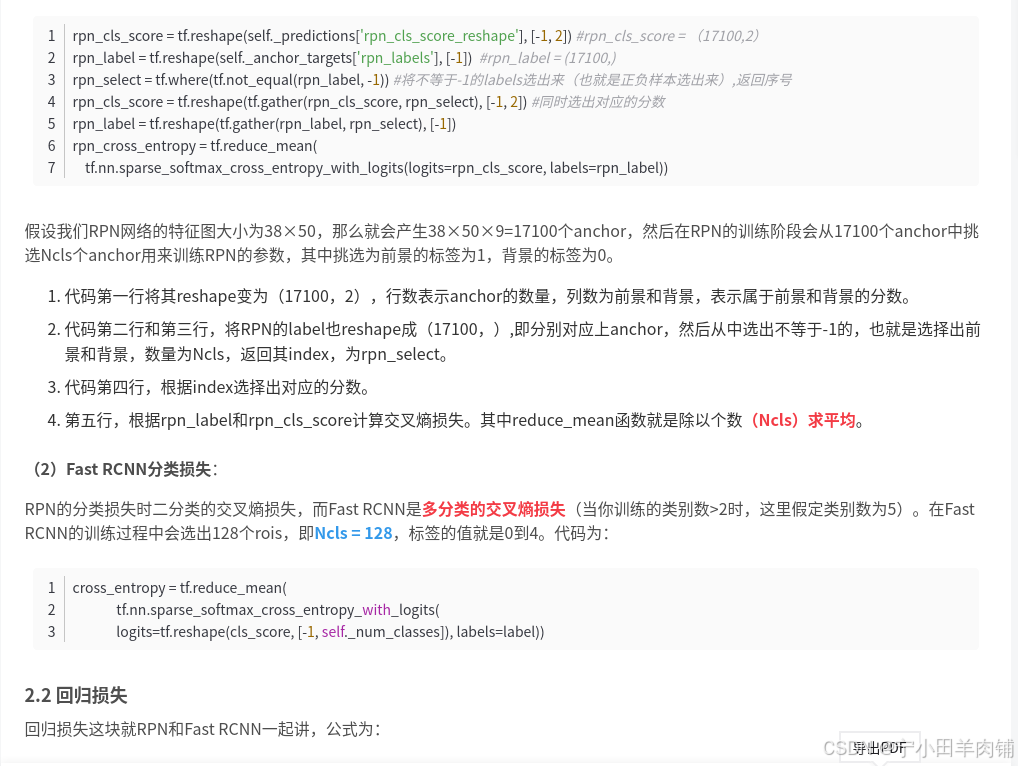
MaskRCNN:损失部分解析
损失部分解析
Mask RCNN中总共有五个损失函数,分别是rpn网络的两个损失,mrcnn的两个损失,以及mask分支的损失函数。
前四个损失函数与fasterrcnn的损失函数一样,最后的mask损失函数的采用的是mask分支对于每个RoI有K*m^2维度的输出。K个(类别数)分辨率为m * m的二值mask。 Lmask为平均二值交叉熵损失(the average binary cross - entropy loss). 对于一个属于第k个类别的RoI, Lmask仅仅考虑第k个mask(其他的掩模输入不会贡献到损失函数中)。这样的定义会允许对每个类别都会生成掩模,并且不会存在类间竞争。
代码中损失部分的整体代码如下:
# *************************8,计算各部分的损失******************************************************************
# maskrcnn中总共有五个损失函数,分别是rpn网络的两个损失,mrcnn的两个损失,以及mask分支的损失函数。
# 前四个损失函数与fasterrcnn的损失函数一样,最后的mask损失函数的采用的是mask分支对于每个RoI有K*m^2维度的输出。
# K个(类别数)分辨率为m * m的二值mask。
# 因此作者利用了aper - pixelsigmoid,并且定义Lmask为平均二值交叉熵损失(the average binary cross - entropy loss).
# 对于一个属于第k个类别的RoI, Lmask仅仅考虑第k个mask(其他的掩模输入不会贡献到损失函数中)。
# 这样的定义会允许对每个类别都会生成掩模,并且不会存在类间竞争。
# Losses
# rpn 分类损失
rpn_class_loss = KL.Lambda(lambda x: rpn_class_loss_graph(*x), name="rpn_class_loss")(
[input_rpn_match, rpn_class_logits])
# rpn 回归损失
rpn_bbox_loss = KL.Lambda(lambda x: rpn_bbox_loss_graph(config, *x), name="rpn_bbox_loss")(
[input_rpn_bbox, input_rpn_match, rpn_bbox])
# mrcnn 分类损失
class_loss = KL.Lambda(lambda x: mrcnn_class_loss_graph(*x), name="mrcnn_class_loss")(
[target_class_ids, mrcnn_class_logits, active_class_ids])
# mrcnn 回归损失
bbox_loss = KL.Lambda(lambda x: mrcnn_bbox_loss_graph(*x), name="mrcnn_bbox_loss")(
[target_bbox, target_class_ids, mrcnn_bbox])
# mask 损失
mask_loss = KL.Lambda(lambda x: mrcnn_mask_loss_graph(*x), name="mrcnn_mask_loss")(
[target_mask, target_class_ids, mrcnn_mask])1,rpn 分类损失 交叉熵
rpn_match与GT有关,前景为1背景为0;
rpn_class_logits 是rpn_graph中生成的,是特征图Reshape to [batch, anchors, 2]但没有经过softmax激活的值。
# rpn 分类损失 交叉熵
def rpn_class_loss_graph(rpn_match, rpn_class_logits):
"""RPN anchor classifier loss.
rpn_match: [batch, anchors, 1]. Anchor match type. 1=positive,
-1=negative, 0=neutral anchor.
rpn_class_logits: [batch, anchors, 2]. RPN classifier logits for BG/FG.
"""
# Squeeze last dim to simplify
rpn_match = tf.squeeze(rpn_match, -1)
# Get anchor classes. Convert the -1/+1 match to 0/1 values. # 正样本转换为1,负样本和忽略的转换为0
anchor_class = K.cast(K.equal(rpn_match, 1), tf.int32)
# Positive and Negative anchors contribute to the loss, but neutral anchors (match value = 0) don't.
indices = tf.where(K.not_equal(rpn_match, 0)) # 取不等于0的,即只取正样本
# Pick rows that contribute to the loss and filter out the rest.
rpn_class_logits = tf.gather_nd(rpn_class_logits, indices) # 选择对损失由贡献的行,忽略其他行
anchor_class = tf.gather_nd(anchor_class, indices)
# 交叉熵损失Cross entropy loss
loss = K.sparse_categorical_crossentropy(target=anchor_class,
output=rpn_class_logits,
from_logits=True)
loss = K.switch(tf.size(loss) > 0, K.mean(loss), tf.constant(0.0)) # 如果损失大于0输出,小于0输出0
return loss2,rpn 回归损失 SmoothL1
target_bbox 就是GT
rpn_match与GT有关,前景为1背景为0;
rpn_bbox 是rpn_graph中生成的,特征图Reshape to [batch, anchors, 4]的值。
SmoothL1损失之前解析其他算法时已经讲过了,这里也不多说了。
# rpn 回归损失 SmoothL1
def rpn_bbox_loss_graph(config, target_bbox, rpn_match, rpn_bbox):
"""Return the RPN bounding box loss graph.
config: the model config object.
target_bbox: [batch, max positive anchors, (dy, dx, log(dh), log(dw))].
Uses 0 padding to fill in unsed bbox deltas.
rpn_match: [batch, anchors, 1]. Anchor match type. 1=positive,
-1=negative, 0=neutral anchor.
rpn_bbox: [batch, anchors, (dy, dx, log(dh), log(dw))]
"""
# Positive anchors contribute to the loss, but negative and
# neutral anchors (match value of 0 or -1) don't.
rpn_match = K.squeeze(rpn_match, -1) # squeeze()将下标为axis的一维从张量中移除
indices = tf.where(K.equal(rpn_match, 1)) # 取正样本索引
# Pick bbox deltas that contribute to the loss
rpn_bbox = tf.gather_nd(rpn_bbox, indices) # 选择正样本偏移量
# Trim target bounding box deltas to the same length as rpn_bbox.
# 将目标边界框增量修剪为与rpn_bbox相同的长度。
batch_counts = K.sum(K.cast(K.equal(rpn_match, 1), tf.int32), axis=1)
target_bbox = batch_pack_graph(target_bbox, batch_counts, config.IMAGES_PER_GPU)
loss = smooth_l1_loss(target_bbox, rpn_bbox)
loss = K.switch(tf.size(loss) > 0, K.mean(loss), tf.constant(0.0))
return loss3,mrcnn 分类损失 交叉熵
target_class_ids, 目标类别ID GT;
pred_class_logits, 特征图由头网络连接全连接层得到,预测的类别ID;
active_class_ids 实际的类别ids 80类;
实际用target_class_ids和pred_class_logits计算交叉熵损失;
active_class_ids用于消除不在图像的预测类别中的类别的预测损失。
# mrcnn 分类损失 交叉熵
def mrcnn_class_loss_graph(target_class_ids, pred_class_logits, active_class_ids):
"""Loss for the classifier head of Mask RCNN.
target_class_ids: [batch, num_rois]. Integer class IDs. Uses zero
padding to fill in the array.
pred_class_logits: [batch, num_rois, num_classes]
active_class_ids: [batch, num_classes]. Has a value of 1 for
classes that are in the dataset of the image, and 0
for classes that are not in the dataset.
"""
# During model building, Keras calls this function with
# target_class_ids of type float32. Unclear why. Cast it
# to int to get around it.
target_class_ids = tf.cast(target_class_ids, 'int64')
# Find predictions of classes that are not in the dataset.
# 查找不在数据集中的类的预测
pred_class_ids = tf.argmax(pred_class_logits, axis=2)
# TODO: Update this line to work with batch > 1. Right now it assumes all
# images in a batch have the same active_class_ids
pred_active = tf.gather(active_class_ids[0], pred_class_ids)
# Loss
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=target_class_ids, logits=pred_class_logits)
# Erase losses of predictions of classes that are not in the active
# classes of the image.
# 消除不在图像的预测类别中的类别的预测损失。
loss = loss * pred_active
# Computer loss mean. Use only predictions that contribute
# to the loss to get a correct mean.
loss = tf.reduce_sum(loss) / tf.reduce_sum(pred_active)
return loss4,mrcnn 回归损失 SmoothL1
target_bbox, 就是GT框
target_class_ids, GT框对应的类别ID
pred_bbox 由特征图经过头网络卷积得到的预测框
# mrcnn 回归损失 SmoothL1
def mrcnn_bbox_loss_graph(target_bbox, target_class_ids, pred_bbox):
"""Loss for Mask R-CNN bounding box refinement.
target_bbox: [batch, num_rois, (dy, dx, log(dh), log(dw))]
target_class_ids: [batch, num_rois]. Integer class IDs.
pred_bbox: [batch, num_rois, num_classes, (dy, dx, log(dh), log(dw))]
"""
# Reshape to merge batch and roi dimensions for simplicity.
target_class_ids = K.reshape(target_class_ids, (-1,))
target_bbox = K.reshape(target_bbox, (-1, 4))
pred_bbox = K.reshape(pred_bbox, (-1, K.int_shape(pred_bbox)[2], 4))
# Only positive ROIs contribute to the loss. And only
# the right class_id of each ROI. Get their indices.
positive_roi_ix = tf.where(target_class_ids > 0)[:, 0]
positive_roi_class_ids = tf.cast(
tf.gather(target_class_ids, positive_roi_ix), tf.int64)
indices = tf.stack([positive_roi_ix, positive_roi_class_ids], axis=1)
# Gather the deltas (predicted and true) that contribute to loss
target_bbox = tf.gather(target_bbox, positive_roi_ix)
pred_bbox = tf.gather_nd(pred_bbox, indices)
# Smooth-L1 Loss
loss = K.switch(tf.size(target_bbox) > 0,
smooth_l1_loss(y_true=target_bbox, y_pred=pred_bbox),
tf.constant(0.0))
loss = K.mean(loss)
return loss5,mask 损失 掩膜二进制交叉熵
Lmask是mask分支上的损失函数,输出大小为K*m*m,其编码分辨率为m*m的K个二进制mask,即K个类别每个对应一个二进制mask,对每个像素使用sigmoid 函数,Lmask是平均二进制交叉熵损失。RoI的groundtruth类别为k,Lmask只定义在第k个Mask上,其余的mask属于对它没有影响(也就是说在训练的时候,虽然每个点都会有K个二进制mask,但是只有一个k类mask对损失有贡献,这个k值是分类branch预测出来的)。
Mask-RCNN没有类间竞争,因为其他类别不贡献损失。mask分支对每个类别都有预测,依靠分类层选择输出mask(此时大小应该是m*m,之预测了一个类别出来,只需要输出该类别对应的mask即可),使用FCN的一般方法是对每个像素使用softmax以及多项交叉熵损失,会出现类间竞争。二值交叉熵会使得每一类的 mask 不相互竞争,而不是和其他类别的 mask 比较 。
target_mask, GT mask
target_class_ids, GT框对应的类别ID
mrcnn_mask 由图训练的到的mask
def mrcnn_mask_loss_graph(target_masks, target_class_ids, pred_masks):
"""Mask binary cross-entropy loss for the masks head.
target_masks: [batch, num_rois, height, width].
A float32 tensor of values 0 or 1. Uses zero padding to fill array.
target_class_ids: [batch, num_rois]. Integer class IDs. Zero padded.
pred_masks: [batch, proposals, height, width, num_classes] float32 tensor
with values from 0 to 1.
"""
# Reshape for simplicity. Merge first two dimensions into one.
target_class_ids = K.reshape(target_class_ids, (-1,))
mask_shape = tf.shape(target_masks)
target_masks = K.reshape(target_masks, (-1, mask_shape[2], mask_shape[3]))
pred_shape = tf.shape(pred_masks)
pred_masks = K.reshape(pred_masks,
(-1, pred_shape[2], pred_shape[3], pred_shape[4]))
# Permute predicted masks to [N, num_classes, height, width]
pred_masks = tf.transpose(pred_masks, [0, 3, 1, 2])
# Only positive ROIs contribute to the loss. And only
# the class specific mask of each ROI.
positive_ix = tf.where(target_class_ids > 0)[:, 0]
positive_class_ids = tf.cast(
tf.gather(target_class_ids, positive_ix), tf.int64)
indices = tf.stack([positive_ix, positive_class_ids], axis=1)
# Gather the masks (predicted and true) that contribute to loss
y_true = tf.gather(target_masks, positive_ix)
y_pred = tf.gather_nd(pred_masks, indices)
# Compute binary cross entropy. If no positive ROIs, then return 0.
# shape: [batch, roi, num_classes]
loss = K.switch(tf.size(y_true) > 0,
K.binary_crossentropy(target=y_true, output=y_pred),
tf.constant(0.0))
loss = K.mean(loss)
return loss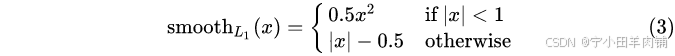
代码中的x=K.abs(y_true-y_pred)
"""
Implements Smooth-L1 loss.
y_true and y_pred are typically: [N, 4], but could be any shape.
"""
def smooth_l1_loss(y_true, y_pred):
diff = K.abs(y_true - y_pred)
less_than_one = K.cast(K.less(diff, 1.0), "float32")
loss = (less_than_one * 0.5 * diff**2) + (1 - less_than_one) * (diff - 0.5)
return lossMask-RCNN损失函数分析
之前的文章对Faster-RCNN进行了源代码分析 faster-RCNN1 faster-RCNN2 faster-RCNN,本文将进一步讲解Mask-RCNN的损失函数,首先需要了解Mask-RCNN是基于Faster-RCNN实现的,只是在原有基础结构上加入了Mask层,实现实例分割的功能,这里首先要区分下实例分割(Instance Segmentation)、语义分割(Sematic Segmentation)和全景分割(panoptic segmentation)。
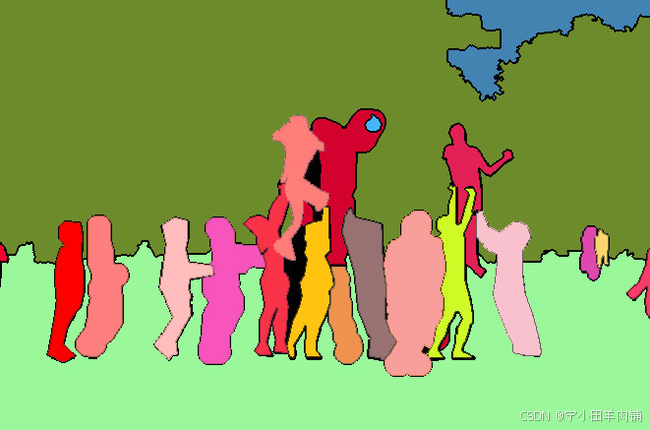
语义分割:对图像中的每个像素都打上一个类别标签,如下图,把图像分为人(红色)、树木(深绿)、草地(浅绿)、天空(蓝色)标签。
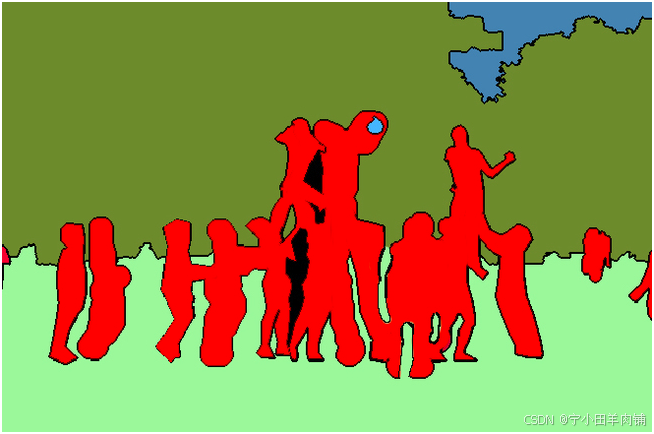
实例分割:目标检测和语义分割的结合,在图像中将目标检测出来(目标检测),然后对每个像素打上标签(语义分割)。对比上图和下图,如以人(person)为目标,语义分割不区分属于相同类别的不同实例(所有人都标为红色),实例分割区分同类的不同实例(使用不同颜色区分不同的人)。
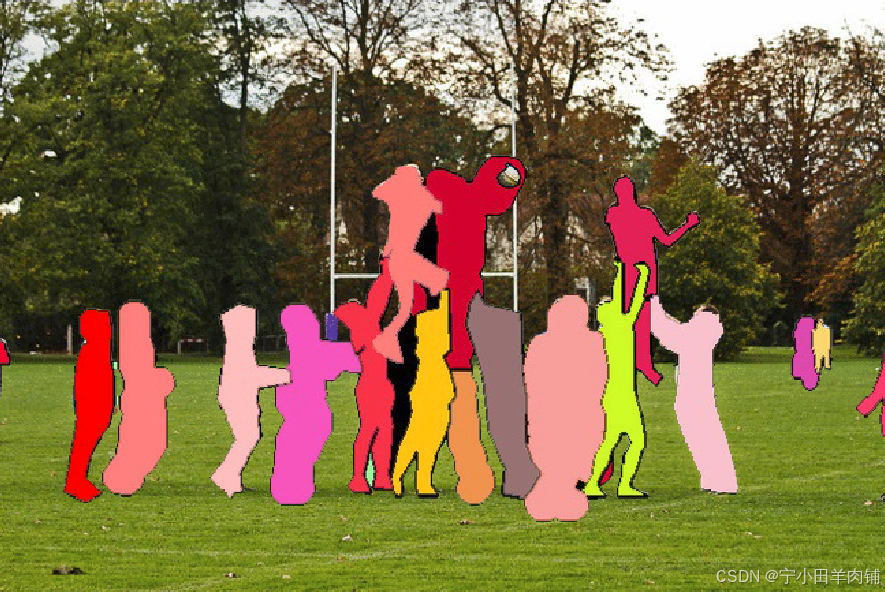
全景分割:语义分割和实例分割的结合,即要对所有目标都检测出来,又要区分出同个类别中的不同实例。对比上图、下图,实例分割只对图像中的目标(如上图中的人)进行检测和按像素分割,区分不同实例(使用不同颜色),而全景分割是对图中的所有物体包括背景都要进行检测和分割,区分不同实例(使用不同颜色)。
在搞清楚这几个概念后,下面我们来讲一下Mask RCNN的实现原理。 Mask R-CNN和Faster R-CNN采取相同的结构RPN预测分类和回归框,但Mask RCNN对于每一个RoI还会输出一个二进制的Mask,在训练期间对于每一个RoI定义一个多任务损失函数:
![]()
分别是分类损失L_{cls}、回归框损失L_{box}和新加入的mask损失L_{mask},前两个损失与Faster-RCNN是一致的,对于一个m \times m的RoI, L_{mask}有Km^2维的输出,编码了K个二进制m \times m的Mask对于K个分类,对于每一个像素都有一个sigmoid函数,L_{mask}为所有像素二进制交叉熵的平均,对于对应K种分类的RoI,也就是说对于一个RoI,如果其对应的分类有K种,那么L_{mask}就对应了K个m \times m的二进制mask,而这K个mask是相互独立地进行分割的,这样各个分类之间将不存在竞争。那么我们最终选择哪个mask做分割呢?我们直接根据分类分支即L_{cls}对应的分支分类结果来确定选择哪个mask,这与常用的全卷积(FCN)图像分割算法是不同的。
1.Faster RCNN
双阶段目标检测算法,如上图所示整体流程:
- 首先用ResNet-FPN做BackBone提取特征
- 然后RPN(Region Proposal Network)得到FeatureMap中的ROI
- 使用RIO pooling处理RIO变成固定尺寸
- Head部分做边框的分类与回归
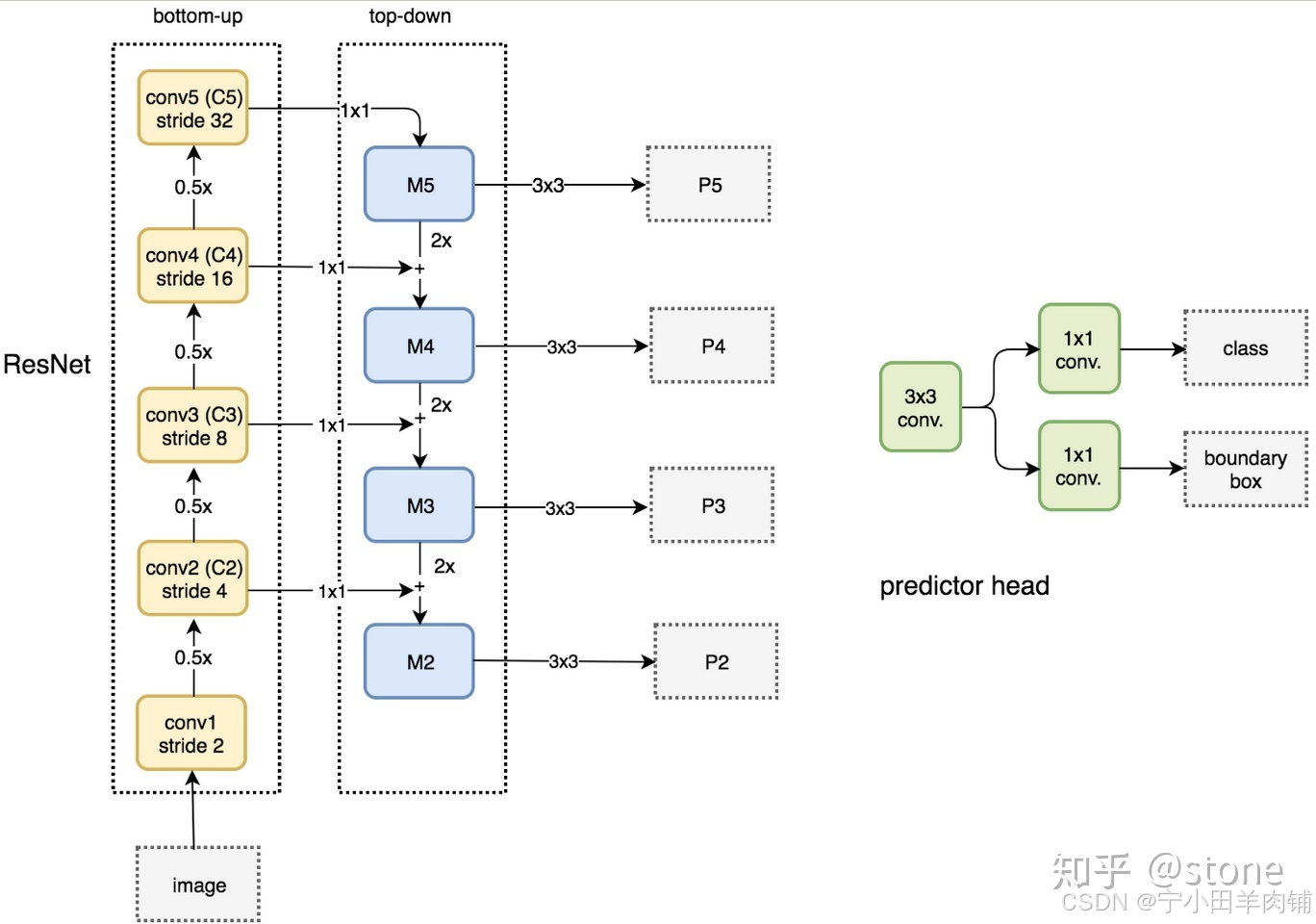
ResNet-FPN
因为FasterRCNN和MaskRCNN采用的都是ResNet-FPN主干网络,所以这里先介绍,在熟悉ResNet的基础上看一下ResNet-FPN:
FPN(Feature Pyramid Network)是一种旨在解决多尺度问题而提出的算法,下图(a)(c)(d)展示了三种典型的多尺度问题处理方式:(a)将图片缩放为不同size,(c)使用不同层次的FeatureMap,(d)特征金字塔网络。
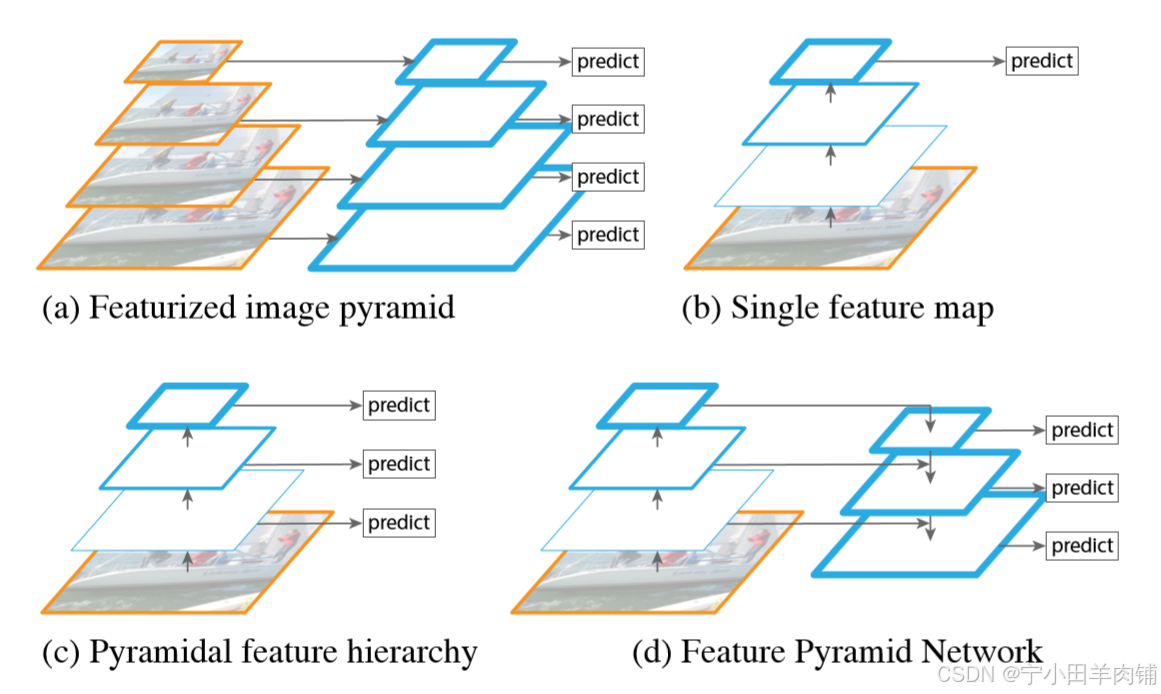
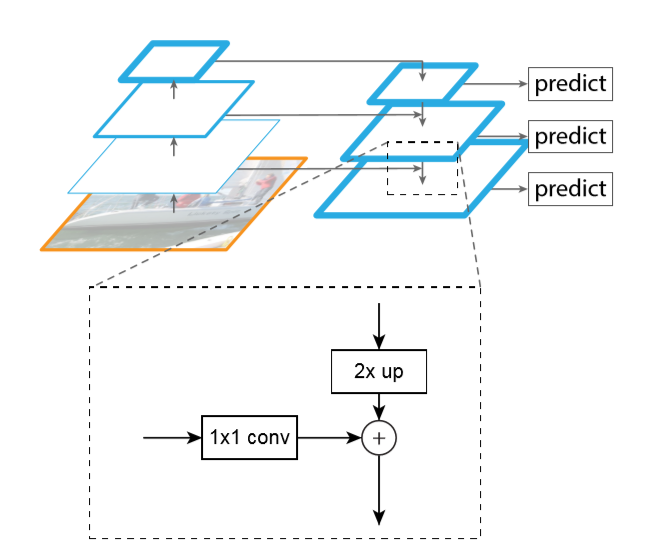
FPN结构中包括自下而上,自上而下和横向连接三种,如下图所示。这种结构可以将各个层级的特征进行融合,使其同时具有强语义信息和强空间信息。
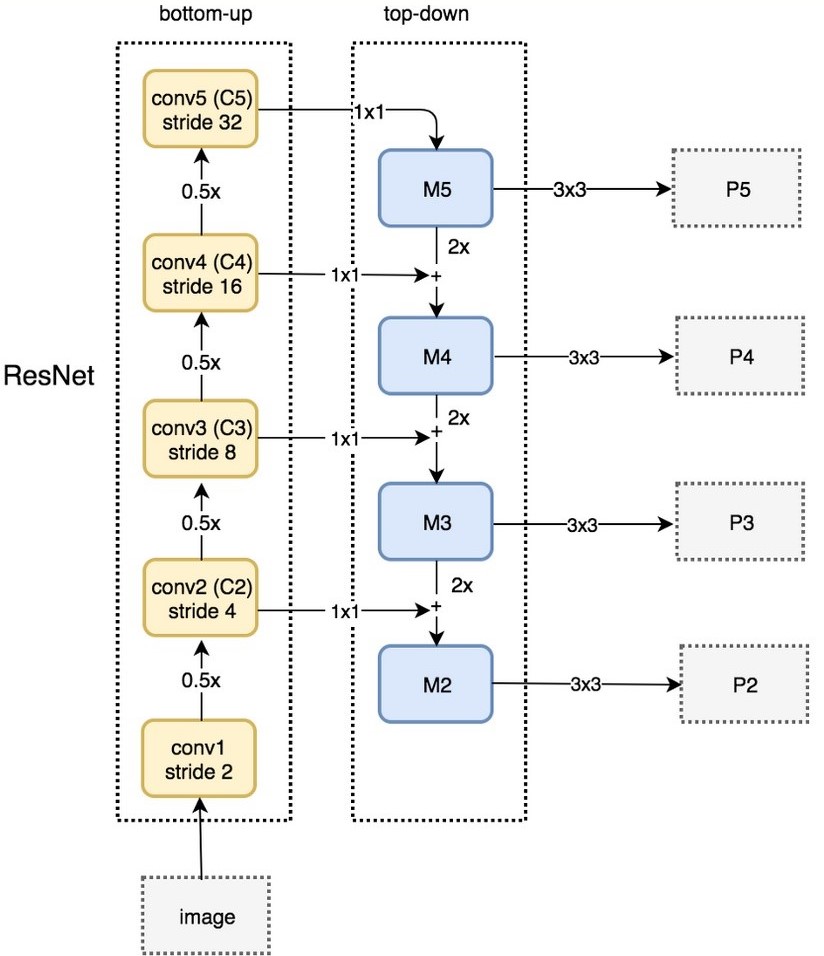
FPN是一种通用结构,可以结合各种backbone使用,下图及为ResNet-FPNd的整体结构。最终产生的是特征金字塔[P2, P3, P4, P5](其实还有P6,图中缺少了)。那么其后的RPN网络在哪张特征图上产生ROI呢?FPN会利用一个公式选择最合适尺度的FeatureMap来切ROI,详情请见FPN的论文。
2.Mask RCNN
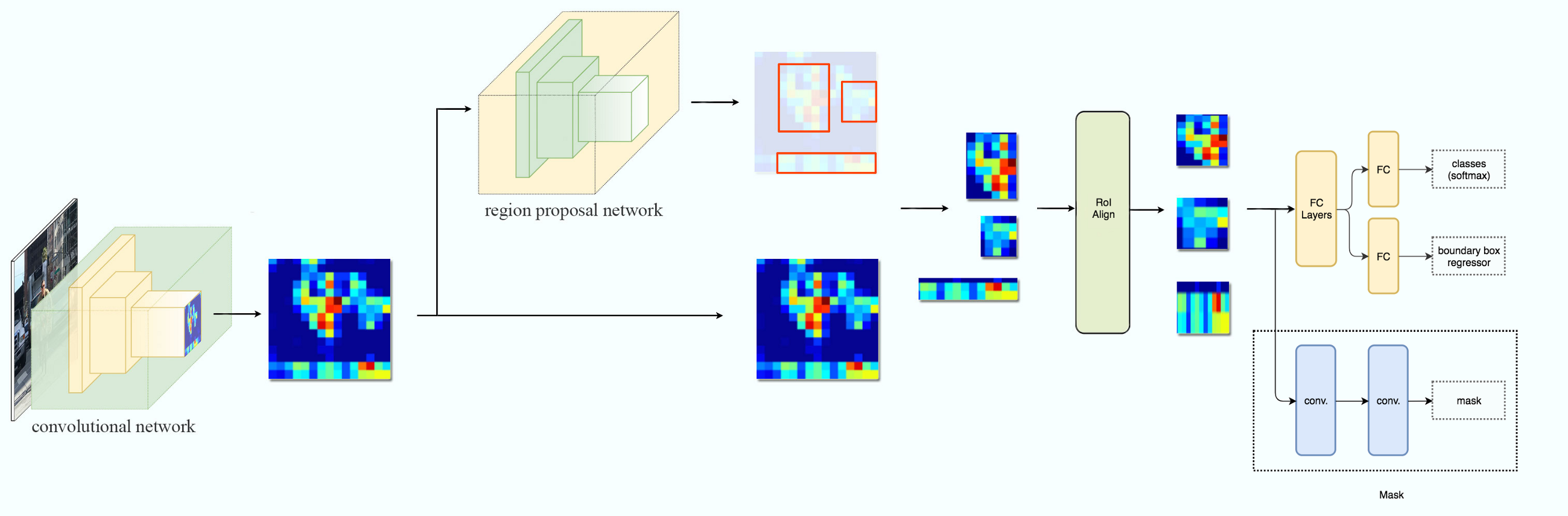
正如作者自己在论文中所说”Mask R-CNN is simple to implement and train given the Faster R-CNN framework“,确实只需要在FasterRCNN中的ROI Pooling(实际是改进后的ROI Align)后加入一个Mask分支——FCN(Fully Convolutional Networks)对每个ROI预测MasK即可,在这之前都与FasterRCNN相同。可以看出,MaskRCNN算法对于FasterRCNN有两个重点:ROI Align、Mask预测分支,下面两节详细介绍:
3.ROI Align
ROI pooling & 缺陷
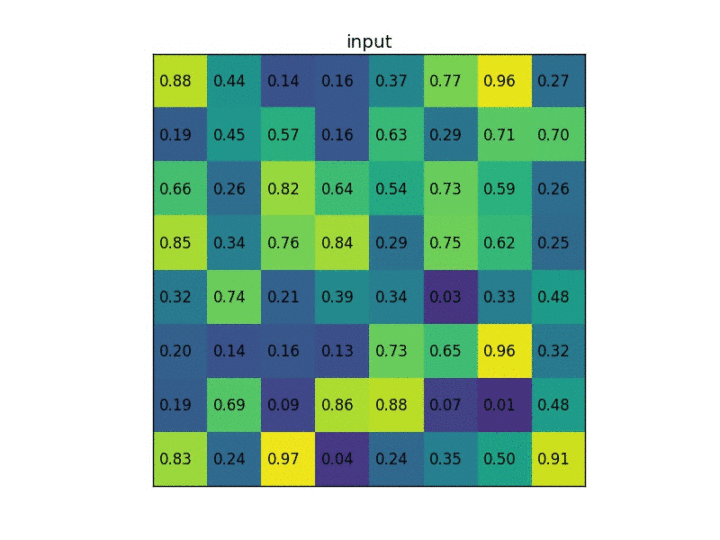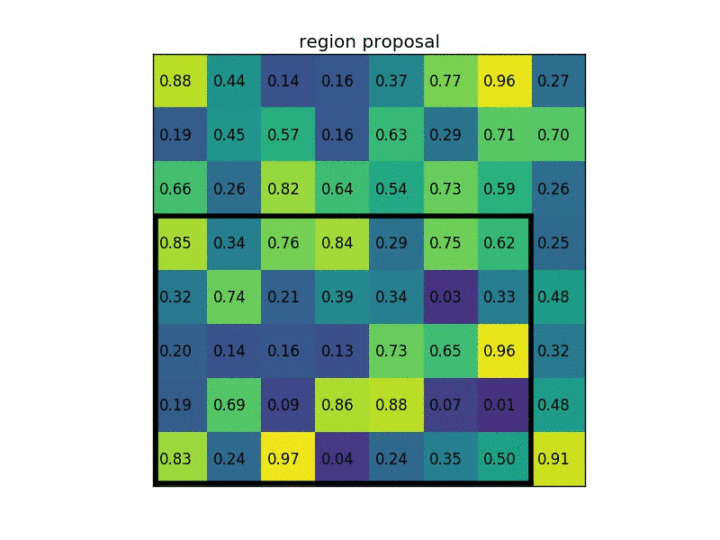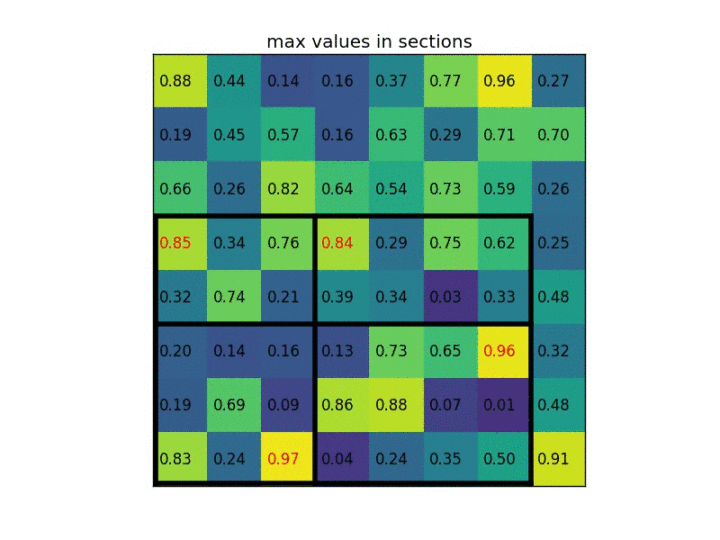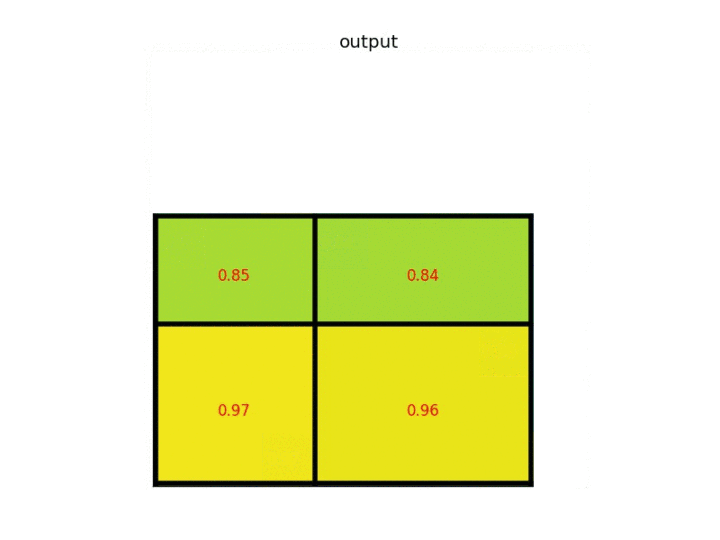
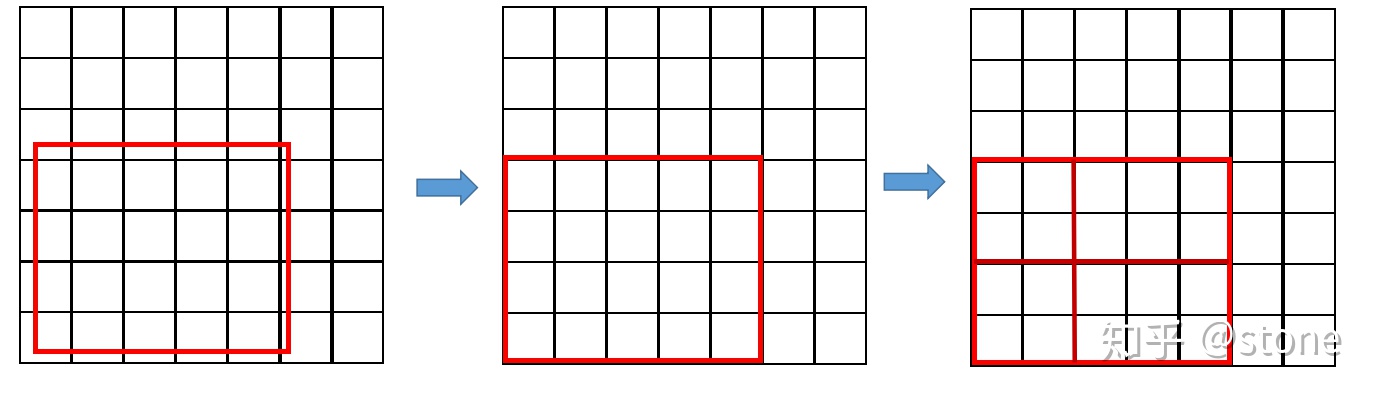
ROI pooling方法:在一张feature map中截取ROI,并将此ROI池化为规定大小。简单的例子就能明白:假设现在有一个8x8大小的feature map,我们要在这个feature map上得到ROI,并且进行ROI pooling到2x2大小的输出。假设ROI的bounding box为[x1, y1, x2, y2] = [0, 3, 7, 8]。将它划分为2x2的网格,因为ROI的长宽除以2是不能整除的,所以会出现每个格子大小不一样的情况。进行max pooling的最终输入2×2的结果。
但ROI pooling方法存在不对齐(mis-alignment)问题,在目标检测领域还好,但对于分割这一像素级任务就会有致命性问题。mis-alignment主要来源于两次取整操作:
-
x,y,w,h的取整。(上述例子中我们给的ROI位置为整数,但实际通过RPN得到的区域并不是整数的)
-
划分小格时除不尽取整。(正如上面例子ROI宽为7,要分成2小格,不能整除,须取整)
ROI Align
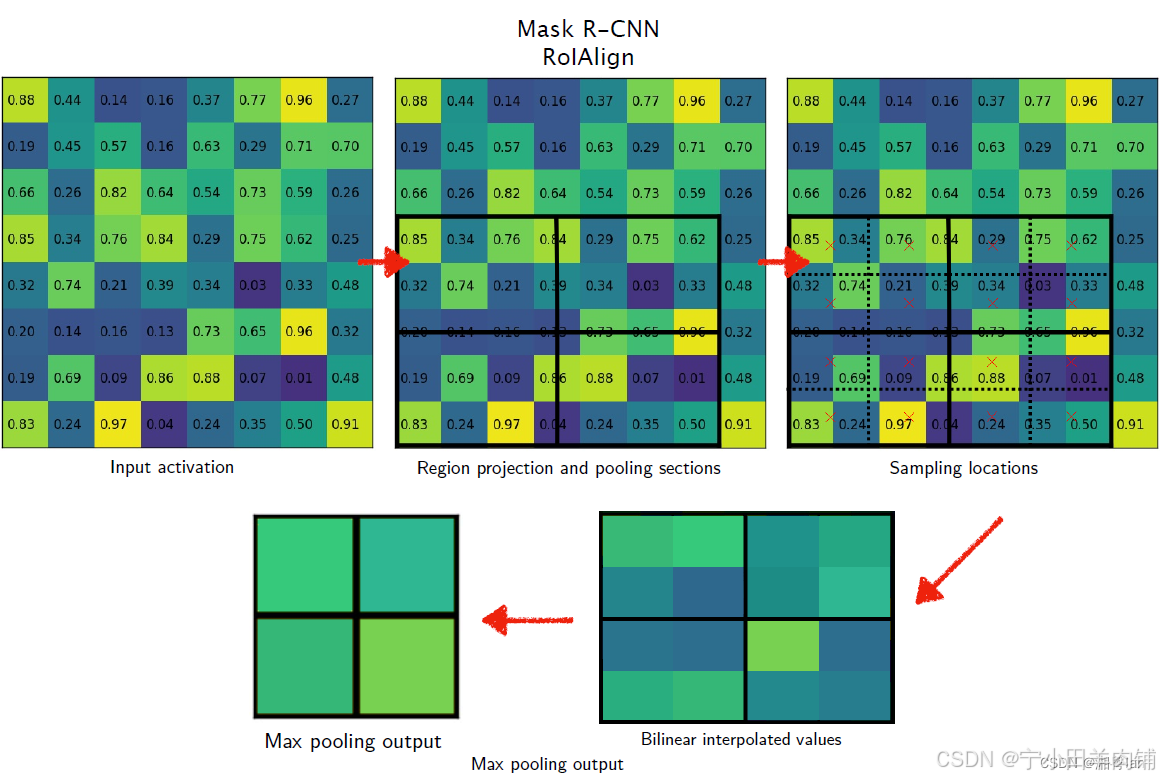
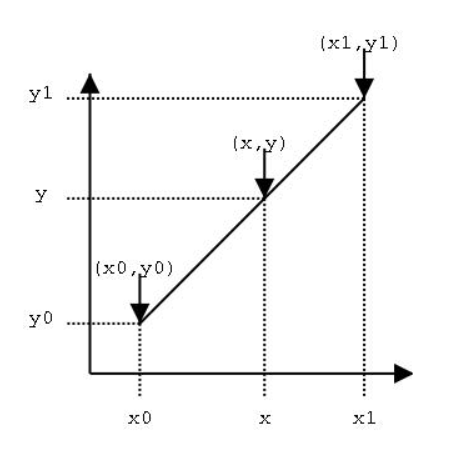
ROI Align为了解决不对齐问题,将以上两次取整操作全部保留本来的浮点数,重新设计了算法。为了保留浮点数,采用了双线性插值,关于双线性插值看下图就可明白,计算公式可以自行百度,简而概之关键,普通线性插值确定一点的值需要两个点,双线性插值需要四个点。
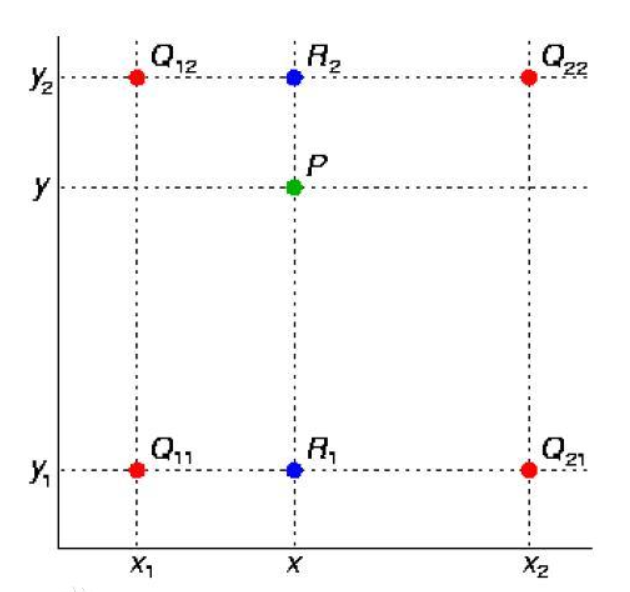
ROI Align操作。如下图,虚线部分表示feature map,实线表示ROI,假设期望输出ROI为2×2。若采样点数是4,那我们首先将每个单元格子均分成四个小方格(如红色线所示),每个小方格中心就是采样点。这些采样点的坐标通常是浮点数,所以需要对采样点像素进行双线性插值(如四个箭头所示),就可以得到该像素点的值了。然后对每个单元格内的四个采样点进行maxpooling,就可以得到最终的ROIAlign的结果。
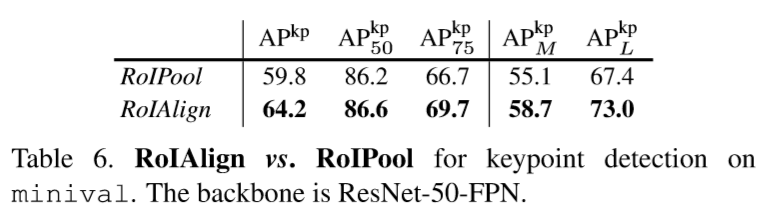
使用ROI Align代替ROI pooling后,效果有十分显著提升,实际效果:
4.Mask解耦(LossFunction)

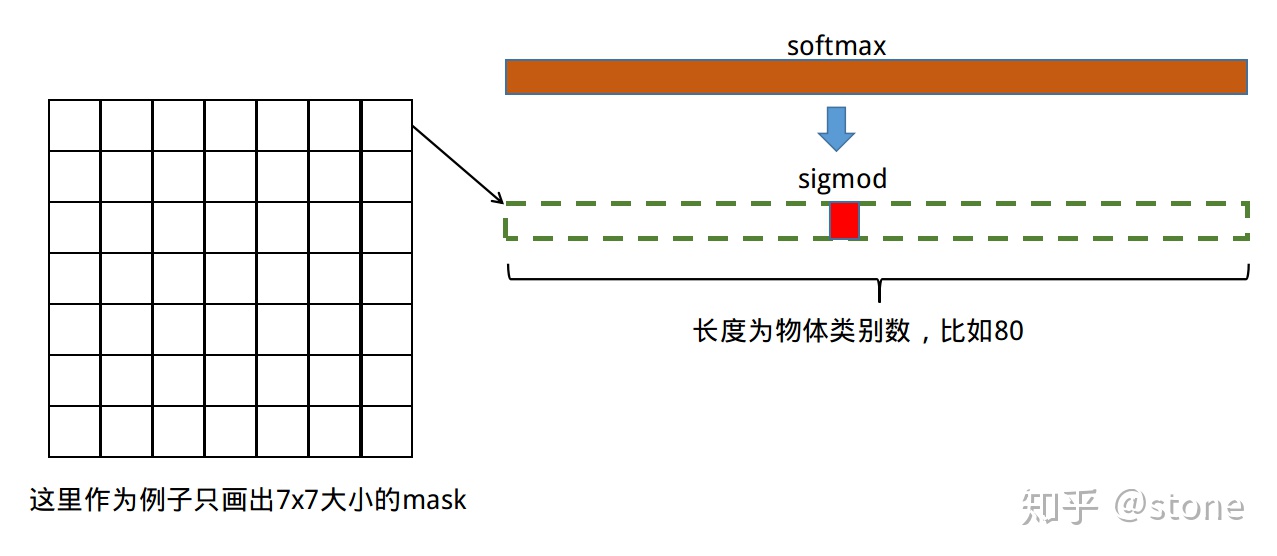
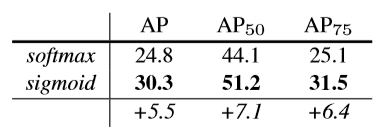
Sigmoid与Softmax对比实际提升效果:
1 总结架构与主要思想
总体架构
Mask-RCNN 大体框架还是 Faster-RCNN 的框架,可以说在基础特征网络之后又加入了全连接的分割子网,由原来的两个任务(分类+回归)变为了三个任务(分类+回归+分割)。Mask R-CNN 是一个两阶段的框架,第一个阶段扫描图像并生成提议(proposals,即有可能包含一个目标的区域),第二阶段分类提议并生成边界框和掩码。
这里写图片描述
其中黑色部分为原来的 Faster-RCNN,红色部分为在 Faster网络上的修改,总体流程如下:
1)输入图像;
2)将整张图片输入CNN,进行特征提取;
3)用FPN生成建议窗口(proposals),每张图片生成N个建议窗口;
4)把建议窗口映射到CNN的最后一层卷积feature map上;
5)通过RoI Align层使每个RoI生成固定尺寸的feature map;
6)最后利用全连接分类,边框,mask进行回归。
另一系统图:
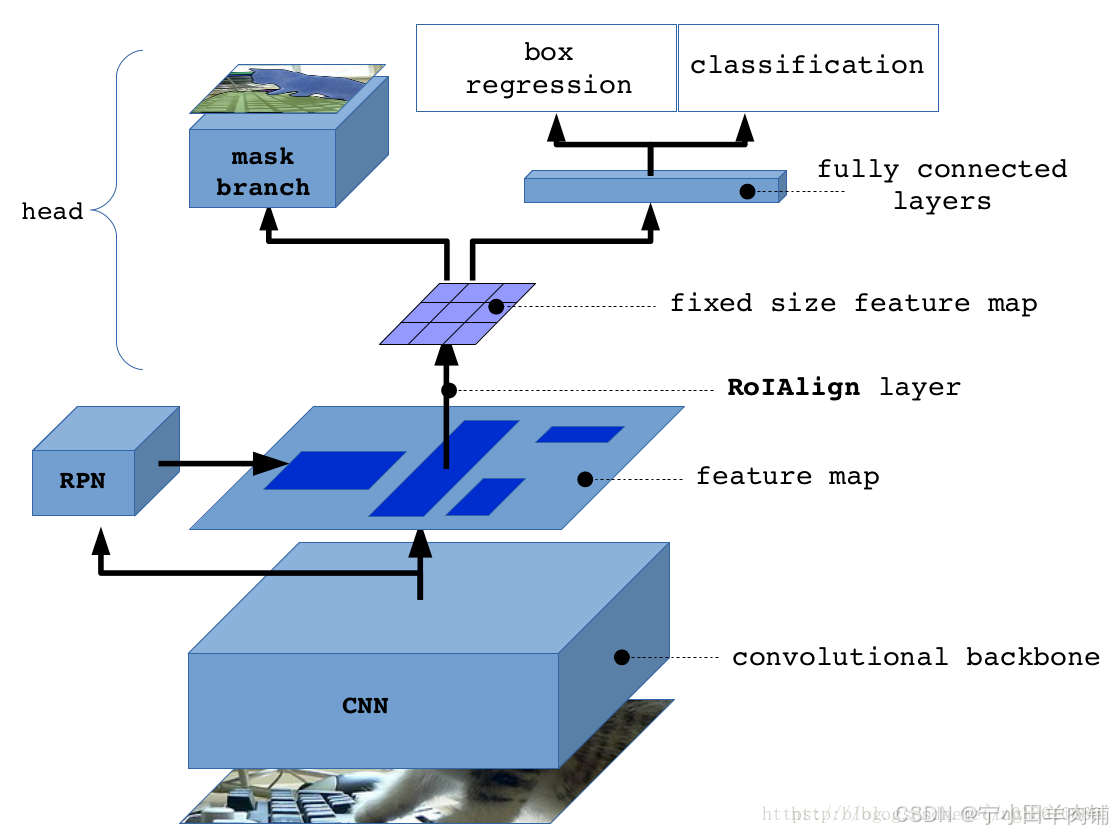
首先对图片做检测,找出图像中的ROI,对每一个ROI使用ROIAlign进行像素校正,然后对每一个ROI使用设计的FCN框架进行预测不同的实例所属分类,最终得到图像实例分割结果。
与faster RCNN的区别:
1)使用ResNet101网络
2)将 Roi Pooling 层替换成了 RoiAlign;
3)添加并列的 Mask 层;
4)由RPN网络转变成FPN网络
主要改进点:
1. 基础网络的增强,ResNeXt-101+FPN的组合可以说是现在特征学习的王牌了;
2. 分割 loss 的改进,由原来的 FCIS 的 基于单像素softmax的多项式交叉熵变为了基于单像素sigmod二值交叉熵。softmax会产生FCIS的 ROI inside map与ROI outside map的竞争。但文章作者确实写到了类间的竞争, 二值交叉熵会使得每一类的 mask 不相互竞争,而不是和其他类别的 mask 比较 ;
3. ROIAlign解决Misalignment 的问题,说白了就是对 feature map 的插值。直接的ROIPooling的那种量化操作会使得得到的mask与实际物体位置有一个微小偏移,个人感觉这个没什么 insight,就是工程上更好的实现方式。
说明:这么好的效果是由多个阶段的优化实现的,大头的提升还是由数据和基础网络的提升:多任务训练带来的好处其实可以看作是更多的数据带来的好处;FPN 的特征金字塔,ResNeXt更强大的特征表达能力都是基础网络。
其中:
残差网络ResNet参见:残差网络resnet详解
RPN网络参见:目标检测--FPN解析
Mask-RCNN 的几个特点(来自于 Paper 的 Abstract):
1)在边框识别的基础上添加分支网络,用于语义Mask 识别;
2)训练简单,相对于 Faster 仅增加一个小的 Overhead,可以跑到 5FPS;
3)可以方便的扩展到其他任务,比如人的姿态估计等;
4)不借助 Trick,在每个任务上,效果优于目前所有的 single-model entries,包括 COCO 2016 的Winners。
2 ROI Align
ROI Align 很好地解决了ROI Pooling操作中两次量化造成的区域不匹配(mis-alignment)的问题。实验显示,在检测测任务中将 ROI Pooling 替换为 ROI Align 可以提升检测模型的准确性。
2.1 ROI Pooling
在faster rcnn中,anchors经过proposal layer升级为proposal,需要经过ROI Pooling进行size的归一化后才能进入全连接网络,也就是说ROI Pooling的主要作用是将proposal调整到统一大小。步骤如下:
将proposal映射到feature map对应位置
将映射后的区域划分为相同大小的sections
对每个sections进行max pooling/avg pooling操作
举例说明:
考虑一个8*8大小的feature map,经过一个ROI Pooling,以及输出大小为2*2.
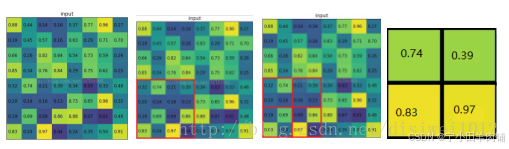
1)输入的固定大小的feature map (图一)
2)region proposal 投影之后位置(左上角,右下角坐标):(0,4)?,(4,4)(图二)
3)将其划分为(2*2)个sections(因为输出大小为2*2),我们可以得到(图三) ,不整除时错位对齐(Fast RCNN)
4)对每个section做max pooling,可以得到(图四)
2.2 ROI Pooling 的局限性分析
在常见的两级检测框架(比如Fast-RCNN,Faster-RCNN,RFCN)中,ROI Pooling 的作用是根据预选框的位置坐标在特征图中将相应区域池化为固定尺寸的特征图,以便进行后续的分类和包围框回归操作。由于预选框的位置通常是由模型回归得到的,一般来讲是浮点数,而池化后的特征图要求尺寸固定。故ROI Pooling这一操作存在两次量化的过程。
将候选框边界量化为整数点坐标值。从roi proposal到feature map的映射时,取[x/16],这里x是原始roi的坐标值,而方框代表四舍五入。
将量化后的边界区域平均分割成 k x k 个单元(bin), 对每一个单元的边界进行量化,每个bin使用max pooling。
事实上,经过上述两次量化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度。在论文里,作者把它总结为“不匹配问题(misalignment)。
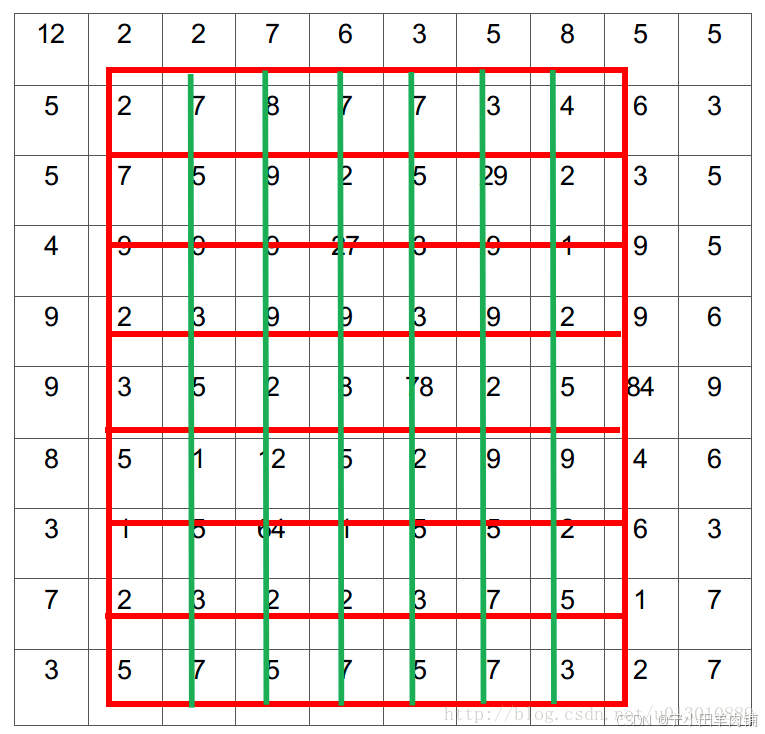
下面我们用直观的例子具体分析一下上述区域不匹配问题。如 图1 所示,这是一个Faster-RCNN检测框架。输入一张800*800的图片,图片上有一个665*665的包围框(框着一只狗)。图片经过主干网络提取特征后,特征图缩放步长(stride)为32。因此,图像和包围框的边长都是输入时的1/32。800正好可以被32整除变为25。但665除以32以后得到20.78,带有小数,于是ROI Pooling 直接将它量化成20。
接下来需要把框内的特征池化7*7的大小,因此将上述包围框平均分割成7*7个矩形区域。显然,每个矩形区域的边长为2.86,又含有小数。于是ROI Pooling 再次把它量化到2。经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,这一差别不容小觑。
图 1 (感觉第二次量化画错了,根据ross的源码,不是缩小了,而是部分bin大小和步长发生变化)

简而言之:
做segment是pixel级别的,但是faster rcnn中roi pooling有2次量化操作导致了没有对齐
2.3 ROI Align 的主要思想和具体方法
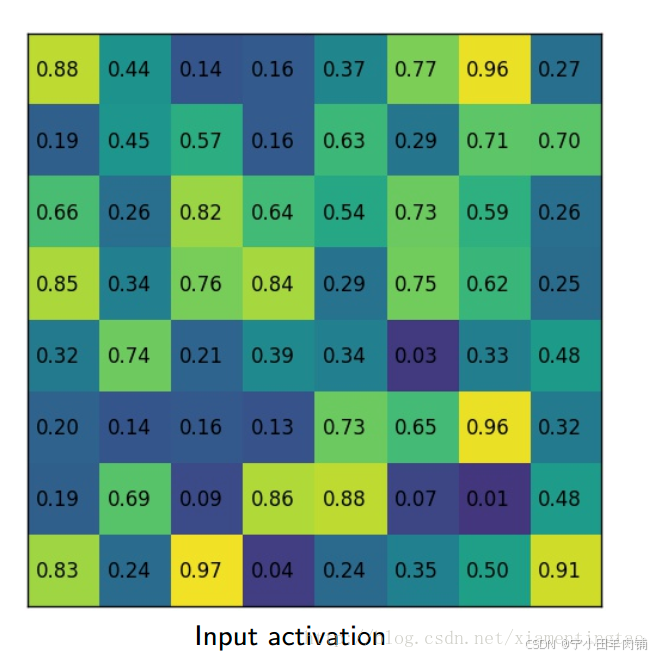
为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法(如图2)。ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。值得注意的是,在具体的算法操作上,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套比较优雅的流程,如图3 所示:
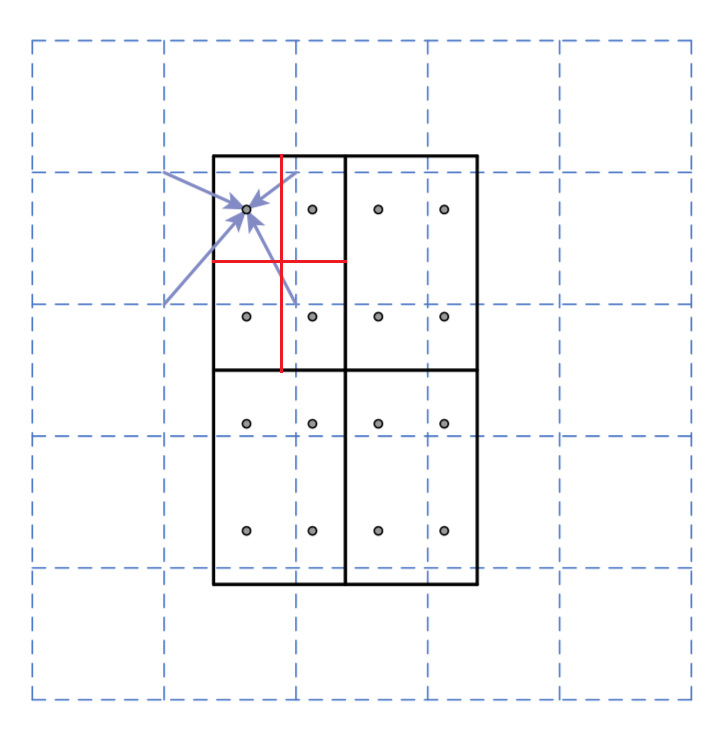
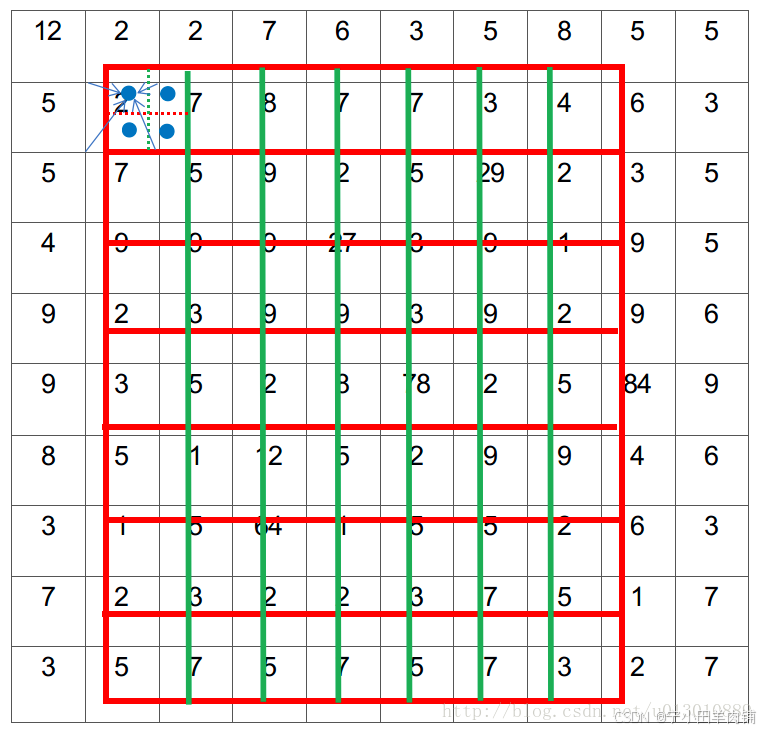
遍历每一个候选区域,保持浮点数边界不做量化。
将候选区域分割成k x k个单元,每个单元的边界也不做量化。
在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。
事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。值得一提的是,我在实验时发现,ROI Align在VOC2007数据集上的提升效果并不如在COCO上明显。经过分析,造成这种区别的原因是COCO上小目标的数量更多,而小目标受misalignment问题的影响更大(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)。
图 2
图片标题
图 3
图片标题
下面插图更加细致地描述roialign:
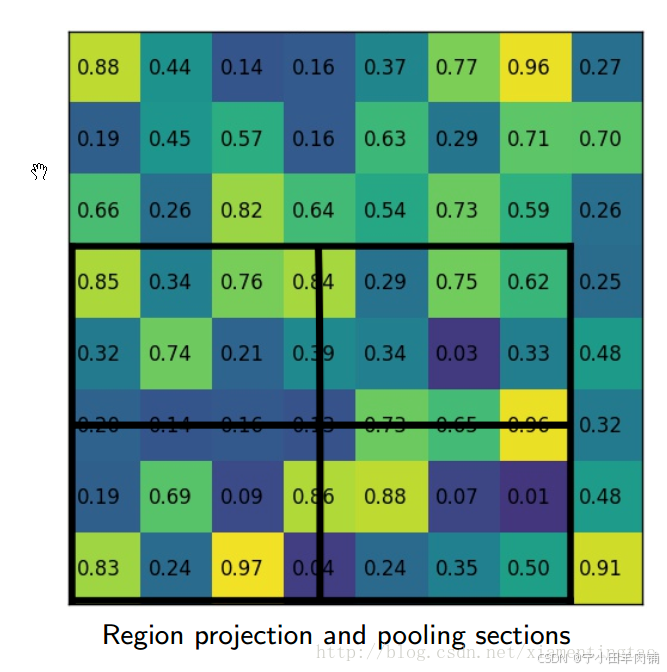
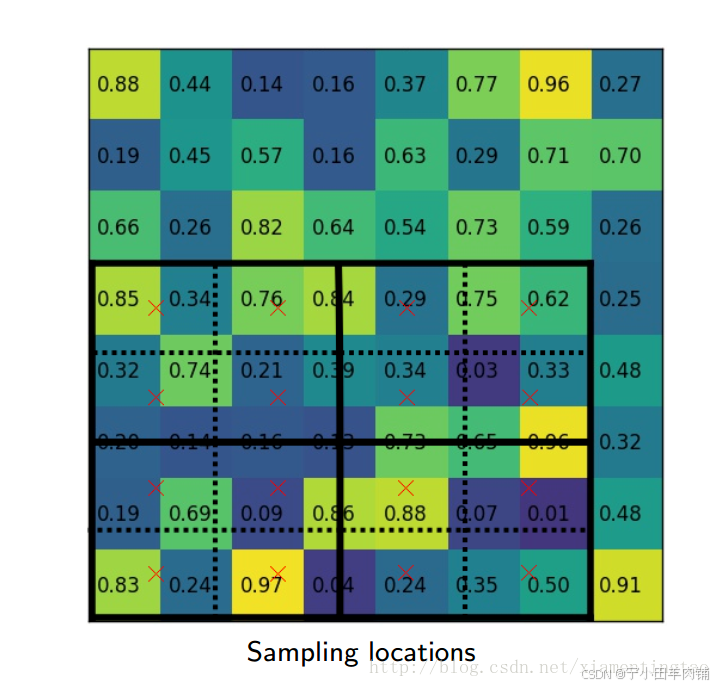
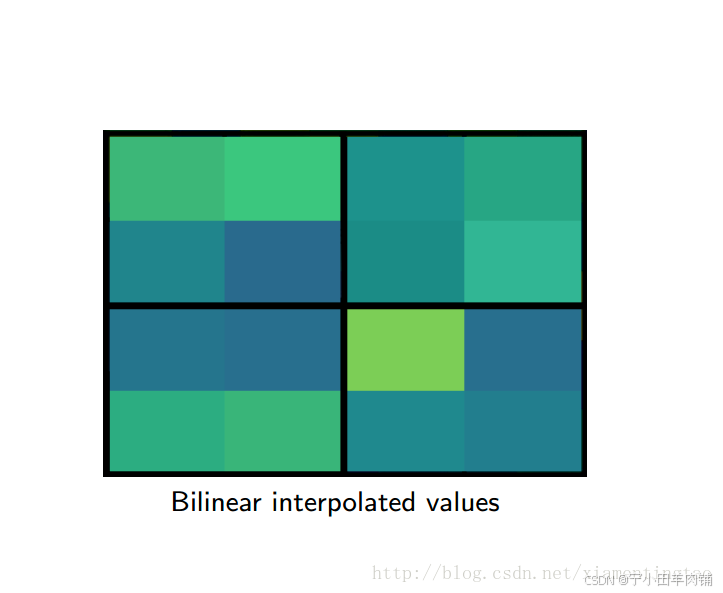
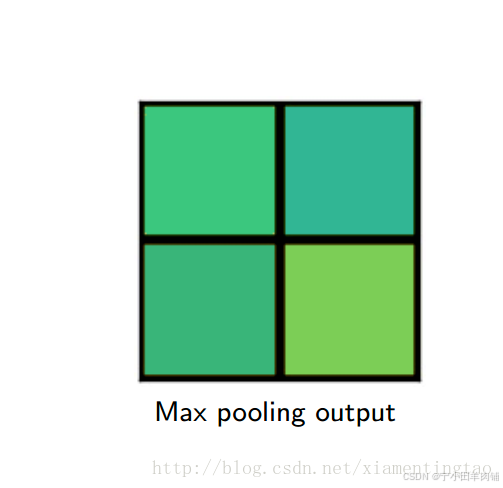
2.4 ROI Align 的反向传播
常规的ROI Pooling的反向传播公式如下:
图片标题
这里,xi代表池化前特征图上的像素点;yrj代表池化后的第r个候选区域的第j个点;i*(r,j)代表点yrj像素值的来源(最大池化的时候选出的最大像素值所在点的坐标)。由上式可以看出,只有当池化后某一个点的像素值在池化过程中采用了当前点Xi的像素值(即满足i=i*(r,j)),才在xi处回传梯度。
类比于ROIPooling,ROIAlign的反向传播需要作出稍许修改:首先,在ROIAlign中,xi*(r,j)是一个浮点数的坐标位置(前向传播时计算出来的采样点),在池化前的特征图中,每一个与 xi*(r,j) 横纵坐标均小于1的点都应该接受与此对应的点yrj回传的梯度,故ROI Align 的反向传播公式如下:
图片标题
上式中,d(.)表示两点之间的距离,Δh和Δw表示 xi 与 xi*(r,j) 横纵坐标的差值,这里作为双线性内插的系数乘在原始的梯度上。
roi-align总结:对于每个roi,映射之后坐标保持浮点数,在此基础上再平均切分成k*k个bin,这个时候也保持浮点数。再把每个bin平均分成4个小的空间(bin中更小的bin),然后计算每个更小的bin的中心点的像素点对应的概率值。这个像素点大概率是一个浮点数,实际上图像的浮点是没有像素值的,但这里假设这个浮点数的位置存储一个概率值,这个值由相邻最近的整数像素点存储的概率值经过双线性插值得到,其实也就是根据这个中心点所在的像素值找到所在的大bin对应的4个整数像素存储的值,然后乘以多个参数进行插值。这些参数其实就是那4个整数像素点和中心点的位置距离关系构成参数。最后再在每个大bin中对4个中心点进行max或者mean的pooling。
2.5 ROI Pooling 、ROI Align和RoIWarp
下图对比了三种方法的不同,其中roiwarp来自:J. Dai, K. He, and J. Sun. Instance-aware semantic segmentation via multi-task network cascades。RoIWarp第一次量化了,第二次没有,RoIAlign两次都没有量化 。
2.6 实例
输出7*7的fix featrue:
-
划分7*7的bin(我们可以直接精确的映射到feature map来划分bin,不用第一次量化)
-
每个bin中采样4个点,双线性插值
-
对每个bin4个点做max或average pooling
-
# pytorch # 这是pytorch做法先采样到14*14,然后max pooling到7*7 pre_pool_size = cfg.POOLING_SIZE * 2 grid = F.affine_grid(theta, torch.Size((rois.size(0), 1, pre_pool_size, pre_pool_size))) crops = F.grid_sample(bottom.expand(rois.size(0), bottom.size(1), bottom.size(2), bottom.size(3)), grid, mode=mode) crops = F.max_pool2d(crops, 2, 2) # tensorflow pooled.append(tf.image.crop_and_resize( feature_maps[i], level_boxes, box_indices, self.pool_shape, method="bilinear"))3 损失函数
介绍一下网络使用的损失函数为分类误差+检测误差+分割误差
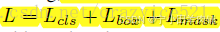
分类误差和检测误差在farster R-CNN当中已经介绍过了,参看前面文章。
分割误差为新的东西,对于每一个ROI,mask分支定义一个K*m*2维的矩阵表示K个不同的分类对于每一个m*m的区域,对于每一个类都有一个。对于每一个像素,都是用sigmod函数进行求相对熵,得到平均相对熵误差Lmask。对于每一个ROI,如果检测得到ROI属于哪一个分类,就只使用哪一个分支的相对熵误差作为误差值进行计算。(举例说明:分类有3类(猫,狗,人),检测得到当前ROI属于“人”这一类,那么所使用的Lmask为“人”这一分支的mask。)这样的定义使得我们的网络不需要去区分每一个像素属于哪一类,只需要去区别在这个类当中的不同分别小类。最后可以通过与阈值0.5作比较输出二值mask。这样避免了类间的竞争,将分类的任务交给专业的classification分支。
而Lmask对于每一个像素使用二值的sigmoid交叉熵损失。
参考theano的文档,二值的交叉熵定义如下: 这里的o就是sigmoid输出。

Lmask(Cls_k) = Sigmoid (Cls_k),平均二值交叉熵 (average binary cross-entropy)Loss,通过逐像素的 Sigmoid 计算得到。Why K个mask?通过对每个 Class 对应一个 Mask 可以有效避免类间竞争(其他 Class 不贡献 Loss )。
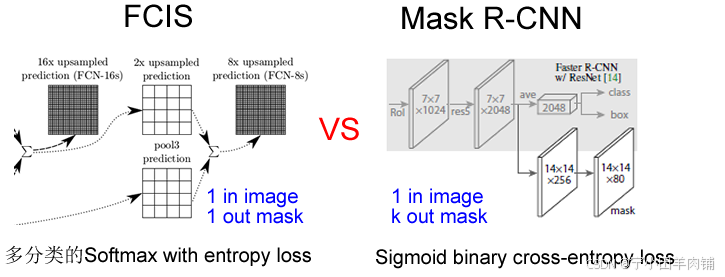
通过结果对比来看(Table2 b),也就是作者所说的 Decouple 解耦,要比多分类的Softmax 效果好很多。
代码:
# Losses
rpn_class_loss = KL.Lambda(lambda x: rpn_class_loss_graph(*x), name="rpn_class_loss")(
[input_rpn_match, rpn_class_logits])
rpn_bbox_loss = KL.Lambda(lambda x: rpn_bbox_loss_graph(config, *x), name="rpn_bbox_loss")(
[input_rpn_bbox, input_rpn_match, rpn_bbox])
class_loss = KL.Lambda(lambda x: mrcnn_class_loss_graph(*x), name="mrcnn_class_loss")(
[target_class_ids, mrcnn_class_logits, active_class_ids])
bbox_loss = KL.Lambda(lambda x: mrcnn_bbox_loss_graph(*x), name="mrcnn_bbox_loss")(
[target_bbox, target_class_ids, mrcnn_bbox])
mask_loss = KL.Lambda(lambda x: mrcnn_mask_loss_graph(*x), name="mrcnn_mask_loss")(
[target_mask, target_class_ids, mrcnn_mask])rpn_class_loss :RPN网络分类损失函数
rpn_bbox_loss :RPN网络回归损失函数
class_loss :分类损失函数
bbox_loss :回归损失函数
mask_loss:Mask回归损失函数
4 分割掩码
分割掩码网络是 Mask R-CNN 的论文引入的附加网络,在气球分割中:

掩码分支是一个卷积网络,取 ROI 分类器选择的正区域为输入,并生成它们的掩码。其生成的掩码是低分辨率的:28x28 像素。但它们是由浮点数表示的软掩码,相对于二进制掩码有更多的细节。掩码的小尺寸属性有助于保持掩码分支网络的轻量性。在训练过程中,我们将真实的掩码缩小为 28x28 来计算损失函数,在推断过程中,我们将预测的掩码放大为 ROI 边框的尺寸以给出最终的掩码结果,每个目标有一个掩码。
代码提示:掩码分支网络在 build_fpn_mask_graph() 中。
5 网络结构-head

图中灰色部分是 原来的 RCNN 结合 ResNet or FPN 的网络,下面黑色部分为新添加的并联 Mask层,这个图本身与上面的图也没有什么区别,旨在说明作者所提出的Mask RCNN 方法的泛化适应能力 - 可以和多种 RCNN框架结合,表现都不错。
这里实际上有两个网络结构:
一个就是Fater R-CNN with ResNet/ResNeXt: overview的那副图(或者如上左边)。使用resnet-c4作为前面的卷积网络,将rpn生成的roi映射到C4的输出,并进行roi pooling,最后进行分叉预测三个目标。
另一个网络就是faster rcnn with FPN。
作为特征提取器。底层检测的是低级特征(边缘和角等),较高层检测的是更高级的特征(汽车、人、天空等)。
Mask RCNN个人理解
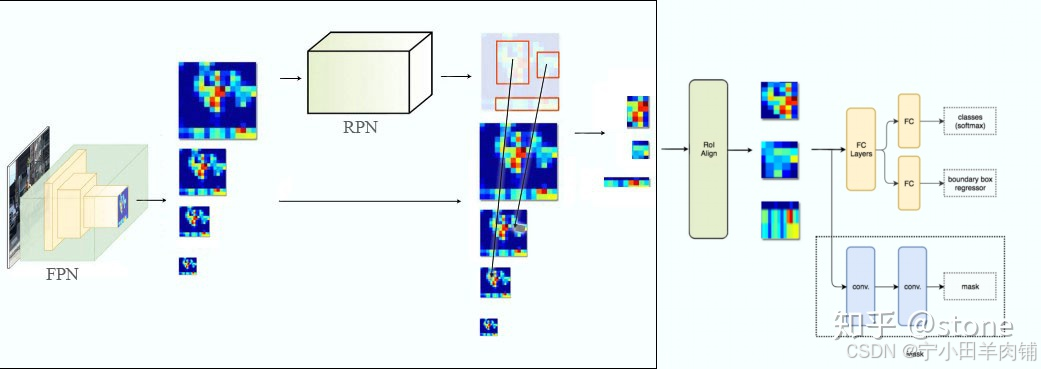
以ResNet-FPN提取图像信息,得到P2,P3,P4,P5这4张特征图像,另外一张P6是P5上采样的到,这5张大小不同,通道相同。
将上一步中P2,P3,P4,P5,P6特征图分别送入RPN,FasterRcnn的核心,用来找到最合适,最接近正确物体的框的4个坐标,和两个前景后景分数。但是这几张图生成那么多roi,选择哪些进行分类和回归呢?选择其中一张来选出真正的roi。这里有公式计算选择哪张特征图:其中224表示预训练的ImageNet图片的大小,k0表示面积为w*h=224*224的ROI所应该在的层级,作者将k设置为4,计算后,wh=224时,k=4,表示224的ROI应该从P4中切出来,这个方法可以根据roi大小选择在合适分辨率的特征图中切
进行边框回归和框内物体分类
ROI Align是为了弥补FasterRcnn中池化所有的roi为同一个尺寸后产生的细节问题,池化时,除不尽的时候会变为整数,造成池化后的roi所圈范围并不是真正的gt。roi Align采用了双线性插值,使roi更加精确。
损失函数L=Lcls+Lbox+Lmask cls是分类状况,box是边框回归状况,mask是有了分类后的类别之后开始对标注的实例进行分割,这里的标注是逐像素的。
【Faster RCNN】损失函数理解
1. 使用Smoooh L1 Loss的原因
对于边框的预测是一个回归问题。通常可以选择平方损失函数(L2损失)f(x)=x^2。但这个损失对于比较大的误差的惩罚很高。
我们可以采用稍微缓和一点绝对损失函数(L1损失)f(x)=|x|,它是随着误差线性增长,而不是平方增长。但这个函数在0点处导数不存在,因此可能会影响收敛。
一个通常的解决办法是,分段函数,在0点附近使用平方函数使得它更加平滑。它被称之为平滑L1损失函数。它通过一个参数σ 来控制平滑的区域。一般情况下σ = 1,在faster rcnn函数中σ = 3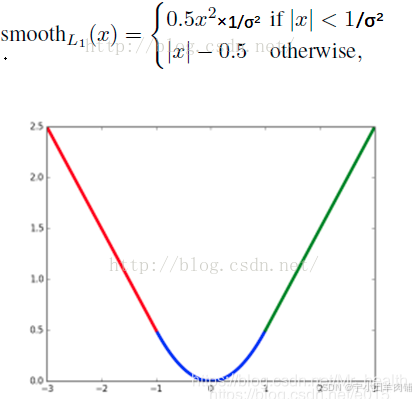


def _smooth_l1_loss(self, bbox_pred, bbox_targets, bbox_inside_weights, bbox_outside_weights, sigma=1.0, dim=[1]):
sigma_2 = sigma ** 2
box_diff = bbox_pred - bbox_targets #ti-ti*
in_box_diff = bbox_inside_weights * box_diff #前景才有计算损失的资格
abs_in_box_diff = tf.abs(in_box_diff) #x = |ti-ti*|
smoothL1_sign = tf.stop_gradient(tf.to_float(tf.less(abs_in_box_diff, 1. / sigma_2))) #判断smoothL1输入的大小,如果x = |ti-ti*|小于就返回1,否则返回0
#计算smoothL1损失
in_loss_box = tf.pow(in_box_diff, 2) * (sigma_2 / 2.) * smoothL1_sign + (abs_in_box_diff - (0.5 / sigma_2)) * (1. - smoothL1_sign)
out_loss_box = bbox_outside_weights * in_loss_box
loss_box = tf.reduce_mean(tf.reduce_sum(
out_loss_box,
axis=dim
))
return loss_box

















 3094
3094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









