






深度学习复现论文常见错误
简介
之前本来想做一个关于自己学习深度学习过程的文章,后来因为大四事比较多,就坚持了一小会,现在我想重操就业,一方面希望自己可以坚持一个有意义的事情,另一方面分享自己的学习经验希望帮助到需要帮助的人。我自己的目前的状态是学习深度学习一年多,django、flask也学习过一段时间也遇到了许多bug,前后python编程三年多,解决问题的有那么一点点长进。目前研一在读(2024/4/1),深知自己在黑暗里摸索的痛苦,自己找bug的痛苦。准备现在开始把自己遇到的bug总结在这里,供大家学习交流,希望这次可以坚持 !!
这是一个分割线
针对如何解决问题,最关键的是找到错误,然后再去解决问题,经常看到的错误是,当出现了一个bug,爆红一大片,然后对于初学者来说是无从下手的。。
先说一下怎么找错吧,总体上是这的,一般先看最后一行,会有一个报错类型,比如(TypeError、ValueError、IndexError)这个是挺关键的比如爆出了类型错误,你就知道可能是需要一个int类型,然后你给出了一个float类型,这时候你再往上翻错误,就会找到具体的出现问题的代码块(就是你写的代码对应的那行,把类型改好就可以了)这个我认为是最重要的环节,找到错误。
其实这时候,你找到了一个错误你知道报错的地方了,而且也找到具体代码块了,这个时候大部分人还是不知道怎么解决,这个时候就需要动手去百度了,一般是直接在比如这个Type Error:******* failed,一般直接把这一块直接复制就会有对应的解决方案,当然直接一次性解决也是不太可能的,可能需要多找几个方案。等到我找到合适的bug,我会演示一下。
比如以下这个bug:
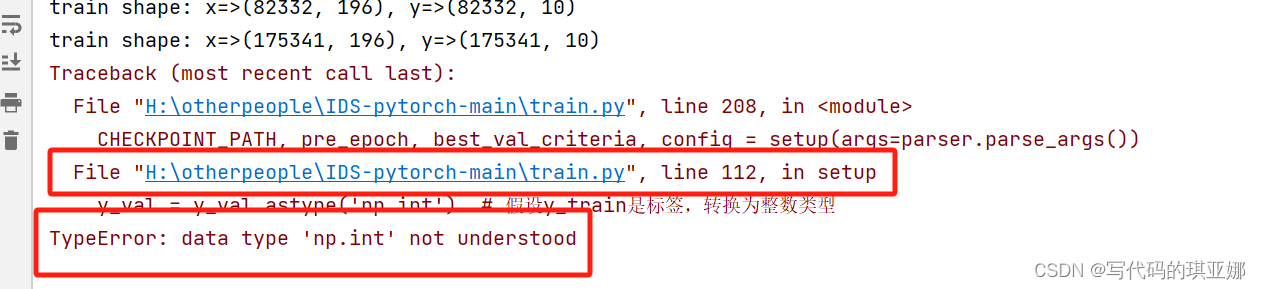
这里可以看出这个是数据类型错误,最后一行很容易就可以看到,这个由于我是在同一py文件下随手修改的,所以相隔比较近就可以找到对应位置一般是在其他文件下,我记得在YOLOV5时就有这个bug,这个就找到对应的行

发现是np.int,这个时候一开始是不知道怎么解决的,就需要先去百度直接复制最后一行就ok
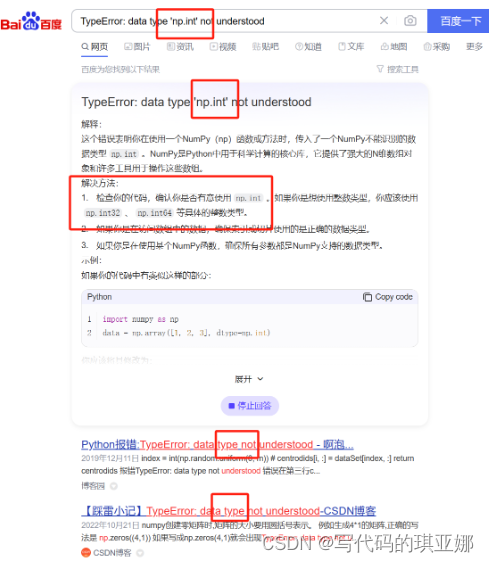
这时候我把重点标出来了,其实这样复制大部分是可以的,但是百度会给你一堆这样的情况,我看了一下第一页都是无法解决问题的。这就导致解决bug的难度大大提高,这时候发现匹配不全可以删除前边一部分

- 版本问题(灾难区tensorflow;cuda加速)
- 数据问题(权重文件 or 数据集)
- 系统问题(Windows or Linux)
- 隐形bug(找不到具体位置,深度学习不常见)
- 代码bug(主要是改模型遇到的bug)
这是我目前总结的,若有错误,欢迎大家指出
在这里错误里,个人感觉最让人讨厌的就是隐形bug和版本问题,一个是你找不到错误,另一个是找不到解决方案~其他问题解决起来相对容易,代码bug需要自己有一定的改代码的基础,稍微会点也不是很难。
常见解决途径
- Chat GPT
- 百度
- GitHub
- 官方文档(不适合大部分人)
下边是我感觉解决bug的顺序
1、出现了问题先看Github,下载代码的issues部分可能会出一些解决方案,当然现成的解决方案是最快的也是最准确的
2、GPT的话最容易的,基本可以解决大部分的bug。但是GPT也会胡言乱语,可能会带来更多的错误。。不过大部分都是可以解决了
3、百度的话,主要是需要尝试,很考验从垃圾捡金子的能力,一般第一页的是可以解决的,缺点就是浪费时间,但是基本可以解决所有的问题
4、实在解决不了只能求助官方文档了,基本需要的就是CTRL+A就可以追踪到代码位置,里边会有详细使用方式,然后自己根据断点一点点的改。当然这是一部分,另一个官方文档(线上的)会说明与之前的差距,会告诉你怎么改,但是这里涉及到了版本的问题,要改的地方十分多,我自己也没遇到过几次。一般不会到这一步,真这一步那就需要求助大佬了。。
数据集num_workers错误
这种错误是很常见,但是他不会说出具体的位置,我认为完全是自己的个人经验,一般在作者跑实验时设置的num_workers=!0的因为他们是在Linux下,自己使用Linux的情况比较少,这里推荐Windows用户第一步直接CTRL+F->num_workers=0就好了,具体的解释可以自行百度
self = reduction.pickle.load(from_parent)
EOFError: Ran out of input

Tensorboard
写在前边
这个东西是个让我非常伤脑筋的事,只是可视化就会遇到很多问题,先把我目前用的版本放一下
tensorboard 2.13.0
tensorboard-data-server 0.7.0
tensorboard-logger 0.1.0
tensorboard-plugin-wit 1.8.1
tensorboardX 2.6.2.2
tensorflow 2.13.0
tensorflow-estimator 2.13.0
tensorflow-intel 2.13.0
tensorflow-io-gcs-filesystem 0.31.0
tensorflow-probability 0.21.0
首先,Tensorboard是需要和Tensorflow的版本一致的,这个tensorboardX是pytorch的,可以不用版本一致。
话不多说开始正题
tensorboard --logdir=的问题
在我所用这个版本用=是不会报错的,但是不会显示内容,所以直接(以下是例子)这里路径是直接这样的,但是“=”位置不当也是会报错的 如下所示:
“= ” 报错 :tensorboard: error: invalid choice: ‘H:\Desktop\flower_classification_experiment2’ (choose from ‘serve’, ‘dev’)
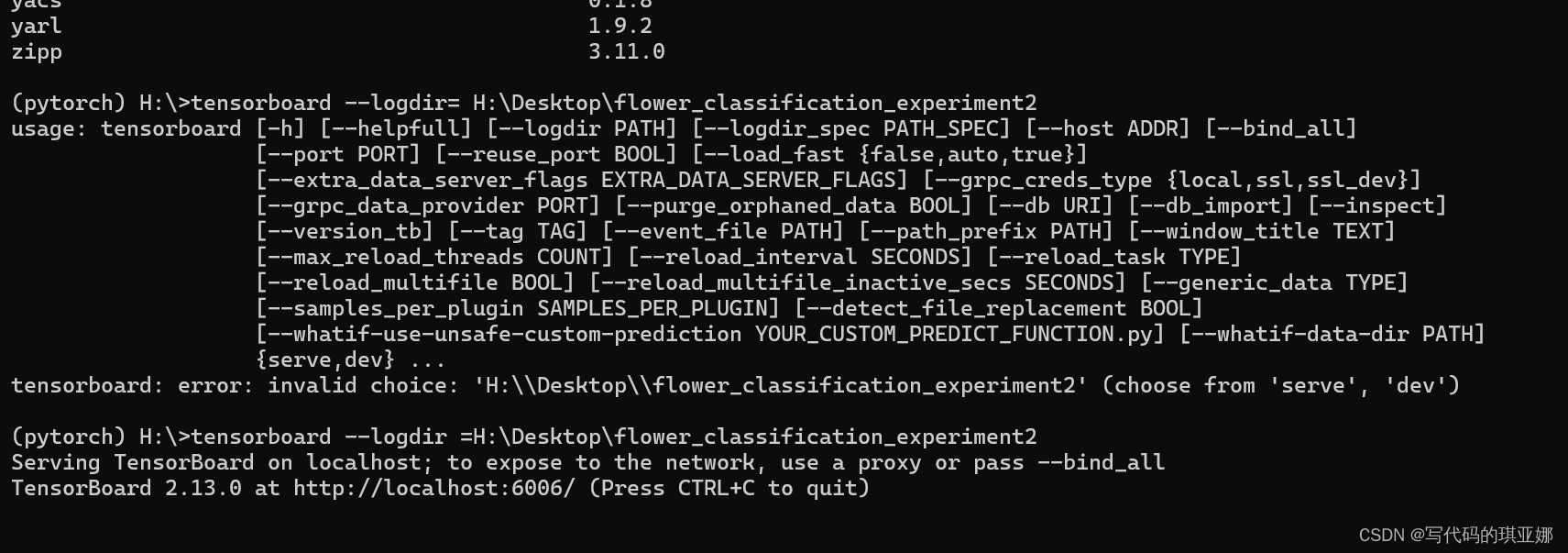
会有这样的一个错误No dashboards are active for the current data set导致任何数据显示不全.如下所示:
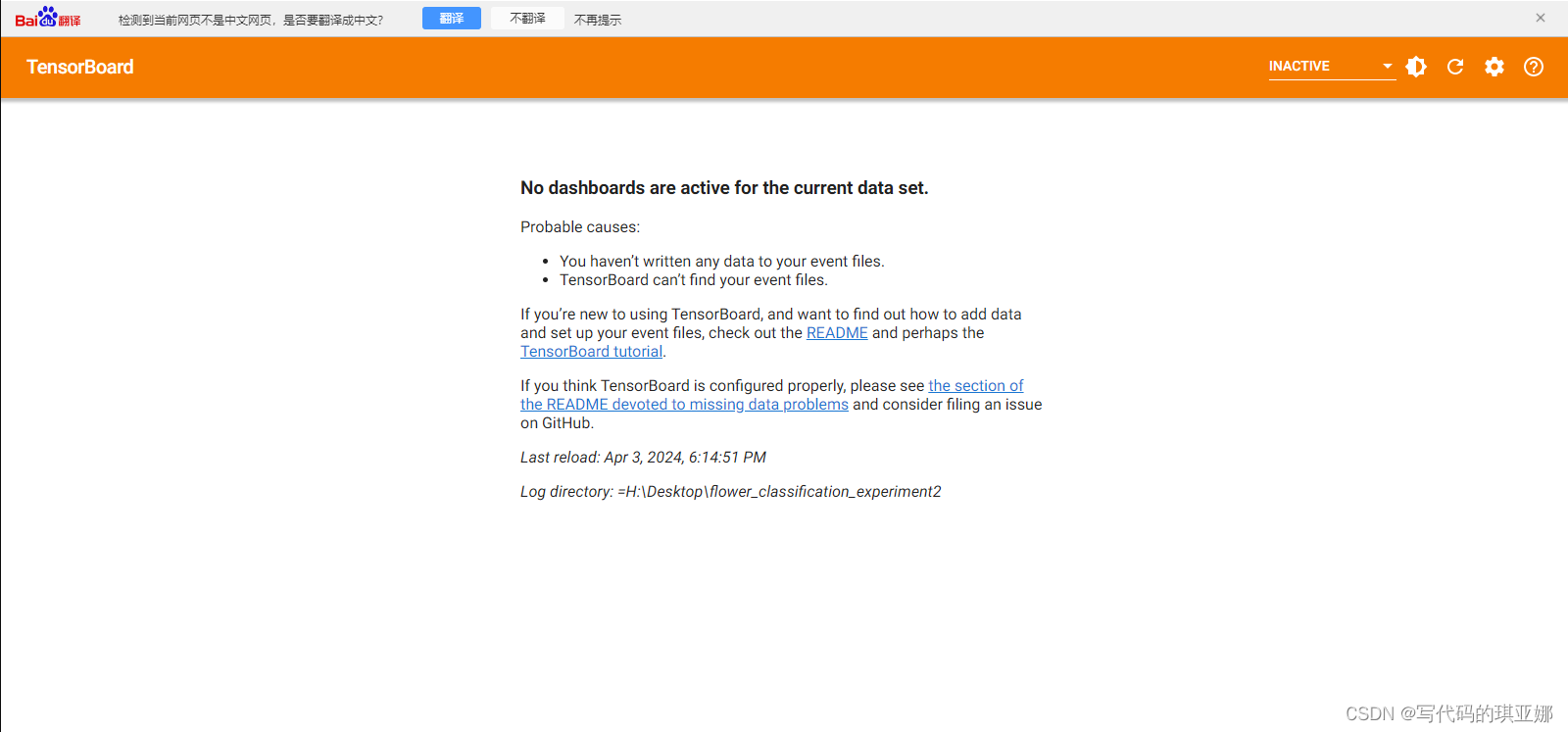
正确做法如下
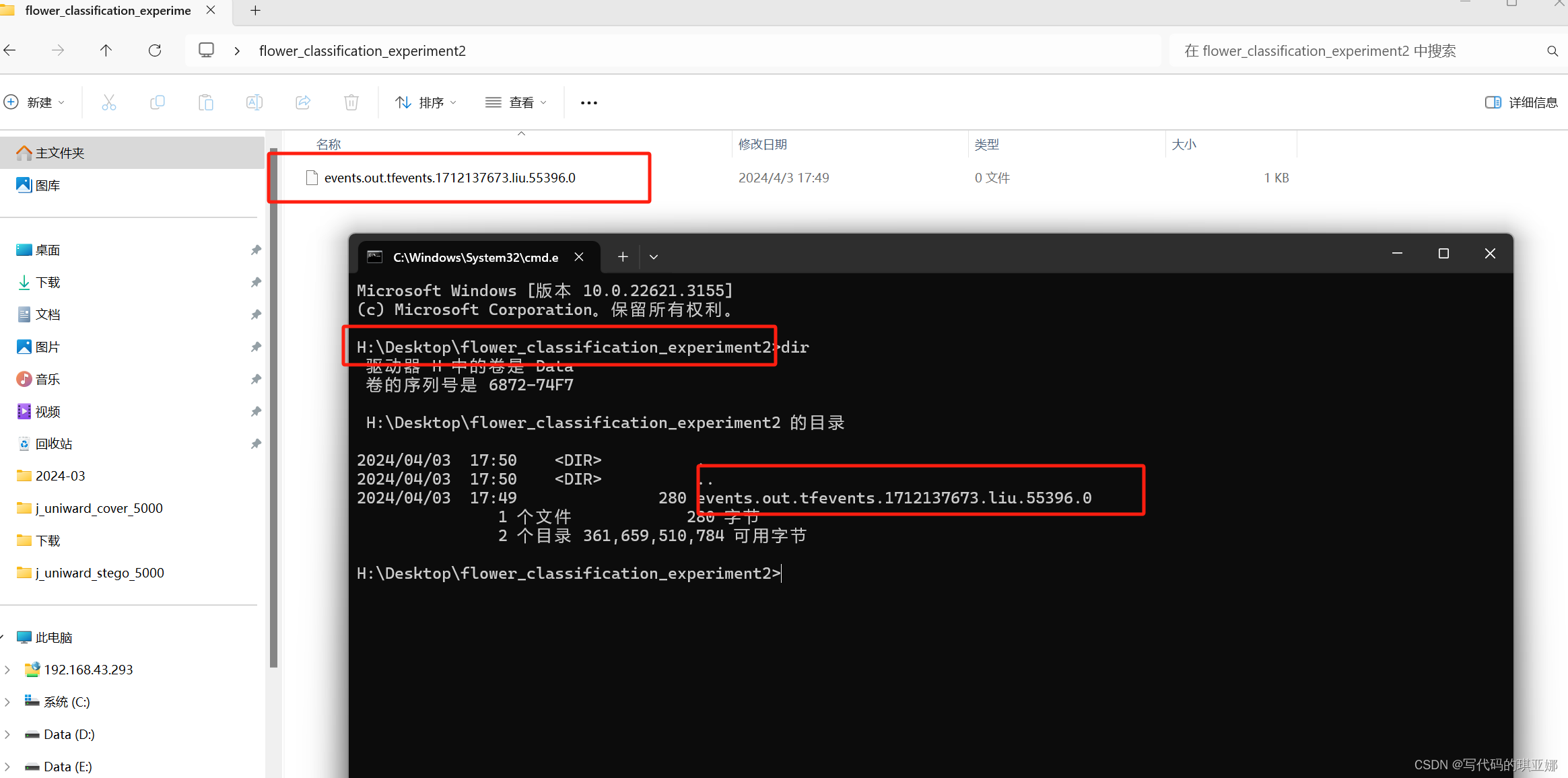
(pytorch) H:\>tensorboard --logdir H:\Desktop\flower_classification_experiment2
目录如下所示:
端口占用bug
端口被占用出现下列错误
(base) H:\>tensorboard --logdir H:\Desktop\flower_classification_experiment2
2024-04-03 19:07:38.447394: I tensorflow/core/util/port.cc:113] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2024-04-03 19:07:40.061305: I tensorflow/core/util/port.cc:113] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
E0403 19:07:43.698683 58852 application.py:125] Failed to load plugin WhatIfToolPluginLoader.load; ignoring it.
Traceback (most recent call last):
File "E:\anaconda\lib\site-packages\tensorboard\backend\application.py", line 123, in TensorBoardWSGIApp
plugin = loader.load(context)
File "E:\anaconda\lib\site-packages\tensorboard_plugin_wit\wit_plugin_loader.py", line 57, in load
from tensorboard_plugin_wit.wit_plugin import WhatIfToolPlugin
File "E:\anaconda\lib\site-packages\tensorboard_plugin_wit\wit_plugin.py", line 40, in <module>
from tensorboard_plugin_wit._utils import common_utils
File "E:\anaconda\lib\site-packages\tensorboard_plugin_wit\_utils\common_utils.py", line 17, in <module>
from tensorboard_plugin_wit._vendor.tensorflow_serving.apis import classification_pb2
File "E:\anaconda\lib\site-packages\tensorboard_plugin_wit\_vendor\tensorflow_serving\apis\classification_pb2.py", line 15, in <module>
from tensorboard_plugin_wit._vendor.tensorflow_serving.apis import input_pb2 as tensorflow__serving_dot_apis_dot_input__pb2
File "E:\anaconda\lib\site-packages\tensorboard_plugin_wit\_vendor\tensorflow_serving\apis\input_pb2.py", line 37, in <module>
_descriptor.FieldDescriptor(
File "E:\anaconda\lib\site-packages\google\protobuf\descriptor.py", line 561, in __new__
_message.Message._CheckCalledFromGeneratedFile()
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
默认是6006,只需要--port=6007
tensorboard --logdir H:\Desktop\flower_classification_experiment2 --port=6007
或者关闭那个进程,关闭进程不推荐,可能引发其他问题,推荐直接换一个端口。
关于CUDA out of Memory
最常见的一个bug就是爆显存了,这时候仅需要调整batch size就可以了,比如以下的错误
File "/home/liu/anaconda3/envs/python10/lib/python3.10/site-packages/mamba_ssm/ops/selective_scan_interface.py", line 182, in forward
delta = rearrange(delta_proj_weight @ x_dbl[:, :delta_rank].t(), "d (b l) -> b d l", l = L)
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 138.00 MiB. GPU 0 has a total capacty of 6.00 GiB of which 0 bytes is free. Including non-PyTorch memory, this process has 17179869184.00 GiB memory in use. Of the allocated memory 20.09 GiB is allocated by PyTorch, and 179.72 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
这样明显就算显存不够用了,这样仅仅调小batch size就可以,还有一个是在读取data时候有个参数 pin_memory=True,
RuntimeError: CUDA error: out of memory
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
当出现这个问题时可以考虑将这个True改为False

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









