






 本文详细介绍了Transformer中Patch Merging层的工作原理和实现方式,该层用于下采样,减少分辨率,调整通道数,并在保持信息完整性的前提下节省计算量。与传统的池化操作不同,Patch Merging通过拼接相邻的patch来实现降采样,最终通过线性层减少通道数。源代码展示了如何在PyTorch中实现这一过程。
本文详细介绍了Transformer中Patch Merging层的工作原理和实现方式,该层用于下采样,减少分辨率,调整通道数,并在保持信息完整性的前提下节省计算量。与传统的池化操作不同,Patch Merging通过拼接相邻的patch来实现降采样,最终通过线性层减少通道数。源代码展示了如何在PyTorch中实现这一过程。
1.图示
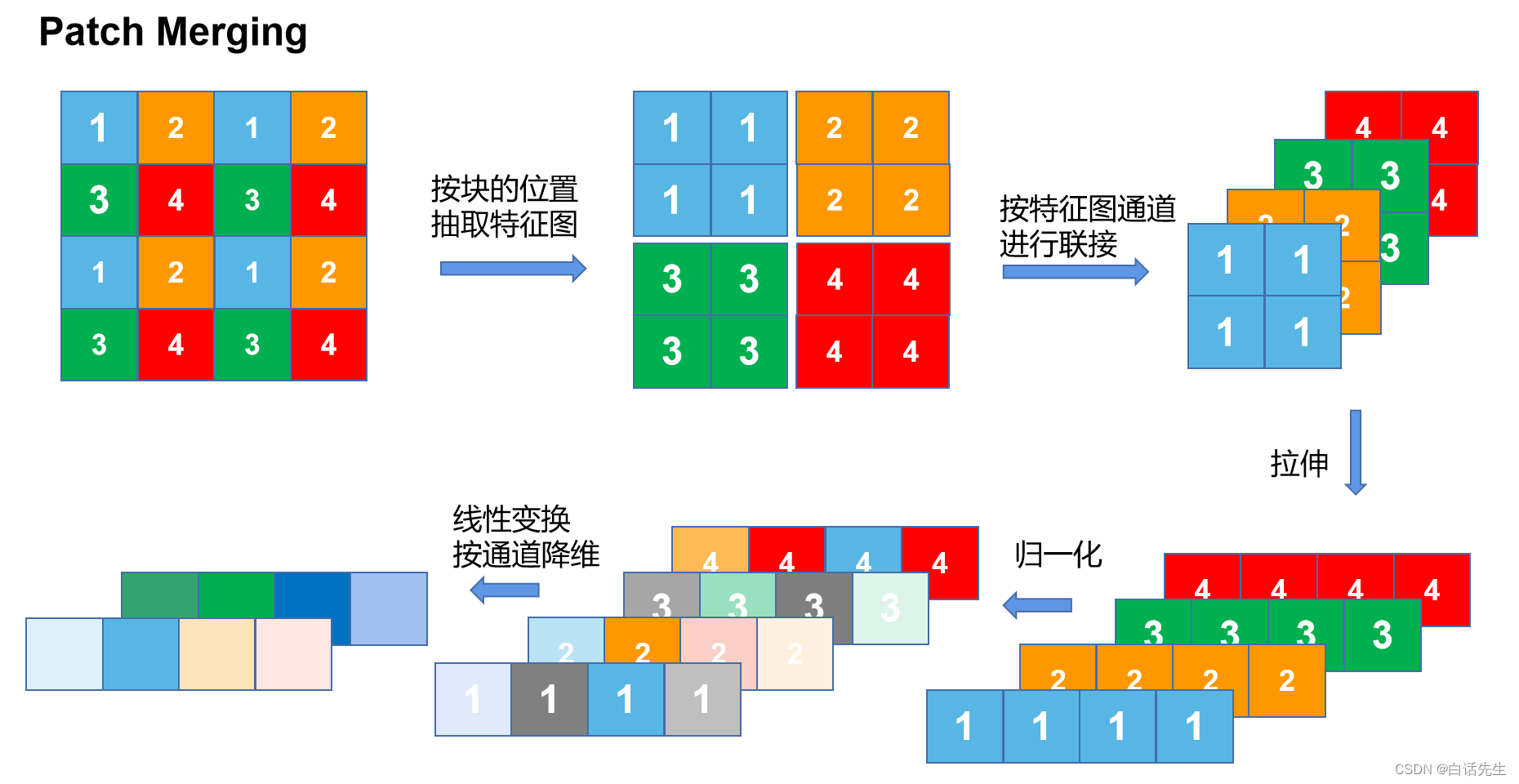
2.原理
Patch Merging层进行下采样。该模块的作用是做降采样,用于缩小分辨率,调整通道数 进而形成层次化的设计,同时也能节省一定运算量。
在CNN中,则是在每个Stage开始前用stride=2的卷积/池化层来降低分辨率。
patch Merging是一个类似于池化的操作,但是比Pooling操作复杂一些。池化会损失信息,patch Merging不会。
每次降采样是两倍,因此在行方向和列方向上,按位置间隔2选取元素,拼成新的patch,再把所有patch都concat起来作为一整个张量,最后展开。此时通道维度会变成原先的4倍(因为H,W各缩小2倍),此时再通过一个全连接层再调整通道维度为原来的两倍。
3.源码
import torch
import torch.nn as nn
import math
import numpy as np
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
B, L, C = x.shape
H = int(math.sqrt(L))
W = int(math.sqrt(L))
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
print('--------------------------')
print(x)
print('原始图像4D维度:',x.shape)
# 在行和列方向上间隔1选取元素
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
print('--------------------------')
print(x0)
print('切分图像4D维度:',x0.shape)
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
print('--------------------------')
print(x1)
print('切分图像4D维度:',x1.shape)
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
print('--------------------------')
print(x2)
print('切分图像4D维度:',x2.shape)
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
print('--------------------------')
print(x3)
print('切分图像4D维度:',x3.shape)
# 拼接到一起作为一整个张量
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
print('--------------------------')
print(x)
print('拼接整个张量后:',x.shape)
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
print('--------------------------')
print(x)
print('合并行和列后:',x.shape)
x = self.norm(x) # 归一化操作
print('--------------------------')
print(x)
print('归一化操作后:', x.shape)
x = self.reduction(x) # 降维,通道降低2倍
print('--------------------------')
print(x)
print('通道降低2倍后:', x.shape)
return x
if __name__ == "__main__":
x = np.array([[0, 2, 0, 2],[ 1, 3, 1, 3 ],[ 0, 2, 0, 2 ],[ 1, 3, 1, 3 ]])
x = torch.from_numpy(x)
x = x.view(1, 4*4, 1)
x=x.to(torch.float32)
model = PatchMerging(1)
print('--------------------------')
print(x)
print('原始图像3D维度:', x.shape)
y = model(x)

















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









