







Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
https://github.com/microsoft/Swin-Transformer
实验记录
微软使用分布式训练,每个主机用8块卡!
改成非分布式训练4GPU,估计会炸显存。。。
单卡32G显存,batch size=64仅占一半显存,128也没任何问题(显存利用率达到了90.28%)
6500+数据量 && img_size=224+caching && batch_size=128 && epochs=75:1小时 8分 49秒,平均速率50s/epoch。
Swin Transformer源码剖析
Image to Patch Embedding
patch=4x4x3;
patches_resolution = [224//4, 224//4];
Linear Embedding projection就是一层卷积nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size),将每个patch由3通道卷成C通道;
示例:
(1, 3, 224, 224) -> (1, 96, 112, 112) -> (1, 96, 112*112)
-> (1, Ph*Pw, C)=(1, 112*112, 96)
其中,(B, Ph*Pw, C)也作(B, L, C),C放后面是便于nn.Linear处理。
WindowAttention(W-MSA/SW-MSA)
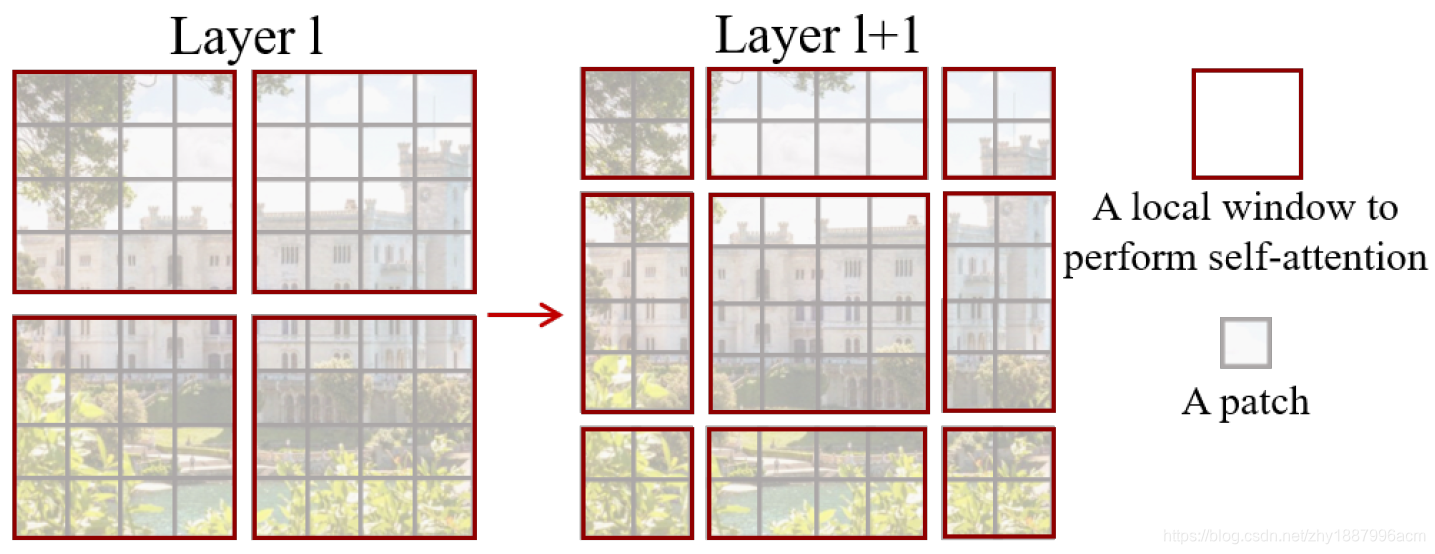
针对partition windows层面计算多头self-attention,并加入relative position bias来关联位置信息,可同时支持W-MSA和SW-MSA。
输入x: (num_windows*B, N, C),assert N == window_size*window_size;
qkv: nn.Linear(dim, dim * 3, bias=qkv_bias:[True]),query, key, value;dim=int(embed_dim * 2 ** i_layer),embed_dim=96,则Number of input channels: dim=int(96 * 2 ^ 0/1/2/3)=96/192/384/768;depths=[2, 2, 6, 2],num_layers=4;num_heads=[3, 6, 12, 24],Number of attention heads(H);每个head都有自己的参数,源码中将输入x的qkv结果均分给了所有attention heads,H次放缩点积结果进行拼接;relative_position_bias_table记录每个attention head处理的偏置值;
输出y: 与x的shape完全相同;
window_partition
输入x: (B, H, W, C)和window_size;
输出y: 即不重叠的windows: (num_windows*B, window_size, window_size, C);
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
window_reverse
与window_partition正好相反;
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
PatchMerging
输入x: (B, H*W, C);
输出y: (B, H/2*W/2, 2*C);
格子间隔取数,降维,但通道数变成4*C,最后还用了一层Linear将通道数降为2*C;
SwinTransformerBlock(depths=[2, 2, 6, 2])

输入x: (B, L, C),assert L == H * W;
输出y: 与x的shape完全相同;W-MSA、SW-MSA、MLP后面都使用了随机深度(Stochastic depth,Drop paths:Deep Networks with Stochastic Depth (https://arxiv.org/abs/1603.09382));
每逢奇数depth则shift window,shift_size=window_size // 2;偶数depth则不进行shift;因此每个stage都是偶数个SwinTransformerBlock,盲猜是为了均衡吧,交替执行Shift windows(Swin)。
LN:nn.LayerNorm层;
W-MSA/SW-MSA:WindowAttention层;
MLP:全连接层1——激活函数——Dropout——全连接层2——Dropout,目的是为了把in_features映射为out_features!提高学习能力!😮。实际源码中out_features=in_features,MLP只有一层hidden layer,通道数:窄-宽-窄,宽窄相间更有利于学习!
采用了cyclic shift以简化运算,torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))。
BasicLayer
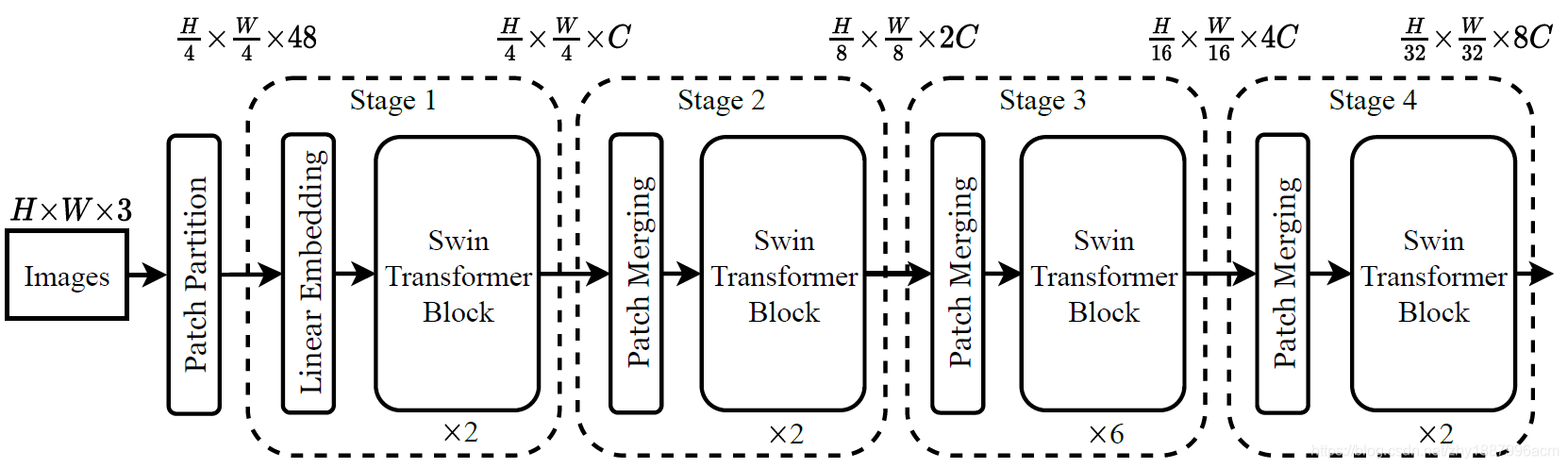
BasicLayer里实现SwinTransformerBlocks的堆叠,之后需要进行PatchMerging(downsample,除了最后一层)。


















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









