









此文是对论文Generative Adversarial Nets读后的一个总结。
参考博客1:地址
参考博客2:地址
参考新闻3:地址
参考Twitter4:地址
1、简单总结
GAN是一个极大极小博弈问题,网络中分为两个模型,一个生成模型G,作为生成器,用来生成与真实数据x极为相似的含有噪音z的数据;一个判别模型D,作为判别器,用来判别数据中哪些是真实数据x,哪些是G生成的伪数据。而GANs做的就是最大化D,最小化G。
生成对抗网络,由两个网络组成,即生成器和判别器,两者都是由感知器组成。生成器用来建立满足一定分布的随机噪声和目标分布的映射关系,判别器用来区别实际数据分布和生成器产生的数据分布。在训练的过程中,交替迭代训练生成器和判别器,使得生成器产生的数据分布逼近真实数据的分布,欺骗判别器;判别器提升两个数据分布的判别能力。最终达到纳什均衡,使得判别器无法判断两个分布的真伪。
2、进一步总结
首先Generative,在机器学习中含有两种模型,生成式模型(Generative Model)和判别式模型(Discriminative Model)。生成式模型研究的是联合分布概率,主要用来生成具有和训练样本分布一致的样本;判别式模型研究的是条件分布概率,主要用来对训练样本分类。
判别式模型因其多方面的优势,在以往的研究和应用中占了很大的比例,尤其是在目标识别和分类等方面;而生成式模型则只有很少的研究和发展,而且模型的计算量也很大很复杂,实际上的应用也就比判别式模型要少很多。而本文就是一篇对生成式模型的研究,当然也说明了这篇文章做描述的生成式模型是和传统的生成式模型是很不同的,那么不同之处在哪里呢?
然后Adversarial,这边是这篇文章与传统的生成式模型的不同之处:对抗,谁与之对抗呢?当然就是判别式模型,那么,如何对抗呢?这也就是这篇文章主要的研究内容。类似于这样一个故事,生成式模型就像是罪犯,专门造假币,判别式模型就像是警察,专门辨别假币,那生成式模型就要努力提高自己的造假技术使造的假币不被发现,而判别式模型就要努力提高自己辨别假币的能力。这就类似于一个二人博弈问题。最终的结果就是两人达到一个平衡的状态,这就是对抗。
那么这样的对抗在机器里是怎样实现的呢?在论文中,真实数据x的分布为1维的高斯分布p(data),生成器G为一个多层感知机,它从随机噪声中随机挑选数据z输入,输出为G(z),G的分布为p(g)。判别器D也是一个多层感知机,它的输出D(x)代表着判定判别器的输入x属于真实数据而不是来自于生成器的概率。再回到博弈问题,G的目的是让p(g)和p(data)足够像,那么D就无法将来自于G的数据鉴别出来,即D(G(z))足够大;而D的目的是能够正确的将G(z)鉴别出来,即使D(x)足够大,且D(G(z))足够小,即(D(x)+(1-D(G(z))))足够大。
那么模型的目标函数就出来了,对于生成器G,目标函数为(梯度下降):
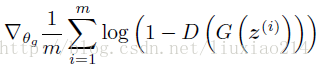
而对于判别器D,目标函数为(梯度上升):
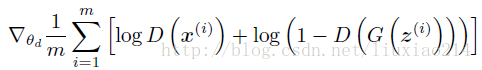
于是模型就成了优化这两个目标函数的问题了。这样的话就只需要反向传播来对模型训练就好了,没有像传统的生成式模型的最大似然函数的计算、马尔科夫链或其他推理等运算了。
也就是方程式:
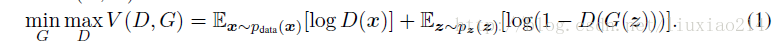
3、最终总结
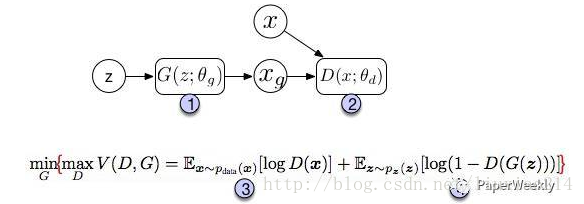
图中上半部分是GAN模型的基本架构。我们先从一个简单的分布中采样一个噪声信号 z(实际中可以采用[0, 1]的均匀分布或者是标准正态分布),然后经过一个生成函数后映射为我们想要的数据分布 Xg (z 和 X 都是向量)。生成的数据和真实数据都会输入一个识别网络 D。识别网络通过判别,输出一个标量,表示数据来自真实数据的概率。
在实现上,G 和 D 都是可微分函数,都可以用多层神经网络实现。因此上面的整个模型的参数就可以利用backpropagation来训练得到。
图中的下半部分是模型训练中的目标函数。仔细看可以发现这个公式很像cross entropy,注意D是 P(Xdata) 的近似。对于 D 而言要尽量使公式最大化(识别能力强),而对于 G 又想使之最小(生成的数据接近实际数据)。
整个训练是一个迭代过程,但是在迭代中,对 D 的优化又是内循环。所以每次迭代,D 先训练 k次,G 训练一次。
4、拓展延伸
GAN模型最大的优势就是训练简单,但是也有缺点比如训练的稳定性。有趣的是,在这篇文章future work部分,作者提出了5个可能扩展的方向,而现在回过头来看,后续的很多工作真的就是在照着这几个思路填坑。比如第一个conditional generative model就是后面要讲的conditional GAN的思路,而最后一个determing better distribution to sample z from during training则是后面InfoGAN的思路。
所以基于这些,先对关于GANs的一些延伸做个总结,方便以后的学习。
衍生模型结构图:
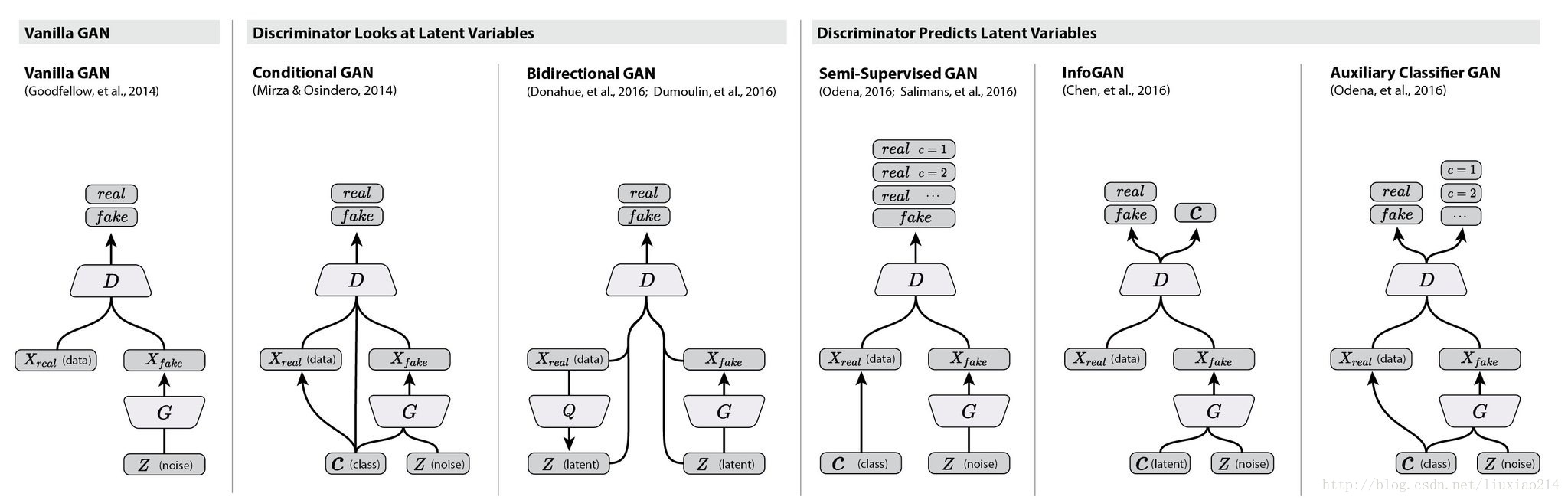
4.1 DCGAN
上面Ian J. Goodfellow等人的文章提出了GAN的模型和训练框架,但是没有描述具体的实现,而DCGAN这篇文章讲的就是用deep convolutional network实现一个生成图片的GAN模型。这篇文章没有在基本模型上有所扩展,但是他描述了很多实现上细节,尤其是让GAN模型stable的方法。所以如果对于GAN的实现有兴趣,这篇文章也是必读。此外,最新NIPS2016也有最新的关于训练GAN模型的总结 [How to Train a GAN? Tips and tricks to make GANs work]。
4.2 infoGAN
在GAN模型中,生成模型的输入是一个连续的噪声信号,由于没有任何约束,即便我们得到一个有效的生成模型,z也不能被很好的解释。为了使输入包含可以解释,更有信息的意义,InfoGAN这篇文章的模型在z之外,又增加了一个输入c,称之为隐含输入(latent code),然后通过约束c与生成数据之间的关系,使得c里面可以包含某些语义特征(semantic feature),比如对MNIST数据,c可以是digit(0-9),倾斜度,笔画厚度等。具体做法是:首先我们确定需要表达几个特征以及这些特征的数据类型,比如是类别(categorical)还是连续数值,对每个特征我们用一个维度表示ci 。
接下来,利用互信息量来约束c。原理在于,如果 c 和生成的图像之间存在某种特定的对应(如果c是图像的某些特征,则有这样的函数存在),那么c和G(z,c)之间就应该有互信息量。如果是无约束的情况,比如z单独的每一个维度都跟和G(z)没有特定的关系,那么它们之间的互信息量应该接近0。所以加上这个约束之后,要优化的目标函数就变成了
min max V(D,G) = V(D,G) - �� I(c;G(z,c))
接下来就是如何处理 I(c; G)。由于 I(c;G(z,c)) 的计算需要 p(c|x),而我们并不知道真实的分布。这时候,我们需要用一个 Q(c|x) 来近似,很显然,Q可以用神经网络来实现。此外, 可以利用reparametrization(可见原文附录中的解释)的技巧来简化网络。
在实际中,由于Q和D都是输入x,而且识别网络D除了可以输出概率,也可以做特征提取,因此Q可以和D共享参数。在正常的D之后,额外加一层full connected layer,利用softmax等可以输出c。结构图如下:
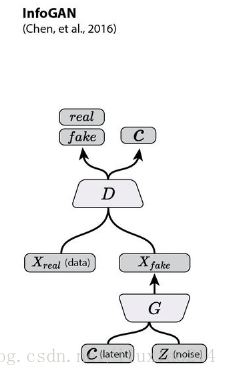
4.3 conditional GAN
Conditional GAN这篇论文中的基本模型如下图所示。
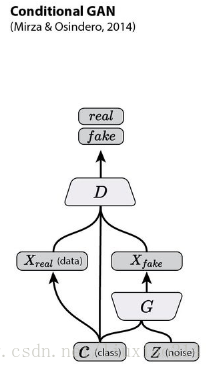
所谓conditional的意思就是,生成图片的模型变成了 P(X|z, c),而c是我们额外提供的信息。这里要注意conditional GAN和Info GAN的结构区别:
1、Info中c信息是需要网络去学习提取的特征,而这里是需要我们输入网络的信息。
2、Info中c只输入生成网络,而这里需要同时输入生成和识别网络,以便让网络学习到它们之间的关联。
在Conditional GAN中,随着c的变换可以衍生出很多应用,比如输入可以是label,可以是分类。甚至是另外一个图片,比如可以做image to image的风格转换,也可以做分辨率提升super-resolution。这里我们以Text-to-Image为例,讲一下conditional GAN的一种建模方法。
同样,先上图:
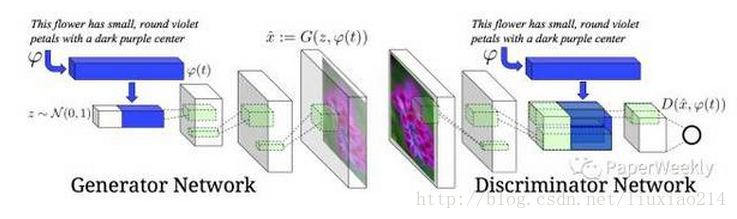
模型的任务是给定一句文字描述,然后可以生成符合描述的图像。可以看到,网络的输入除了采样噪声z以外还有文字信息。整个任务分为两大部分:第一部分是要对文字进行编码(text encoding),这部分并不是Conditonal GAN模型的一部分,可以使用RNN或者char-CNN等。文中用的是deep convolutional and recurrent text encoder ,感兴趣可以去看这篇文章。
在模型中,文字信息同时输入 G 和 D 是关键所在,这样网络才能够将文字和图片关联起来。其次,在训练中,原GAN中 D 只需要判断两种数据:real/fake的图片。而这里,D 需要判断(输入)三种数据{real image, right text},{real image, wrong text}以及{fake image, right text}。
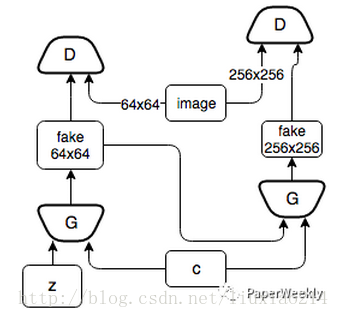
4.4 Stack GAN
StackGAN这篇文章模型本质就是是Conditional GAN,只不过它使用了两层conditional GAN模型,第一层模型 P(X1|z, c) 利用输入的文字信息c生成一个较低分辨率的图片。之后第二层模型 P(X|c,,X1) 基于第一层生成的图片以及文字信息生成更加优化的图片。文中给出的实验效果非常的惊人,可以生成256x256的非常真实的图片。这里不再重复细节。下图为简化的StackGAN模型。
5、本篇总结
预计下篇博客开始做一个关于GAN的应用。应该会参考这篇文章来做。
或者,应该先看DCGAN这篇论文,然后看一下16年Goodfellow在NIPS会议上做的口头报告视频。
视频相关资料解读:
1、“GANs之父”Goodfellow 38分钟视频亲授:如何完善生成对抗网络?(上)
2、NIPS 2016 Tutorial:Generative Adversarial Networks
3、译文 | GAN之父在NIPS 2016上做的报告:两个竞争网络的对抗
4、How to Train a GAN? Tips and tricks to make GANs work
5、新闻1
以上。















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









