







Relevance of Unsupervised Metrics in Task-Oriented Dialogue for Evaluating Natural Language Generation
https://arxiv.org/pdf/1706.09799.pdf
实现地址:https://github.com/Maluuba/nlg-eval
自动化度量指标(BLEU等)已经广泛用于机器翻译中,在任务型 task-oriented 对话中,这些指标也与人类判断有很好的相关性。对于提供多个 ground truth 参考语句的数据集,相关性甚至更好。
基于规则和模板的对话响应生成系统 (Axelrod, 2000; Elhadad, 1992) 已经存在很长时间,直到今天,在生产环境中部署的许多任务型对话系统仍然是基于规则和模板的。这些系统不会随着域复杂性的增加而扩展,并且维护模板数量的增加会变得很麻烦。因此 (Oh and Rudnicky 2000) 提出一种基于语料库的任务型对话系统自然语言生成方法 NLG。其他统计方法还有基于树的模型和强化学习 (Walker et al., 2007; Rieser and Lemon, 2009)。近来,基于深度学习的方法在对话生成任务中取得了更好的结果。
机器生成语言的自动评价是一个具有挑战性的问题,也是 NLP 面临的一个重要问题。目前广泛使用的自动化度量基于单词重叠 word-overlap,如 BLEU、METEOR (Papineni et al., 2002; Banerjee and Lavie, 2005),它们最初是为机器翻译提出的。由于非任务型对话更具多样性,单词重叠度量无法捕获语义,因此即便是适当的回答也可能导致较差的分数。在这种情况下,人工评估是最可靠的度量,然而,人工评估是昂贵的、不能随时获得。
任务型对话系统被应用在更窄的领域(如预订餐厅),响应的多样性不如非任务型的环境。另一个重要的区别是,在非任务型对话中,响应生成通常是端到端执行的,这意味着模型将用户最后一句话和对话历史信息作为输入,输出模型生成的回答;而在任务型对话中,语言生成任务通常被看作是一个从句子的抽象表征到句子本身的翻译步骤,因此,将生成的句子与参考句子进行比较的自动化度量可能适合用来评估。在这篇论文中,作者:
• 研究两个主流的任务型对话数据集上的人工评估和几个无监督自动化指标之间的相关性;
• 引入现有模型的变体,并评估它们在这些指标上的表现。
Metrics
首先考虑 word-overlap metrics,然后考虑 embedding-based metrics,当提供多个参考句时,逐个计算预测与参考句之间的相似度,选择最大值,然后对整个语料库的分数进行平均。
1. Word-overlap based metrics
(1)BLEU
比较候选句子和参考句子的 n-gram:
{Candidates} 是模型产生的候选句子, 是截断计数,是一个 n-gram 在候选句子中出现的次数,与它在各个参考句子中出现次数的最大值进行比较,再取二者之间较小的那一个。BLEU-N 分数定义为:
其中 N 为 n-grams 的最大长度,一般只计算 BLEU-1 ~ BLEU-4;wn 为不同 gram 的权重,一般都取1;BP 是短句惩罚项。论文考虑了语料库级和句子级的 BLEU 分数,以分析其与人类评价的相关性。
(2)METEOR
一种在句子级更好地与人类评价相关联的度量。首先将候选句中的每个 unigram 映射为参考句中 unigram 的0或1,创建候选句和参考句之间的对齐,这种对齐不仅基于精确匹配,而且还基于词干、同义词和释义匹配。基于对齐计算 unigram 准确率和召回率:
其中 为准确率与召回率之间的调和均值,召回率的权重为准确率的9倍,p为惩罚率。
(3)ROUGE
最早是用于摘要的度量标准,论文中计算候选句和参考句之间的最长公共子序列(LCS)的 ,即 ROUGE-L。
2. Embedding based metrics
考虑另一种不依赖单词重叠的度量方式,计算候选句和参考句的向量之间的余弦相似度。
(1) Skip-Thought
以一种无监督方式训练,并使用一个递归网络(GRU)将给定句子编码成向量,然后解码它来预测前后句子。编码器产生的向量在语义关联任务上是健壮的。
(2)Embedding average
通过对组成句子的单词 w 的向量 进行平均来计算句子 C 的向量:
(3)Vector extrema
取句子中的单词在每个维度上的极值计算句子级向量:
其中,d是维数的索引。
(4)Greedy matching
不计算句子向量,而是直接计算候选句 C 和参考句 r 之间的相似度评分:
即候选句中的每个单词和参考句中的每个单词的余弦相似度贪婪匹配的平均值,交换候选句和参考句以同样的方式计算,将两种分数的平均作为最终的相似度分数。
响应生成模型
介绍论文中使用的不同 NLG 模型,所有这些模型都将一组可能具有槽类型和槽值的对话行 dialogue acts为作为输入,并将该输入转换为话语。一个输入示例是 inform(food = Chinese),相应的输出是“我正在寻找一家中国餐馆”。在这个例子中,对话行为是inform,槽类型是food,槽值是Chinese。
(1)Random
给定一个具有一个或多个槽类型的对话行为,随机模型将查找训练集中具有相同对话行为和槽类型的所有示例(忽略槽值),并从参考语句中随机选择输出。作者的数据集有一些特殊的槽值,比如“yes”、“no”、“don 't care”,由于模型忽略了所有槽值,所以这些特殊情况没有得到适当的处理,导致如果不花费更多时间手工处理这些值会降低模型性能。
(2)LSTM
对话行为和槽类型首先被编码为一个二进制向量 DA,其长度为数据集中对话行为和槽类型可能组合的数量。给定对话行为集合的DA向量是融合对话行为槽类型上的二进制向量,例如 INFORM-FOOD、INFORM-COUNT 等。
这个二进制向量为 LSTM 解码器每个时间步长的输入,解码器输出一个 delexicalized 句子,包含槽值的占位符。例如“I am looking for a FOOD restaurant.”,直接从输入中复制 dexicalized slots 的值(在本例中是 food 的类型)。
(3)delex-sc-LSTM
除了在解码器中使用 sc-LSTM (Wen et al., 2015b) 单元而不是 LSTM 单元外,该模型与上一个 LSTM 模型架构相同,DA 向量同样只编码对话动作和 dexicalized slots,不包含槽值的信息。
通过向该模型提供与 LSTM 模型相同的 DA 向量输入,可以研究 sc-LSTM 单元的读取门的额外复杂性是否比当前可用的小型任务型对话数据集有显著的改进。
(4)hierarchical-lex-delex-sc-LSTM
该模型是 (Sharma et al., 2017) 提出的 ld-sc-LSTM 模型的变体。
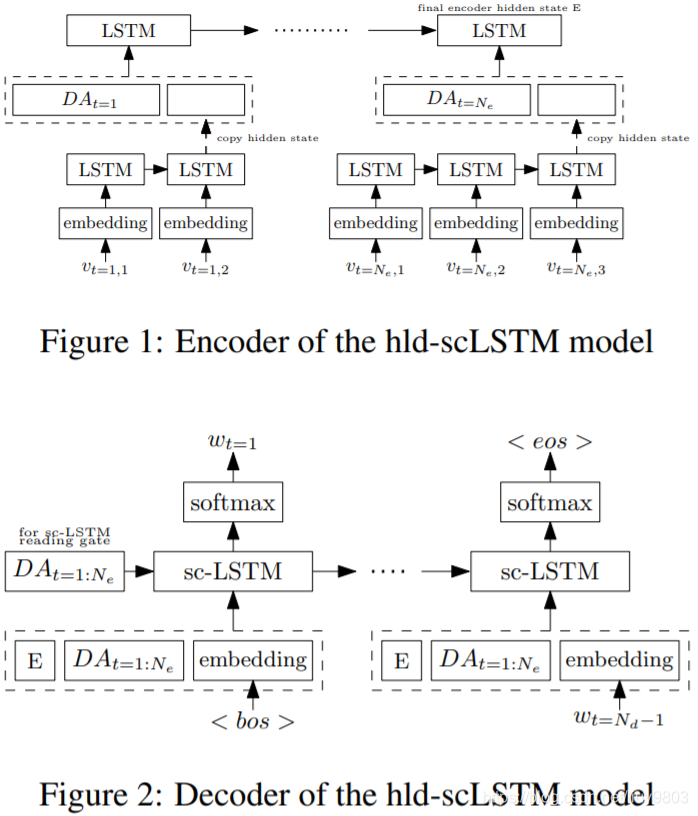
图1为编码器,由一个具有 个时间步的层次 LSTM 组成,
是 DA 向量中非零项的数目。编码器每个时间步编码一个对话行为的 delexicalized and lexicalized slot-value pair(INFORM-FOOD, “Chinese”)。Delexicalized act-slot 部分被编码为一个 one-hot 向量
,通过 mask 掉 DA 中除了第 t 个对话行为之外的其他行为来构造的。Lexicalized 值部分由 LSTM 编码器进行编码,该编码器跨所有时间步共享参数,并使用词法化值
的词向量。本模型与 ld-sc-LSTM 的不同之处在于:使用 LSTM 编码器得到词向量,而不是计算词向量的平均值,LSTM 的最终隐藏状态与
连接,作为上层 LSTM 的输入(见图1),然后将上层 LSTM 的最终隐藏状态输入到解码器;只使用最后的隐藏状态E,比使用编码器所有隐藏状态的平均值的效果要好。
图2为解码器,与 ld-sc-LSTM 相同。每个时间步的输入为编码器输出 E、DA 向量,和前一个时间步产生的词的词向量。DA 向量还被额外提供给 sc-LSTM cell 用于其读取门的正则。
实验
训练时每个时间步,都使用前一个时间步的 ground truth 单词,因此模型学会根据前一个单词生成下一个单词。使用 beam search 测试生成句子,生成器的第一个单词输入是 < bos > 表示序列的开始,如果达到了指定的最大时间步长,或者如果模型输出 < eos > 就停止解码。使用槽错误率惩罚项,重新排列 beam search 生成的句子。对 LSTM、d-scLSTM 和 hld- scLSTM 三个模型都使用此方法。与 LSTM 模型相似,d-scLSTM 和 hld- scLSTM 产生去词汇化的句子,即生成 slot token,而不是直接生成槽值,在后处理步骤中被替换为槽值。
自动评价通常用于改进生成式 NLP 任务,在非任务型对话中,与人类评估仅有微弱的相关性 (Liu et al., 2016)。由于人类评估很昂贵,易用且快速的自动化指标被广泛采用。
使用自动评价指标评估上述模型在 DSTC2 (Henderson et al., 2014) 和餐馆数据集 (Wen et al., 2015a) 的表现,实验结果如表1和表2所示,自动度量评估代码在 https://github.com/Maluuba/nlg-eval
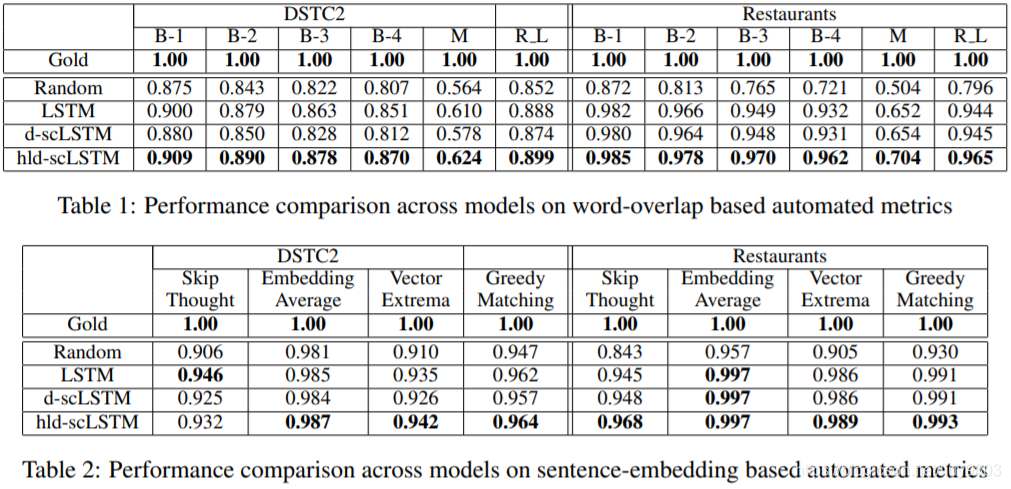
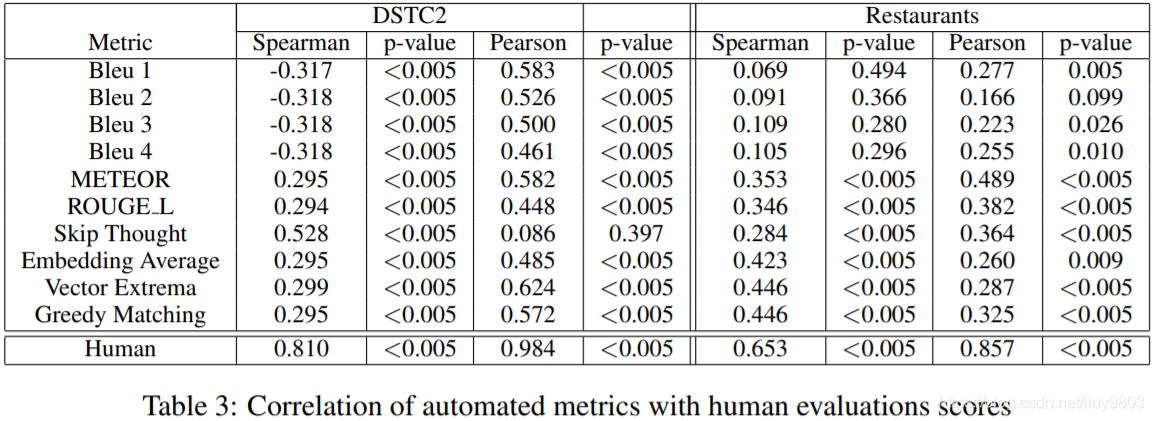
所有模型的自动评价指标得分都很高,这表明候选句和参考句之间有很多的单词重叠,并且这些数据集上的 NLG 任务可以用简单的模型来解决,如 LSTM 模型。表1显示 LSTM 的性能与基于单词重叠度量的 d-scLSTM 相当,这可以解释为 d-scLSTM 模型有更多的参数,并且可能在这些相对较小的数据集上出现过拟合问题。
hld-scLSTM 始终优于基于单词重叠度量的其他模型,这是由于 lexicalized slot values 考虑了输出附近生成的单词的语法关联,从而生成更高质量的句子。
人类评价收集
从每个数据集的测试集中随机选择20个对话行为,每个上下文含有5个句子:测试集中提供的1个gold 参考句和4个模型生成的候选句,随机打乱这些句子。邀请18位用户对合适程度给这100个句子打出1至5分的 Likert-type 评分,1分是最低分,意味着这个回答根本不合适,5分意味着这个句子非常合适。
计算 Cohen's kappa scores (Cohen's, 1960),以两个用户为一组,删除7个 kappa 值小于0.1的用户,kappa 值见表4。
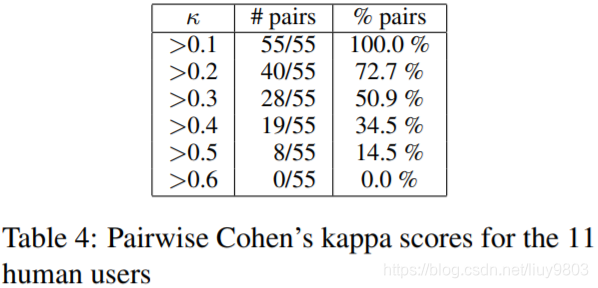
自动评价之间的相关性
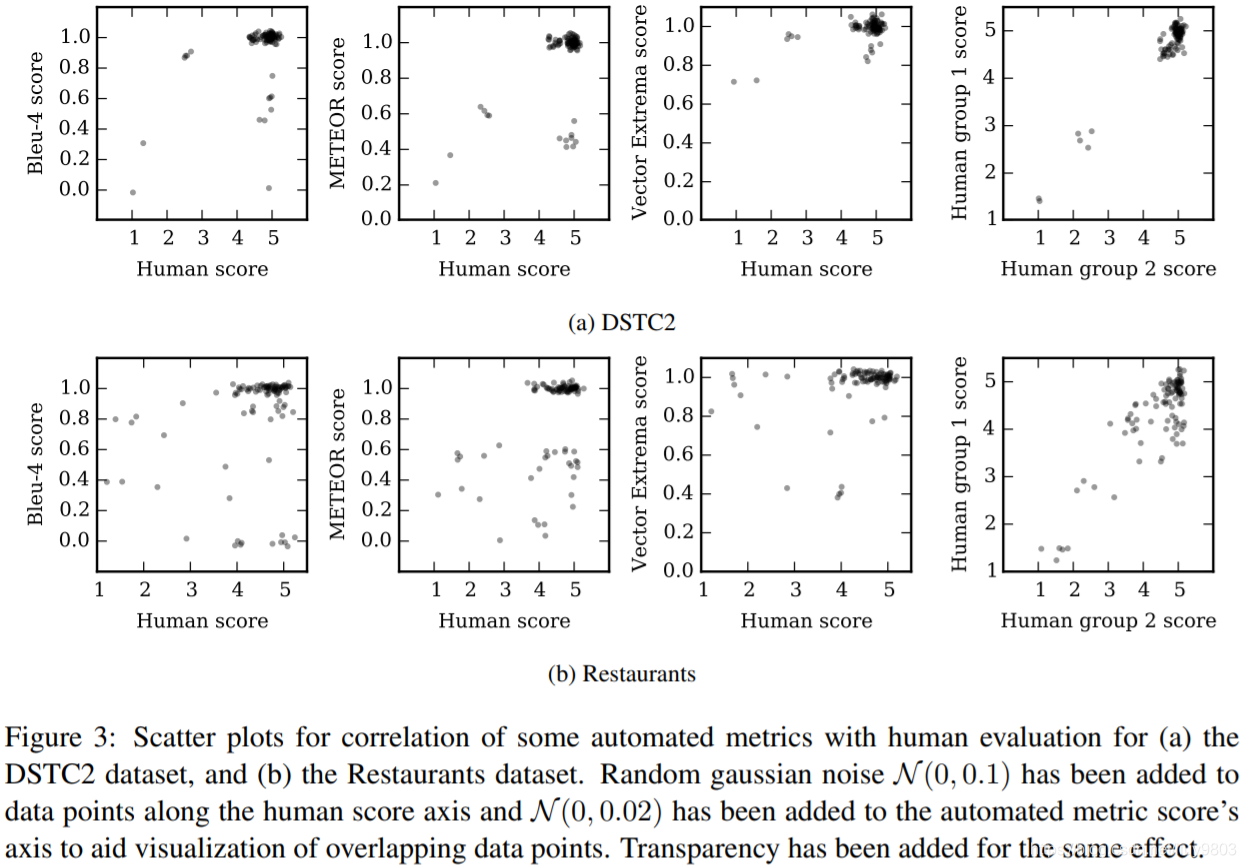
在大多数情况下,人类评分与其他人类评分的相关性最好。除了 BLEU-N 分数的 Spearman 相关性,可以看到这些任务型数据集的自动评价指标和人类评分之间存在正相关,这与非任务型对话形成对比。对于 BLEU-N 的负 Spearman 相关性的一种可能的解释是,DSTC2 数据集的每个上下文只有一个 gold 参考,而餐馆数据集的每个上下文有两个 gold 参考。多个参考将增加生成响应与一个参考单词重叠的可能性。图3为表3中一些度量的散点图,在高分的例子中,所有的指标都与人类有很好的相关性(人给出5分的最高分)。可用的任务型对话NLG任务的语料库不是很有挑战性,一个简单的基于 LSTM 的模型可以输出高质量的响应。
总结
在基于单词重叠的自动评估中,METEOR 始终与人类评估相关,在机器翻译任务中,METEOR 与人类评估也具有良好的相关性。虽然 METEOR 不依赖于词向量,但在计算候选词和参考词的对齐时,它包括同义词和释义的概念。因此建议使用 METEOR 进行任务型对话 NLG,而不是BLEU。
当提供多个引用时,基于单词重叠的度量与人类评估的相关性更好。
与随机抽样相比,使用 beam search 显著提高了生成句子的质量。
添加槽错误率惩罚项后,普通 LSTM 的性能与 d-scLSTM 一样好,这表明在这两个数据集上 sc-LSTM cell 引入的额外复杂性并没有提供显著的优势。
作者的模型在 DSTC2 和餐馆数据集上实现了自动评价的高性能,这表明这两个数据集对于 NLG 任务来说不是很有挑战性,应使用更大、更复杂的任务型对话数据集,如 Frames dataset (El Asri et al., 2017) 或 E2E NLG Challenge dataset (Novikova et al., 2016)。

















 4955
4955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









