







张量
在深度学习的实践中,我们通常使用向量或矩阵运算来提高计算效率。比如w1x1+w2x2+⋯+wNxN的计算可以用w⊤x来代替(其中w=[w1w2⋯wN]⊤,x=[x1x2⋯xN]⊤),这样可以充分利用计算机的并行计算能力,特别是利用GPU来实现高效矩阵运算。
在深度学习框架中,数据经常用张量(Tensor)的形式来存储。张量是矩阵的扩展与延伸,可以认为是高阶的矩阵。1阶张量为向量,2阶张量为矩阵。如果你对Numpy熟悉,那么张量是类似于Numpy的多维数组(ndarray)的概念,可以具有任意多的维度。
张量的大小可以用形状(shape)来描述。比如一个三维张量的形状是 [2,2,5],表示每一维(也称为轴(axis))的元素的数量,即第0轴上元素数量是2,第1轴上元素数量是2,第2轴上的元素数量为5。
下图为3种维度的张量可视化表示:
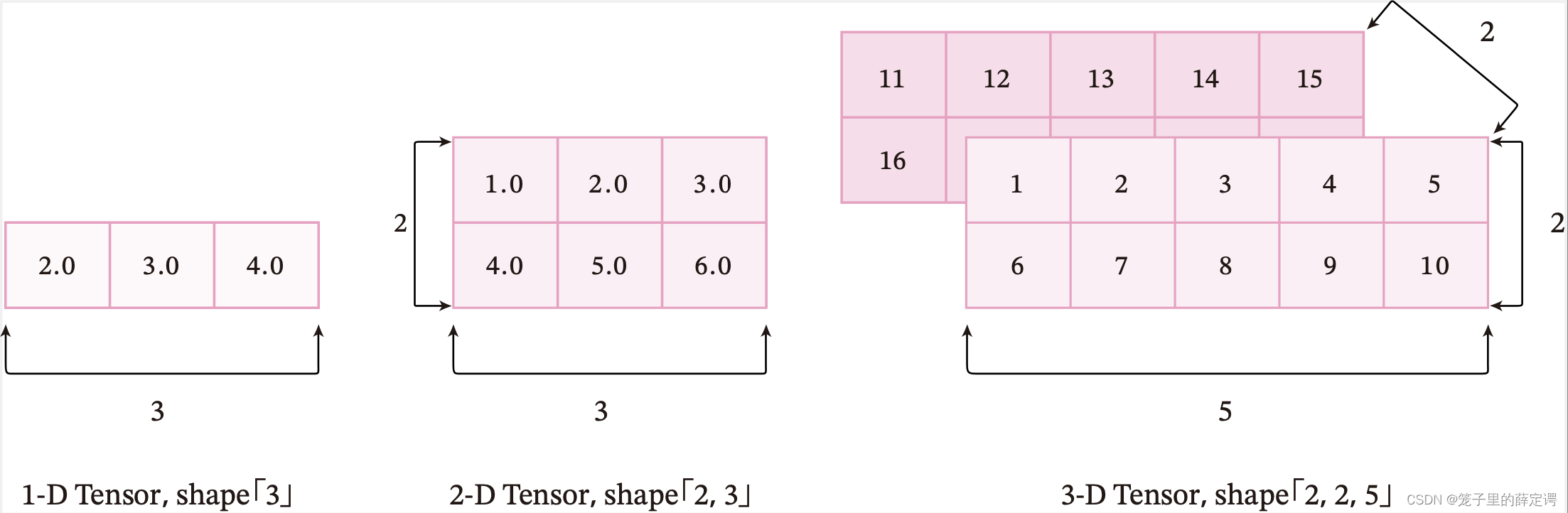
注意:这里的“维度”是“阶”的概念,和线性代数中向量的“维度”含义不同。
张量中元素的类型可以是布尔型数据、整数、浮点数或者复数,但同一张量中所有元素的数据类型均相同。因此我们可以给张量定义一个数据类型(dtype)来表示其元素的类型。
算子
深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称OP)。在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully-connected Layer, FC layer)中的权值求和过程,是一个算子。
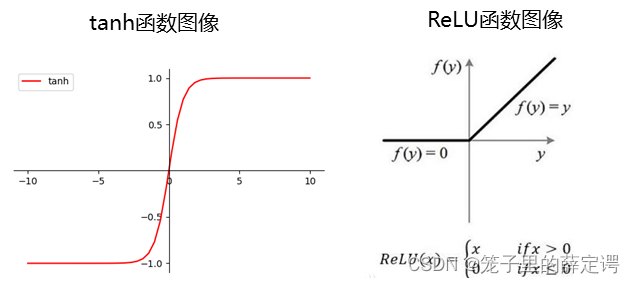
再例如:tanh、ReLU等,为在网络模型中被用做激活函数的算子。
- 算子的名称-:标识网络中的某个算子,同一网络中算子的名称需要保持唯一。
- 算子的类型:网络中每个算子根据算子类型进行实现逻辑的匹配,在一个网络中同一类型的算子可能存在多个。
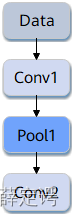
如下图所示,Conv1、Pool1、Conv2都是此网络中的算子名称,其中Conv1与Conv2算子的类型都为Convolution,表示分别做一次卷积计算。
二. 使用pytorch实现张量运算
1.2 张量
1.2.1 创建张量
1.2.1.1 指定数据创建张量
x = torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print(x)
运行结果

1.2.1.2 指定形状创建
x = torch.zeros((2, 3, 4))
print(x)
运行结果
1.2.1.3 指定区间创建
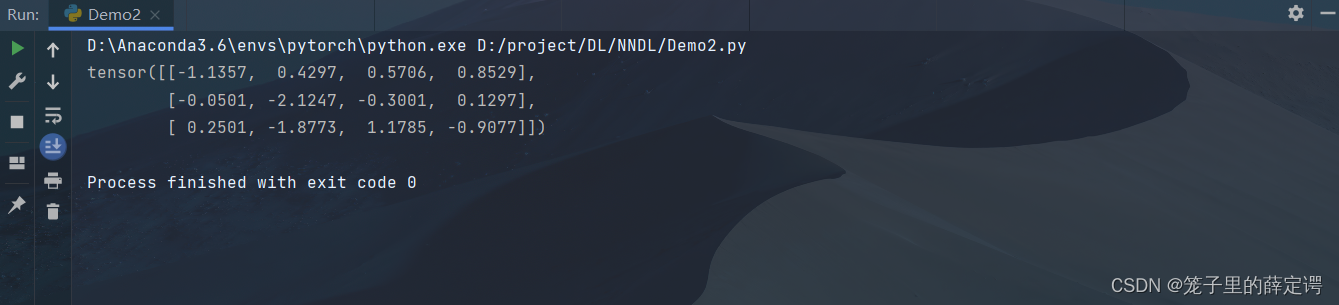
#产生一个形状为(3,4),符合标准正态分布的张量
x = torch.randn(3, 4)
print(x)
运行结果
1.2.2 张量的属性
1.2.2.1 张量的形状
x = torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
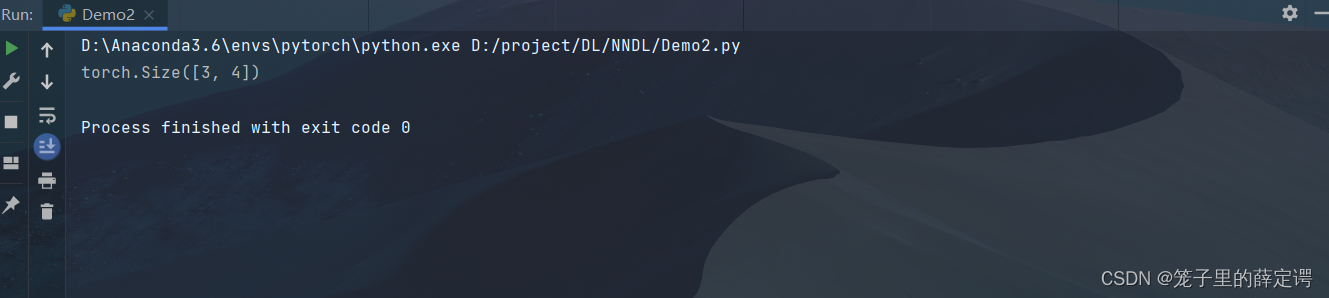
print(x.shape)
运行结果
1.2.2.2 形状的改变
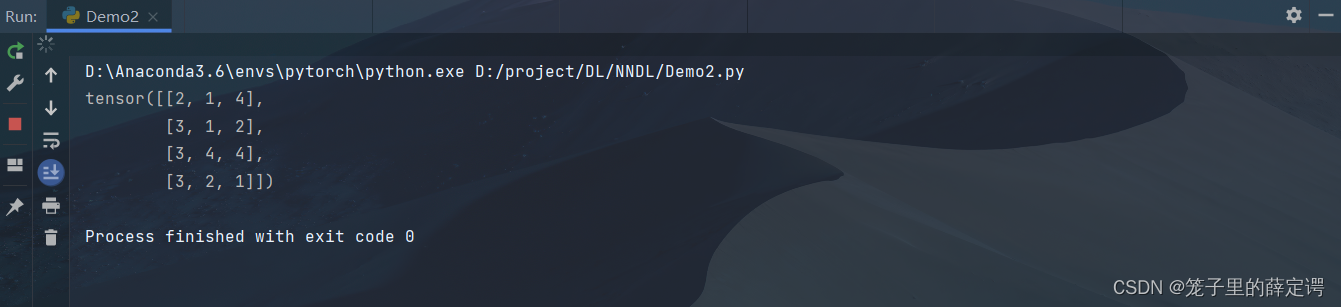
x = x.reshape(4, 3)
print(x)
运行结果
1.2.2.3 张量的数据类型
print(x.dtype)
print(x.type())
运行结果
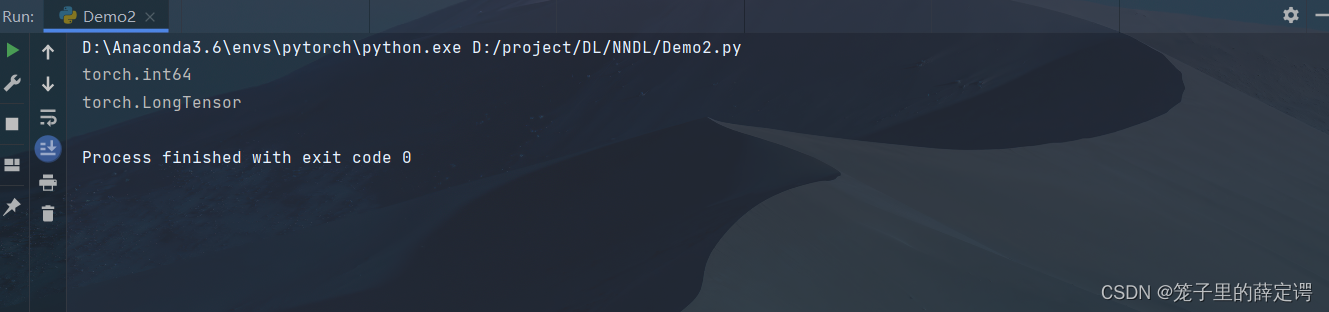
注:dtype是查看torch定义的数据类型
type不仅查看定义的数据类型,还可查看是CPU张量还是GPU张量
1.2.2.4 张量的设备位置
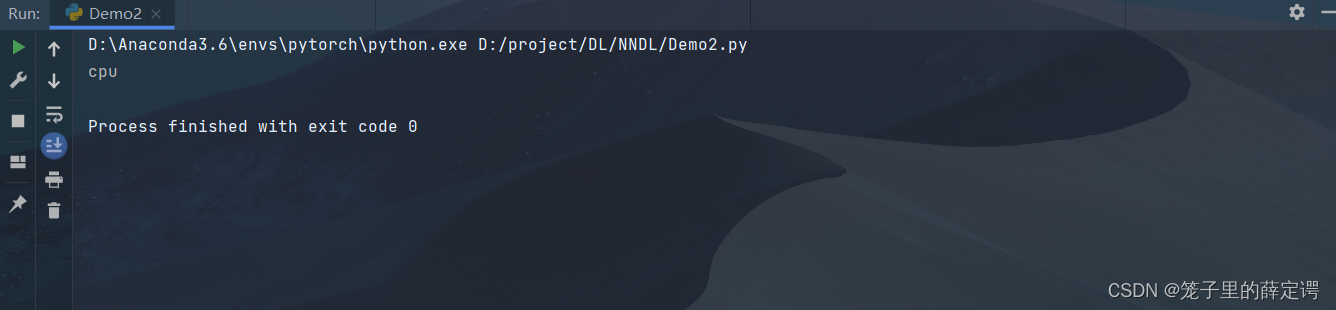
#可以指定设备,位于CPU还是GPU,若有多块GPU,还可指定位于哪块GPU上
print(x.device)
运行结果
1.2.3 张量与Numpy数组转换
x = x.numpy()
1.2.4 张量的访问
1.2.4.1 索引和切片
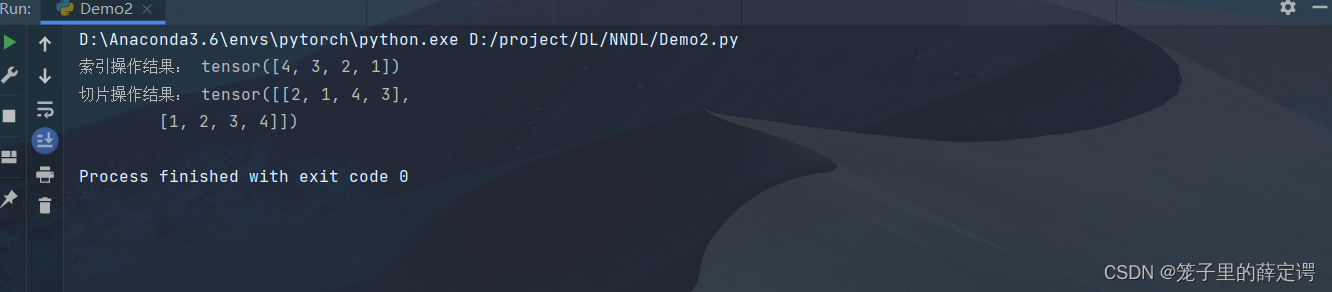
print("索引操作结果:", x[-1])
print("切片操作结果:", x[0:2])
运行结果
1.2.4.2 访问张量
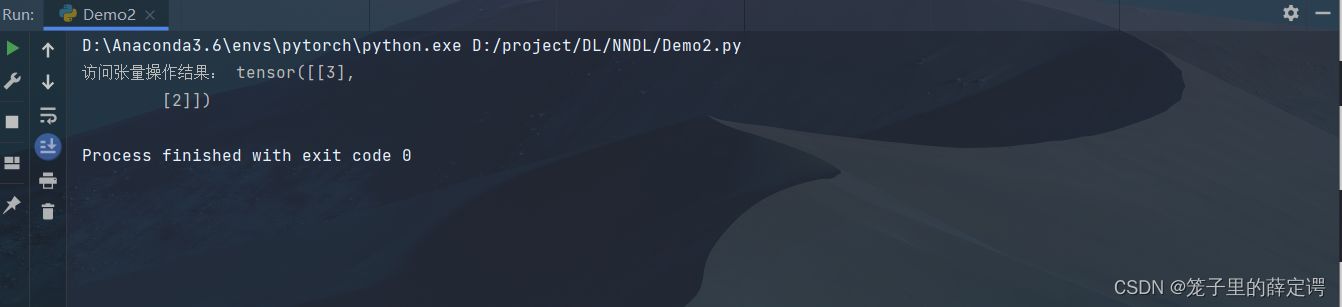
print("访问张量操作结果:",x[1:,2:3])
运行结果
1.2.4.3 修改张量
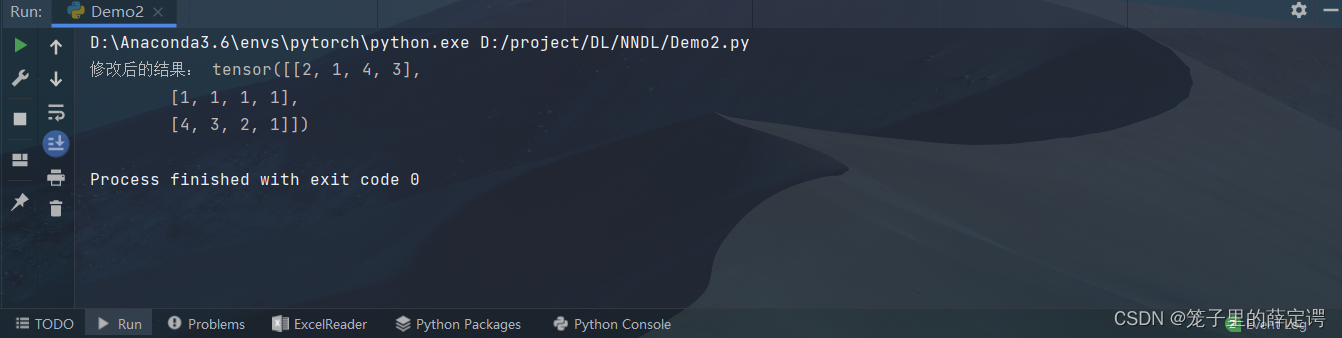
x[1] = 1
print("修改后的结果:", x)
运行结果
1.2.5 张量的运算
1.2.5.1 数学运算
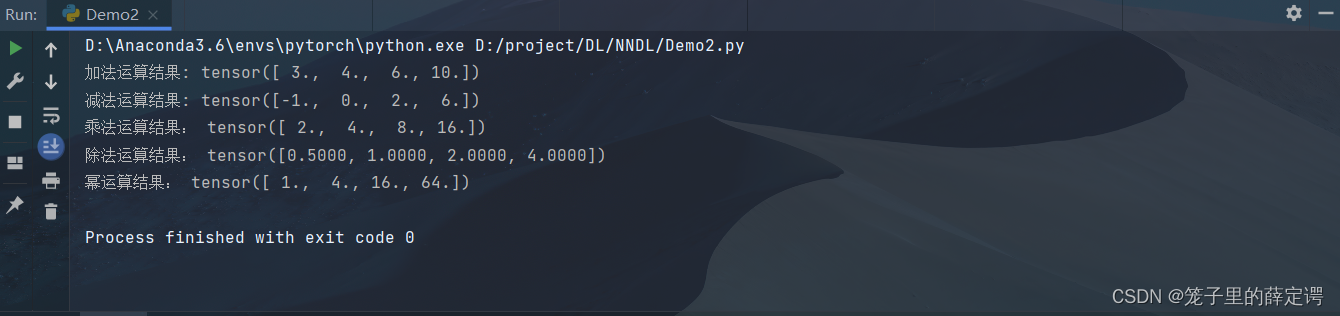
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
# 分别为加减乘除幂运算
print("加法运算结果:", x + y)
print("减法运算结果:", x - y)
print("乘法运算结果:", x * y)
print("除法运算结果:", x / y)
print("幂运算结果:", x ** y)
运行结果
1.2.5.2 逻辑运算
print("判断两个张量对应位置元素是否相同:", x == y)
运行结果

1.2.5.3 矩阵运算
X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print("按行连结结果", torch.cat((X, Y), dim=0))
print("按列连结结果:", torch.cat((X, Y), dim=1))
运行结果

1.2.5.4 广播机制
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
print("两个形状不匹配的张量相加结果:", a + b)
运行结果
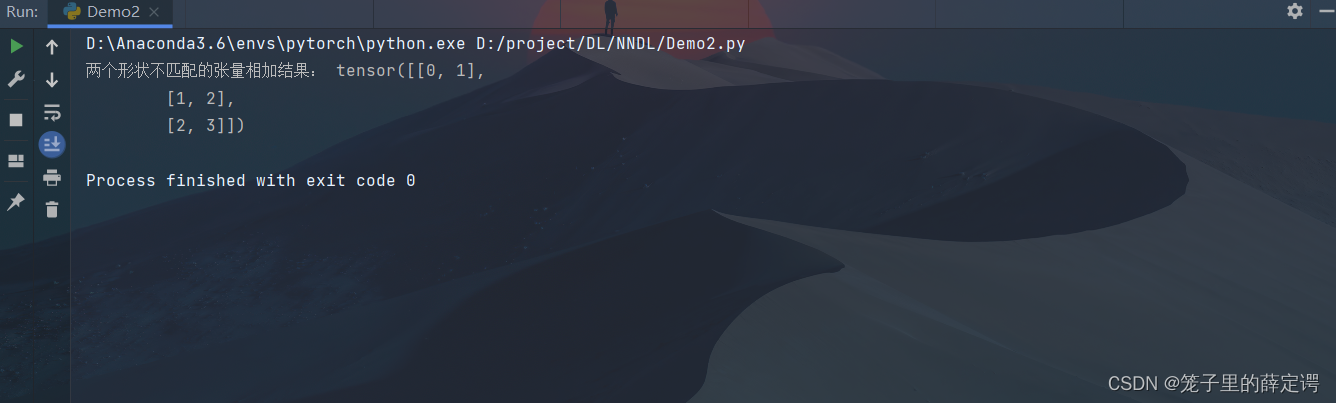 注:由于a和b分别是和矩阵,如果让它们相加,它们的形状不匹配。 我们将两个矩阵广播为一个更大的矩阵,如上所示:矩阵a将复制列, 矩阵b将复制行,然后再按元素相加。
注:由于a和b分别是和矩阵,如果让它们相加,它们的形状不匹配。 我们将两个矩阵广播为一个更大的矩阵,如上所示:矩阵a将复制列, 矩阵b将复制行,然后再按元素相加。
三. 使用pytorch实现数据预处理
1.读取数据集 house_tiny.csv、boston_house_prices.csv、Iris.csv
import pandas as pd
data_file1 = r"D:\project\DL\NNDL\boston_house_prices.csv"
data_file2 = r"D:\project\DL\NNDL\house_tiny.csv"
data_file3 = r"D:\project\DL\NNDL\Iris.csv"
data1 = pd.read_csv(data_file1)
data2 = pd.read_csv(data_file2)
data3 = pd.read_csv(data_file3)
# print(data1)
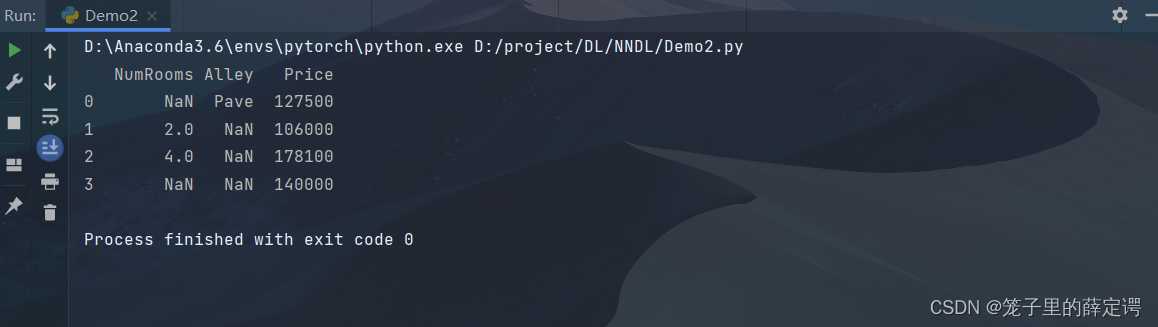
print(data2)
# print(data3)
运行结果
 torch中包含了许多的数据集,所以也可直接通过torch进行下载读取,代码如下(CIFAR10为例):
torch中包含了许多的数据集,所以也可直接通过torch进行下载读取,代码如下(CIFAR10为例):
import torchvision.datasets
from torchvision import transforms
# 定义图像变换,可以通过Compose函数被连接起来
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))]
)
# 划分训练集、测试集
trainset = torchvision.datasets.CIFAR10(root="D:\project\DL\cifar10", train=True, download=True,
transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=36,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root="D:\project\DL\cifar10", train=False, download=True,
transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=36,
shuffle=True, num_workers=0)
注:若对应文件夹已有数据集,即便download=True也不会进行下载
2.处理缺失值
#将house_tiny.csv中的NAN缺失值设置为对应列的均值
inputs, outputs = data2.iloc[:, 0:5],data2.iloc[:, 5]
inputs = inputs.fillna(inputs.mean())
print(inputs)
运行结果
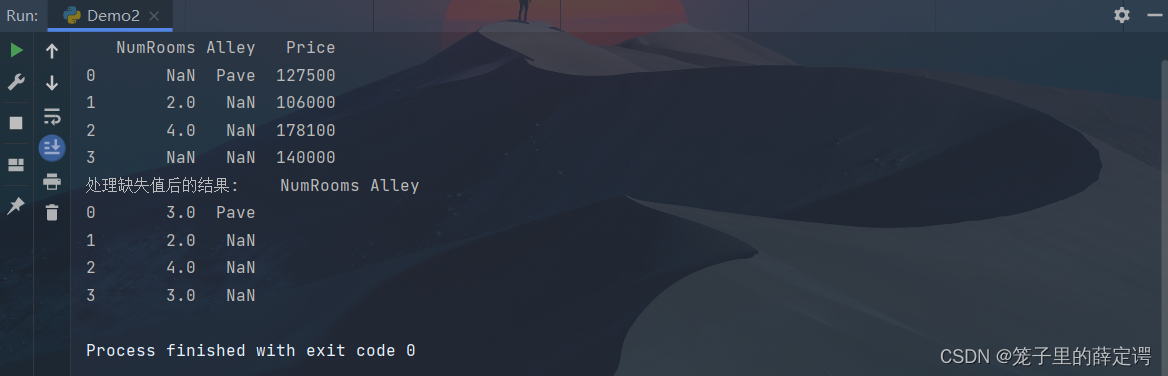 注:“NaN”项代表缺失值。 为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。 在这里,我采用的是插值法。
注:“NaN”项代表缺失值。 为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。 在这里,我采用的是插值法。
.3. 转换为张量格式
# 将inputs和outputs中的所有条目都转换为Tensor格式,进而可以调用上述学到的方法
X, Y = torch.Tensor(inputs.values), torch.Tensor(outputs.values)
print(X.dtype)
print(Y.dtype)
运行结果
 注:将读取的数据集转换为Tensor类型必须保证inputs和outputs中的所有条目为数值类型,要不然会报如上的错误。
注:将读取的数据集转换为Tensor类型必须保证inputs和outputs中的所有条目为数值类型,要不然会报如上的错误。
下面是我将数据集换成Iris前四列运行结果:

总结
这次实验也挺基础,做下来倒是没卡壳,就是对PaddlePaddle框架不太熟悉,只会用Pytorch。只掌握一门框架还是不行,以后实验课会跟着邱锡鹏老师多读些PaddlePaddle框架的代码。















 1641
1641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









