







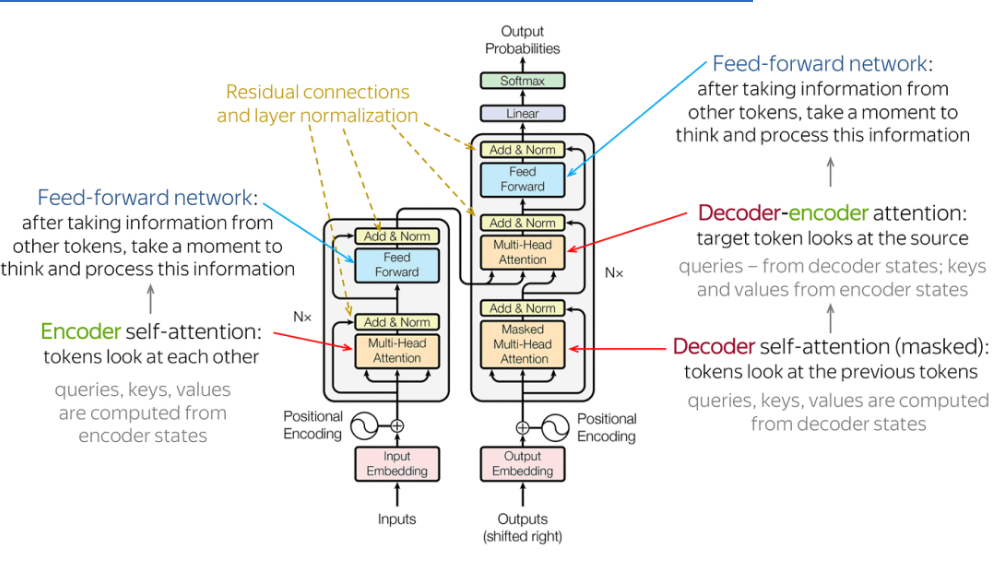
关于Transformer想信大家并不陌生,网上文章地相关描述大致如下:
Transformer:一种基于自注意力机制的神经网络结构,通过并行计算和多层特征抽取,有效解决了长序列依赖问题,实现了在自然语言处理等领域的突破。
Transformer架构:主要由输入部分(输入输出嵌入与位置编码)、多层编码器、多层解码器以及输出部分(输出线性层与Softmax)四大部分组成。
很显然上面的解释,对于初学者是极其不友好的,一看一个不吱声!我相信90%的同学只是想了解Transformer工作的基础流程,而并不想了解其中的实现细节,那么今天我就用一个生动的实例满足大家的需求!
我是沈阳人,我想向外地的老铁们来介绍一下我的家乡沈阳,那么Transformer生成沈阳介绍的流程大致如下:
首先我们把Transformer想象成一间智能厨房
- 厨师(AI模型)看过无数本菜谱(训练数据)
- 厨房里有一群配合默契的帮厨(多头注意力机制)
- 每个帮厨都盯着所有食材(输入文字),但各自关注不同部分
然后要做"沈阳介绍"这道菜时,按照下面的步骤进行
- 理解订单:拆解"沈阳"、"家乡"、"介绍"等关键词
- 食材准备:从记忆库调取相关信息
- 历史:清朝发祥地、故宫
- 地标:彩电塔、中街
- 美食:老边饺子、鸡架
- 季节:四季分明
3. 分层加工:
- 第一层帮厨:把"故宫"和"北京故宫"对比
- 第二层帮厨:把"鸡架"和城市夜生活关联
- 第三层帮厨:串联工业历史和现代转型
4.摆盘上菜:
- 按照"总-分-总"结构:
- 开头点题 → 分段详述 → 抒情结尾
另外还要补充一些特殊能力:
- 同时看全桌调料(并行处理):不用像老式RNN那样一个个字处理
- 自动加重点(自注意力):说到"老四季抻面"时,自动关联鸡架文化
- 防跑题机制(位置编码):确保先说地理位置再说历史,顺序合理
实际生成时,就像有个看不见的沈阳导游在你大脑里:
- 先画思维导图(生成大纲)
- 给每个景点配小故事(细节填充)
- 最后用"欢迎来沈阳"收尾(情感升华)
整个过程比人写作文快n倍,但会偶尔出现"沈阳靠海"这种错误(因为学习数据有噪声),这正是人类需要校对的原因。
我的每一篇文章都希望帮助读者解决实际工作中遇到的问题!如果文章帮到了您,劳烦点赞、收藏、转发!您的鼓励是我不断更新文章最大的动力!


















 2162
2162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











