







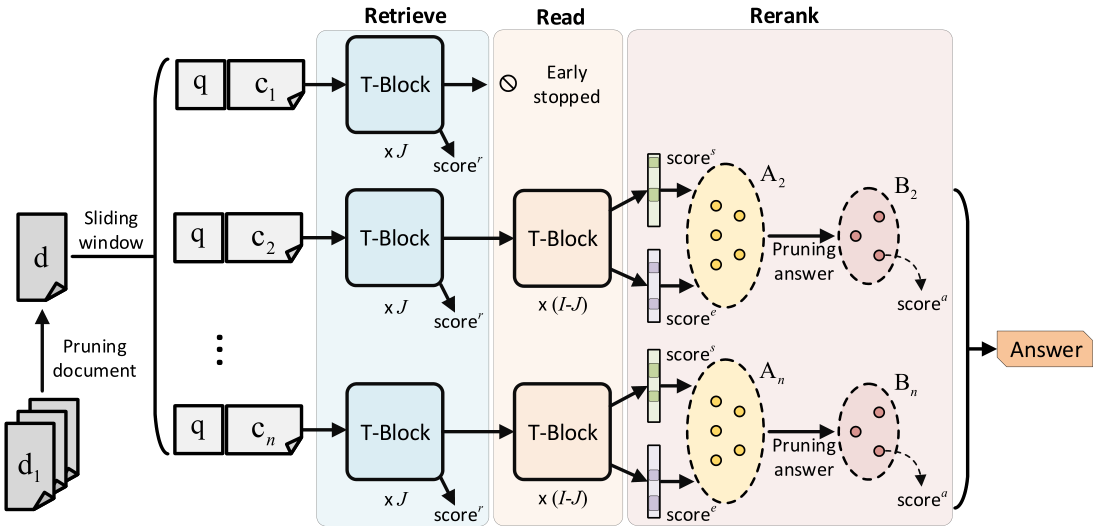
RARR(Retrieve-Read-Rerank) 和 RAG(Retrieval-Augmented Generation) 是两种不同的检索增强生成技术,核心差异在于流程设计、优化目标及适用场景。以下从多个维度对比两者的区别:
1. 流程架构与核心步骤
RAG(检索增强生成)
-
流程:
-
检索(Retrieve):从外部知识库中检索与查询相关的文档或文本片段。
-
生成(Generate):将检索到的内容与原始查询拼接,输入大语言模型(LLM)生成最终答案。
-
-
特点:
-
强调检索与生成的直接结合,无需中间处理。
-
依赖检索质量,若检索结果不相关或碎片化,生成答案可能不准确或冗余。
-
RARR(检索-阅读-重排序)
-
流程:
-
检索(Retrieve):初步获取大量相关文档。
-
阅读(Read):对检索结果进行深度解析,提取关键信息或实体关系。
-
重排序(Rerank):通过算法(如语义相似度、上下文关联度)对结果重新排序,筛选最相关的片段。
-
生成(Generate):将优化后的内容输入LLM生成答案。
-
-
特点:
-
通过“阅读”和“重排序”优化检索结果的准确性和上下文连贯性。
-
适用于复杂查询,减少生成中的冗余或错误。
-
2. 技术目标与优化方向
| 维度 | RAG | RARR |
|---|---|---|
| 核心目标 | 快速整合外部知识生成答案 | 提升检索结果质量后再生成答案 |
| 优化重点 | 检索效率与生成模型能力 | 中间阶段的精准筛选与排序 |
| 适用场景 | 事实性问答、简单查询 | 复杂推理、多跳关联查询 |
-
RAG的局限性:
-
若检索结果包含噪声或不相关文本块,生成答案可能受干扰。
-
缺乏对检索结果的深度分析,难以处理需多步推理的问题。
-
-
RARR的优势:
-
通过“阅读”步骤解析语义,识别实体关系(类似知识图谱的局部构建)。
-
重排序可结合多指标(如相关性、覆盖度)优化上下文,减少生成中的幻觉问题。
-
3. 实现复杂度与性能
-
RAG:
-
复杂度低:流程简单,适合快速部署。
-
性能瓶颈:检索质量直接影响生成结果,若知识库规模大或查询复杂,可能需牺牲精度换取速度。
-
-
RARR:
-
复杂度高:需额外设计阅读解析模型(如实体识别)和重排序算法(如NDCG、MRR)。
-
性能优势:在复杂查询中显著提升答案质量,但计算成本和响应时间可能增加。
-
4. 典型应用场景
-
RAG:
-
客服问答:快速回答用户关于产品发布时间、功能参数等事实性问题。
-
实时信息整合:结合新闻或动态数据库生成最新资讯。
-
-
RARR:
-
专业领域分析:如医疗诊断需综合患者症状、病史和药物关系。
-
多跳推理任务:例如“某公司CEO的母校有哪些校友获得过行业奖项?”。
-
5. 技术演进与融合趋势
-
RAG的扩展:
-
结合知识图谱(GraphRAG):利用图结构增强实体关系理解,解决传统RAG的碎片化问题。
-
动态检索(如FLARE):交替执行检索与生成,迭代优化答案。
-
-
RARR的优化:
-
轻量化设计(如LightRAG):通过增量更新和高效索引降低计算开销。
-
混合架构:在RARR中引入RAG的快速检索能力,平衡效率与精度。
-
总结
| 技术 | 核心差异 | 适用场景 |
|---|---|---|
| RAG | 快速检索+直接生成,依赖检索质量 | 简单事实性问答、实时性要求高 |
| RARR | 检索后深度处理+重排序优化,提升答案精准度 | 复杂推理、多跳关联查询 |
选择建议:
-
若需快速响应且查询简单,优先选择RAG。
-
若问题涉及深层语义关联或需高精度答案,RARR或结合知识图谱的GraphRAG更优。


















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











