










谷歌Google于12月初正式发布了Gemini大模型,与GPT3.5、GPT4达到了相近效果。除了文本生成之外,Gemini还支持输入图片并进行理解,下文将详细介绍调用方式。当前阶段,Gemini应该有300刀的免费额度,有效期为3个月。每分钟调用次数为60次,而OpenAI免费GPT3.5的限制为每分钟3次。文末将给出Gemini key及其模型技术交流群。
1 GeminiPro
GeminiPro模型的输入文本,输出也为文本。详细如下所示。
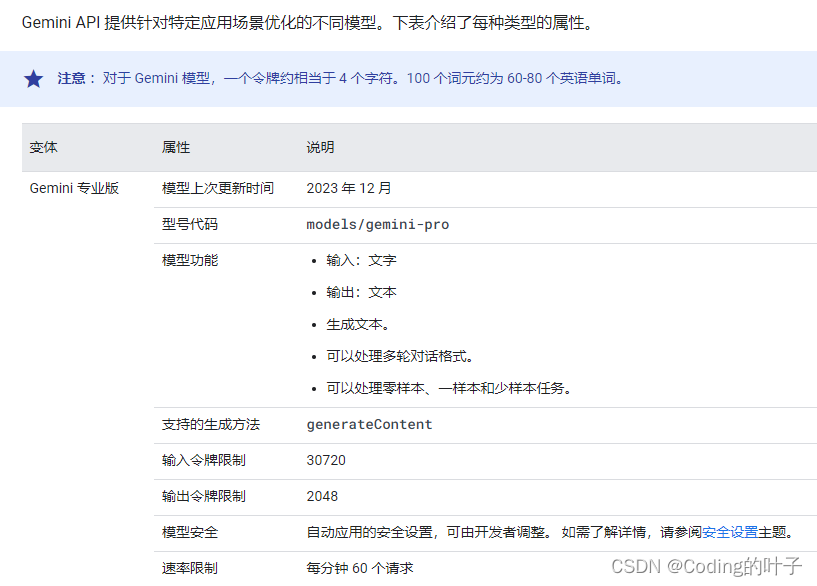
我们可以看到输入支持将近32K个token,并且一个token大约相当于4个字符。
1.1 非stream输出
示例程序如下所示。
import json
import requests
# 非stream方式
def test_gemini_no_stream(apikey, text):
url = f'https://generativelanguage.googleapis.com/v1beta/models/gemini-pro:generateContent?key={apikey}'
headers = {'Content-Type': 'application/json'}
data = {
'contents': [
{
'parts': [
{
'text': text
}
]
}
]
}
response = requests.post(url, headers=headers, data=json.dumps(data))
# print(response.json())
print(response.json()['candidates'][0]['content']['parts'][0]['text'])
if __name__ == '__main__':
apikey = 'xxx'
text = 'say hello'
print('test_gemini_no_stream(apikey, text):')
test_gemini_no_stream(apikey, text)输出结果为:
test_gemini_no_stream(apikey, text):
Hello there! How are you doing today?1.2 google-generativeai非stream输出
上面直接通过requests访问api,这里将使用Google的Python库进行调用。首先需要通过下面命令安装google-generativeai。
pip install -U google-generativeai注意事项:Python版本需至少为3.9,google-generativeai版本为0.3.1。
示例程序如下所示。
import google.generativeai as genai
def genai_no_stream(apikey, text):
genai.configure(api_key=apikey)
# 支持的模型列表
# for m in genai.list_models():
# if 'generateContent' in m.supported_generation_methods:
# print(m.name)
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("how are you")
print(response.text)输出结果为:
genai_no_stream(apikey, text):
I am a large language model, trained by Google.1.3 google-generativeai stream输出
流式输出只需将generate_content的stream设置为True即可,示例程序如下所示。
# text = '请介绍人工智能发展历史'
def genai_stream(apikey, text):
genai.configure(api_key=apikey)
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content(text, stream=True)
for chunk in response:
print(chunk.text, end='', flush=True)输出结果如下
**人工智能发展史**
* **1940年代:**诞生
* 1943年,沃伦·麦卡洛克和沃尔特·皮茨提出神经网络模型。
* 1949年,艾伦·图灵提出图灵检测,用以判断机器是否具有智能。
* **1950年代:**发展
* 1950年,艾伦·纽厄尔和克利福德·肖提出逻辑理论家程序,该程序能够证明定理。
* 1952年,阿瑟·塞缪尔发明会下棋的程序。
* 1956年,约翰·麦卡锡在达特茅斯学院举办了世界上第一次人工智能研讨会,人工智能一词正式诞生。
* **1960年代:**突破
* 1965年,拉斐尔·内尔逊提出通用问题求解器,该程序能够解决各种各样的问题。
* 1966年,弗兰克·罗森布拉特发明感知机,该机器能够识别手写数字。
* 1969年,马文·明斯基和西摩尔·帕帕特出版《感知机》,该书对感知机进行了详细的阐述。
* **1970年代:**停滞
* 1973年,马文·明斯基和西摩尔·帕帕特出版《人工智能框架》,该书对人工智能进行了全面的概述。
* 1974年,罗杰·香克斯和罗伯特·阿贝尔森提出脚本理论,该理论认为人们的行为是基于存储在记忆中的脚本。
* 1979年,爱德华·菲根鲍姆和朱丽叶·费根鲍姆出版《人工智能专家系统》,该书对专家系统进行了详细的阐述。
* **1980年代:**复兴
* 1980年,约翰·霍普菲尔德提出霍普菲尔德网络,该网络能够存储和检索信息。
* 1982年,特伦斯·塞诺夫斯基和杰弗里· Hinton提出多层感知器,该网络能够学习和识别模式。
* 1986年,戴维·鲁梅尔哈特和杰弗里· Hinton出版《并行分布式处理:探索大脑的计算》,该书对并行分布式处理进行了详细的阐述。
* **1990年代:**爆发
* 1997年,IBM的深蓝战胜了世界象棋冠军加里·卡斯帕罗夫。
* 1997年,杨立昆等人提出卷积神经网络,该网络能够识别图像。
* 1998年,吴恩达等人提出长短期记忆网络,该网络能够学习和记忆长时间序列的数据。
* **2000年代:**深化
* 2006年,杰弗里· Hinton等人提出深度信念网络,该网络能够学习和识别复杂的数据。
* 2012年,安德鲁·恩等人提出卷积神经网络,该网络能够识别图像。
* 2015年,谷歌的阿尔法狗战胜了世界围棋冠军李世石。
* **2010年代:**应用
* 2016年,谷歌的阿尔法狗战胜了世界象棋冠军李世石。
* 2017年,百度的人工智能围棋程序AlphaGo Zero战胜了阿尔法狗。
* 2018年,谷歌的 Duplex 人工智能助手能够与人类进行自然的对话。
* 2019年,OpenAI 的 GPT-3 人工智能语言模型能够生成类似人类的文本。人工智能的发展日新月异,未来人工智能将对人类社会产生深远的影响。
可以看到,其输出默认为MarkDown格式。
1.4 chat模式
使用chat模式可以自动获取上下文。示例程序如下所示。
def genai_chat(apikey, text):
genai.configure(api_key=apikey)
# 历史消息,必须为偶数
messages = [
{'role':'user',
'parts': ["请将我接下来的任何输入都直接翻译成中文即可。"]},
{'role':'model',
'parts': ["好的。我接下来将任何输入都直接翻译成中文"]}
]
model = genai.GenerativeModel('gemini-pro')
chat = model.start_chat(history=messages)
response = chat.send_message(text)
print(response.text)输出结果如下:
电脑就像一个聪明的机器人,可以帮助我们做很多事情。它里面有很多小零件,比如处理器、内存、硬盘、显卡等等。处理器就像电脑的大脑,负责处理信息和计算。内存就像电脑的短期记忆,可以临时存储信息。硬盘就像电脑的长期记忆,可以永久存储信息。显卡负责处理图形和图像。
当我们使用电脑时,我们通过键盘、鼠标或触摸屏等输入设备将信息输入到电脑中。电脑会将这些信息发送给处理器,由处理器进行处理和计算。处理后的结果会存储在内存中,或者永久存储在硬盘中。如果我们想看到处理结果,电脑会将它们发送给显示器或打印机等输出设备,这样我们就可以看到或打印出结果了。
电脑还可以连接到互联网,这样我们就可以与世界各地的其他人交流信息和数据。虽然上述程序可以加入历史消息,但是并不能模拟出OpenAI GPT api的system参数或GPTs功能。Gemini没有system这个角色。在获取上下文时,messages里的model信息正常情况下是由Gemini生成的。这里想人为进行设计的,似乎达不到想要的功能,但并不是说chat模式有问题,而是历史消息中的model信息没有正确设置为Gemini生成的内容。正常示例程序如下所示。
model = genai.GenerativeModel('gemini-pro')
chat = model.start_chat(history=[])
response = chat.send_message("In one sentence, explain how a computer works to a young child.")
print(chat.history)
response = chat.send_message("Okay, how about a more detailed explanation to a high schooler?", stream=True)
for chunk in response:
print(chunk.text)
print("_"*80)1.5 多轮对话
示例程序如下:
def genai_multi_turn(apikey, text):
genai.configure(api_key=apikey)
model = genai.GenerativeModel('gemini-pro')
messages = [
{'role':'user',
'parts': ["请将我接下来的任何输入都直接翻译成中文即可。"]},
{'role':'model',
'parts': ["好的。我接下来将任何输入都直接翻译成中文"]},
{'role':'user',
'parts': [text]}
]
response = model.generate_content(messages)
print(response.text)输出结果如下:
电脑就像一个聪明的机器人,它能帮助我们做很多事情。电脑里面有很多零件,就像人有大脑、心脏、手脚一样。电脑的大脑叫中央处理器,它负责处理信息。电脑的心脏叫内存,它负责存储信息。电脑的手脚叫输入输出设备,它们负责与我们交流。
当我们使用电脑时,我们会通过键盘或鼠标把信息输入到电脑里。电脑的大脑会处理这些信息,然后把结果通过显示器或打印机等输出设备显示出来。
电脑还可以存储信息,就像我们的大脑可以记住事情一样。我们可以把照片、音乐、文件等信息存储在电脑里,以后需要的时候随时可以调出来。
电脑还可以帮助我们做很多有趣的事情,比如玩游戏、看电影、听音乐等。它就像一个神奇的工具,可以帮助我们学习、工作和娱乐。效果同上文的chat模式,正确用法为:
model = genai.GenerativeModel('gemini-pro')
messages = [
{'role':'user',
'parts': ["Briefly explain how a computer works to a young child."]}
]
response = model.generate_content(messages)
messages.append({'role':'model',
'parts':[response.text]})
messages.append({'role':'user',
'parts':["Okay, how about a more detailed explanation to a high school student?"]})
response = model.generate_content(messages)
print(response.text)1.6 system或GPTs
以上通过多轮对话来实现system或GPTs并没有获得成功,最好直接指定任务,如下所示。
def genai_system(apikey, text):
genai.configure(api_key=apikey)
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("请将下面内容翻译成中文。\nBriefly explain how a computer works to a young child.")
print(response.text)输出结果如下:
genai_system(apikey, text):
简单地向一个孩子解释电脑的工作原理。2 Gemini Pro Vision
Gemini Pro Vision支持对图片的理解,详细参数如下所示。

下载示例图片:
curl -o image.jpg https://t0.gstatic.com/licensed-image?q=tbn:ANd9GcQ_Kevbk21QBRy-PgB4kQpS79brbmmEG7m3VOTShAn4PecDU5H5UxrJxE3Dw1JiaG17V88QIol19-3TM2wCHw
示例程序如下所示:
def gemini_pro_vision(apikey, text, image_path):
import PIL.Image
genai.configure(api_key=apikey)
model = genai.GenerativeModel('gemini-pro-vision')
img = PIL.Image.open(image_path)
response = model.generate_content([text, img], stream=True)
response.resolve()
print(response.text)输出如下所示。
今天分享一道超级简单的快手便当,上班族和学生党都非常适合哦!
所需食材:鸡胸肉、西兰花、胡萝卜、米饭。
制作步骤:
1. 鸡胸肉切小块,用料酒、生抽、黑胡椒粉腌制15分钟。
2. 西兰花和胡萝卜焯水备用。
3. 米饭蒸熟。
4. 锅中热油,放入腌制好的鸡胸肉翻炒至变色。
5. 加入西兰花和胡萝卜,翻炒均匀。
6. 加入米饭,翻炒均匀即可。
这道快手便当就做好啦,是不是超级简单?赶紧动手试试吧!图片的理解(或者图片内容提取)可以与GeminiPro或者GPT进行结合实现更多应用。
3 模型配置
Gemini也有与常规LLM或GPT相类似的配置方式,示例程序如下所示。
def genai_config(apikey, text):
genai.configure(api_key=apikey)
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content(
text,
generation_config=genai.types.GenerationConfig(
# Only one candidate for now.
candidate_count=1,
stop_sequences=['x'],
max_output_tokens=20,
temperature=1.0)
)
print(response.text)4 全部完整示例程序
import json
import requests
# 非stream方式
def test_gemini_no_stream(apikey, text):
url = f'https://generativelanguage.googleapis.com/v1beta/models/gemini-pro:generateContent?key={apikey}'
headers = {'Content-Type': 'application/json'}
data = {
'contents': [
{
'parts': [
{
'text': text
}
]
}
]
}
response = requests.post(url, headers=headers, data=json.dumps(data))
# print(response.json())
print(response.json()['candidates'][0]['content']['parts'][0]['text'])
import google.generativeai as genai
def genai_no_stream(apikey, text):
genai.configure(api_key=apikey)
# 支持的模型列表
# for m in genai.list_models():
# if 'generateContent' in m.supported_generation_methods:
# print(m.name)
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("how are you")
print(response.text)
def genai_stream(apikey, text):
genai.configure(api_key=apikey)
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content(text, stream=True)
for chunk in response:
print(chunk.text, end='', flush=True)
def genai_chat(apikey, text):
genai.configure(api_key=apikey)
# 历史消息,必须为偶数
messages = [
{'role':'user',
'parts': ["请将我接下来的任何输入都直接翻译成中文即可。"]},
{'role':'model',
'parts': ["好的。我接下来将任何输入都直接翻译成中文"]}
]
model = genai.GenerativeModel('gemini-pro')
chat = model.start_chat(history=messages)
response = chat.send_message(text)
print(response.text)
def genai_multi_turn(apikey, text):
genai.configure(api_key=apikey)
model = genai.GenerativeModel('gemini-pro')
messages = [
{'role':'user',
'parts': ["请将我接下来的任何输入都直接翻译成中文即可。"]},
{'role':'model',
'parts': ["好的。我接下来将任何输入都直接翻译成中文"]},
{'role':'user',
'parts': [text]}
]
response = model.generate_content(messages)
print(response.text)
def genai_system(apikey, text):
genai.configure(api_key=apikey)
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("请将下面内容翻译成中文。\nBriefly explain how a computer works to a young child.")
print(response.text)
def gemini_pro_vision(apikey, text, image_path):
import PIL.Image
genai.configure(api_key=apikey)
model = genai.GenerativeModel('gemini-pro-vision')
img = PIL.Image.open(image_path)
response = model.generate_content([text, img], stream=True)
response.resolve()
print(response.text)
def genai_config(apikey, text):
genai.configure(api_key=apikey)
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content(
text,
generation_config=genai.types.GenerationConfig(
# Only one candidate for now.
candidate_count=1,
stop_sequences=['x'],
max_output_tokens=20,
temperature=1.0)
)
print(response.text)
if __name__ == '__main__':
apikey = 'xxx'
text = 'say hello'
# print('test_gemini_no_stream(apikey, text):')
# test_gemini_no_stream(apikey, text)
# print('genai_no_stream(apikey, text):')
# genai_no_stream(apikey, text)
# print('genai_stream(apikey, text):')
# genai_stream(apikey, text='请介绍人工智能发展历史')
# print('genai_chat(apikey, text):')
# genai_chat(apikey, text='Briefly explain how a computer works to a young child.')
# print('genai_chat(apikey, text):')
# genai_multi_turn(apikey, text='Briefly explain how a computer works to a young child.')
# print('genai_system(apikey, text):')
# genai_system(apikey, text='请将下面内容翻译成中文。\nBriefly explain how a computer works to a young child.')
# print('gemini-pro-vision(apikey, text, image_path):')
# gemini_pro_vision(apikey, text='请基于图片中内容写一篇小红书文案。', image_path='image.jpg')
print('genai_config(apikey, text)')
genai_config(apikey, text='say hello.')5 技术知识交流



















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











