







 本教程详细介绍了如何使用PyTorch Geometric库构建和训练一个针对图分类任务的3层ConvGCN+3层GraphConv模型。内容涵盖数据集下载、统计、划分,模型定义,训练过程,以及使用GraphConv提高模型性能。
本教程详细介绍了如何使用PyTorch Geometric库构建和训练一个针对图分类任务的3层ConvGCN+3层GraphConv模型。内容涵盖数据集下载、统计、划分,模型定义,训练过程,以及使用GraphConv提高模型性能。
目录
简介
在本教程中,我们将深入了解如何将图神经网络(GNNs)应用到图分类任务中。
- 图分类是指对给定的图数据集,基于图的一些结构属性,对整个图(而不是节点)进行分类的问题。
- 这里,我们想要嵌入整个图,我们想要以这样一种方式嵌入这些图,使它们在给定任务的情况下线性可分。
- 图分类最常见的任务是分子性质预测,其中分子用图表示,任务可能是推断一个分子是否抑制了HIV病毒的复制。
- 多特蒙德大学收集了大量不同的图分类数据集,称为TUDatasset,也可以通过
torch_geometric.datasets.TUDataset访问。 - 测试一个较小的MUTAG数据集
- 和以往代码不同的是需要引入一个新的读出层包 from torch_geometric.nn import global_mean_pool
- 和以往代码不同的是需要引入一个新的读出层包 from torch_geometric.nn import global_mean_pool
代码实现
数据集下载+信息统计
- 该数据集提供188个不同的图,任务是将每个图分类为两个类中的一个,节点特征维度7。
代码
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='/data/TUDataset', name='MUTAG')
print()
print(f'Dataset: {dataset}:')
print('====================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')结果
Downloading https://www.chrsmrrs.com/graphkerneldatasets/MUTAG.zip
Extracting \data\TUDataset\MUTAG\MUTAG.zip
Processing...
Done!
Dataset: MUTAG(188):
====================
Number of graphs: 188
Number of features: 7
Number of classes: 2单个图(第一个图)信息统计
- 通过检查数据集的第一个图对象,我们可以看到它有17个节点(带有7维特征向量)和38条边(导致平均节点度为2.24)。
- 它还提供了一个精确的图形标签(y=[1]),
- 还提供了额外的4维边缘特征(edge_attr=[38,4])。但是,为了简单起见,我们不使用这些。
代码
data = dataset[0] # Get the first graph object.
print(data)
print('=============================================================')
# Gather some statistics about the first graph.
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
print(f'Contains isolated nodes: {data.contains_isolated_nodes()}')
print(f'Contains self-loops: {data.contains_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')结果
Data(edge_attr=[38, 4], edge_index=[2, 38], x=[17, 7], y=[1])
=============================================================
Number of nodes: 17
Number of edges: 38
Average node degree: 2.24
Contains isolated nodes: False
Contains self-loops: False
Is undirected: True
数据集划分
PyTorch Geometric提供了一些用于处理图数据集的实用工具,
- 例如,我们可以打乱数据集
- 并使用前150个图作为训练图,而使用其余(188-150=38)的用于测试
代码
import torch
torch.manual_seed(12345)
dataset = dataset.shuffle()
train_dataset = dataset[:150]
test_dataset = dataset[150:]
print(f'Number of training graphs: {len(train_dataset)}')
print(f'Number of test graphs: {len(test_dataset)}')结果
Number of training graphs: 150
Number of test graphs: 38minibatch加载训练集每个图的数据
简介
由于图分类数据集中的图通常比较小,一个好主意是在将它们输入到图神经网络之前对其进行批处理,以保证GPU的充分利用。
- 在图像或语言领域,这个过程通常是通过将每个示例重新缩放或填充为一组大小相同的形状来实现的,然后将示例分组在一个额外的维度中。这个维度的长度等于小批处理中分组的示例的数量,通常称为batch_size。
- 然而,对于gnn,上述两种方法要么是不可行的,可能导致大量不必要的内存消耗。
- 因此,PyTorch Geometric选择了另一种方法来实现多个示例的并行化。
- 这里,邻接矩阵以对角线的方式堆叠(创建一个包含多个孤立子图的巨型图),节点和目标特征在节点维数上简单地连接起来(见下图)
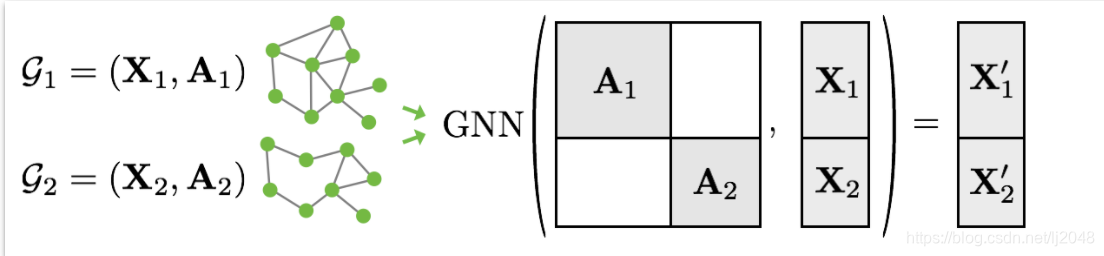
与其他批处理过程相比,这个过程有一些至关重要的优点:
- 依赖于消息传递方案的GNN操作符不需要修改,因为消息不会在属于不同图的两个节点之间交换。
- 没有计算或内存开销,因为邻接矩阵以稀疏方式保存,只保存非零项,即边缘。
PyTorch Geometric使用torch_geometric.data.DataLoader自动处理将多个图形批量生成为单个巨型图形
实现
这里,我们选择batch_size为64,导致3个(随机打乱的)小批量,包含所有2个64+22=150个图。此外,每个批处理对象都配有一个批处理向量batch,该向量将每个节点映射到批处理中的各自图上
![]()
这个batch是对图数据的划分
- y就是每个图的标签,150个图变成了64 64 22
- x就是【节点数,节点特征7】
- edge_index【2,边数(约节点2倍)】
- edge_attr【边数,边特征4】模型并没用这个属性
代码
from torch_geometric.data import DataLoader
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
for step, data in enumerate(train_loader):
print(f'Step {step + 1}:')
print('=======')
print(f'Number of graphs in the current batch: {data.num_graphs}')
print(data)
print()结果
Step 1:
=======
Number of graphs in the current batch: 64
Batch(batch=[1169], edge_attr=[2592, 4], edge_index=[2, 2592], x=[1169, 7], y=[64])
Step 2:
=======
Number of graphs in the current batch: 64
Batch(batch=[1116], edge_attr=[2444, 4], edge_index=[2, 2444], x=[1116, 7], y=[64])
Step 3:
=======
Number of graphs in the current batch: 22
Batch(batch=[429], edge_attr=[958, 4], edge_index=[2, 958], x=[429, 7], y=[22])GNN模型定义
训练GNN图分类通常遵循一个简单的规则:
- 通过执行多轮消息传递每个节点嵌入
- 将节点嵌入聚合成统一的图嵌入(读出层)
- 训练一个图嵌入的最终分类器
- 在这里,同样利用
GCNConv)激活的GCNConv来获取局部的节点嵌入 - 然后在图形读出层上应用最终的分类器。
- 在这里,同样利用
文献中存在多种读出层,但最常见的是简单取节点嵌入的平均值
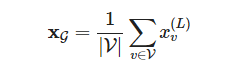
PyTorch Geometric通过torch_geometric.nn.global_mean_pool提供了这个功能,
- 它接受小批处理中所有节点的节点嵌入和赋值向量批处理,
- 为批处理中的每个图计算大小为[batch_size, hidden_channels]的图嵌入
- 将gnn应用于图分类任务的最终架构如下,并允许进行完整的端到端训练
代码
from t 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2464
2464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











