







 本文探讨了图神经网络(GNN)在金融风控领域的应用,包括恶意账户识别、贷款违约预测和反欺诈。介绍了GNN的核心思想、相关框架与开源平台,并讨论了未来的研究方向。在蚂蚁金服、IBM和北航的实际案例中,GNN展现出在识别网络中的异常模式和风险预测方面的潜力。此外,还提到了GNN在其他领域如推荐系统、音乐推荐和车辆调控管理中的应用。
本文探讨了图神经网络(GNN)在金融风控领域的应用,包括恶意账户识别、贷款违约预测和反欺诈。介绍了GNN的核心思想、相关框架与开源平台,并讨论了未来的研究方向。在蚂蚁金服、IBM和北航的实际案例中,GNN展现出在识别网络中的异常模式和风险预测方面的潜力。此外,还提到了GNN在其他领域如推荐系统、音乐推荐和车辆调控管理中的应用。
前言
本文重点:
-
工业界 金融欺诈风控领域上 GNN的应用及进展
注:
-
本文仅针对 可用「深度图神经网络解决」的 - 「金融风控」相关的任务论文
-
「除深度图神经网络之外,业界常用经典图算法」 & 「除金融欺诈风控领域之外,常见推荐等任务」 & 「图数据库存储方式」会顺带提及,但本文不会详细讲解
前置知识:
1WHY GNN
非欧空间需要GNN来解决:
-
当前,深度学习技术已经在语音识别、机器翻译、图像分析和计算机视觉等方向取得了重要成果
-
✅ 欧氏空间:音频 / 自然语言(1D)、图像(2D)、视频(3D)
-
❌ 非欧空间:社交网络数据、生物化学图结构、引文网络等
“图结构”的分类
-
有向 / 无向(边)
-
有权 / 无权(边)
-
有特征 / 无特征(节点 / 边)
-
同构 / 异购(节点 / 边)
-
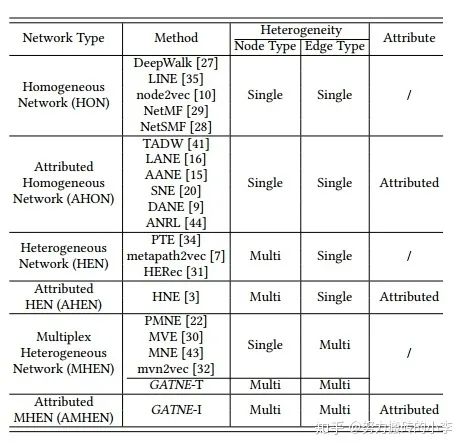
-
Attributed:考虑节点性质,如用户性别、年龄、购买力等
-
Multiplex:多重边,节点之间可能有多种关系,比如说两个用户之间可能为好友、同学、交易关系等;用户和item之间可以浏览、点击、添加到购物车、购买等
-
Heterogeneous:异构,节点和边有多种类型,节点类型+边类型>2
-
-- Representation Learning for Attributed Multiplex Heterogeneous Network 阿里异构Embedding GATNE
GNN 的核心
-
就是 information diffusion mechanism / message passing。
-
其核心就是要在相互连接的节点之间交换信息,即需要迭代地更新节点的表示,每一次更新,每个节点上的信息都和相邻节点做一定的交互。
-
这两类都通过一个参数化表示的深度学习模块来做这样的信息交换:在 RecGNN 中, 每一步信息交换的变换函数都是一样的,并且目标是做很多次这样的信息交换直到每个节点上的特征都达到稳态;在 ConvGNN 中,每一步信息交换的函数都不一样,并且只经过有限步的信息交换。这一点区别如下图所示。
-
对于 graph-level 的任务来说,还需要从图上每个节点把信息聚合起来,这就涉及到很多 pooling 的技术。
-
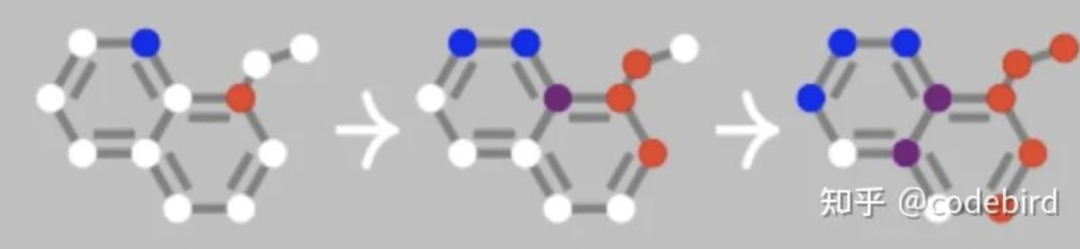
图神经网络的基本思想:
-
图神经网络的基本思想,就是基于节点的局部邻居信息对节点进行embedding。
-
直观来讲,就是通过神经网络来聚合每个节点及其周围节点的信息。
-
算法思想是基于节点的局部邻居及其自身特征信息对节点进行表示学习(Node Representation Learning)。
-
本质上是通过神经网络对聚合节点及其邻居节点的特征信息做非线性变换。
-
图神经网络有很多变种,可以从图的类型、训练方法和传播步骤等多方面进行变种分类。
图上的学习任务
-
1、图节点分类任务:图中每个节点都有对应的特征,当我们已知一些节点的类别的时候,可以设计分类任务针对未知节点进行分类
-
2、图边结构预测任务:图中的节点和节点之间的边关系可能在输入数据中能够采集到,而有些隐藏的边需要我们挖掘出来。就是对边的预测任务,节点和节点之间关系的预测。
-
3、图的分类:对于整个图来说,我们也可以对图分类。基本思路是将图中节点的特征聚合起来作为图的特征,再进行分类。
另:
-
一般在图中寻找子团的任务为社群检测(Community Detection)或者叫作高密子图挖掘(Dense Subgraph Mining)
-
算法不断删除节点使得剩下的节点构成的社区可疑度最大,然后记录整个删除过程中社区可疑度最大的那一轮,那么该轮的剩余节点构成的子图就是最可疑的。
-
针对固定问题使用固定算法,如FRAUDAR 算法自动化地挖掘出二部图里的高密子图,较少用GNN解决
-
https://zhuanlan.zhihu.com/p/45625323
学习任务的应用
-
图神经网络在文本分类(Text classification)
-
序列标注(Sequence labeling)
-
神经机器翻译(Neural machine translation)
-
关系抽取(Relation extraction)
-
事件抽取(Event extraction)
-
图像分类(Image Classification)
-
视觉推理(Visual Reasoning)
-
语义分割(Semantic Segmentation)
-
等等
领域应用:
-
风控领域、推荐系统(社交网络 / 电商推荐)、生物医疗等等
未来的研究方向
-
如何有效地提升模型复杂度:因为 convolution 层变多时,各个节点的特征将会变得越来越接近,加多层数最后会使得所有的点上的特征都变成一样的,因此不能单独靠把模型做深来提高模型复杂度。
-
如何提高模型的拓展性:当图的规模变得特别大时,就需要考虑如何来对图进行聚合并且尽量不要丢失图上的信息。有两种思路:sampling 可能会使得节点丢失一些很关键的邻居;clustering 可能会使得图丢失一些比较特别的结构模式。
-
如何融合异源数据:真实应用场景中,图可能会有不同类型的节点、连边,如何处理这些数据也将成为一个研究方向。
-
如何处理动态的图&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











