







之前的文章可以看这里
相关论文在这里

开始介绍DPG之前,先回顾下DQN系列
DQN直接训练一个Q Network 去估计每个离散动作的Q值,使用时选择Q值大的动作去执行(贪婪策略)
DQN可以处理每个离散的动作,对于连续动作空间上,虽然可以细分步长转化为更多的离散动作来做,但效果不好且训练成本倍增,由此学者们想到了Policy Gradient 确定策略梯度。
一、PG Policy Gradient

策略梯度算法是一种更为直接的方法,它让神经网络直接输出策略函数 π(s),即在状态s下应该执行何种动作。对于非确定性策略,输出的是这种状态下执行各种动作的概率值,即如下的条件概率
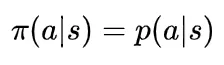
对于连续性动作来说,一般使用随机高斯策略,网络的输入是智能体当前状态,网络的输出的高斯策略的均值和标准差,网络是一个拟合网络。
无论是连续动作还是离散动作,在使用PG时,必须先弄清下面公式,离散动作和连续动作最大的不同就在于

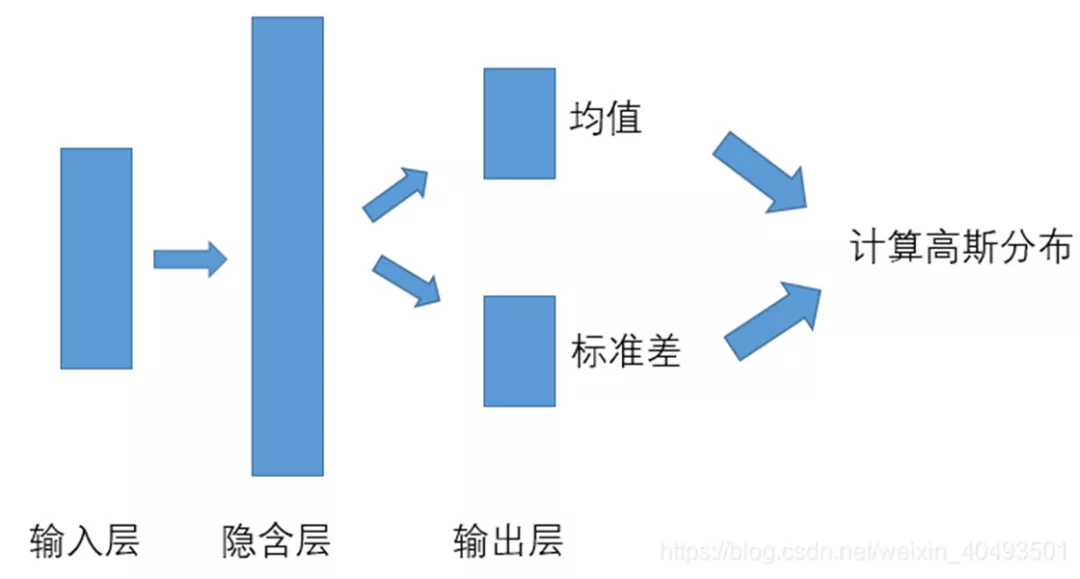
连续动作PG算法网络模型如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6963
6963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









