







Adapt or Perish: Adaptive Sparse Transformer with Attentive Feature Refinement for Image Restoration
论文地址:
主要问题: 基于Transformer的图像恢复方法在建模长距离依赖关系方面表现出色,但同时也存在计算量大、冗余信息多和噪声交互等问题。
解决方案: 论文提出了一个自适应稀疏Transformer (AST) 模型,旨在减少无关区域的噪声交互,并消除空间和通道域中的特征冗余。
AST模型主要包含两个核心设计:
-
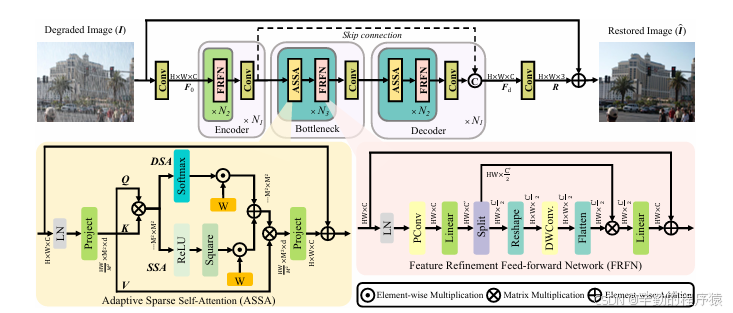
自适应稀疏自注意力 (ASSA) 模块: 该模块采用双分支模式,包括稀疏自注意力分支 (SSA) 和密集自注意力分支 (DSA)。SSA用于过滤掉低查询-键匹配分数的负面影響,而DSA则确保足够的信息流通过网络网络,以学习判别性表示。
-
特征细化前馈网络 (FRFN): 该模块采用增强和简化方案来 适用任务: 论 AST模型在多个图像恢复任务中表现出色,包括:
-
雨痕去除: 在SPAD数据集上,AST-B模型在PSNR指标上比现有的最佳的CNN模型和Transformer模型。
-
雨滴去除: 在AGAN-Data数据集上,AST-B模型在PSNR指标上优于之前最佳的雨滴去除方法和。
-
真实雾去除: 在Dense-Haze数据集上,AST-B模型在PSNR指标上优于之前最佳的雾去除方法。
-
AST模型通过自适应稀疏自注意力和特征细化前馈网络,有效地解决了基于 AST模型通过自适应稀疏自注意力和特征细化前馈网络,有效地解决了基于 AST模型通过自适应稀疏自注意力和特征细化前馈网络,有效地解决了基于Transformer的图像恢复方法中存在的计算量大、冗余信息多和噪声交互等问题,并在多个图像恢复任务中取得了优异的性能。
即插即用代码:
import torch
import torch.nn as nn
from timm.models.layers import trunc_normal_
from einops import repeat
class LinearProjection(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, bias=True):
super().__init__()
inner_dim = dim_head * heads
self.heads = heads
self.to_q = nn.Linear(dim, inner_dim, bias = bias)
self.to_kv = nn.Linear(dim, inner_dim * 2, bias = bias)
self.dim = dim
self.inner_dim = inner_dim
def forward(self, x, attn_kv=None):
B_, N, C = x.shape
if attn_kv is not None:
attn_kv = attn_kv.unsqueeze(0).repeat(B_,1,1)
else:
attn_kv = x
N_kv = attn_kv.size(1)
q = self.to_q(x).reshape(B_, N, 1, self.heads, C // self.heads).permute(2, 0, 3, 1, 4)
kv = self.to_kv(attn_kv).reshape(B_, N_kv, 2, self.heads, C // self.heads).permute(2, 0, 3, 1, 4)
q = q[0]
k, v = kv[0], kv[1]
return q,k,v
# Adaptive Sparse Self-Attention (ASSA)
class WindowAttention_sparse(nn.Module):
def __init__(self, dim, win_size, num_heads=8, token_projection='linear', qkv_bias=True, qk_scale=None, attn_drop=0.,
proj_drop=0.):
super().__init__()
self.dim = dim
self.win_size = win_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * win_size[0] - 1) * (2 * win_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.win_size[0]) # [0,...,Wh-1]
coords_w = torch.arange(self.win_size[1]) # [0,...,Ww-1]
coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing='ij')) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.win_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.win_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.win_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
trunc_normal_(self.relative_position_bias_table, std=.02)
if token_projection == 'linear':
self.qkv = LinearProjection(dim, num_heads, dim // num_heads, bias=qkv_bias)
else:
raise Exception("Projection error!")
self.token_projection = token_projection
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
self.relu = nn.ReLU()
self.w = nn.Parameter(torch.ones(2))
def forward(self, x, attn_kv=None, mask=None):
B_, N, C = x.shape
q, k, v = self.qkv(x, attn_kv)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.win_size[0] * self.win_size[1], self.win_size[0] * self.win_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
ratio = attn.size(-1) // relative_position_bias.size(-1)
relative_position_bias = repeat(relative_position_bias, 'nH l c -> nH l (c d)', d=ratio)
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
mask = repeat(mask, 'nW m n -> nW m (n d)', d=ratio)
attn = attn.view(B_ // nW, nW, self.num_heads, N, N * ratio) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N * ratio)
attn0 = self.softmax(attn)
attn1 = self.relu(attn) ** 2 # b,h,w,c
else:
attn0 = self.softmax(attn)
attn1 = self.relu(attn) ** 2
w1 = torch.exp(self.w[0]) / torch.sum(torch.exp(self.w))
w2 = torch.exp(self.w[1]) / torch.sum(torch.exp(self.w))
attn = attn0 * w1 + attn1 * w2
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
if __name__ == '__main__':
# Instantiate the WindowAttention_sparse class
dim = 32 # Dimension of input features
win_size = (32, 32) # Window size(H, W)
# Create an instance of the WindowAttention_sparse module
window_attention_sparse = WindowAttention_sparse(dim, win_size)
C = dim
input = torch.randn(1, 32 * 32, C)#输入B H W
# Forward pass
output = window_attention_sparse(input)
# Print input and output size
print(input.size())
print(output.size())玩yolo的同行可进交流群,群里有答疑(QQ:828370883):




















 3715
3715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









