







图像修复-CVPR2024-AST-Adapt or Perish: Adaptive Sparse Transformer with Attentive Feature Refinement for Image Restoration
文章目录
Adaptive Sparse Transformer (AST) 通过减少图像恢复过程中无关区域的噪声干扰和特征冗余,实现更高效的图像清晰度恢复。AST 包含两个关键设计:自适应稀疏自注意力(ASSA) 和 特征精炼前馈网络(FRFN)。
论文链接:Adaptive Sparse Transformer with Attentive Feature Refinement for Image Restoration
源码链接:/joshyZhou/AST
主要创新点
ASSA:采用双分支结构,其中稀疏分支通过过滤低查询-键匹配分数的影响,减小无关区域的噪声干扰;而密集分支则保持信息流的充分传递,帮助网络学习判别性表示。
FRFN:使用增强和简化机制消除通道上的特征冗余,从而提升清晰图像的恢复效果。
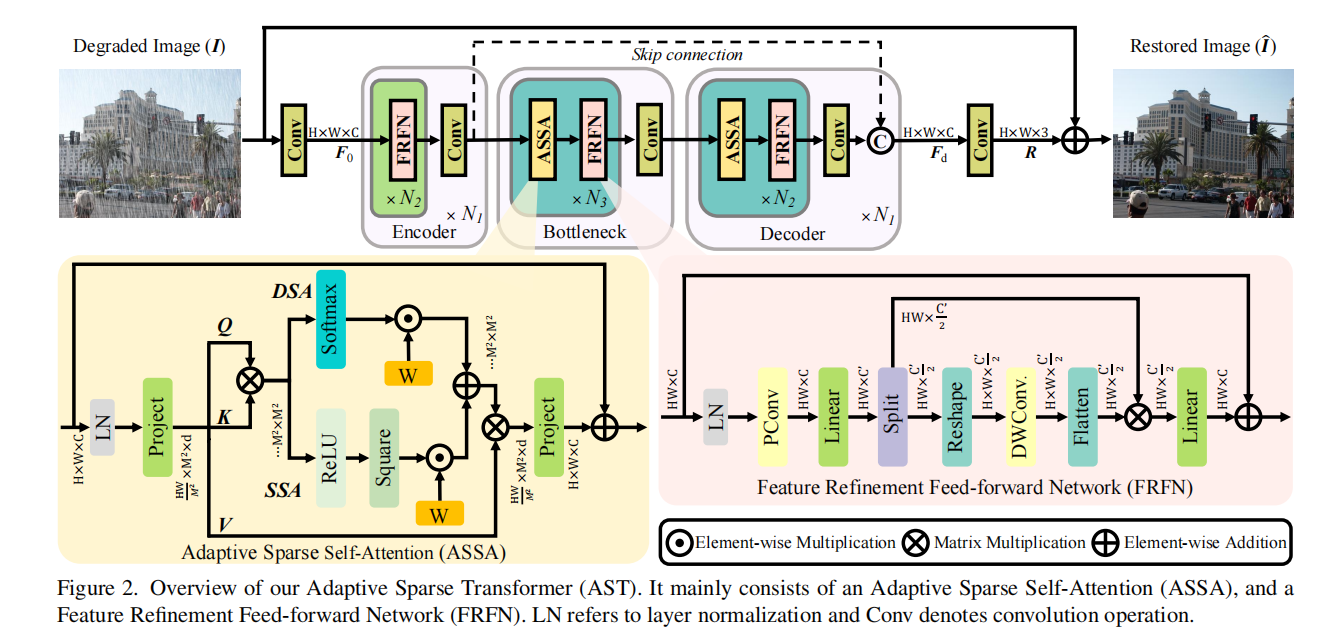
模型架构图
主要由下面两部分组成:
自适应稀疏自注意力(ASSA):主要采用了双分支结构,设计采用
RELU平方激活函数,针对性地过滤低查询-键匹配分数的特征,从而减少无关区域的噪声影响,并保持稀疏特性,但考虑稀疏会丢失关键性信息,采用DSA使用softmax作为激活函数,来保留关键性信息。特征精炼前馈网络(FRFN):FRFN 引入 PConv 操作 来加强特征中的有用元素,并通过 门控机制 减少冗余信息的处理负担。
前面和后面的
3x3卷积分别是将图片映射在特征图上、将特征图解码成图片,中间的encoder为N2xN1层,Bottleneck为N3层,Decoder为N2xN1层下面将从源码层面剖析,模型设计和代码实现上的区别。
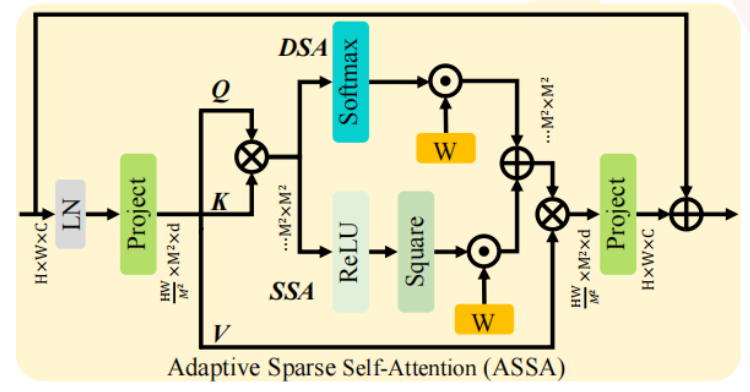
自适应稀疏自注意力(ASSA)
本文提出了一种双分支自注意力机制,通过 稀疏自注意力(SSA) 和 密集自注意力(DSA) 的自适应组合,来优化特征聚合,从而提升图像恢复效果。
SSA和DSA通过自适应加权融合来利用二者优势,以提高信息提取的精确性。
- 密集自注意力(DSA):采用
softmax层计算所有查询-键对之间的注意力分数,适用于大多数自注意力机制。DSA将每个查询和所有键的相似度都纳入考虑,能够保证信息的充足传递。但这种密集注意力可能会引入无关区域的噪声干扰,影响清晰图像的恢复。- 稀疏自注意力(SSA):通过
平方ReLU层处理查询和键的相似度,剔除负分数的相似度,从而增强特征聚合的稀疏性。SSA过滤了不相关的区域,减少了特征冗余,但会导致信息缺失,可能不利于后续处理。
ASSA源码实现
从源码实现上来看,相对来说所简单的,先计算注意力分数
attn,为每个注意力加上偏置,基本上作用就是提升模型对窗口中token的空间位置关系的建模能力,然后有掩码加入掩码,没有就直接将attn进行DSA 使用softmax计算注意力和SSA使用平方ReLU计算注意力,最后在特征融合阶段,分别初始化一个权重参数,来达到自适应选择两者的计算后的注意力,最后将计算得到注意力attn加个dropout,然后应用到V,完成整个ASSA过程。
########### Window-based Self-Attention #############
class WindowAttention_sparse(nn.Module):
def __init__(self, dim, win_size, num_heads, token_projection='linear', qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
# 初始化参数
self.dim = dim # 特征维度
self.win_size = win_size # 窗口大小(Wh, Ww)
self.num_heads = num_heads # 注意力头数量
head_dim = dim // num_heads # 每个头的维度
self.scale = qk_scale or head_dim ** -0.5 # 缩放因子,用于稳定数值计算
# 定义相对位置偏置的参数表
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * win_size[0] - 1) * (2 * win_size[1] - 1), num_heads)) # 大小为 2*Wh-1 * 2*Ww-1, nH
# 获取窗口中每个 token 的相对位置索引
coords_h = torch.arange(self.win_size[0]) # [0,...,Wh-1]
coords_w = torch.arange(self.win_size[1]) # [0,...,Ww-1]
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 生成坐标,形状为 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 扁平化为 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 计算相对坐标差
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # 形状调整为 Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.win_size[0] - 1 # 偏移以从 0 开始
relative_coords[:, :, 1] += self.win_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.win_size[1] - 1
relative_position_index = relative_coords.sum(-1) # 计算相对位置索引,形状为 Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index) # 将其注册为缓冲区
trunc_normal_(self.relative_position_bias_table, std=.02) # 初始化相对位置偏置参数
# 定义查询、键、值的投影
if token_projection == 'linear':
self.qkv = LinearProjection(dim, num_heads, dim // num_heads, bias=qkv_bias)
else:
raise Exception("Projection error!")
self.token_projection = token_projection
self.attn_drop = nn.Dropout(attn_drop) # 注意力权重的 dropout
self.proj = nn.Linear(dim, dim) # 输出投影
self.proj_drop = nn.Dropout(proj_drop) # 输出的 dropout
# 定义 softmax 和 ReLU 激活
self.softmax = nn.Softmax(dim=-1)
self.relu = nn.ReLU()
self.w = nn.Parameter(torch.ones(2)) # 自适应权重参数
def forward(self, x, attn_kv=None, mask=None):
B_, N, C = x.shape # 获取输入张量的 batch size, token 数和通道数
q, k, v = self.qkv(x, attn_kv) # 计算查询、键和值
q = q * self.scale # 缩放查询
attn = (q @ k.transpose(-2, -1)) # 计算查询和键之间的点积注意力分数
# 加入相对位置偏置
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.win_size[0] * self.win_size[1], self.win_size[0] * self.win_size[1], -1) # 大小调整为 Wh*Ww, Wh*Ww, nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # 形状调整为 nH, Wh*Ww, Wh*Ww
ratio = attn.size(-1) // relative_position_bias.size(-1) # 计算 ratio
relative_position_bias = repeat(relative_position_bias, 'nH l c -> nH l (c d)', d=ratio) # 扩展维度
attn = attn + relative_position_bias.unsqueeze(0) # 加入偏置
# 使用掩码(mask),如果有
if mask is not None:
nW = mask.shape[0]
mask = repeat(mask, 'nW m n -> nW m (n d)', d=ratio) # 扩展掩码维度
attn = attn.view(B_ // nW, nW, self.num_heads, N, N * ratio) + mask.unsqueeze(1).unsqueeze(0) # 加入掩码
attn = attn.view(-1, self.num_heads, N, N * ratio)
attn0 = self.softmax(attn) # DSA 使用 softmax 计算注意力
attn1 = self.relu(attn)**2 # SSA 使用平方 ReLU 计算注意力
else:
attn0 = self.softmax(attn)
attn1 = self.relu(attn)**2
# 计算自适应权重并进行融合
w1 = torch.exp(self.w[0]) / torch.sum(torch.exp(self.w)) # 自适应权重 w1
w2 = torch.exp(self.w[1]) / torch.sum(torch.exp(self.w)) # 自适应权重 w2
attn = attn0 * w1 + attn1 * w2 # 融合两个注意力分支
attn = self.attn_drop(attn) # dropout 处理
# 计算输出特征
x = (attn @ v).transpose(1, 2).reshape(B_, N, C) # 应用注意力权重到值 v
x = self.proj(x) # 线性投影
x = self.proj_drop(x) # dropout 处理
return x # 返回最终输出
特征精炼前馈网络(FRFN)
- 常规的前馈网络(FFN)在每个像素位置独立地处理信息,这有助于通过自注意力机制来增强特征表示。然而,当使用 Adaptive Sparse Self-Attention (ASSA) 来移除空间域中的冗余信息时,通道中的信息冗余依然存在,影响了图像清晰度的恢复效果。为了解决这一问题,
FRFN通过一个 “增强和简化” 的过程,对特征进行变换和优化,提升通道维度上的信息表达能力。- PConv(部分卷积) 用于强化特征中的信息元素,有助于提取关键信息。
- 门控机制(Gate Mechanism) 用于减少冗余信息的处理负担,通过限制无用信息的传播,减少不相关特征对图像恢复的干扰。
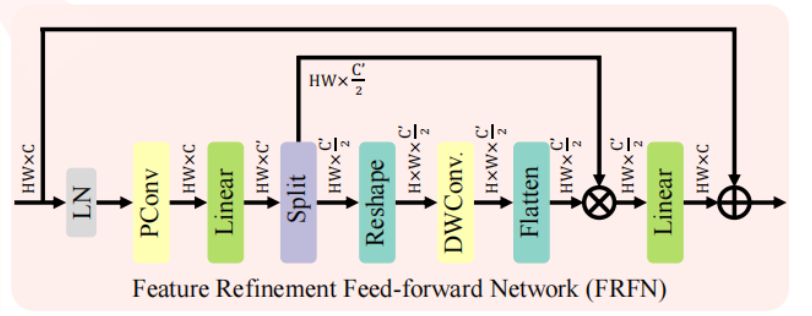
PConv 和 DWConv:部分卷积和深度卷积可以有效提取局部关键信息,帮助
FRFN从流动信息中提取具有代表性的特征,增强模型的图像恢复能力。门控机制和冗余控制:通过通道分割和信息聚合,
FRFN在保留重要信息的同时减少冗余,简化了通道维度的无用特征,从而提升了清晰图像的恢复效果。
FRFN源码实现
实现上是基本上按照图中所画实现的,但是也是有些区别的, 可能是图画错了。对比代码和图中流程:
- 图中流程:经过一个
LN,然后使用一个PConv,然后线性激活,然后将图像split通道数分成两半x1,x2,然后对x1来多少经过深度卷积然后再和x2做矩阵乘法,最后经过线性激活得到最终图像。- 代码流程:可以看出实现上是有一定区别的,在的
PConv之前会将图像先split,然后经过PCov之后又将图像拼合,一起做线性激活Linear,然后再分成两部分,来进行Dconv和之后的步骤。对比可以发现流程图和代码之间的区别,个人理解,如果你有更好的理解,可以与我探讨。
class FRFN(nn.Module):
def __init__(self, dim=32, hidden_dim=128, act_layer=nn.GELU, drop=0., use_eca=False):
super().__init__()
# 第一层线性变换,输出维度为 hidden_dim*2,用于后续的分支计算
self.linear1 = nn.Sequential(
nn.Linear(dim, hidden_dim * 2),
act_layer()
)
# 深度卷积层,用于提取局部特征,维度为 hidden_dim
self.dwconv = nn.Sequential(
nn.Conv2d(hidden_dim, hidden_dim, groups=hidden_dim, kernel_size=3, stride=1, padding=1),
act_layer()
)
# 第二层线性变换,将通道维度从 hidden_dim 变换回 dim
self.linear2 = nn.Sequential(
nn.Linear(hidden_dim, dim)
)
self.dim = dim
self.hidden_dim = hidden_dim
# 通道分割参数,dim_conv 表示需要卷积操作的通道数量,dim_untouched 表示不进行卷积的通道数量
self.dim_conv = self.dim // 4
self.dim_untouched = self.dim - self.dim_conv
# 部分卷积操作,用于特定通道上的局部特征提取
self.partial_conv3 = nn.Conv2d(self.dim_conv, self.dim_conv, 3, 1, 1, bias=False)
def forward(self, x):
# 输入形状为 [batch_size, height*width, channels]
bs, hw, c = x.size()
hh = int(math.sqrt(hw)) # 计算高度和宽度,假设为正方形
# 恢复空间维度,将 x 从平面形式恢复为 2D 特征图形状 [batch_size, channels, height, width]
x = rearrange(x, 'b (h w) c -> b c h w', h=hh, w=hh)
# 将通道分为两部分 x1 和 x2,分别处理
x1, x2 = torch.split(x, [self.dim_conv, self.dim_untouched], dim=1)
# 对 x1 进行部分卷积处理,增强局部特征
x1 = self.partial_conv3(x1)
# 将处理后的 x1 和未处理的 x2 合并回原通道维度
x = torch.cat((x1, x2), dim=1)
# 将 x 再次展平为 [batch_size, height*width, channels] 形式
x = rearrange(x, 'b c h w -> b (h w) c', h=hh, w=hh)
# 第一次线性变换
x = self.linear1(x)
# 将 x 切分为两部分,用于门控机制
x_1, x_2 = x.chunk(2, dim=-1)
# 将 x_1 恢复为 [batch_size, channels, height, width] 形状,便于卷积操作
x_1 = rearrange(x_1, 'b (h w) c -> b c h w', h=hh, w=hh)
# 对 x_1 应用深度卷积,提取局部特征
x_1 = self.dwconv(x_1)
# 将 x_1 恢复为展平形状 [batch_size, height*width, channels]
x_1 = rearrange(x_1, 'b c h w -> b (h w) c', h=hh, w=hh)
# 门控机制,将 x_1 和 x_2 相乘,保留重要信息并过滤冗余
x = x_1 * x_2
# 第二次线性变换,将通道维度变回原始 dim
x = self.linear2(x)
# 如果启用 ECA,可在此处使用
# x = self.eca(x)
return x


















 3871
3871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









