






 文章提出了一种名为LGCF的多语言学习模型,该模型利用局部语境焦点和全局语境焦点的交互学习,以捕捉局部和全局上下文与方面情感极性的关联。LGCF结合了多头自注意力、BGRU和CNN,解决了上下文信息提取的问题,并在中英文数据集上的ABSA任务中展示了优越性能。
文章提出了一种名为LGCF的多语言学习模型,该模型利用局部语境焦点和全局语境焦点的交互学习,以捕捉局部和全局上下文与方面情感极性的关联。LGCF结合了多头自注意力、BGRU和CNN,解决了上下文信息提取的问题,并在中英文数据集上的ABSA任务中展示了优越性能。
题目、作者:

ABSTRACT
1. 写作目的:现有的研究大多集中在方面情感极性与局部语境的相关性上,但全局语境与方面情感极性之间重要的深层关联尚未得到足够的重视;
2. 基于局部语境焦点机制,我们提出了一种基于局部语境焦点(focus)和全局语境焦点交互学习的多语言学习模型——LGCF;
3. 该模型可以有效地同时学习局部上下文与目标方面之间的相关性以及全局上下文与目标方面之间的相关性。
一、INTRODUCTION
1. 我们的工作注意到:一个方面的情感极性不仅与局部上下文有很大的相关性,而且与全局上下文也有很深的相关性;
2. 由于CNN能够从自然语言中提取局部特征和深度特征,RNN能够处理顺序输入并解决长期依赖问题,所以我们设计了全局上下文焦点(Global Context Focus, GCF)来解决提取完整上下文信息不足的问题;
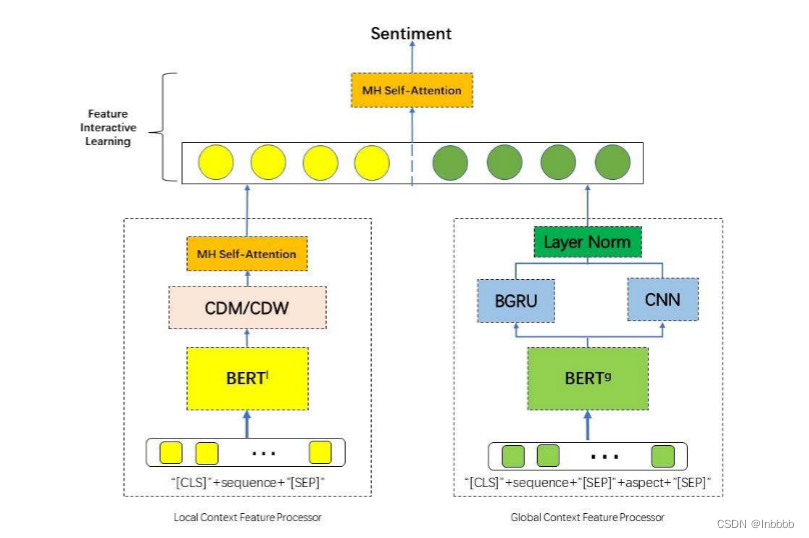
3. 模型方法介绍:LGCF设计模型不同于以往的研究,在LGCF设计模型中,局部上下文焦点部署了多头自注意力(MHSA)和上下文特征动态遮蔽(mask)或上下文特征动态加权。同时,GCF部署了双向门控循环单元(BGRU)、卷积神经网络(CNN)和层归一化(LN);
4. contributions:
① 本文提出了利用上下文特征动态掩码(CDM)或上下文特征动态加权(CDW)和多头自注意捕捉局部上下文特征的LGCF设计模型。利用BGRU和CNN学习全局上下文特征。LGCF设计模型结合局部和全局上下文特征,推断出目标方面的情感极性。
② 本文对中英文数据集上的ABSA进行了研究,为多语言ABSA的研究提供了一种新的思路。
③ 我们将BGRU和CNN引入到全局语境的特征学习中,并对BGRU和CNN不同层次结合对模型效果的影响进行了实验,充分挖掘了其在全局语境特征学习中的潜力。
二、PROPOSED METHODOLOGY
如图,LGCF主要包括四个部分:输入嵌入层、局部上下文聚焦层、全局上下文聚焦层和特征交互学习层
2.1 TASK DEFINITION
给定由n个单词(包括方面词)组成的输入内容序列(sequence):![]() ,其中方面词序列
,其中方面词序列![]()
为W 的一个子序列。ABSC(Aspect-based sentiment classification)的任务是找到目标方面对应的情感极性。
2.2 INPUT EMBEDDING LAYER
我们使用BERT将每个单词映射到嵌入的向量 ,LGCF使用两个独立的Bert共享层分别建模局部上下文序列特征和全局上下文序列特征。
在LGCF中,输入嵌入层包括局部上下文嵌入和全局上下文嵌入两个部分,它们的输入分别为:
局部上下文嵌入 → [CLS] + Sentence(sequence) + [SEP]【即![]() 】;
】;
全局上下文嵌入 → [CLS] + Sentence(sequence) + [SEP] + Aspect term + [SEP]【即![]() 】。
】。
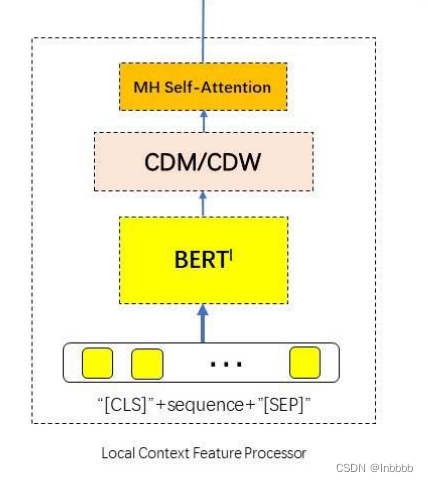
2.3 LOCAL CONTEXT FOCUS
2.3.1 MULTI-HEADED SELF-ATTENTION

多头注意力: 指重复多次寻找注意力机制的过程,然后通过线性层将它们聚集在一起,形成单个头的大小。
由于SDA(Scaled dot-product attention mechanism)计算起来更快、更有效,所以将它作为相同的自注意力函数,定义如下:
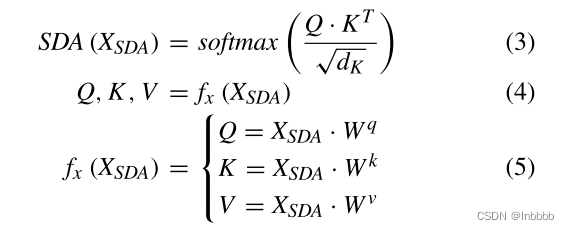
其中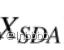 为通过嵌入层嵌入的输入表示,Wq、Wk、Wv为权重矩阵(可训练)。
为通过嵌入层嵌入的输入表示,Wq、Wk、Wv为权重矩阵(可训练)。
每个注意力头学习到的注意力表示(Hi)将通过乘以一个向量![]() (参数矩阵)来连接和转换
(参数矩阵)来连接和转换
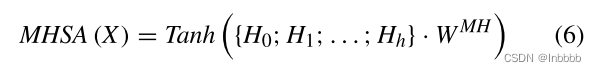
2.3.2 SEMANTIC-RELATIVE DISTANCE
LCF(Local Context FeatureProcessor)根据语义相对距离(SRD)确定哪些上下文单词属于目标方面的上下文单词(即该方面词的局部内容)。大量的实验结果表明,目标方面的局部环境包含着非常重要的信息。
语义相对距离(SRD):用于描述token和方面词之间的距离。
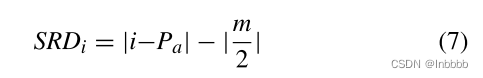
其中i (1 < i < n)是具体token的位置,Pa是方面的中心位置。m是目标方面的长度,SRDi表示第i个token和目标方面之间的语义相对距离。
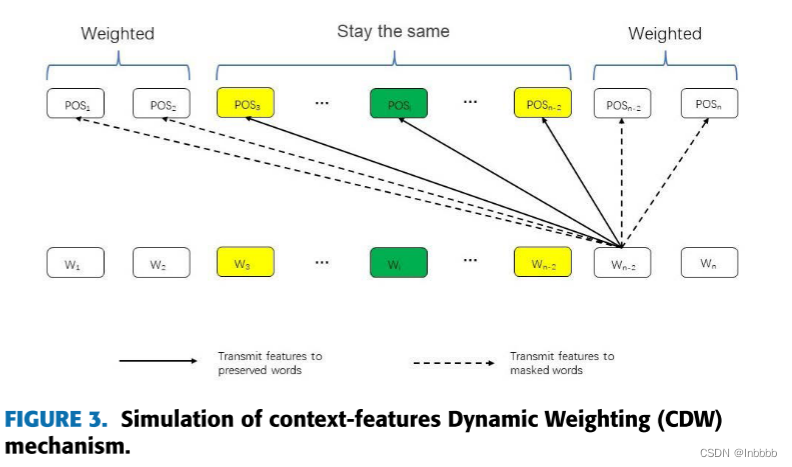
下面两个图显示了两种局部上下文聚焦机制的实现,分别是上下文特征动态掩码(CDM)层和上下文特征动态加权(CDW)层。图的底部和顶部表示每个token对应的特征输入位置和输出位置(POS)。多头注意力(MHSA)编码器计算所有token的输出,然后在每个输出位置的输出特征将被mask或加权衰减,而局部上下文将保持不变(stay the same)。
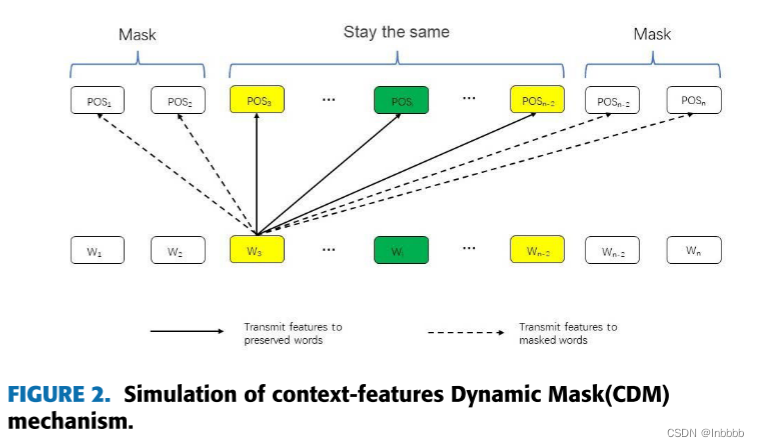
 2.3.3 CONTEXT-FEATURES DYNAMIC MASK
2.3.3 CONTEXT-FEATURES DYNAMIC MASK
针对局部上下文机制之一:上下文特征动态掩码
作用:mask掉Bert共享层中相对来说学习语义较少的上下文特征。mask后,多头注意力编码器学习mask位置的上下文特征,通过这种方式,LCF设计减轻了具有相对较少语义的上下文的影响,但是保留了每个上下文单词和方面之间的相关性。
CDM关注局部上下文,为每个上下文单词构造一个掩码向量![]()
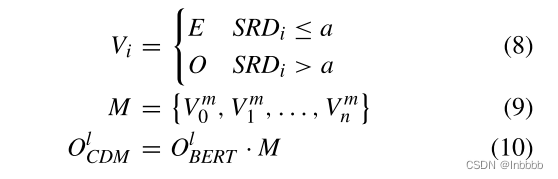
其中a为SRD(语义相对距离)的阈值,M为输入序列的掩码矩阵,n为输入序列长度,E为一个向量。
当语义相对距离较小(小于a)时,令该单词的向量Vi等于E;较大时等于0(看Figure 2方便理解)
2.3.4 CONTEXT-FEATURES DYNAMIC WEIGHTING
针对局部上下文机制之二:上下文特征动态加权
作用:语义相关的上下文特征将被完全保留,而语义不相关的上下文特征将被削弱。根据上下文词的语义相对距离,将上下文词远离目标方面的特征进行加权(削弱)

公式符号含义与2.2.3相似
2.3.5 CDM-CDW
根据CDW和CDM的输出,可以得到局部上下文的输出表示。
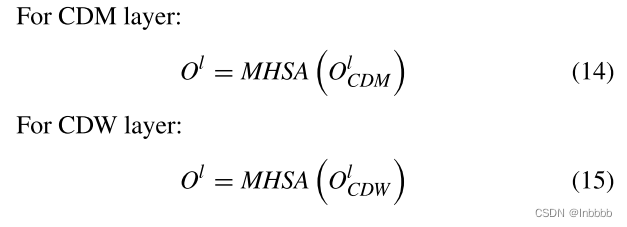
CDM-CDW融合了CDM和CDW,将CDM和CDW层学习到的特征连接起来,并采用线性变换作为局部上下文的特征
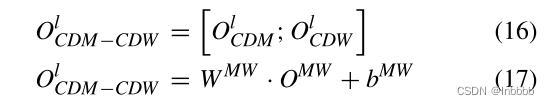
其中![]() 分别为权重矩阵和偏置向量。
分别为权重矩阵和偏置向量。
2.4 GLOBAL CONTEXT FOCUS
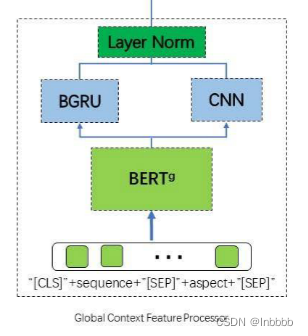
CNN介绍:CNN可以从自然语言中提取局部特征和深度特征。
总体介绍:在本节中,我们将CNN和BGRU结合起来进行全文上下文焦点(GCF)。全局上下文焦点主要由三部分组成:双向门控循环单元(BGRU)、卷积神经网络(CNN)和层归一化(LN)
2.4.1 BIDIRECTIONAL GATED RECURRENT UNIT
RNN介绍:处理序列数据,在序列学习中学习长期依赖关系,同时避免学习过程中的梯度消失和梯度爆炸【GRU为RNN的变体】。
BGRU(双向GRU)作用:我们利用一个由两层GRU组成的BGRU,一层从序列数据中学习特征,另一层从反向输入数据中学习特征。
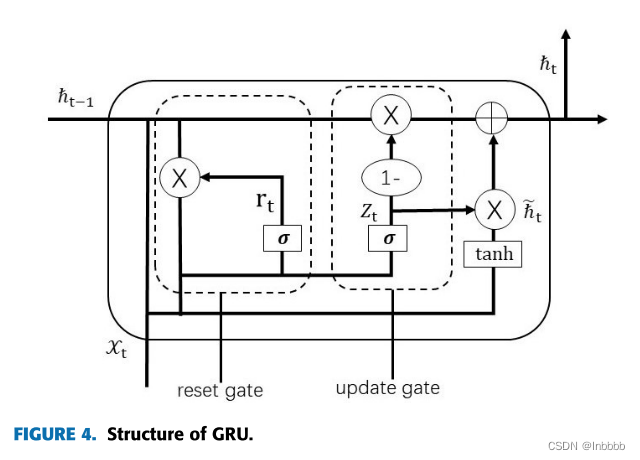
GRU介绍:图4为GRU结构图,时间t的输入为ht−1和xt,输出为ht
其中参数按以下公式更新:
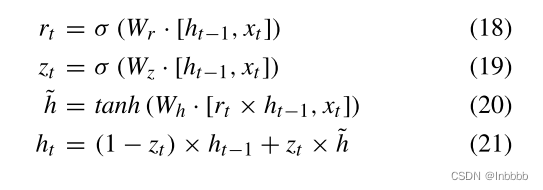
其中rt、zt分别对应重置门、更新门,ht表示候选隐层,wr、Wz、Wh、Wo为GRU参数,激活函数tanh公式为:
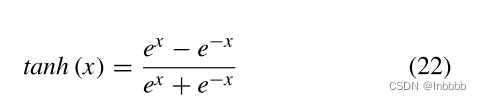
上述结构使模型能够从顺序数据输入中完全了解上下文信息。此外,在每个训练过程中,对部分神经元元素进行随机归零,是一种有效的正则化方法
最后,得到BGRU的输出:
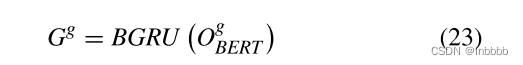
其中  为由处理全局上下文Bert的输出。
为由处理全局上下文Bert的输出。
2.4.2 CONVOLUTIONAL NEURAL NETWORK

CNN作用:在卷积层之间共享权值可以让模型去除网络中各层之间的一些连接,这有助于减少计算量,避免过度拟合。根据:
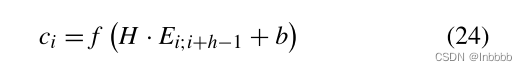
(其中![]() 为i到i+h-1的列向量,b为偏置,f为激活函数)
为i到i+h-1的列向量,b为偏置,f为激活函数)
对整个输入应用卷积核,得到特征映射:
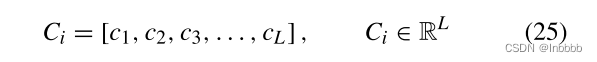
最终得到CNN层的输出
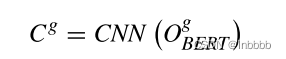
2.4.3 LAYER NORMALIZATION
![]()
层归一化(layer normalization)作用:层归一化是针对单个训练样本执行的,不依赖于其他数据。因此,它可以避免批量归一化过程中受小批量数据分布影响的问题,可以应用于小批量场景、动态网络场景和RNN,特别是在自然语言处理领域。层归一化不需要节省小批处理的均值和方差,节省了额外的存储空间
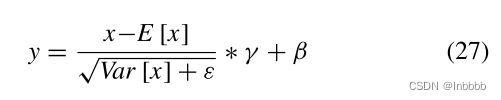
公式解释:第一项是标准化过程。为了防止数值不稳定,分母中的ε是一个非常小的数。γ和β是仿射参数。将规范化数据再次放大以获得新数据。γ是标准差,β是均值,它们通常是可以学习的。γ和β是层标准化的唯一可学参数。
最后将CNN与BGRU的输出合并起来,送入归一化中,得到layer normalization的输出:
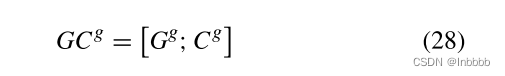
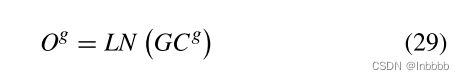
2.4.4 FEATURE INTERACTIVE LEARNING LAYER
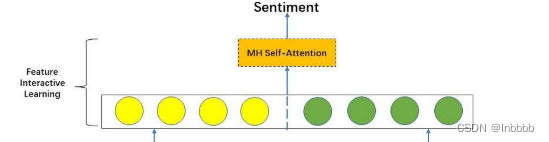
作用:交互方式学习全文的上下文特征。
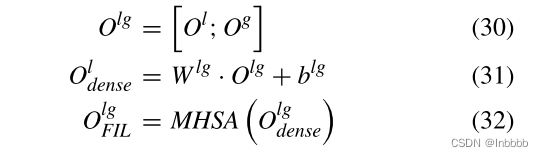
特征交互学习层首先多头注意力(局部上下文特征处理器)的输出与归一化层(全局上下文特征处理器)的输出结合在一起得到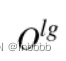 ,后将其乘一个权重,加上个偏置,送到最后一个多头注意力层,得到本层的最终输出。
,后将其乘一个权重,加上个偏置,送到最后一个多头注意力层,得到本层的最终输出。
2.4.5 OUTPUT LAYER
在输出层中,通过池化(POOL)提取第一个token对应位置的隐藏状态,将特征交互学习层学习到的特征表示集合起来。最后利用softmax层预测情感的极性
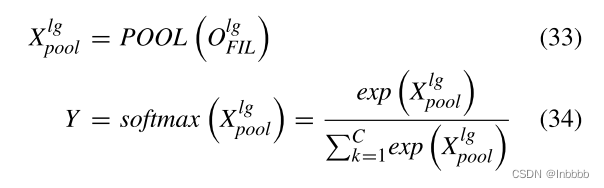
Train——LOSS交叉熵损失:
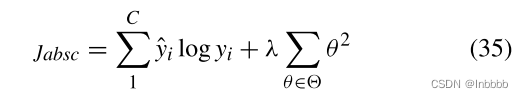
三、EXPERIMENTS
在中文数据集上的对比实验:

在英文数据集上的对比实验: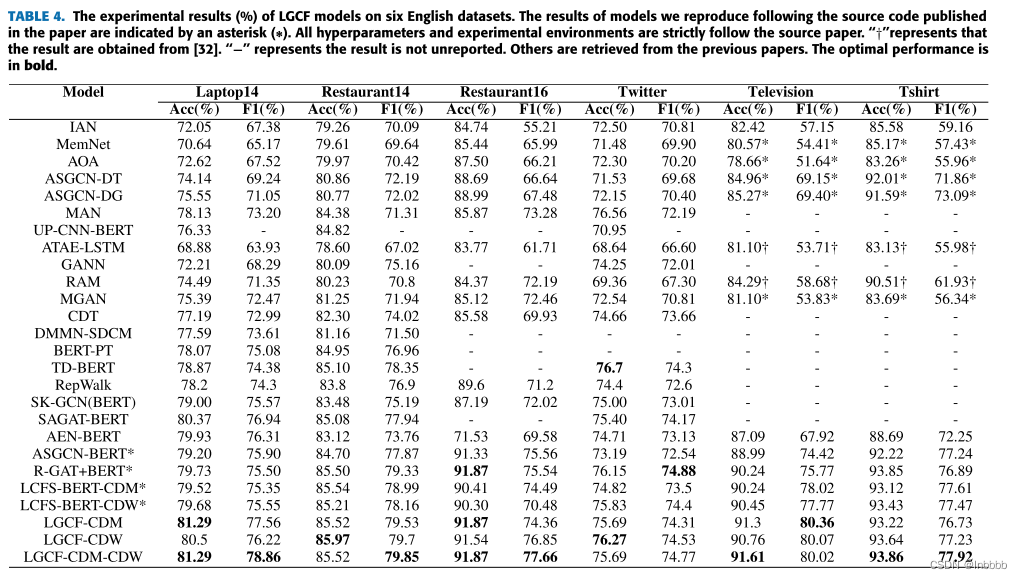

















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









