







在一些对神经网络可解释性的研究中,总是会利用到损失函数对最后一层特征图进行求梯度的操作,例如著名的Grad CAM,因此对于卷积神经网络的理解不能仅仅停留在调包的阶段,我们需要拆解开它求梯度的黑盒。
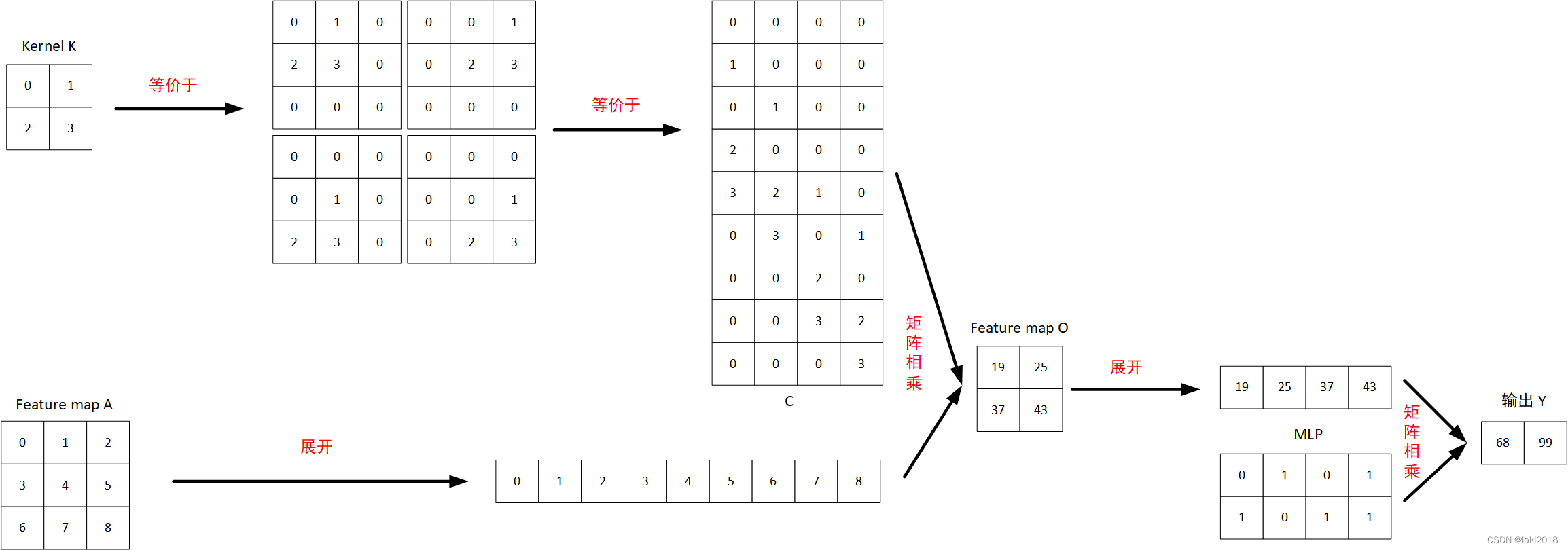
如图所示,假设有一个特征图
A
A
A, 经过一个
2
×
2
2 \times 2
2×2的卷积核
K
K
K操作之后,得到一个新的特征图
O
O
O,再将其展平后经过
M
L
P
MLP
MLP得到一个长度为2的输出向量
Y
Y
Y。
如果想要知道特征图
A
A
A的每个元素对最终输出的贡献大小,就需要计算出
Y
Y
Y对
A
A
A中每个元素的偏导,即
∂
Y
∂
A
\frac{ \partial Y }{ \partial A }
∂A∂Y。
我们整理一下从特征图
A
A
A得到输出
Y
Y
Y的过程,可以写为:
O
=
C
O
N
V
(
A
)
O=CONV(A)
O=CONV(A)
Y
=
M
L
P
(
O
)
Y=MLP(O)
Y=MLP(O)
因此根据链式求导法则,
∂
Y
∂
A
=
∂
Y
∂
O
∂
O
∂
A
\frac{ \partial Y }{ \partial A }= \frac{ \partial Y }{ \partial O} \frac{ \partial O }{ \partial A}
∂A∂Y=∂O∂Y∂A∂O。
以输出
Y
1
=
68
Y_1=68
Y1=68为例,
Y
1
=
0
∗
O
11
+
1
∗
O
12
+
0
∗
O
21
+
1
∗
O
22
Y_1=0*O_{11}+1*O_{12}+0*O_{21}+1*O_{22}
Y1=0∗O11+1∗O12+0∗O21+1∗O22, 因此
∂
Y
1
∂
O
=
[
0
1
0
1
]
\frac{ \partial Y_1 }{ \partial O }=[0 \quad1 \quad0\quad1]
∂O∂Y1=[0101]
再来计算
∂
O
∂
A
=
[
∂
O
11
∂
A
11
∂
O
11
∂
A
12
∂
O
11
∂
A
13
∂
O
11
∂
A
21
…
∂
O
11
∂
A
33
∂
O
12
∂
A
11
∂
O
12
∂
A
12
∂
O
12
∂
A
13
∂
O
12
∂
A
21
…
∂
O
12
∂
A
33
∂
O
21
∂
A
11
∂
O
21
∂
A
12
∂
O
21
∂
A
13
∂
O
21
∂
A
21
…
∂
O
21
∂
A
33
∂
O
22
∂
A
11
∂
O
22
∂
A
12
∂
O
22
∂
A
13
∂
O
22
∂
A
21
…
∂
O
22
∂
A
33
]
=
C
T
\frac{ \partial O }{ \partial A}=\begin{bmatrix} \frac{ \partial O_{11} }{ \partial A_{11}} & \frac{ \partial O_{11} }{ \partial A_{12}} & \frac{ \partial O_{11} }{ \partial A_{13}} & \frac{ \partial O_{11} }{ \partial A_{21}} & \dots & \frac{ \partial O_{11} }{ \partial A_{33}} \\ \frac{ \partial O_{12} }{ \partial A_{11}} & \frac{ \partial O_{12} }{ \partial A_{12}} & \frac{ \partial O_{12} }{ \partial A_{13}} & \frac{ \partial O_{12} }{ \partial A_{21}} & \dots & \frac{ \partial O_{12} }{ \partial A_{33}} \\ \frac{ \partial O_{21} }{ \partial A_{11}} & \frac{ \partial O_{21} }{ \partial A_{12}} & \frac{ \partial O_{21} }{ \partial A_{13}} & \frac{ \partial O_{21} }{ \partial A_{21}} & \dots & \frac{ \partial O_{21} }{ \partial A_{33}} \\ \frac{ \partial O_{22} }{ \partial A_{11}} & \frac{ \partial O_{22} }{ \partial A_{12}} & \frac{ \partial O_{22} }{ \partial A_{13}} & \frac{ \partial O_{22} }{ \partial A_{21}} & \dots & \frac{ \partial O_{22} }{ \partial A_{33}}\end{bmatrix} =C^T
∂A∂O=⎣⎢⎢⎢⎡∂A11∂O11∂A11∂O12∂A11∂O21∂A11∂O22∂A12∂O11∂A12∂O12∂A12∂O21∂A12∂O22∂A13∂O11∂A13∂O12∂A13∂O21∂A13∂O22∂A21∂O11∂A21∂O12∂A21∂O21∂A21∂O22…………∂A33∂O11∂A33∂O12∂A33∂O21∂A33∂O22⎦⎥⎥⎥⎤=CT
最后将结果整合之后,再将形状变换与
A
A
A相同即可,即
[
0
0
1
0
2
4
0
2
3
]
\begin{bmatrix} 0 & 0 & 1\\ 0 & 2 & 4 \\ 0 & 2 & 3\end{bmatrix}
⎣⎡000022143⎦⎤。
以下是以上计算过程的代码,可以发现计算结果和推导是一致的。
import torch
import torch.nn as nn
X = torch.tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]]).reshape(1, 1, 3, 3).float()
X.requires_grad = True
kernel = torch.tensor([[0, 1],
[2, 3]]).reshape(1, 1, 2, 2).float()
conv = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=2, bias=False)
conv.weight.data = kernel
fc = nn.Linear(in_features=4, out_features=2, bias=False)
fc.weight.data = torch.tensor([[0, 1, 0, 1],
[1, 0, 1, 1]]).float()
print(conv(X))
O = fc(torch.flatten(conv(X), start_dim=1))
print(O)
O[0][0].backward()
print(X.grad)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









