







 论文介绍了PFLD,一个基于mobileNetv2的人脸关键点检测模型,特别适用于实时应用场景。模型通过加入几何约束和人脸属性信息来处理局部和全局变化,解决数据不平衡问题。网络结构包括主干分支和辅助分支,用于回归预测68个关键点和欧拉角。实验结果显示模型具有高精度和快速运行速度。然而,实际在手机端的表现可能需要更多数据训练来提升。
论文介绍了PFLD,一个基于mobileNetv2的人脸关键点检测模型,特别适用于实时应用场景。模型通过加入几何约束和人脸属性信息来处理局部和全局变化,解决数据不平衡问题。网络结构包括主干分支和辅助分支,用于回归预测68个关键点和欧拉角。实验结果显示模型具有高精度和快速运行速度。然而,实际在手机端的表现可能需要更多数据训练来提升。
论文:PFLD: A Practical Facial Landmark Detector
Github:http://sites.google.com/view/xjguo/fld
GitHub - polarisZhao/PFLD-pytorch: PFLD pytorch Implementation
论文基于mobilbeNet v2的主干结构,设计了一个快速准确的人脸关键点检测模型,PFLD。其中,PFLD 0.25X仅仅2.1Mb,速度达到了140fps。
难点挑战:
- Local Variation,包括表情,局部光照,遮挡
- Global Variation,包括姿态,图片质量
- Data Imbalance,数据集中类别和属性分布不均匀
- Model Efficiency,模型的大小和计算量
主要贡献:
- 训练过程加入人脸几何约束geometric constraint,使得大角度,难样本,传递更大的loss。
- 加入人脸属性信息(profile-face, frontal-face, head-up, head-down, expression,
and occlusion),解决数据不平衡data imbalance
Loss设计:
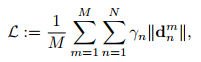
n表示第n个关键点
m表示第m个输入图片,
rn表示随机的权重
d表示loss的距离,例如L1,L2
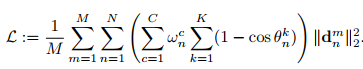
θ1, θ2, and θ3 (K=3),表示预测的欧拉角,yaw,pitch,roll和groundtruth之间的偏差。
w表示人脸属于profile-face, frontal-face, head-up, head-down, expression,occlusion这几种类别里面的分数。
网络结构:
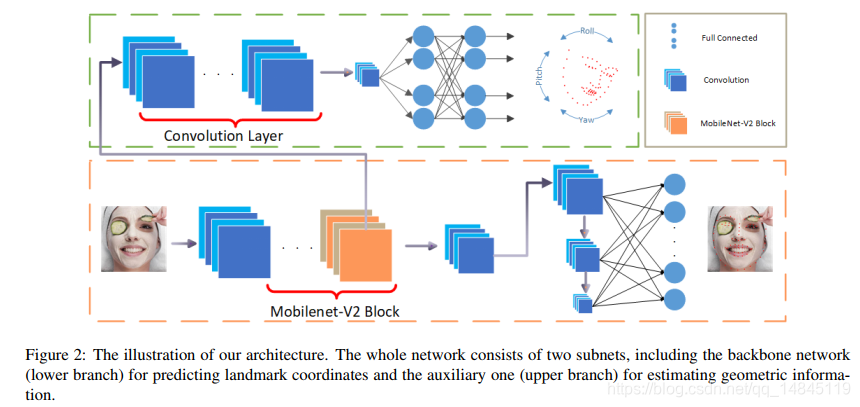
网络输入图片为112*112,数据增强方法包括,随机水平翻转,[-30,30]之间每5度的角度旋转,20%的人脸随机遮挡。
网络以mobileNetv2作为主干网络结构。后续分为绿色和红色2个分支。红色的分支为主干分支,用于回归预测68个关键点,绿色的分支为辅助分支,用于预测欧拉角。对于推理阶段,只使用红色的主干分支。
红色主干分支的结构:
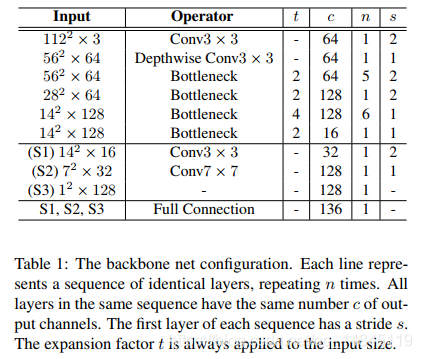
绿色辅助分支的结构:
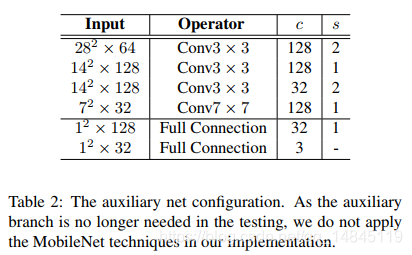
实验结果:

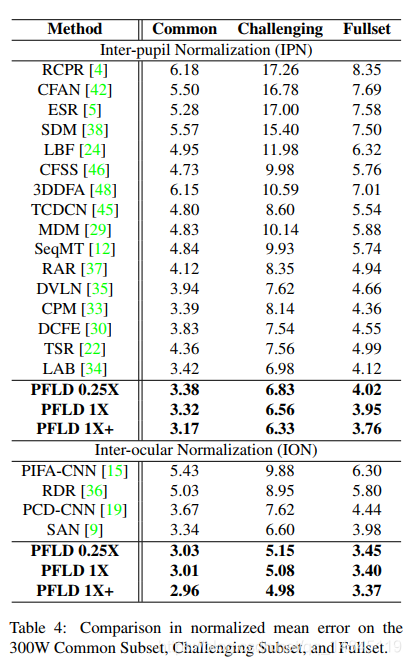

评价指标:
NME:normalized mean error
所有预测关键点和groundtruth关键点之间的L2 Norm,然后除以(关键点的个数*两只眼睛之间的距离),
def compute_nme(preds, target):
""" preds/target:: numpy array, shape is (N, L, 2)
N: batchsize L: num of landmark
"""
N = preds.shape[0]
L = preds.shape[1]
rmse = np.zeros(N)
for i in range(N):
pts_pred, pts_gt = preds[i, ], target[i, ]
if L == 19: # aflw
interocular = 34 # meta['box_size'][i]
elif L == 29: # cofw
interocular = np.linalg.norm(pts_gt[8, ] - pts_gt[9, ])
elif L == 68: # 300w
# interocular
interocular = np.linalg.norm(pts_gt[36, ] - pts_gt[45, ])
elif L == 98:#wflw
interocular = np.linalg.norm(pts_gt[60, ] - pts_gt[72, ])
elif L == 106:#lapa
interocular = np.linalg.norm(pts_gt[66, ] - pts_gt[79, ])
else:
raise ValueError('Number of landmarks is wrong')
rmse[i] = np.sum(np.linalg.norm(pts_pred - pts_gt, axis=1)) / (interocular * L)
return rmse
总结:
- 以mobilenetv2作为主干网络结构,简单实用,模型够小,速度够快,更加贴合实际工业应用。
- 手机端模型实际测试,效果还是差些,可能需要加更多的数据进行训练。

















 2693
2693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









