








 超级会员免费看
超级会员免费看

 VideoCrafter是一个开源工具,用于文本到视频生成和编辑。包括Base T2V、VideoLoRA和VideoControl模型。Base T2V基于LVDM合成逼真视频,VideoLoRA使用LoRA微调生成个性化视频,VideoControl提供条件控制的视频生成。支持Anaconda和xformer环境安装,提供预训练模型和Huggingface演示。
VideoCrafter是一个开源工具,用于文本到视频生成和编辑。包括Base T2V、VideoLoRA和VideoControl模型。Base T2V基于LVDM合成逼真视频,VideoLoRA使用LoRA微调生成个性化视频,VideoControl提供条件控制的视频生成。支持Anaconda和xformer环境安装,提供预训练模型和Huggingface演示。
文章目录
本文于 2023-04-06 翻译转自:https://github.com/VideoCrafter/VideoCrafter
这个 repo 在持续更新,最新信息请前往 repo 查看。
关于 VideoCrafter
A Toolkit for Text-to-Video Generation and Editing
🤗🤗🤗 VideoCrafter是一个用于制作视频内容的开源视频生成和编辑工具箱。
目前包括以下三种 模型:
1. Base T2V: 通用文本生成视频
We provide a base text-to-video (T2V) generation model based on the latent video diffusion models (LVDM).
It can synthesize realistic videos based on the input text descriptions.
我们提供了一个基于潜在视频扩散模型(LVDM)的基础文本到视频(T2V)生成模型,它可以根据输入的文本描述合成逼真的视频。
LVDM : https://yingqinghe.github.io/LVDM/
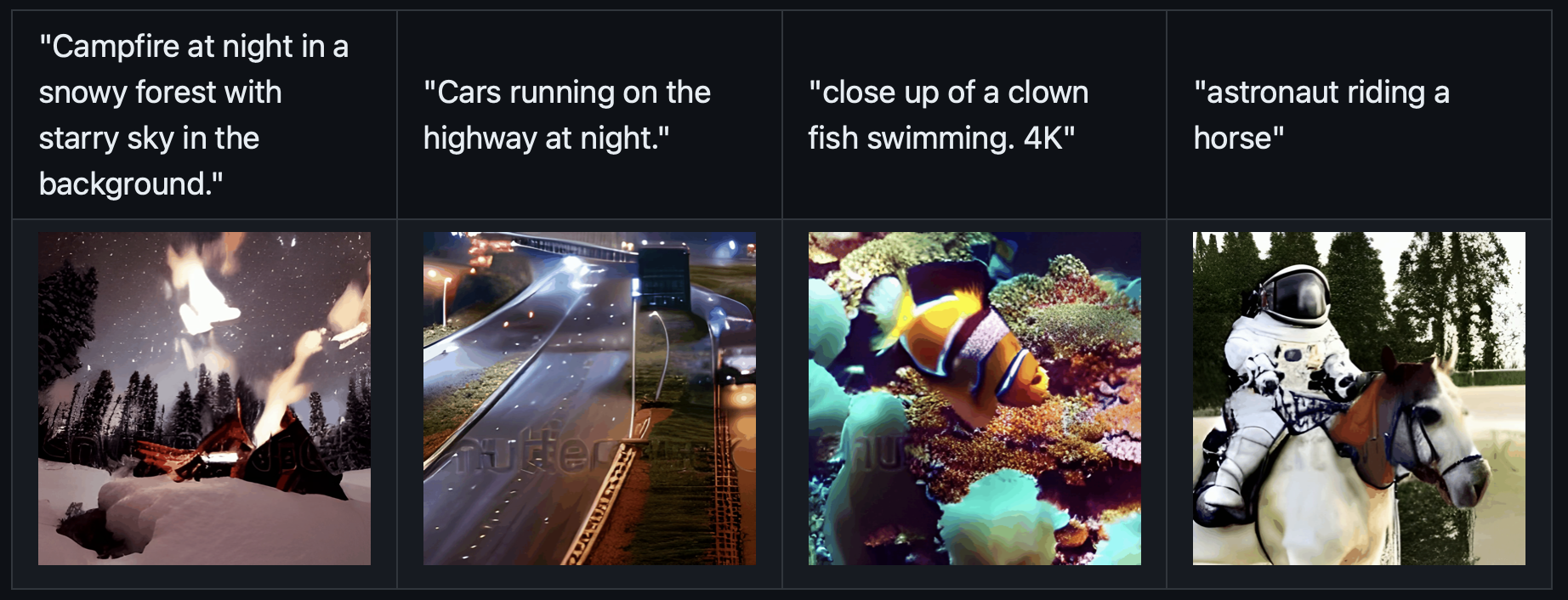
2. VideoLoRA: 使用LoRA生成个性化文本到视频
基于预训练的LVDM,我们可以通过 在一组描述特定概念的视频剪辑或图像上微调 来创建我们自己的视频生成模型。
我们采用LoRA来实现微调,因为它易于训练,并且需要更少的计算资源。
以下是我们在四种不同风格的视频剪辑上,训练的四个 VideoLoRA 模型的生成结果。
通过提供描述视频内容的句子以及LoRA触发词(在LoRA训练期间指定),它可以生成具有所需风格(或主题/概念)的视频。
四个 VideoLoRA 模型,输入 A monkey is playing a piano, ${trigger_word}的结果,:
每个VideoLoRA的触发词在生成结果下方进行注释。
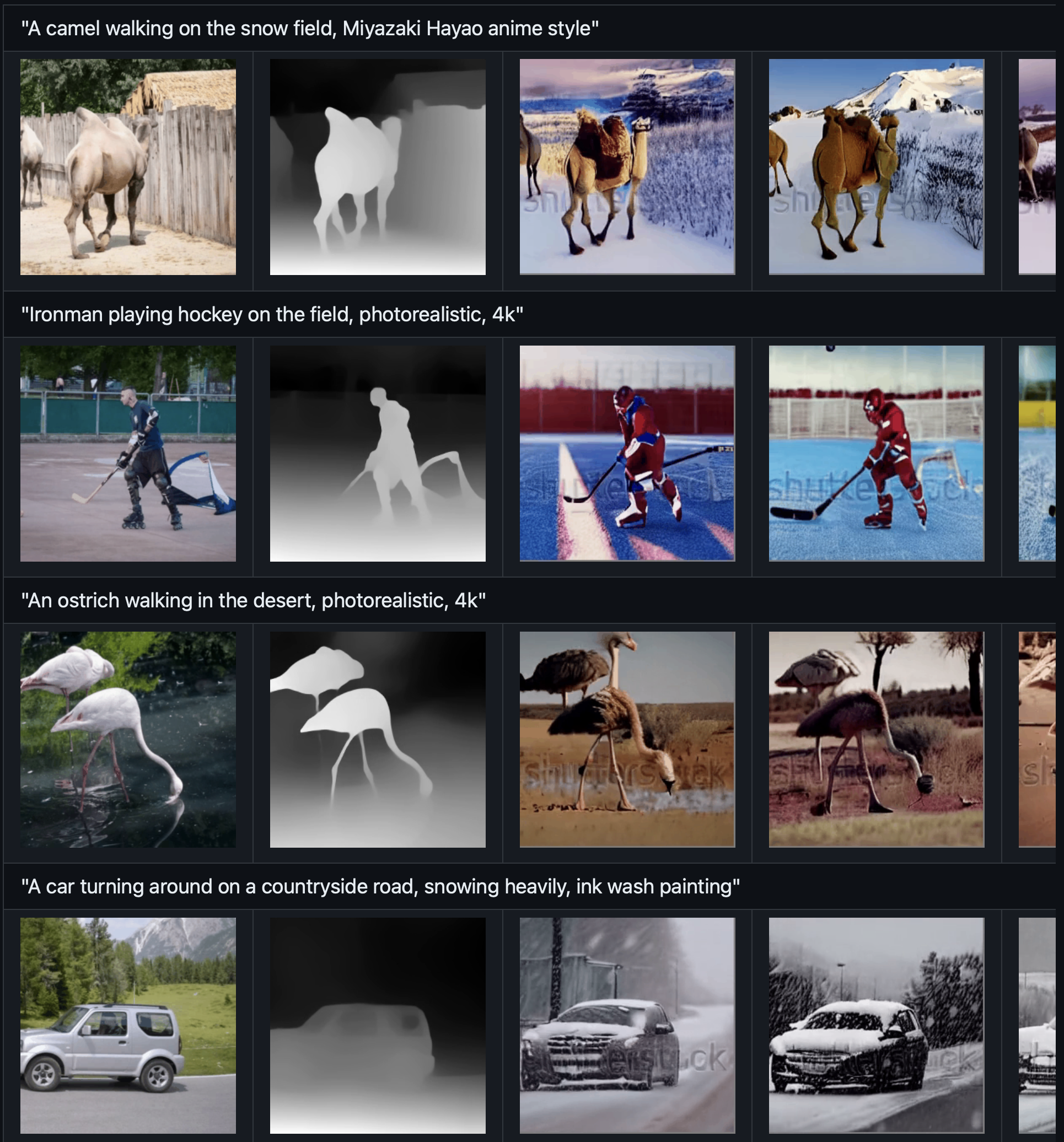
3. VideoControl: 具有更多条件控制的视频生成
为了增强 T2V 模型的可控能力,我们受 T2I适配器的启发,开发了条件适配器。
通过将轻量级适配器模块 插入T2V模型,我们可以获得具有更详细控制信号(如深度)的生成结果。
- T2I-adapter : https://github.com/TencentARC/T2I-Adapter)
输入文本: Ironman is fighting against the enemy, big fire in the background, photorealistic, 4k

🤗🤗🤗 这个repo 将不断被更新,并添加更多功能和模型。请继续关注!
⏳ 后续更新
- Huggingface Gradio demo & Colab
- Technical report
- Release new base model with NO WATERMARK
- Release training code for VideoLoRA
- More customized models
⚙️ 安装
方式一:Anaconda
conda create -n lvdm python=3.8.5
conda activate lvdm
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 -f https://download.pytorch.org/whl/torch_stable.html
pip install pytorch-lightning==1.8.3 omegaconf==2.1.1 einops==0.3.0 transformers==4.25.1
pip install opencv-python==4.1.2.30 imageio==2.9.0 imageio-ffmpeg==0.4.2
pip install av moviepy
pip install -e .
方式二:支持 xformer 的环境
conda create -n lvdm python=3.8.5
conda activate lvdm
pip install -r requirements_xformer.txt
💫 推理
1. Text-to-Video
Google Drive : https://drive.google.com/file/d/13ZZTXyAKM3x0tObRQOQWdtnrI2ARWYf_/view?usp=share_link
Huggingface : https://huggingface.co/VideoCrafter/t2v-version-1-1/tree/main/models
-
通过 Google Drive / Huggingface 下载预训练的 T2V 模型 , 并将
model.ckpt文件放到models/base_t2v/model.ckpt. -
在终端输入下属命令,它将在 GPU 0 中开始运行;
PROMPT="astronaut riding a horse"
OUTDIR="results/"
BASE_PATH="models/base_t2v/model.ckpt"
CONFIG_PATH="models/base_t2v/model_config.yaml"
python scripts/sample_text2video.py \
--ckpt_path $BASE_PATH \
--config_path $CONFIG_PATH \
--prompt "$PROMPT" \
--save_dir $OUTDIR \
--n_samples 1 \
--batch_size 1 \
--seed 1000 \
--show_denoising_progress
2. VideoLoRA
- 通过 Google Drive / Huggingface 下载预训练的 T2V 模型 , 并将
model.ckpt文件放到models/base_t2v/model.ckpt。 - 通过 Google Drive / Huggingface 下载预训练的 VideoLoRA 模型 , 并将
model.ckpt文件放到models/videolora/${model_name}.ckpt。 - 在终端输入下属命令,它将在 GPU 0 中开始运行;
PROMPT="astronaut riding a horse"
OUTDIR="results/videolora"
BASE_PATH="models/base_t2v/model.ckpt"
CONFIG_PATH="models/base_t2v/model_config.yaml"
LORA_PATH="models/videolora/lora_001_Loving_Vincent_style.ckpt"
TAG=", Loving Vincent style"
python scripts/sample_text2video.py \
--ckpt_path $BASE_PATH \
--config_path $CONFIG_PATH \
--prompt "$PROMPT" \
--save_dir $OUTDIR \
--n_samples 1 \
--batch_size 1 \
--seed 1000 \
--show_denoising_progress \
--inject_lora \
--lora_path $LORA_PATH \
--lora_trigger_word "$TAG" \
--lora_scale 1.0
CLICK ME for the TAG of all lora models
-
If your find the lora effect is either too large or too small, you can adjust the
CLICK ME for the visualization of different lora scaleslora_scaleargument to control the strength.
3. VideoControl (后续更新)
🥳 Gallery
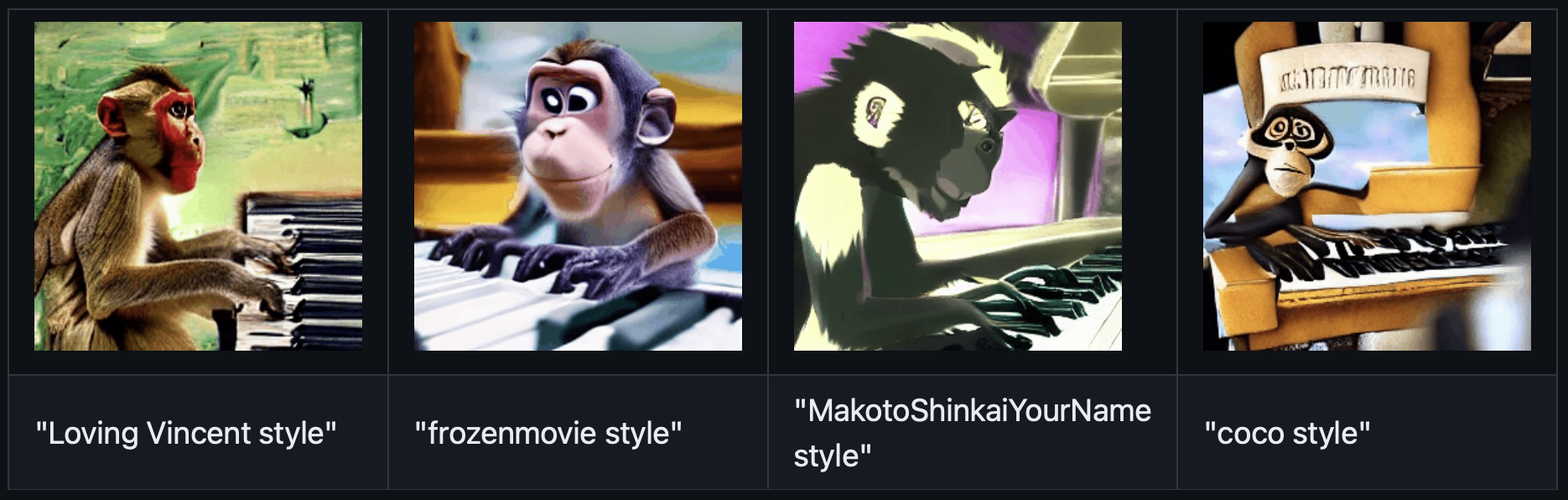
VideoLoRA Models
Loving Vincent Style

Frozen
|
Your Name

CoCo

VideoControl
📭 联系作者
如果你有问题或评价,可以联系:
- Yingqing He, yhebm@connect.ust.hk
- Haoxin Chen, jszxchx@126.com
- Menghan Xia, menghanxyz@gmail.com
2023-04-06

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









