







本文翻译自:Unsloth - Dynamic 4-bit Quantization (2024年12月4日 Daniel & Michael
https://unsloth.ai/blog/dynamic-4bit
我们能否将一个20GB的语言模型缩小到仅5GB,同时不牺牲准确性?使用量化技术!
流行的算法如AWQ、Bitsandbytes、GPTQ和HQQ 旨在压缩模型,但简单的量化 通常会损害准确性,使得模型变得不可用。
我们很高兴地介绍 Unsloth - 动态4位量化,这涉及到 动态选择 不对某些参数进行量化,并且它建立在 BitsandBytes 4位之上。这种方法在仅使用比BnB 4位多10%的VRAM的情况下,实现了显著的精度提升。
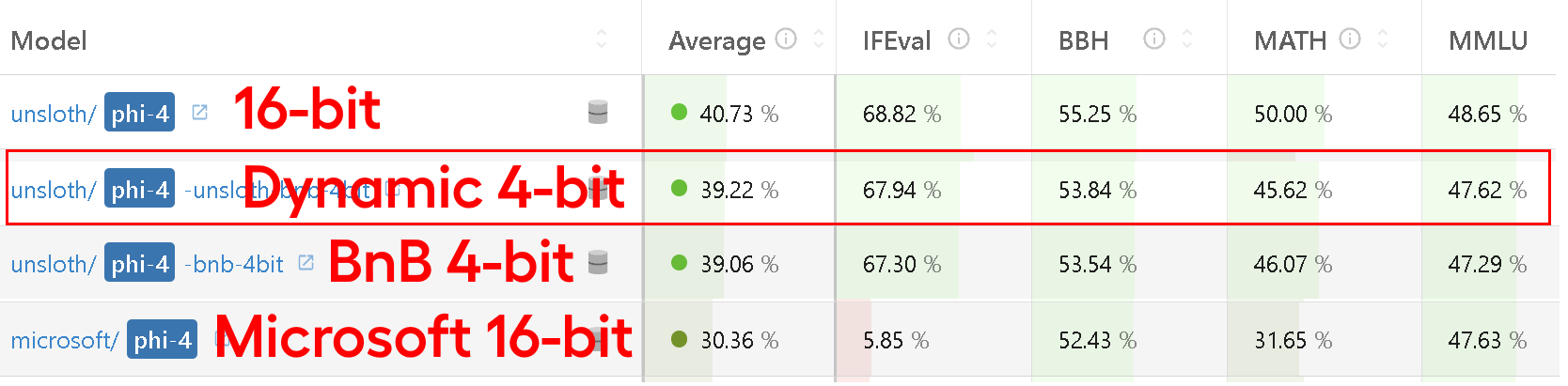
2025年1月更新: 我们动态量化专家的有效性有一个很好的例子,就是我们对微软的Phi-4的最新动态量化。
我们修复了Phi-4中的错误并将我们的动态4位量化提交到了Hugging Face的OpenLLM排行榜。
我们的动态4位模型得分几乎与我们的16位版本一样高——并且远高于标准的Bnb 4位和微软官方的16位模型,特别是在MMLU方面。
我们已经在 Hugging Face 上上传了视觉模型,包括 Llama 3.2 Vision,使用名为 unsloth-bnb-4bit 的新方法进行量化此处。
基于文本的模型,如Llama 3.1(8B)也上传了我们也有一个Colab笔记本微调Llama 3.2(11B)视觉与我们的新的动态量化方法 这里。
下面的测试表明,标准4位量化的性能比原来的16位差,而 Unsloth的动态4位量化 提供了非常准确和可靠的结果。
💔 量化可能会破坏模型
Unsloth 默认使用金标准的 Bitsandbytes 对所有线性层进行优化。例如,Llama 3.2 Vision (11B) 在全精度下使用 20GB,但使用 nf4 时只需 6.5GB——减少了 68%。
例如,将Qwen2 Vision (2B)的量化降低到4位会完全破坏模型。事实表明,较小的模型仅使用6到8位量化,而较大的模型如 8B 及以上则使用4位量化。

| Qwen2-VL-2B-Instruct | Description | Size | Result |
|---|---|---|---|
| 16bit | The image shows a train traveling on tracks. | 4.11GB | ✅ |
| Default 4bit all layers | The image depicts a vibrant and colorful scene of a coastal area. | 1.36GB | ❌ |
| Unsloth quant | The image shows a train traveling on tracks. | 1.81GB | ✅ |
例如,将所有层量化到4位 将使模型将上面的图像描述为 a vibrant and colorful scene of a coastal area,这是错误的。
通过仔细选择 不量化一些参数,模型恢复了其准确性,并且与全精度格式相似,内存使用额外增加了450MB。全精度使用4.11GB。
大多数视觉模型都有一个线性投影,所以如果我们也关闭对所有中间线性投影的量化,我们会看到模型仍然损坏。
| Qwen2 VL (2B) Instruct | Description | Size | Result |
|---|---|---|---|
| Except linear layers | The image depicts a vibrant and colorful scene of a coastal area during a sunny day. | 4.11GB | ❌ |
| Unsloth quant | The image shows a train traveling on tracks. | 1.81GB | ✅ |
在错误分析中,我们看到 Qwen2 VL 2B Instruct 在前几层有大的激活量化错误(左图)。
也存在一个大的峰值,以及激活错误的逐渐下降。我们还看到有一个参数有大的权重量化错误。
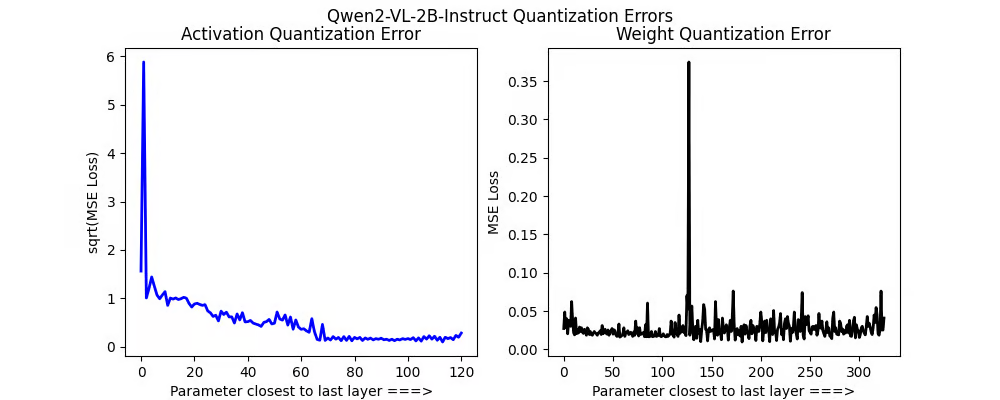
我们上传了我们的动态4位量化模型,用于Qwen2 VL:
🦙 Llama 3.2 Vision 细节
Llama 3.2 11B Vision 对量化不那么敏感。因此,目标是尽可能匹配 16 位精度。

| Llama-3.2-Vision-11B-Instruct | Description | Size | Result |
|---|---|---|---|
| 16bit | The image depicts a serene scene of a wooden bench situated near a body of water, with a group of birds perched on the backrest. The purpose of the image appears to be capturing a peaceful moment in nature. | 19.87GB | ✅ |
| Default 4bit all layers | The image depicts a serene scene featuring a wooden bench with a row of small birds perched on its backrest, set against the backdrop of a body of water. The bench, made of light-colored wood, has a horizontal slat design and is positioned at an angle, facing the water. | 6.54GB | 🆗 No mention of the purpose of the image |
| Unsloth quant | The image depicts a serene scene featuring a wooden bench with a row of small birds perched on its backrest, set against the backdrop of a body of water. The purpose of the image appears to be capturing a peaceful moment in nature. | 7.23GB | ✅Purpose of image returns |
有趣的是,4位量化去除了描述图像目的的句子。
Unsloth的动态量化使用了更多的内存,但再次将图像的目的恢复回来了!!
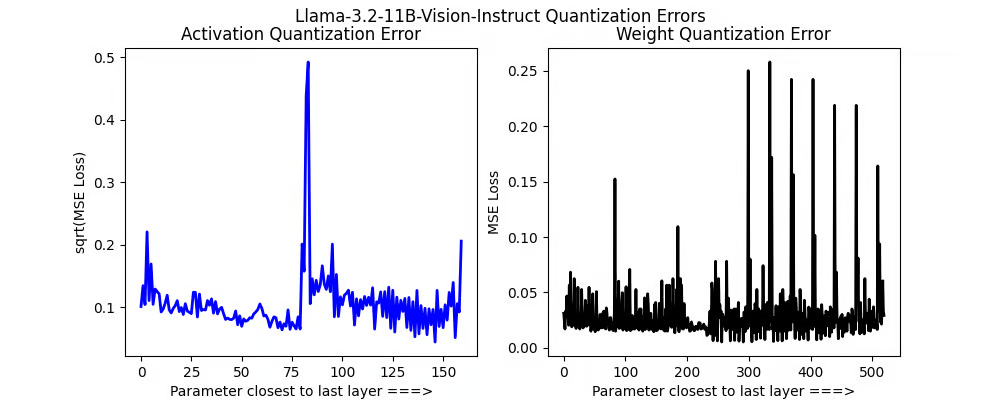
Llama的错误图看起来非常有趣!视觉编码器似乎没有极其大的错误,除了1个大的峰值。权重量化错误看起来非常有趣!我们发现除了第一层之外,所有层的交叉注意力输出投影都不应该进行量化。
我们的动态4位量化Llama 3.2(11B)视觉模型:
Pixtral (12B) 视觉
Pixtral 是最有趣的分析对象!权重量化误差相对温和,尽管有一个较大的峰值。激活误差非常有趣!我们发现整个视觉编码器不应该量化到 4bit,因为它会导致很大的差异。
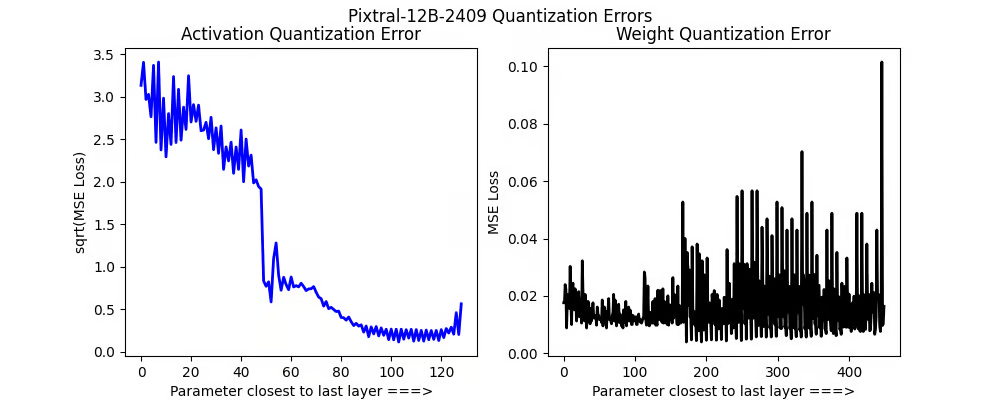
最有趣的是,如果我们使用我们的动态量化方法,它确实使模型变得更好,但它仍然奇怪地不匹配16位全精度。
如果我们放宽约束并捕捉所有“坏”模块,我们就能恢复模型的全部功能!
以下您可以看到4位版本表现不错,但16位版本对X射线的分析更加深入。
我们的动态量化使用了400MB更多的内存,但实际上开始分析X射线,这与完整的4位模型不同。
如果我们再使用3.5GB的内存(这已经相当多了),那么我们就可以完全模拟16位的精度!
我们还将比较使用额外1GB内存的8bit版本,有趣的是,它看起来与4bit版本相似,因此8bit似乎表现不佳。但这确实需要更多的调查!
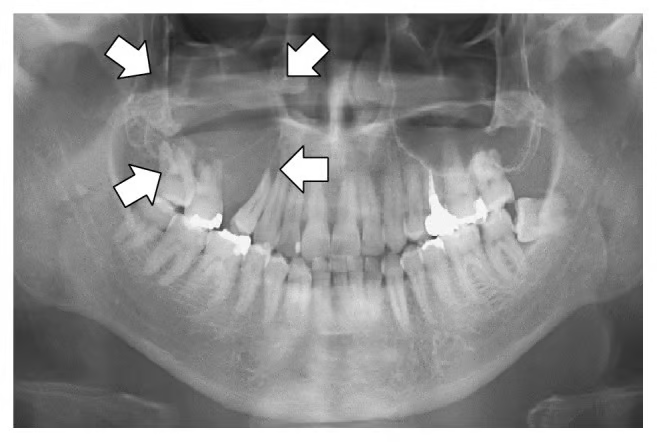
| Pixtral-12B | Description | Size | Result |
|---|---|---|---|
| 16bit | The image is a dental X-ray (radiograph) of a child’s mouth, showing the arrangement of teeth and jaw structure. The X-ray highlights several key features: 1. Upper Arrows: These arrows point to the upper jaw area, likely indicating the presence of unerupted or impacted teeth, which are teeth that have not erupted through the gums but are trapped beneath the surface. | 26.32GB | ✅ |
| Default 4bit all layers | This is a dental X-ray image of a child’s mouth, highlighting several teeth with arrows. The image shows the positions of different types of teeth: primary (baby teeth), secondary (adult teeth), and tertiary (permanent teeth). The primary teeth are already fallen, the secondary teeth are coming out, and the tertiary teeth have not yet come out. | 7.83GB | 🆗 No mention of arrows’ purpose. No detailed analysis. |
| Unsloth quant | This is an X-ray image of a child’s mouth, highlighting several teeth with arrows. The image shows the arrangement and presence of primary (baby) teeth and permanent teeth. The arrows are pointing to specific teeth that may require attention, possibly for removal or other dental treatment. | 8.42GB | 🆗 Much better - analyses the X-ray more. |
| 8bit quant | The image is a dental X-ray of a child’s mouth, highlighting specific areas with arrows. The X-ray shows the arrangement and development of the child’s teeth and jaw structure. The arrows likely indicate areas of concern or interest, such as potential issues with tooth alignment, decay, or other dental problems. | 13.1GB | 🆗Also better than full 4bit - analysis the X-ray. |
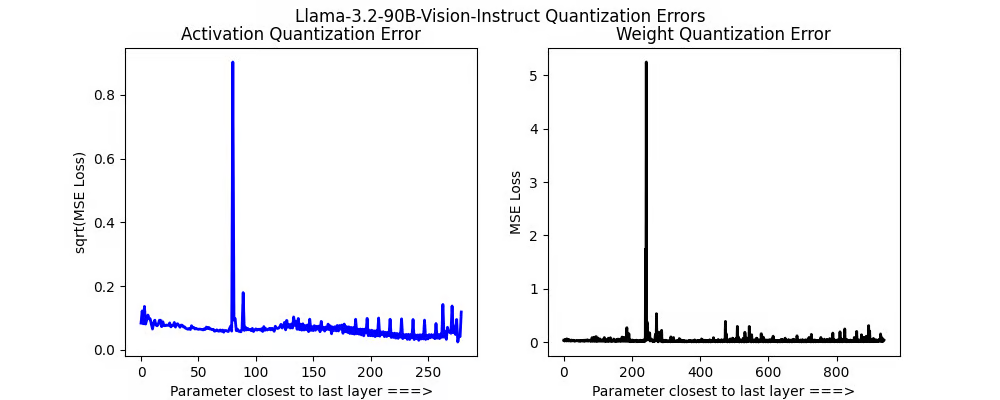
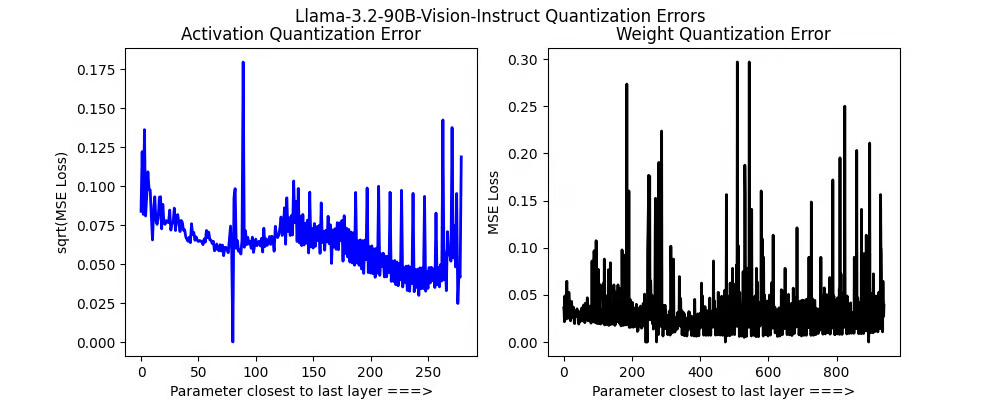
🦙 Llama 3.2 (90B) 视觉指令
对于Llama最大的视觉模型,我们看到了一些峰值,但并不多。来自11B模型的交叉注意力现象似乎要少得多。
2025-03-09(日)



















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











