







0. 简介
在像家庭和仓库这样的部署场景中,人们期望移动机器人能够自主导航较长时间,并以人类操作员直观理解的方式无缝执行任务。本文《GOAT: GOto AnyThing》提出了GOAT(GO To Any Thing),这是一种能够满足这些要求的通用导航系统,具有三个关键特性:a) 多模态:能够处理通过类别标签、目标图像和语言描述指定的目标;b) 终身学习:能够从相同环境中的过去经验中获益;c) 平台无关:可以快速部署在具有不同结构的机器人上。GOAT的实现得益于模块化的系统设计和不断增强的实例感知语义记忆,该记忆不仅跟踪来自不同视角的物体外观,还包括类别级别的语义。这使得GOAT能够区分同类别的不同实例,从而实现通过图像和语言描述指定的目标导航。
1. 引言
自从动物能够移动以来,导航到所需位置——食物、伴侣、巢穴——就成为了动物和人类行为的一个基本方面。导航的科学研究是一个高度跨学科的领域,涉及到许多研究者的贡献,包括动物行为学、动物学、心理学、神经科学和机器人学等。在本文中,我们展示了一种移动机器人系统,该系统受到动物和人类导航中一些最显著发现的启发。
- 认知地图。许多动物保持其环境的内部空间表征。关于这种地图的性质存在激烈的争论——它是以欧几里得意义上的度量形式存在,还是仅仅是拓扑形式——在诺贝尔奖获奖的研究中,认知地图的神经相关性已在海马体中被发现。这表明,纯粹反应式、无记忆的导航系统对于机器人技术来说是不够的。
- 这种内部空间表征是如何获得的? 从人类研究中,有人认为这些表征是通过“基于路线”的知识构建的。在日常或其他情境活动的过程中,我们学习路线的结构——起点、终点、途经点等。随着时间的推移,不同经历中的特征被整合成一个单一的布局表征,即“地图”。对于移动机器人来说,这激励了“终身学习”的一种版本——在移动机器人进行主动搜索和探索的过程中,不断改善内部空间表征。
- 导航是否仅由位置的几何配置驱动? 不,地标的视觉外观在动物和人类导航中发挥着重要作用。这表明需要保持移动机器人空间环境的丰富多模态表征。
让我们具体化一下。考虑一个在未见环境中启动的机器人,如图1所示,假设它被要求找到一张餐桌的图像(目标1)。导航到这个目标需要识别出图片显示的是一张餐桌,并具备对室内空间的语义理解,以便有效地探索家居环境(例如,餐桌不会出现在浴室里)。假设随后机器人被要求去沙发旁的盆栽植物(目标2)。这需要在物理空间中对文本指令进行视觉定位。下一个指令是去水槽(目标3),大写字母强调任何属于水槽类别的物体都是有效目标。在这个例子中,机器人在第一个任务中已经在房子里见过一个水槽,因此它应该记住其位置,并能够规划一条有效的路径到达那里。这要求机器人建立、维护和更新对环境中物体的终身记忆,包括它们的视觉和语言特性以及它们的最新位置。面对任何新的多模态目标,机器人还应该能够查询记忆,以确定目标物体是否已经存在于记忆中,或者是否需要进一步探索。
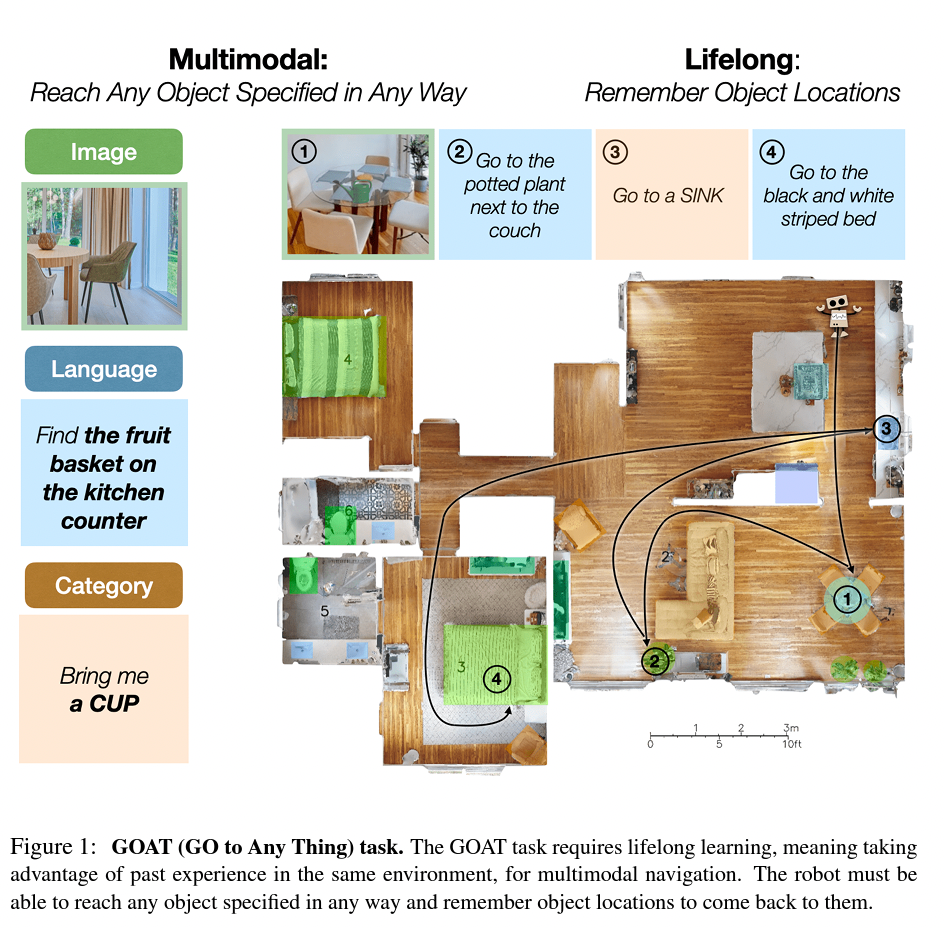
图1:GOAT(GO to Any Thing)任务。 GOAT任务要求终身学习,这意味着在同一环境中利用过去的经验进行多模态导航。机器人必须能够到达以任何方式指定的任何物体,并记住物体的位置以便能够返回。
除了这些多模态感知、探索、终身记忆和目标定位的能力外,机器人还需要有效的规划和控制,以在避免障碍物的同时到达目标。
在本文中,我们提出了“GO to Any Thing”(GOAT),一个具有三个关键特征的通用导航系统:a) 多模态:它可以处理通过类别标签、目标图像和语言描述指定的目标;b) 终身:它利用在同一环境中过去的经验,以物体实例的地图形式(而不是隐式存储在机器学习模型的参数中)随时间更新;c) 平台无关:它可以无缝部署在具有不同形态的机器人上——我们在四足机器人和轮式机器人上部署了GOAT。GOAT的实现得益于实例感知语义记忆的设计,该记忆跟踪不同视角下物体的外观,除了类别级语义。这使得GOAT能够区分同一类别的不同实例,从而实现基于图像和细粒度语言描述的目标导航。随着智能体在环境中花费更多时间,这种记忆不断增强,从而提高了达到目标的效率。
尽管在导航方面有大量的研究工作,但大多数仅在模拟中进行评估或开发专门的解决方案来处理这些任务的子集。经典机器人工作采用几何推理来解决几何目标的导航。随着图像语义理解的进步,研究人员开始使用语义推理来提高在新环境中的探索效率,并处理通过类别、图像和语言指令指定的语义目标。大多数这些方法都是a) 专门针对单一任务(即它们是单模态的),b) 每个回合仅处理单一目标(即不是终身的),c) 仅在模拟中评估(或在初步的现实环境中)。GOAT在这三个方面都超越了这些工作,并以终身的方式处理现实世界中的多个目标规格。这超越了过去仅在一个维度上创新的工作,例如,过去的工作处理一系列目标,但目标仅限于在模拟中是物体目标或图像目标,处理灵活目标规格但仅展示每个回合一个目标的模拟结果,以及在现实世界中展示结果但每个回合仅针对一个物体目标的工作。
受到动物和人类导航的启发,GOAT维护环境的地图以及视觉地标——物体实例的自我中心视图——这些都存储在我们新颖的实例感知物体记忆中。该记忆应能够通过图像和自然语言进行查询,以满足GOAT的多模态要求。我们通过存储视觉地标的原始图像而非特征来实现这一点,从而使我们能够独立利用图像-图像匹配和图像-语言匹配的最新进展。我们使用对比语言-图像预训练(CLIP)进行图像-语言匹配,使用SuperGlue进行图像-图像匹配。CLIP遵循将文本与图像或图像区域关联的悠久历史,并促成了语言条件开放词汇物体检测器的发展。CLIP本身或从CLIP派生的物体检测器最近已被用于机器人任务,例如物体搜索、移动操作和桌面操作。类似地,SuperGlue遵循几何图像匹配的悠久历史,最近的基于学习的方法在某些情况下提高了性能。最近的研究开始在具身环境中评估这些方法,其中机器人必须导航到世界中的图像或与特定物体实例对应的图像。
GOAT的记忆表征遵循过去40年机器人领域场景表征的悠久历史:占用地图(具有几何、显式语义或隐式语义)、拓扑表征和神经特征场。许多这些工作开始使用预训练的视觉-语言特征,如CLIP,并将其直接投影到3D中或在隐式神经场中捕获。参数化表征将环境总结为低维抽象特征,而非参数化表征则将图像集合本身视为一种表征。我们的工作利用了两者的特点。我们构建了一个用于导航到物体的语义地图,同时也存储与发现的物体(地标)相关的原始图像。
2 GoToAnyThing系统架构
2.1 系统概述
图7(A) 展示了GOAT系统的概览。感知系统检测物体实例,在场景的自上而下的语义地图中对其进行定位,并在物体实例记忆中存储每个实例被观察到的图像。当指定一个新目标时,全球策略首先尝试在物体实例记忆中对其进行定位。如果没有定位到任何实例,全球策略将输出一个探索目标。最终,局部策略计算朝向长期目标的行动。
2.2 感知
图7 (B) 显示了感知系统。它以当前的深度图像 D t D_t Dt、RGB图像 I t I_t It 和来自机载传感器的位姿读取 x t x_t xt 作为输入。它使用现成的模型对RGB图像中的实例进行分割。我们使用MaskRCNN [23],其基于ResNet50 [24],并在MS-COCO上进行了预训练,以进行物体检测和实例分割。我们选择MaskRCNN是因为当前的开放集模型,如Detic [62],在早期实验中对常见类别的可靠性较低。我们还估计深度,以填补原始传感器读取中反射物体的孔洞。为了填补深度图像中的孔洞,我们首先使用单目深度估计模型从 I t I_t It 中获得密集的深度估计(我们使用了MiDaS [47] 模型,尽管任何深度估计模型都适用)。由于深度估计模型通常预测相对距离而非绝对距离,我们使用来自 D t D_t Dt 的已知真实深度值来校准预测的深度。具体而言,我们求解一个缩放因子,以最小化估计深度与感测深度之间的均方误差,公式为:
argmin A , b ∑ i ∥ D t , i − A X t , i − b ∥ 2 \text{argmin}_{A,b} \sum_i \|D_{t,i} - AX_{t,i} - b\|^2 argminA,bi∑∥Dt,i−AXt,i−b∥2
其中 D t , i D_{t,i} Dt,i 是来自深度读取 D t D_t Dt 的第 i i i 个深度读取, X t , i X_{t,i} Xt,i 是同一点的深度估计。这个优化可以很容易地作为方程组求解,从而得到一个缩放因子和偏移量,以将估计的深度点投影到绝对距离中。我们使用这些深度估计来处理深度图像中未注册读取的像素。利用上述计算的密集深度,我们将第一人称语义分割投影到点云中,将点云分箱到3D语义体素地图中,最后对高度进行求和以计算2D实例地图 m t m_t mt。对于每个检测到的物体实例,我们还将检测到物体的图像存储为物体实例记忆的一部分。
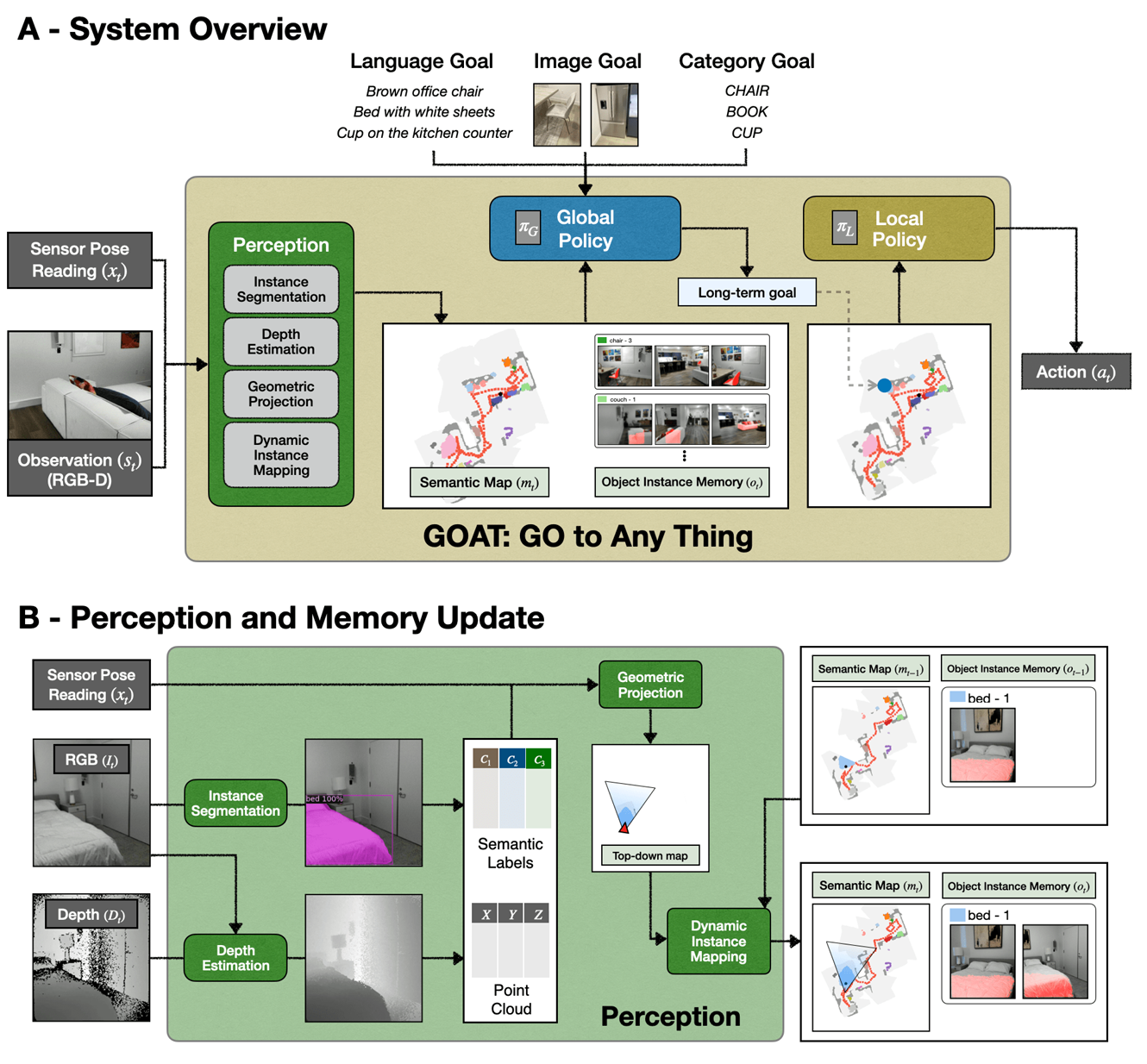
图7: (A) GOAT系统概览。感知系统检测并定位物体实例,全球策略根据机器人是否应该探索或到达已存储的目标输出高层次的导航命令,而局部策略则执行这些命令。
(B) 感知与记忆更新。感知系统处理RGB-D输入以填补深度,分割物体实例,将其投影到自上而下的语义地图中,并在物体实例记忆中存储视图。
2.3 语义地图表示
语义地图(在时间步 t t t 的 m t m_t mt)是环境的空间表示,跟踪物体实例的位置、障碍物和已探索区域。具体而言,它是一个 K × M × M K \times M \times M K×M×M 的整数矩阵,其中 M × M M \times M M×M 是地图大小, K K K 是地图通道的数量。这个空间地图的每个单元对应于物理世界中的 25 cm 2 25 \text{cm}^2 25cm2( 5 cm × 5 cm 5 \text{cm} \times 5 \text{cm} 5cm×5cm)。地图通道 K = C + 4 K = C + 4 K=C+4,其中 C C C 是语义物体类别的数量,其余的4个通道表示障碍物、已探索区域以及智能体的当前和过去位置。如果单元格包含特定语义类别的物体、障碍物或已探索,则地图中的一个条目为非零,具体取决于通道,否则为零。在这种语义地图表示中,前 C C C 个通道存储投影物体的唯一实例ID。地图在每个回合开始时初始化为全零,智能体从地图中心朝东开始。
2.4 对象实例记忆
图8 (A) 显示了物体实例记忆(ot 在时间步 t)。我们的物体实例记忆根据物体在地图中的位置和类别,将跨时间的物体检测聚类为实例。每个物体实例 i i i 被存储为地图中的一组单元 C i C_i Ci,一组以边界框和上下文表示的物体视图 M i M_i Mi,以及一个指示语义类别的整数 S i S_i Si。对于每个输入的RGB图像 I I I,我们检测物体。对于每个检测 d d d,我们使用围绕检测的边界框 I d I_d Id、语义类别 S d S_d Sd,以及基于投影深度的相应地图点 C d C_d Cd。我们将每个实例在地图 C d C_d Cd 上膨胀 p p p 个单位,以获得每个实例的膨胀点集 D d D_d Dd,该点集用于与之前添加到记忆和地图中的实例进行匹配。我们逐对检查每个检测与每个现有物体实例之间的匹配。如果检测 d d d 和实例 i i i 的语义类别相同,并且在地图中的任何投影位置重叠,即 S d = S i S_d = S_i Sd=Si 且 D d ∩ C i ≠ ∅ D_d \cap C_i \neq \emptyset Dd∩Ci=∅,则认为它们匹配。如果存在匹配,我们用新点和新图像更新现有实例
C i ← C i ∪ C d , M i ← M i ∪ { I d } C_i \leftarrow C_i \cup C_d, M_i \leftarrow M_i \cup \{I_d\} Ci←Ci∪Cd,Mi←Mi∪{Id}
否则,使用 C d C_d Cd 和 I d I_d Id 添加一个新实例。
该过程在时间上聚合独特的物体实例,使得新的目标能够轻松与特定实例或类别的所有图像进行匹配。
2.5 全球策略
图8 (B) 显示了全球策略。当向智能体指定一个新目标时,全球策略 π G \pi_G πG 首先搜索物体实例记忆,以查看该目标是否已经被观察到。计算匹配的方法根据目标规格的模态进行调整。对于类别目标,我们简单地检查语义地图中是否存在该类别的任何物体。对于语言目标,我们首先从语言描述中提取物体类别(在我们的实验中通过提示 Mistral 7B [30]),然后将语言描述的 CLIP 特征与我们物体实例记忆中推断类别的每个物体实例的 CLIP 特征进行匹配。类似地,对于图像目标,我们首先使用 MaskRCNN 从图像中提取物体类别,然后使用现成的 SuperGlue 模型将目标图像的关键点与推断类别的每个物体实例的关键点进行匹配。在环境被探索时,如果匹配分数超过某个阈值(CLIP 为 0.28,SuperGlue 为 6.0),我们认为物体实例与目标匹配;而当环境完全探索后,我们选择具有最高相似度分数的物体实例。选择实例后,其在自上而下地图中的存储位置被用作长期点导航目标。如果没有实例被定位,全球策略则输出一个探索目标。我们使用基于边界的探索 [60],选择最近的未探索区域作为目标。
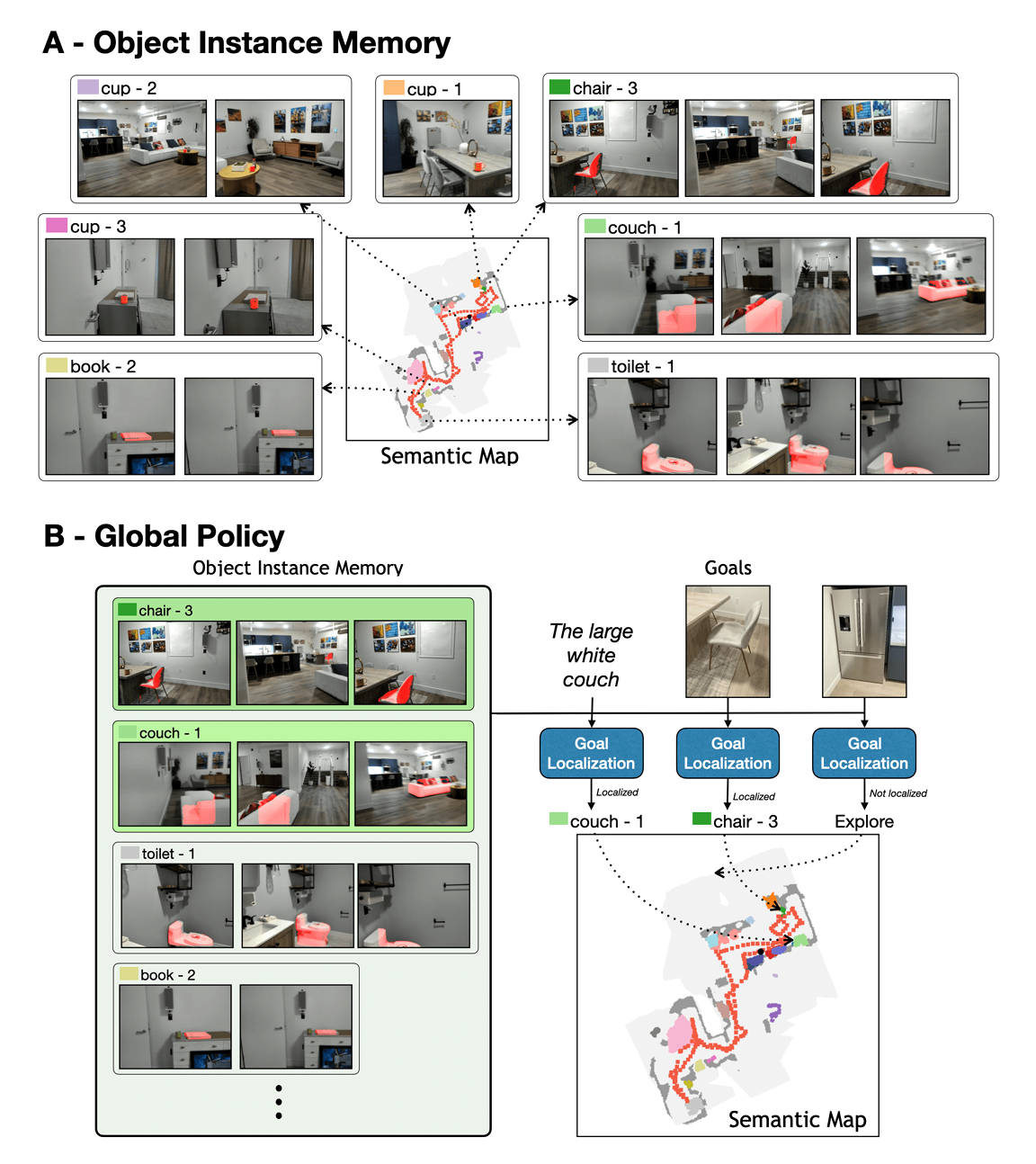
图8: (A) 物体实例记忆。我们根据物体在语义地图中的位置和类别,将物体检测及其观察到的图像视图聚类为实例。 (B) 全球策略。当指定一个新目标时,全球策略首先尝试在物体实例记忆中对其进行定位。如果没有实例被定位,则输出一个探索目标。
2.6 局部策略
给定全球策略 π G \pi_G πG 输出的长期目标,局部策略 π L \pi_L πL 使用快速行进法(Fast Marching Method)规划通往该目标的路径。在 On the Spot 机器人上,我们使用内置的点导航控制器沿着这条路径到达航点。在没有此类内置控制器的 Stretch 机器人上,我们以确定性方式规划沿着这条路径的第一个低级动作,如文献 [19] 所述。
3. 总结
本研究展示了GOAT(Go to Any Thing)系统在多模态导航任务中的应用,特别是在未见环境中定位和导航到目标物体的能力。研究团队在波士顿动力公司的Spot机器人和Hello Robot Stretch机器人上进行了定性和定量的实验。总共在9个真实家庭中进行了大规模的定量实验,涉及超过200种不同的物体实例。GoToAnyThing任务被定义为机器人在随机环境中依次到达未见目标物体。机器人在每个时间步接收来自RGB图像、深度图像和位姿读数的观察数据,并根据当前的目标物体进行导航。机器人能够通过维护一个记忆系统来提高导航效率。


















 4332
4332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











