







具身智能VLA方向模型fine-tune(单臂)
- 文章概述
-
- 数据集
- 机械臂
- VLA模型
- 数据集
-
- VLA数据集要有什么
- npy格式
-
- 用npy保存实时原始数据
- 支持tfds读取的npy文件
- RLDS格式
- hdf5格式
- VLA模型
-
- openVLA
-
- 准备数据集
- 转化数据部分
- prismatic/vla/datasets/rlds/oxe/transforms.py:对应注册一个函数(数据读取)
- prismatic/vla/datasets/rlds/oxe/configs.py:一个数据集格式(将数据对应到模型接口)
- prismatic/vla/datasets/rlds/oxe/transforms.py:一段描述(将我们的数据集绑定到我们的数据集格式上)
- 微调模型
- 部署测试
- RDT
-
- 推荐提前操作
- 准备数据集
- 转化数据格式
-
- 按照自己的数据修改data/hdf5_vla_dataset.py
- 微调模型
- 部署测试
-
- scripts/agilex_model.py
- 编写自己的inference代码:scripts/my_inference.py
- scripts/encode_lang.py
文章概述
最近几个月导师让我来研究下具身智能,说这个很火,经过三个月和师兄两人零基础的摸索,终于把VLA方向弄明白了一些,于是写个文章来记录下整个过程,相当于一个新手教程把哈哈。
本文章主要聚焦于:数据集制作,机械臂通讯,openVLA和RDT的微调以及部署。
数据集
目前VLA方向的主要数据集是OXE(Open-X-Ebodiedment),这个数据集有各种各样机械臂,各种各样数据保存格式,主哟适用于大模型的pre-training,拥有让模型有初步的language&vison to action的认知,为什么目前看到的所有VLA都需要fine-tune呢,因为不同视角下运动的xyz轴的方向都不同,并且模型的输出尺度不同,我们需要让模型迁移到当前的现实场景中。
Open-X-Embodiedment
机械臂
老板还是很愿意花钱的,给我们配备的是RealMan的机械臂,这个机械臂是通过网口通讯的,可以实时获取机械臂的相关状态,并且实时操控机械臂的移动,不过目前只在单臂测试,下一阶段才是双臂,到时候有了结果会再发一篇文章的。
VLA模型
VLA模型顾名思义就是vision-language-action model,即用视觉+语言指令作为输入,让模型来决定的操作动作。
数据集
VLA数据集要有什么
- 运动相关:保存每次行动的坐标+欧拉角/关节角/运动变化量等
- 视觉图像:每一次运动时你要输入模型的图像(第一/第三视角)
知道了需要保存的数据,那么数据集该怎么制作,用什么标准保存?实际上在我看来,数据集保存格式只要遵守:数据结构清晰,数据精度不变,存读方便这三点就足够了,目前我接触到的主流有四种格式:.npy,.whl,.hdf5,tfds(这个是一个统一格式,不是后缀,对于OXE数据集,是叫做RLDS,保存是使用tfds的接口来做的),在这里我之展示我用的三种格式.npy,.hdf5,tfds,whl和npy基本一致,就不展示了。
空讲无益,直接读取数据展示直观点。
npy格式
用npy保存实时原始数据
这是我们第一次制作数据集用的保存格式,因为转成tfds格式官方给出的方法是通过npy转化,不过我们保存的这个是原始数据,不能直接转化为tfds文件,我们是每一次运动保存一个npy文件,实际上在所有的数据集中,单次任务的所有数据应该用一次observation来保存。
import PIL.Image
import cv2
import numpy as np
import PIL
class CollectData:
def __init__(self,arm_union,imgs,gripper):
self.joint = arm_union["joint"]
self.imgs = imgs
self.gripper = gripper
self.pos = arm_union["pose"]
def write(self,path, index):
"""将数据保存为npy文件"""
# 收集数据
data = {
'joint': np.array(self.joint, dtype=np.float32),
'pose': np.array(self.pos, dtype=np.float32),
'image': np.array(self.imgs[0]),
'wrist_image': np.array(self.imgs[1]),
'depth_image':np.array(self.imgs[2]),
'gripper': self.gripper # 将gripper转化为字典
}
# image = PIL.Image.fromarray(self.imgs)
cv2.imwrite(path+str(index)+'.jpg', self.imgs[0])
cv2.imwrite(path+'wrist'+str(index)+'.jpg', self.imgs[1])
depth_colorized = cv2.applyColorMap(cv2.convertScaleAbs(self.imgs[2], alpha=0.03), cv2.COLORMAP_JET)
cv2.imwrite(path+'depth'+str(index)+'.jpg', self.imgs[2])
# 保存为.npy文件
np.save(path+"targ"+str(index), data)
很明显,我们这里保存的每个npy文件里都有data这个字典的对应存储的数据,解释下对应数据:
- joint:关节角,每个关节旋转的角度(rad)
- pose:末端坐标,即夹爪的位置(m)
- image:第三人称视角图片
- wrist_image:因为是单臂,所以只有一个wrist_image,是在末端的第一人称视角,最好看得到夹爪
- depth_image:目前主流vla都没有使用深度参数,不过保存也没事(m)
- gripper:夹爪开合度,0~1,1表示完全张开,0表示完全闭合
注意!!!后面的所有数据都是从本格式npy出发转化的。
支持tfds读取的npy文件
前文说到,所有的标准格式都应该一次完整任务存储到一个文件里,而上面的npy格式是这样的:
{ask_name}->0->targ1.npy,targ2.npy.......targ{end}.npy
1->targ1.npy,targ2.npy.......targ{end}.npy
......
instruction.txt(一段描述任务的文字,英文,做完任务后手动添加的)
因此我们需要先按照tfds要求,先将这些数据对应每一次任务整理到一个文件中。
from typing import Iterator, Tuple, Any
import os
import glob
import numpy as np
import pdb
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
def list_files_and_folders(path):
# 获取当前目录下的所有文件和文件夹
episode = []
for entry in os.listdir(path):
entry_path = os.path.join(path, entry) # 构建完整的路径
for e in os.listdir(entry_path):
if e.endswith(".npy"):#找到对应的npy文件
data = np.load(os.path.join(entry_path, e), allow_pickle=True).item()
gripper = data["pose"]
print(gripper)
def data_transform(path, embed,language_instruction,begin,begin_val):
print(language_instruction)
language_embedding = embed([language_instruction])[0].numpy()
# print(language_embedding)
subfolders = [f for f in os.listdir(path) if os.path.isdir(os.path.join(path, f))] # 获得当前文件夹下所有子文件夹
for i in range(len(subfolders)): # 遍历所有子任务(目前10个)
subfolder_name = f"{i}"
subfolder_path = os.path.join(path, subfolder_name)
last_state = np.zeros((7))
tar = 0
# print(subfolders[i])
if os.path.isdir(subfolder_path): # 确保是文件夹
episode = []
npy_files = [f for f in os.listdir(subfolder_path) if f.endswith('.npy')]#获得所有.npy文件
for j in range(1,len(npy_files)+1):# 遍历所有.npy文件
npy_file_path = os.path.join(subfolder_path,f'targ{j}.npy')
# print(f'targ{j}.npy')
data = np.load(npy_file_path, allow_pickle=True).item()
state = np.array(data["pose"])# x,y,z,rx,ry,rz
state = np.append(state, data["gripper"])# 添加一个张开度0~1
state = state.astype(np.float32)
# pose = np.array(data["pose"])
action = np.zeros((7)) #初始化action,这个是六个关节角+夹爪开合度
# 计算action
if j == 1:
pass #默认全0,没有相对变化
else:
action = (state - last_state) #rad/s
if action[6]>0.1:
tar = 1
elif action[6]<-0.1:
tar = 0
action[6] = tar
state[6] = action[6]
#pdb.set_trace()
action = action.astype(np.float32)
last_state = state
episode.append({
'observation': {
'image': data['image'],
# 'wrist_image': data['wrist_image'],
'state': state,
#x,y,z,rx,ry,rz
},
'action': action,
'discount': 1.0,
'reward': float(j == (len(npy_files))),
'is_first': 1 if j==1 else 0,
'is_last': 1 if j==(len(npy_files)) else 0,
'is_terminal': j == (len(npy_files)),
'language_instruction': language_instruction,
'language_embedding': language_embedding,
})
sample = {
'steps': episode,
'episode_metadata': {
'file_path': f"{subfolder_path}.pkl"
}
}
# print("success")
# print(sample)
if i%10 > 1:
# 检查目录是否存在,如果不存在则创建目录
os.makedirs("./data/train/", exist_ok=True)
np.save(f"./data/train/episode_{begin}.npy", episode)
begin += 1
print(begin)
else:
# 检查目录是否存在,如果不存在则创建目录
os.makedirs("./data/val/", exist_ok=True)
np.save(f"./data/val/episode_{begin_val}.npy", episode)
begin_val += 1
return begin,begin_val
# 获取当前路径
# current_path = "./midSmallBottle_ToBetween"
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder-large/5")
# begin = 10
# end =19
# data_transform(current_path,embed,"Rotate the box counterclockwise by 90 degrees",begin,end)
subfolders = [f for f in os.listdir("./") if os.path.isdir(os.path.join("./", f))]
begin = 0
begin_val = 0
for folder in subfolders:
if folder=="data":
continue
current_path = os.path.join("./",folder)
instruction_path = os.path.join(current_path,"instruction.txt")
with open(instruction_path, 'r') as file:
content = file.read()
begin,begin_val = data_transform(current_path,embed,content,begin,begin_val)
这个代码的执行文件结构如下图所示:

通过执行DatTransform.py,就能在当前目录下按照tfds的要求生成一个./data/train和./data/val的文件夹,里面存好对应的训练需要的参数,需要注意的是,运行该文件需要翻墙,因为需要从tfhub上获取文字编码模型。
RLDS格式
OXE数据集是使用tfds接口保存后的,该数据格式被叫做RLDS:RLDSgithub
要讲自己的npy数据转为RLDS,就要先根据openVLA作者给出的一个github示例来改:
RLDS_datasets_example
主要操作是在./example_dataset/下,我们需要根据自己的npy保存数据格式来对应修改数据的格式,例如我的numpy中的图片是1280*720的,就要在对应的地方修改图片尺寸(64,64,3)改为(720,1280,3)。
需要注意,example_dataset和对应.py文件和class ExampleDataset需要分别用下划线间隔命名法和驼峰命名法对齐。例如我的数据集希望叫./finetune_1_dataset,那么py文件名就要为finetune_1_dataset_dataset_builder.py,对应类名要改为class Finetune1Dataset。
有的数据在训练openVLA时不需要,例如wrist_image,可以直接删去,但是如果收集了对应的数据,那么可以保留。
不懂怎么制作能直接转为RLDS格式数据的可以看我上面写的部分:支持tfds读取的npy文件

hdf5格式
hdf5是我们在复现RDT(Robotics-Diffusion-Transformer)时接触到的,是原作者使用的fine-tune数据格式。

附带上这个读取的py文件:
import h5py
import numpy as np
import cv2
import io
def print_hdf5_group_info(group, indent=0):
"""
递归打印HDF5 Group的详细信息。
跳过 'instruction' 数据集。
"""
for key in group.keys():
if key == 'instruction': # 跳过 'instruction'
continue
item = group[key]
indent_str = ' ' * indent
if isinstance(item, h5py.Group):
print(f"{indent_str}Group: {key}")
print_hdf5_group_info(item, indent + 2) # 递归进入子Group
elif isinstance(item, h5py.Dataset):
print(f"{indent_str}Dataset: {key}")
print(f"{indent_str} Shape: {item.shape}, dtype: {item.dtype}")
# 对于标量数据集,直接打印其值
# if item.shape == ():
# print(f"{indent_str} Sample data: {item[()]}") # 直接访问标量数据集
# else:
# # 对于普通的数据集,打印前5个元素
# print(f"{indent_str} Sample data (first 5 elements): {item[:5]}")
def display_image_from_bytes(img_bytes):
"""
解码二进制压缩图像数据并显示图像。
Args:
img_bytes (bytes): 二进制压缩图像数据。
"""
# 使用 OpenCV 解码压缩的图像数据
nparr = np.frombuffer(img_bytes, np.uint8)
print(len(nparr))
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR) # 解码为彩色图像
if img is not None:
cv2.imshow("Decoded Image", img)
cv2.waitKey(10)
else:
print("Image decoding failed.")
def print_hdf5_file_info_and_display_images(file_path):
"""
读取HDF5文件中的所有数据,包括图像、状态、动作等,并展示图像。
跳过 'instruction' 数据集,并且正确解析嵌套在 'observations' 中的数据。
Args:
file_path (str): HDF5文件路径。
"""
with h5py.File(file_path, 'r') as f:
# 打印文件结构
print("HDF5 File Structure:")
print_hdf5_group_info(f) # 递归打印HDF5结构
print("-" * 40)
# 遍历所有数据集
print(f.keys())
for key in f.keys():
# 跳过 instruction 数据集
if key == 'instruction':
continue
dataset = f[key]
# 如果数据集是 observations,解析内部的数据
if key == 'observations':
print("Parsing nested observations data:")
# 获取嵌套数据
if 'qpos' in dataset:
print(f"qpos shape: {dataset['qpos'].shape}")
print(f"Sample qpos data (first 5 elements): {dataset['qpos'][:5]}")
if 'effort' in dataset:
print(f"effort shape: {dataset['effort'].shape}")
print(f"Sample effort data (first 5 elements): {dataset['effort'][:5]}")
if 'qvel' in dataset:
print(f"qvel shape: {dataset['qvel'].shape}")
print(f"Sample qvel data (first 5 elements): {dataset['qvel'][:5]}")
if 'images' in dataset:
# 解析图片数据
print("Parsing images in observations:")
for image_key in dataset['images']:
img_data = dataset['images'][image_key][:]
print(f"Displaying images from {image_key}:")
for i, img_bytes in enumerate(img_data):
display_image_from_bytes(img_bytes)
else:
print(f"\nDataset: {key}")
print(f"Shape: {dataset.shape}, dtype: {dataset.dtype}")
# 打印前5个数据样本
print(f"Sample data (first 5 elements): {dataset[:5]}")
# 等待按键关闭所有窗口
cv2.waitKey(0)
cv2.destroyAllWindows()
# 使用示例:读取指定路径下的HDF5文件并打印内容和显示图像
file_path = "episode_1.hdf5"
print_hdf5_file_info_and_display_images(file_path)
通过这个文件就能可视化读取RDT作者的数据集了,里面机械臂的运动image会直接通过cv2.imshow可视化。
那么该如何从npy原始数据生成一个hdf5数据集呢,接下来给出我们自己的转化代码:
from typing import Iterator, Tuple, Any
import os
import glob
import numpy as np
import h5py
import cv2
def list_files_and_folders(path):
# 获取当前目录下的所有文件和文件夹
episode = []
for entry in os.listdir(path):
entry_path = os.path.join(path, entry) # 构建完整的路径
for e in os.listdir(entry_path):
if e.endswith(".npy"): # 找到对应的npy文件
data = np.load(os.path.join(entry_path, e), allow_pickle=True).item()
gripper = data["pose"]
print(gripper)
def images_encoding(imgs):
encode_data = []
padded_data = []
max_len = 0
for i in range(len(imgs)):
success, encoded_image = cv2.imencode('.jpg', imgs[i])
jpeg_data = encoded_image.tobytes()
encode_data.append(jpeg_data)
# encode_data.append(np.frombuffer(jpeg_data, dtype='S1'))
max_len = max(max_len, len(jpeg_data))
# padding
for i in range(len(imgs)):
padded_data.append(encode_data[i].ljust(max_len, b'\0'))
return encode_data,max_len
def data_transform(path, language_instruction, begin):
subfolders = [f for f in os.listdir(path) if os.path.isdir(os.path.join(path, f))] # 获得当前文件夹下所有子文件夹
for i in range(len(subfolders)): # 遍历所有子任务(目前10个)
subfolder_name = f"{i}"
subfolder_path = os.path.join(path, subfolder_name)
# 存储hdf5要使用的数据
qpos = []
actions = []
cam_high = []
cam_right_wrist = []
past_state = np.zeros(7)
if os.path.isdir(subfolder_path): # 确保是文件夹
episode = []
npy_files = [f for f in os.listdir(subfolder_path) if f.endswith('.npy')] # 获得所有.npy文件
for j in range(1, len(npy_files) + 1): # 遍历所有.npy文件
npy_file_path = os.path.join(subfolder_path, f'targ{j}.npy')
data = np.load(npy_file_path, allow_pickle=True).item()
state = np.array(data["pose"]) # x,y,z,rx,ry,rz
# state = np.append(state, data["gripper"]) # 添加一个张开度0~1
state = state.astype(np.float32)
pos = np.append(state,data["gripper"])
qpos.append(pos)
if j == 1:
pass
elif j == len(npy_files):
action = state - past_state
action=np.append(action, data["gripper"])
actions.append(action)
actions.append(action) # 最后一次轨迹没有预测,就用最后一次的轨迹本身作为预测
else:
action = state - past_state
action=np.append(action, data["gripper"])
actions.append(action)
cam_high.append(data['wrist_image'])
cam_right_wrist.append(data['image'])
past_state = state
hdf5path = os.path.join(path, f'episode_{i}.hdf5')
with h5py.File(hdf5path, 'w') as f:
f.create_dataset('action', data=np.array(actions))
obs = f.create_group('observations')
image = obs.create_group('images')
obs.create_dataset('qpos',data=qpos)
# 图像编码后按顺序存储
cam_high_enc,len_high = images_encoding(cam_high)
cam_right_wrist_enc,len_right = images_encoding(cam_right_wrist)
image.create_dataset('cam_high', data=cam_high_enc, dtype=f'S{len_high}')
image.create_dataset('cam_right_wrist', data=cam_right_wrist_enc, dtype=f'S{len_right}')
begin += 1
print(f"proccess {i} success!")
return begin
subfolders = [f for f in os.listdir("./") if os.path.isdir(os.path.join("./", f))]
begin = 0
for folder in subfolders:
if folder == "data":
continue
current_path = os.path.join("./", folder)
instruction_path = os.path.join(current_path, "instruction.txt")
with open(instruction_path, 'r') as file:
content = file.read()
begin = data_transform(current_path, content, begin)
这个代码和原始.npy数据转支持tfds接口读取的.npy数据的代码几乎相同,不同的是改了一下数据保存的形式,去除掉了语言编码,但是加入了图像的jpeg编码。
VLA模型
大致讲完了数据集,我们就要开始准备fine-tune VLA模型了,目前我们已经完成了openVLA和RDT的fine-tune,所以我们将会对这两个模型的fine-tune细节进行分析,并展示我们的fine-tune步骤。
模型特点:
| openVLA | RDT | |
|---|---|---|
| 机械臂 | 单臂 | 支持双臂/车轮运动 |
| 模型类型 | self regression | diffusion |
| 视觉 | 单视角 | 支持多视角,双臂为三视角 |
| 输出动作 | EEF(末端坐标+欧拉角) | 支持多种形式,EEF/joint angle等 |
| 预测 | 单帧单动作 | 单帧一个chunk size(官方模型为接下来64步) |
openVLA
网址:openVLA官网
这个模型的表现其实不是很好,但是很适合作为入门的模型,模型局限于单视角+单臂,导致没有太多的调整空间。是一个很经典的拼多多模型,主要贡献在于验证了用VLM作为主干网络,进行VLA模型搭建的可行性。
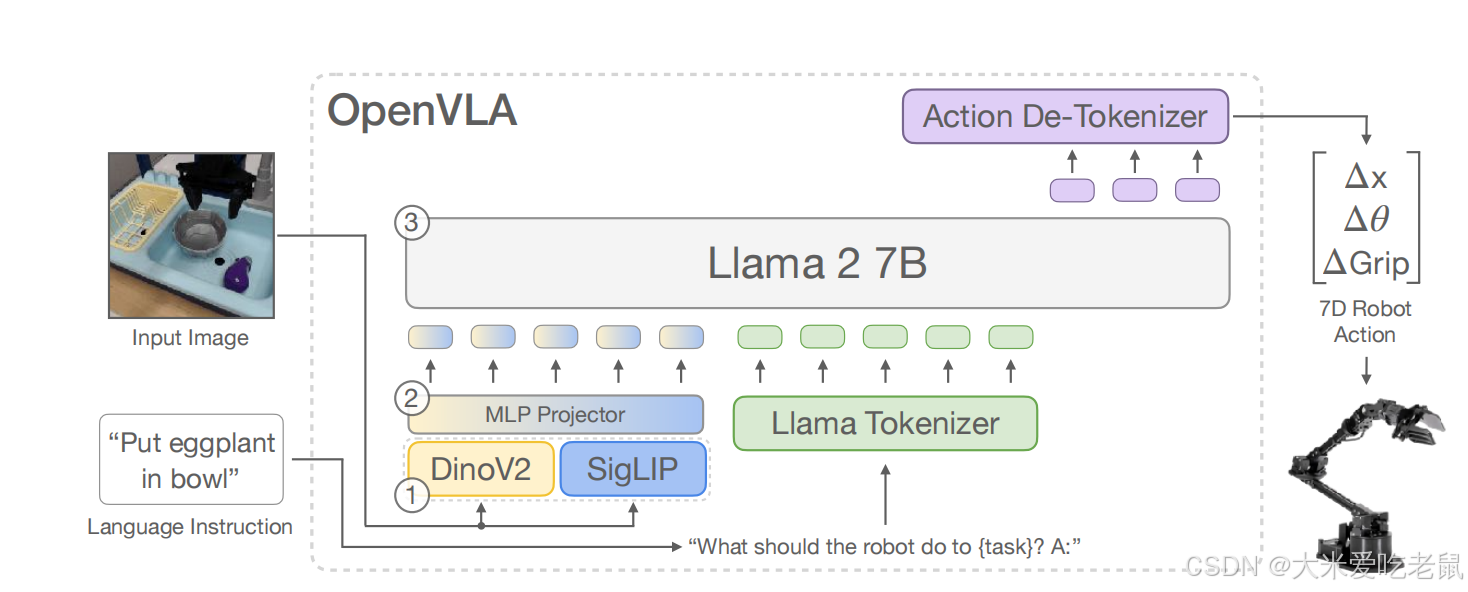
语言处理部分,使用的是googleuniversal-sentence-encoder语言编码器,将语言编码为token输入。
视觉部分采用的是SigLip+Dinov2,SigLip主要是实现了图像与语言特征的映射关系,Dinov2则是被证明有助于提高模型对图片的空间理解能力。
准备数据集
openVLA需要使用rlds数据格式,作者也给出了一个示例:numpy转rlds示例
这个环境就直接使用openVLA下载的环境就行,注意,转化rlds期间,由于tensorflow版本过高,会强制连接google,需要本机拥有梯子,给出一个本地端口转发形式(开启自己的clash):
export http_proxy=http://127.0.0.1:7890
export https_proxy=http://127.0.0.1:7890
# 如果出现端口问题,导致pip之类的无法使用就执行下面的取消端口转发就行
unset http_proxy
unset https_proxy
# 也可以直接写入bashrc避免重复操作
echo 'export http_proxy=http://127.0.0.1:7890' >> ~/.bashrc
echo 'export https_proxy=http://127.0.0.1:7890' >> ~/.bashrc
source ~/.bashrc
#这里的话就sudo vim ~/.bashrc删掉对应行然后重新source ~/.bashrc
然后我们应该已经转化好了对应的rlds数据集,如果还没做的可以看我上面的,从支持tfds读取的npy文件开始直到成功生成给对应的tensorfolw_dataset。
转化数据部分
openVLA为了在OXE各种数据集上进行训练,所以有一个比较复杂的数据转化方式,在官网上也指出了几个需要修改的地方,分别是:

实际上我们需要修改的之后后面三个部分:
prismatic/vla/datasets/rlds/oxe/transforms.py:对应注册一个函数(数据读取)
对于我自己的数据集,我是完全按照bridge_data_v2的形式制作的,因此理论上我不需要写这个,为了展示,我将写一个我们数据集的转化函数,并逐行解释:
def finetune_dataset_transform(trajectory: Dict[str, Any]) -> Dict[str, Any]:
"""
Applies to original version of Bridge V2 from the official project website.
Note =>> In original Bridge V2 dataset, the first timestep has an all-zero action, so we remove it!
"""
for key in trajectory.keys():
# 这个时bridge_data_v2数据集,由于多了一个traj_metadata的存储group,因此直接跳过
if key == "traj_metadata":
continue
elif key == "observation":
#这个就是我们数据存储的位置了,读入我们obs的数据(image,state)
#读入obs中的数据
for key2 in trajectory[key]:
trajectory[key][key2] = trajectory[key][key2][1:]
# 读入action,labguage_embed,多读如一些其他数据没关系,但是模型训练的数据一定要对应名称都进来
else:
trajectory[key] = trajectory[key][1:]
# EEF+gripper,一共七维,将数据分别提取
trajectory["action"] = tf.concat(
[
trajectory["action"][:, :6],
binarize_gripper_actions(trajectory["action"][:, -1])[:, None],
],
axis=1,
)
trajectory = relabel_bridge_actions(trajectory)
trajectory["observation"]["EEF_state"] = trajectory["observation"]["state"][:, :6]
trajectory["observation"]["gripper_state"] = trajectory["observation"]["state"][:, -1:]
return trajectory
prismatic/vla/datasets/rlds/oxe/configs.py:一个数据集格式(将数据对应到模型接口)
在OXE_DATASET_CONFIGS 中添加一个我们的数据集的对应信息绑定:
例如我的dataset类型叫做finetune_data,那么我们应该添加如下信息:
OXE_DATASET_CONFIGS = {
"finetune_data": {
#我们的数据主视角的名字叫image,没有第二视角和眼在手上视角所以None
"image_obs_keys": {"primary": "image", "secondary": None, "wrist": None},
"depth_obs_keys": {"primary": None, "secondary": None, "wrist": None},
"state_obs_keys": ["EEF_state", None, "gripper_state"],
"state_encoding": StateEncoding.POS_EULER,
"action_encoding": ActionEncoding.EEF_POS,
},
prismatic/vla/datasets/rlds/oxe/transforms.py:一段描述(将我们的数据集绑定到我们的数据集格式上)
这个在文件的末尾,我们需要将自己对应名称的数据集绑定到数据转化函数上:
OXE_STANDARDIZATION_TRANSFORMS = {
"finetune_data": finetune_dataset_transform,
这样我们就能只针对我们自己的数据集进行finetune了。
微调模型
配置好上述步骤后,我们可以开始finetune了,方便起见,我们写个finetune.sh脚本。
torchrun --standalone --nnodes 1 --nproc-per-node 1 vla-scripts/finetune.py \
--vla_path "openvla/openvla-7b" \
#可以改成自己本地保存的openvla模型,下载连接(国内镜像):https://hf-mirror.com/openvla/openvla-7b/tree/main
--data_root_dir <PATH TO BASE DATASETS DIR> \
# 以openvla为主目录,./finetune.sh ,我们的tfds(直接从tensorflow_dataset中将对应数据copy过来)
# 然后我们放入./dataset,得到例如./dataset/finetune1_dataset/1.0/*
# 这样这里写dataset/finetune1_dataset
--dataset_name finetune_data\
# 我们自己注册的数据集叫finetune_data
--run_root_dir <PATH TO LOG/CHECKPOINT DIR> \
# 保存日志和模型信息的地方。我喜欢写checkpoints/finetune1(随便写个)
--adapter_tmp_dir <PATH TO TEMPORARY DIR TO SAVE ADAPTER WEIGHTS> \
# 保存临时训练信息的,可以和run_root_dir 一样
--lora_rank 32 \
# lora的低秩训练参数
--batch_size 16 \
--grad_accumulation_steps 1 \
--learning_rate 5e-4 \
--image_aug <True or False> \
# False就行
--wandb_project <PROJECT> \
# 自己注册的wandb账号,按照网络上教程绑定下自己的账号,然后这里填个名称,我就填finetune1
--wandb_entity <ENTITY> \
# 你的wandb账号
--save_steps <NUMBER OF GRADIENT STEPS PER CHECKPOINT SAVE>
# 1000就行,内存够大可以缩小点,按照个人经验,可以6000步左右就可以有基本的效果了
部署测试
openvla部署其实很简单,官网给出了一个示例:
# Install minimal dependencies (`torch`, `transformers`, `timm`, `tokenizers`, ...)
# > pip install -r https://raw.githubusercontent.com/openvla/openvla/main/requirements-min.txt
from transformers import AutoModelForVision2Seq, AutoProcessor
from PIL import Image
import torch
# Load Processor & VLA
processor = AutoProcessor.from_pretrained("openvla/openvla-7b", trust_remote_code=True)
vla = AutoModelForVision2Seq.from_pretrained(
"openvla/openvla-7b",
attn_implementation="flash_attention_2", # [Optional] Requires `flash_attn`
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to("cuda:0")
# Grab image input & format prompt
image: Image.Image = get_from_camera(...)
prompt = "In: What action should the robot take to {<INSTRUCTION>}?\nOut:"
# Predict Action (7-DoF; un-normalize for BridgeData V2)
inputs = processor(prompt, image).to("cuda:0", dtype=torch.bfloat16)
action = vla.predict_action(**inputs, unnorm_key="bridge_orig", do_sample=False)
# Execute...
robot.act(action, ...)
这个示例十分简单,如果是用我们微调后的模型,就只要把路径修改了就行。
然后修改prompt为我们希望完成的任务的描述(一定要全英文),并且将image的来源获取了,例如D435的话是用pyrealsense库,建立一个pipeline连接,usb摄像头的话直接cv2.capture()之类的…
但是不知道为什么,反正我们自己用的时候精度莫名奇妙的低,因此我们基于VLLM加速库,东平西凑做了一个(官方:run_libero_eval.py):
import os
import sys
import time
from dataclasses import dataclass
# from pathlib import Path
# from typing import Optional, Union
from vllm import LLM, SamplingParams
from transformers import AutoProcessor
import numpy as np
import random
import cv2
import json
import tensorflow as tf
from PIL import Image
# sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), 'Demo', 'RMDemo_Python', 'RMDemo_SimpleProcess', 'src')))
# print(sys.path)
from Robotic_Arm.rm_robot_interface import *
# from Demo.RMDemo_Python.RMDemo_SimpleProcess.src.Robotic_Arm.rm_robot_interface import *
import numpy as np
import torch
import pdb
CODE_fi = 65
HOST_fi = '192.168.1.18'
import pyrealsense2 as rs
# from PIL import Imagemodel_family
# Append current directory so that interpreter can find experiments.robot
sys.path.append("../..")
sampling_params = SamplingParams(temperature=0.8,
top_p=0.95,
max_tokens=7)
from experiments.robot.robot_utils import (
DATE_TIME,
get_action,
get_image_resize_size,
get_model,
invert_gripper_action,
normalize_gripper_action,
set_seed_everywhere,
)
@dataclass
class GenerateConfig:
# fmt: off
#################################################################################################################
# Model-specific parameters
#################################################################################################################
model_family: str = "openvla" # Model family
pretrained_checkpoint: str = "/data/wuyuran/code/openvla/openvla/outputs/finetune5_data_twice/openvla-7b+finetune5_data+b10+lr-0.0005+lora-r32+dropout-0.0--image_aug" # Pretrained checkpoint path
load_in_8bit: bool = False # (For OpenVLA only) Load with 8-bit quantization
load_in_4bit: bool = False # (For OpenVLA only) Load with 4-bit quantization
center_crop: bool = True # Center crop? (if trained w/ random crop image aug)
#################################################################################################################
# LIBERO environment-specific parameters
#################################################################################################################
task_suite_name: str = "fiuntune_data6" # Task suite. Options: libero_spatial, libero_object, libero_goal, libero_10, libero_90
num_steps_wait: int = 10 # Number of steps to wait for objects to stabilize in sim
num_trials_per_task: int = 50 # Number of rollouts per task
#################################################################################################################
# Utils
#################################################################################################################
use_wandb: bool = False # Whether to also log results in Weights & Biases
wandb_project: str = "YOUR_WANDB_PROJECT" # Name of W&B project to log to (use default!)
wandb_entity: str = "YOUR_WANDB_ENTITY" # Name of entity to log under
seed: int = 7 # Random Seed (for reproducibility)
def set_seed_everywhere(seed: int):
"""Sets the random seed for Python, NumPy, and PyTorch functions."""
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ["PYTHONHASHSEED"] = str(seed)
def get_vla_llm(cfg):
"""Loads and returns a VLA model from checkpoint."""
# Load VLA checkpoint.
print("[*] Instantiating Pretrained VLA model")
print("[*] Loading in BF16 with Flash-Attention Enabled")
vla = LLM(
model=cfg.pretrained_checkpoint, dtype=torch.bfloat16, trust_remote_code=True,\
gpu_memory_utilization=0.35, quantization="fp8"
)
# Move model to device.
# Note: `.to()` is not supported for 8-bit or 4-bit bitsandbytes models, but the model will
# already be set to the right devices and casted to the correct dtype upon loading.
if not cfg.load_in_8bit and not cfg.load_in_4bit:
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# Load dataset stats used during finetuning (for action un-normalization).
dataset_statistics_path = os.path.join(cfg.pretrained_checkpoint, "dataset_statistics.json")
if os.path.isfile(dataset_statistics_path):
with open(dataset_statistics_path, "r") as f:
norm_stats = json.load(f)
vla.norm_stats = norm_stats
else:
print(
"WARNING: No local dataset_statistics.json file found for current checkpoint.\n"
"You can ignore this if you are loading the base VLA (i.e. not fine-tuned) checkpoint."
"Otherwise, you may run into errors when trying to call `predict_action()` due to an absent `unnorm_key`."
)
return vla
def get_model_LLM(cfg, wrap_diffusion_policy_for_droid=False):
"""Load model for evaluation."""
if cfg.model_family == "openvla":
model = get_vla_llm(cfg)
else:
raise ValueError("Unexpected `model_family` found in config.")
print(f"Loaded model: {type(model)}")
return model
def get_processor(cfg):
"""Get VLA model's Hugging Face processor."""
processor = AutoProcessor.from_pretrained(cfg.pretrained_checkpoint, trust_remote_code=True)
return processor
def crop_and_resize(image, crop_scale, batch_size):
"""
Center-crops an image to have area `crop_scale` * (original image area), and then resizes back
to original size. We use the same logic seen in the `dlimp` RLDS datasets wrapper to avoid
distribution shift at test time.
Args:
image: TF Tensor of shape (batch_size, H, W, C) or (H, W, C) and datatype tf.float32 with
values between [0,1].
crop_scale: The area of the center crop with respect to the original image.
batch_size: Batch size.
"""
# Convert from 3D Tensor (H, W, C) to 4D Tensor (batch_size, H, W, C)
assert image.shape.ndims == 3 or image.shape.ndims == 4
expanded_dims = False
if image.shape.ndims == 3:
image = tf.expand_dims(image, axis=0)
expanded_dims = True
# Get height and width of crop
new_heights = tf.reshape(tf.clip_by_value(tf.sqrt(crop_scale), 0, 1), shape=(batch_size,))
new_widths = tf.reshape(tf.clip_by_value(tf.sqrt(crop_scale), 0, 1), shape=(batch_size,))
# Get bounding box representing crop
height_offsets = (1 - new_heights) / 2
width_offsets = (1 - new_widths) / 2
bounding_boxes = tf.stack(
[
height_offsets,
width_offsets,
height_offsets + new_heights,
width_offsets + new_widths,
],
axis=1,
)
# Crop and then resize back up
image = tf.image.crop_and_resize(image, bounding_boxes, tf.range(batch_size), (224, 224))
# Convert back to 3D Tensor (H, W, C)
if expanded_dims:
image = image[0]
return image
def run_vla(model, prompt, image, sampling_params):
outputs = model.generate({
"prompt": prompt,
"multi_modal_data": {
"image": image
},
}, sampling_params=sampling_params)
##################### 后处理 #############################################
bins = np.linspace(-1, 1, 256)
bin_centers = (bins[:-1] + bins[1:]) / 2.0
predicted_action_token_ids = np.array(list(outputs[0].outputs[0].token_ids))
discretized_actions = 32000 - predicted_action_token_ids
discretized_actions = np.clip(discretized_actions - 1, a_min=0, a_max=bin_centers.shape[0] - 1)
normalized_actions = bin_centers[discretized_actions]
action_norm_stats = {
"mean": [
0.0035543690901249647,
-0.0005810231668874621,
-0.001206998247653246,
-0.03785282373428345,
0.013906827196478844,
0.05368286371231079,
0.1748238056898117
],
"std": [
0.01920616254210472,
0.008486345410346985,
0.02105526812374592,
0.8622716665267944,
0.06187490001320839,
0.962922215461731,
0.3798253536224365
],
"max": [
0.4192430078983307,
0.1644439995288849,
0.4554849863052368,
6.279999732971191,
1.3819999694824219,
6.277000427246094,
1.0
],
"min": [
-0.4192419946193695,
-0.16444599628448486,
-0.4554849863052368,
-6.279999732971191,
-1.3819999694824219,
-6.279000282287598,
0.0
],
"q01": [
-0.008216417431831359,
-0.020317753925919533,
-0.018127536475658415,
-6.249929971694947,
-0.011999964714050293,
-0.12164998769760131,
0.0
],
"q99": [
0.01763271629810335,
0.01648287951946259,
0.023709090054035233,
0.1382301664352449,
0.04200005531311035,
6.257929902076722,
1.0
],
"mask": [
True,
True,
True,
True,
True,
True,
False
]
}
mask = action_norm_stats.get("mask", np.ones_like(action_norm_stats["q01"], dtype=bool))
action_high, action_low = np.array(action_norm_stats["q99"]), np.array(action_norm_stats["q01"])
actions = np.where(
mask,
0.5 * (normalized_actions + 1) * (action_high - action_low) + action_low,
normalized_actions,
)
#####################################################################
return actions
def get_vla_action(vla, base_vla_name, obs, task_label, processor, center_crop=False):
"""Generates an action with the VLA policy."""
image = obs["full_image"]
# (If trained with image augmentations) Center crop image and then resize back up to original size.
# IMPORTANT: Let's say crop scale == 0.9. To get the new height and width (post-crop), multiply
# the original height and width by sqrt(0.9) -- not 0.9!
if center_crop:
batch_size = 1
crop_scale = 0.9
# Convert to TF Tensor and record original data type (should be tf.uint8)
image = tf.convert_to_tensor(np.array(image))
orig_dtype = image.dtype
# Convert to data type tf.float32 and values between [0,1]
image = tf.image.convert_image_dtype(image, tf.float32)
# Crop and then resize back to original size
image = crop_and_resize(image, crop_scale, batch_size)
# Convert back to original data type
image = tf.clip_by_value(image, 0, 1)
image = tf.image.convert_image_dtype(image, orig_dtype, saturate=True)
# Convert back to PIL Image
image = Image.fromarray(image.numpy())
image = image.convert("RGB")
# Build VLA prompt
if "openvla-v01" in base_vla_name: # OpenVLA v0.1
prompt = (
f"{OPENVLA_V01_SYSTEM_PROMPT} USER: What action should the robot take to {task_label.lower()}? ASSISTANT:"
)
else: # OpenVLA
prompt = f"In: What action should the robot take to {task_label.lower()}?\nOut:"
# Process inputs.
action = run_vla(vla, prompt, image, sampling_params)
return action
if __name__ == "__main__":
cap = cv2.VideoCapture('/dev/video0') # 使用 video6 或 video7
if not cap.isOpened():
print("无法打开摄像头")
exit()
robot_controller = RoboticArm(rm_thread_mode_e.RM_TRIPLE_MODE_E)
# 创建机械臂连接,打印连接id
handle = robot_controller.rm_create_robot_arm("192.168.1.18", 8080)
pipeline = rs.pipeline()
config = rs.config()
config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)
pipeline.start(config)
cfg=GenerateConfig()
assert cfg.pretrained_checkpoint is not None, "cfg.pretrained_checkpoint must not be None!"
if "image_aug" in cfg.pretrained_checkpoint:
assert cfg.center_crop, "Expecting `center_crop==True` because model was trained with image augmentations!"
assert not (cfg.load_in_8bit and cfg.load_in_4bit), "Cannot use both 8-bit and 4-bit quantization!"
# Set random seed
set_seed_everywhere(cfg.seed)
# [OpenVLA] Set action un-normalization key
cfg.unnorm_key = cfg.task_suite_name
# Load model
model = get_model_LLM(cfg)
sampling_params = SamplingParams(temperature=0.8,
top_p=0.95,
max_tokens=7)
processor = None
if cfg.model_family == "openvla":
processor = get_processor(cfg)
is_pick_up = False
gripper_release_command = 0
index =0
while True:
# 读入图像
ret, wrist_image = cap.read()
wrist_image =cv2.resize(wrist_image, (640, 480))
# # 将OpenCV图像转换为PIL图像
img_pil = Image.fromarray(cv2.cvtColor(wrist_image, cv2.COLOR_BGR2RGB))
# # 对PIL图像进行左右翻转
img_pil = img_pil.transpose(Image.FLIP_LEFT_RIGHT)
img_pil.save(f'./saved_image{index}.jpg')
image =img_pil
index+=1
# 设置执行命令
task_description = "put the bottle on the carton"
succ, gripper = robot_controller.rm_get_gripper_state()
gripper = gripper['actpos']
gripper = np.array([gripper])
position = robot_controller.rm_get_current_arm_state()[1]['pose']
# 设置当前的机械臂状态
observation = {
"full_image": image,
"state": np.concatenate(
(position[:3], position[3:6], gripper)
),
}
# 根据输入,调用函数输出action
action = get_vla_action(
model,
cfg.pretrained_checkpoint,
observation,
task_description,
processor=processor,
center_crop=cfg.center_crop,
)
# 计算下一步的到达位置,我们的机械臂只能指定位置移动,没有相对移动
print(position)
position[0] = position[0] + action[0]
position[1] = position[1] + action[1]
position[2] = position[2] + action[2]
position[3] = position[3] + action[3]
position[4] = position[4] + action[4]
position[5] = position[5] + action[5]
position = [float(num) for num in position]
gripper = action[6]
# 这个是因为我们机械臂支持的输入精度的原因,所以舍入了精度,可以不要
#position = [round(num, 5) if idx < 3 else round(num, 3) for idx, num in enumerate(position)]
# 阻塞执行
print(action)
robot_controller.rm_movej_p(position, 30,0,0,1)
# 对于夹爪状态做判断:如果抓到物体,则在一段连续时间内不松开
succ, gripper_state = robot_controller.rm_get_gripper_state()
if not is_pick_up and gripper_state["mode"] == 6 and gripper_state["actpos"]>20 and gripper_state["actpos"]<900:
print("pick some object, gripper adjustmentation changed")
is_pick_up = True
if not is_pick_up:
if gripper>0.9:
robot_controller.rm_set_gripper_pick_on(300, 500, True, 1)
print("picing up...")
for i in range(15):
position[2] += 0.01
robot_controller.rm_movej_p(position, 30,0,0,1)
ret, wrist_image = cap.read()
wrist_image =cv2.resize(wrist_image, (640, 480))
# # 将OpenCV图像转换为PIL图像
img_pil = Image.fromarray(cv2.cvtColor(wrist_image, cv2.COLOR_BGR2RGB))
# # 对PIL图像进行左右翻转
img_pil = img_pil.transpose(Image.FLIP_LEFT_RIGHT)
img_pil.save(f'./saved_image{index}.jpg')
index+=1
time.sleep(1)
else:
robot_controller.rm_set_gripper_release(300, True, 1)
# 需要连续一段时间判断为不夹持才松开
else:
if gripper<0.9:
gripper_release_command += 1
if gripper_release_command>5:
gripper_release_command = 0
is_pick_up =False
print("contiuning command to release the gripper, releasing the gripper...")
else:
gripper_release_command = 0
print("gripper:", gripper)
print(action)
time.sleep(0.5)
在这个代码里,模型部分有两个需要修改的,第一个是class GenerateConfig里面的pretrained_project的路径,这个要改为你模型保存的路径,第二个是函数run_vla里的action_norm_stats ,需要改为你模型的对应输出action的统计参数,这个可以在你模型输出中的config找到。
你需要主要实现的一个是输入部分,即你摄像头的输入图像,然后是输出部分操作机械臂的位移和夹爪,这里只给出了一个示例,需要按照自己需求修改。
然后讲下我们的测试结果吧:
我们一共采集的100组数据进行finetune,其中作为测试的只有一个:拾取水瓶然后放到盒子上,但实际上测试下来性能很一般,在拾取到水瓶后放置过去的过程手臂上下抖动幅度很大,最终也只能勉强完成任务。
RDT
RDT官网:RDT官网
自从DP在机械臂控制领域展示出足够的性能后,DP策略就被广泛用于Embodied AI领域了,RDT是第一个开源VLA模型中使用了DP架构来作为输出action的结构,由于是DiT,因此与openVLA的单步推理单步运动不同,RDT输出的是一个action_chunk,变成了单步推理多步运动,更加适合机械臂的精细操作。
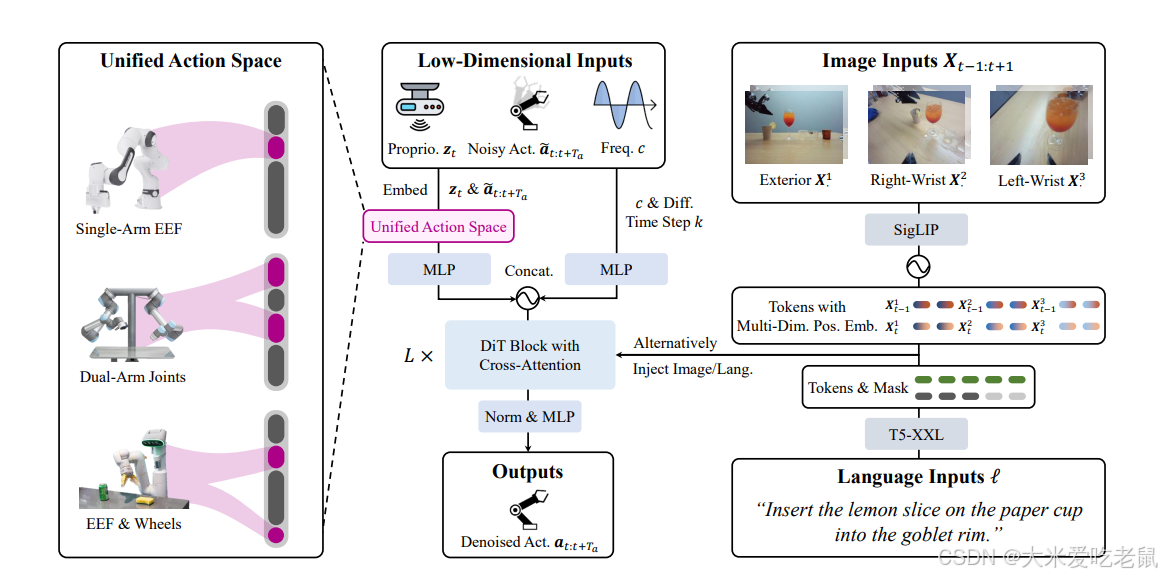
在我看来,RDT是一个集百家之长的一个具有比较好的创新性的VLA模型。
在action方面,RDT对各种机器人的返回动作进行了空间动作映射,让模型对不同机械臂具有更好的适配性,并且能在更广的机械臂数据集上进行训练。
在视觉和语言方面则和常规的VLA做法一样,对视觉和语言数据采用合适的编码器进行token化。
在输出方面,RDT引入了DiT(Diffusion Transformer),让VLM不再用于直接决定action的结果,而是在VLM后面添加了DiT part,让DiT来通过DP来决定机械臂后续64步的运动(RDT模型是基于64步预测训练的,这个是可以改变的,但是需要重新训练模型)。
推荐提前操作
建议花一个晚上先把两个模型下载到本地,然后链接到目录下:
语言编码google_t5
视觉编码SigLip
可以顺便把RDT模型也本地下载了:
RDT模型
准备数据集
上面已经给出了hdf5格式的数据转化了,如果你已经完成了这一步,那么你唯一需要做的就是将你的hdf5数据集放到一个文件夹下,就完成这一步了。
转化数据格式
为了让RDT能正确读如我们自行制作的数据,我们需要按照对应要求修改代码,为了方便,我们直接按早官方步骤,将所有转换后的hdf5文件放置到data/agilex路径下,这样我们不需要区注册自己的数据集,已经默认注册了,想要调整位置只需要按照括囊操作指导,在对应文件夹中添加自己想要的数据集名称就行。
按照自己的数据修改data/hdf5_vla_dataset.py
这个函数的修改主要聚焦于修改两个部分:
- 动作的空间映射
- 读如文件位置
由于我并没有修改文件位置,直接按照默认放置,因此我只需要修改动作空间的映射,进行对齐操作。
import os
import fnmatch
import json
import h5py
import yaml
import cv2
import numpy as np
from configs.state_vec import STATE_VEC_IDX_MAPPING
class HDF5VLADataset:
"""
This class is used to sample episodes from the embododiment dataset
stored in HDF5.
"""
def __init__(self) -> None:
# [Modify] The path to the HDF5 dataset directory
# Each HDF5 file contains one episode
# 如果要修改hdf5存放位置就要在这修改DIR,我这里在该路径下额外家了一层文件夹
# 如果修改了注册数据集的名称,就哟修改DATASET_AME
HDF5_DIR = "data/datasets/agilex/rdt_data/"
self.DATASET_NAME = "agilex"
self.file_paths = []
for root, _, files in os.walk(HDF5_DIR):
for filename in fnmatch.filter(files, '*.hdf5'):
file_path = os.path.join(root, filename)
self.file_paths.append(file_path)
# Load the config
with open('configs/base.yaml', 'r') as file:
config = yaml.safe_load(file)
self.CHUNK_SIZE = config['common']['action_chunk_size']
self.IMG_HISORY_SIZE = config['common']['img_history_size']
self.STATE_DIM = config['common']['state_dim']
# Get each episode's len
episode_lens = []
for file_path in self.file_paths:
valid, res = self.parse_hdf5_file_state_only(file_path)
_len = res['state'].shape[0] if valid else 0
episode_lens.append(_len)
self.episode_sample_weights = np.array(episode_lens) / np.sum(episode_lens)
def __len__(self):
return len(self.file_paths)
def get_dataset_name(self):
return self.DATASET_NAME
def get_item(self, index: int=None, state_only=False):
"""Get a training sample at a random timestep.
Args:
index (int, optional): the index of the episode.
If not provided, a random episode will be selected.
state_only (bool, optional): Whether to return only the state.
In this way, the sample will contain a complete trajectory rather
than a single timestep. Defaults to False.
Returns:
sample (dict): a dictionary containing the training sample.
"""
while True:
if index is None:
file_path = np.random.choice(self.file_paths, p=self.episode_sample_weights)
else:
file_path = self.file_paths[index]
valid, sample = self.parse_hdf5_file(file_path) \
if not state_only else self.parse_hdf5_file_state_only(file_path)
if valid:
return sample
else:
index = np.random.randint(0, len(self.file_paths))
def parse_hdf5_file(self, file_path):
"""[Modify] Parse a hdf5 file to generate a training sample at
a random timestep.
Args:
file_path (str): the path to the hdf5 file
Returns:
valid (bool): whether the episode is valid, which is useful for filtering.
If False, this episode will be dropped.
dict: a dictionary containing the training sample,
{
"meta": {
"dataset_name": str, # the name of your dataset.
"#steps": int, # the number of steps in the episode,
# also the total timesteps.
"instruction": str # the language instruction for this episode.
},
"step_id": int, # the index of the sampled step,
# also the timestep t.
"state": ndarray, # state[t], (1, STATE_DIM).
"state_std": ndarray, # std(state[:]), (STATE_DIM,).
"state_mean": ndarray, # mean(state[:]), (STATE_DIM,).
"state_norm": ndarray, # norm(state[:]), (STATE_DIM,).
"actions": ndarray, # action[t:t+CHUNK_SIZE], (CHUNK_SIZE, STATE_DIM).
"state_indicator", ndarray, # indicates the validness of each dim, (STATE_DIM,).
"cam_high": ndarray, # external camera image, (IMG_HISORY_SIZE, H, W, 3)
# or (IMG_HISORY_SIZE, 0, 0, 0) if unavailable.
"cam_high_mask": ndarray, # indicates the validness of each timestep, (IMG_HISORY_SIZE,) boolean array.
# For the first IMAGE_HISTORY_SIZE-1 timesteps, the mask should be False.
"cam_left_wrist": ndarray, # left wrist camera image, (IMG_HISORY_SIZE, H, W, 3).
# or (IMG_HISORY_SIZE, 0, 0, 0) if unavailable.
"cam_left_wrist_mask": ndarray,
"cam_right_wrist": ndarray, # right wrist camera image, (IMG_HISORY_SIZE, H, W, 3).
# or (IMG_HISORY_SIZE, 0, 0, 0) if unavailable.
# If only one wrist, make it right wrist, plz.
"cam_right_wrist_mask": ndarray
} or None if the episode is invalid.
"""
with h5py.File(file_path, 'r') as f:
qpos = f['observations']['qpos'][:]
num_steps = qpos.shape[0]
# [Optional] We drop too-short episode
# 如果你的动作序列都比较短,可以直接注释这一行
if num_steps < 128:
return False, None
# [Optional] We skip the first few still steps
EPS = 1e-2
# Get the idx of the first qpos whose delta exceeds the threshold
qpos_delta = np.abs(qpos - qpos[0:1])
indices = np.where(np.any(qpos_delta > EPS, axis=1))[0]
if len(indices) > 0:
first_idx = indices[0]
else:
raise ValueError("Found no qpos that exceeds the threshold.")
# We randomly sample a timestep
step_id = np.random.randint(first_idx-1, num_steps)
# Load the instruction
dir_path = os.path.dirname(file_path)
# 自己的数据不一定有用GPT生成额外的语言指令,可以替换成自己的instruction读
# 例如我们已经写入hdf5文件里,叫instruction,那就直接:
# instruction = f['instruction']
# 或者我们也可以在路径下方一个写了instruction的txt文件如:instruction.txt
# with open(os.path.join(HDF5_DIR,'instruction.txt'), 'r') as file:
# content = file.read()
with open(os.path.join(dir_path, 'expanded_instruction_gpt-4-turbo.json'), 'r') as f_instr:
instruction_dict = json.load(f_instr)
# We have 1/3 prob to use original instruction,
# 1/3 to use simplified instruction,
# and 1/3 to use expanded instruction.
instruction_type = np.random.choice([
'instruction', 'simplified_instruction', 'expanded_instruction'])
instruction = instruction_dict[instruction_type]
if isinstance(instruction, list):
instruction = np.random.choice(instruction)
# You can also use precomputed language embeddings (recommended)
# instruction = "path/to/lang_embed.pt"
# Assemble the meta
meta = {
"dataset_name": self.DATASET_NAME,
"#steps": num_steps,
"step_id": step_id,
"instruction": instruction
}
# 如果我们只是拥有单臂,那就只有7维,并且如果我们已经归一化过夹爪,那这里全都改为1代表不归一处理就行
# 注意维度对齐
# Rescale gripper to [0, 1]
qpos = qpos / np.array(
[[1, 1, 1, 1, 1, 1, 4.7908, 1, 1, 1, 1, 1, 1, 4.7888]]
)
target_qpos = f['action'][step_id:step_id+self.CHUNK_SIZE] / np.array(
[[1, 1, 1, 1, 1, 1, 11.8997, 1, 1, 1, 1, 1, 1, 13.9231]]
)
# Parse the state and action
state = qpos[step_id:step_id+1]
state_std = np.std(qpos, axis=0)
state_mean = np.mean(qpos, axis=0)
state_norm = np.sqrt(np.mean(qpos**2, axis=0))
actions = target_qpos
if actions.shape[0] < self.CHUNK_SIZE:
# Pad the actions using the last action
actions = np.concatenate([
actions,
np.tile(actions[-1:], (self.CHUNK_SIZE-actions.shape[0], 1))
], axis=0)
# Fill the state/action into the unified vector
def fill_in_state(values):
# Target indices corresponding to your state space
# In this example: 6 joints + 1 gripper for each arm
# 如果我们只有单臂,那就只保留right_arm部分,留下7维数据
UNI_STATE_INDICES = [
STATE_VEC_IDX_MAPPING[f"left_arm_joint_{i}_pos"] for i in range(6)
] + [
STATE_VEC_IDX_MAPPING["left_gripper_open"]
] + [
STATE_VEC_IDX_MAPPING[f"right_arm_joint_{i}_pos"] for i in range(6)
] + [
STATE_VEC_IDX_MAPPING["right_gripper_open"]
]
uni_vec = np.zeros(values.shape[:-1] + (self.STATE_DIM,))
uni_vec[..., UNI_STATE_INDICES] = values
return uni_vec
state = fill_in_state(state)
state_indicator = fill_in_state(np.ones_like(state_std))
state_std = fill_in_state(state_std)
state_mean = fill_in_state(state_mean)
state_norm = fill_in_state(state_norm)
# If action's format is different from state's,
# you may implement fill_in_action()
actions = fill_in_state(actions)
# Parse the images
def parse_img(key):
imgs = []
for i in range(max(step_id-self.IMG_HISORY_SIZE+1, 0), step_id+1):
img = f['observations']['images'][key][i]
imgs.append(cv2.imdecode(np.frombuffer(img, np.uint8), cv2.IMREAD_COLOR))
imgs = np.stack(imgs)
if imgs.shape[0] < self.IMG_HISORY_SIZE:
# Pad the images using the first image
imgs = np.concatenate([
np.tile(imgs[:1], (self.IMG_HISORY_SIZE-imgs.shape[0], 1, 1, 1)),
imgs
], axis=0)
return imgs
# `cam_high` is the external camera image
cam_high = parse_img('cam_high')
# For step_id = first_idx - 1, the valid_len should be one
valid_len = min(step_id - (first_idx - 1) + 1, self.IMG_HISORY_SIZE)
cam_high_mask = np.array(
[False] * (self.IMG_HISORY_SIZE - valid_len) + [True] * valid_len
)
cam_left_wrist = parse_img('cam_left_wrist')
cam_left_wrist_mask = cam_high_mask.copy()
cam_right_wrist = parse_img('cam_right_wrist')
cam_right_wrist_mask = cam_high_mask.copy()
# Return the resulting sample
# For unavailable images, return zero-shape arrays, i.e., (IMG_HISORY_SIZE, 0, 0, 0)
# E.g., return np.zeros((self.IMG_HISORY_SIZE, 0, 0, 0)) for the key "cam_left_wrist",
# if the left-wrist camera is unavailable on your robot
return True, {
"meta": meta,
"state": state,
"state_std": state_std,
"state_mean": state_mean,
"state_norm": state_norm,
"actions": actions,
"state_indicator": state_indicator,
"cam_high": cam_high,
"cam_high_mask": cam_high_mask,
"cam_left_wrist": cam_left_wrist,
"cam_left_wrist_mask": cam_left_wrist_mask,
"cam_right_wrist": cam_right_wrist,
"cam_right_wrist_mask": cam_right_wrist_mask
}
def parse_hdf5_file_state_only(self, file_path):
"""[Modify] Parse a hdf5 file to generate a state trajectory.
Args:
file_path (str): the path to the hdf5 file
Returns:
valid (bool): whether the episode is valid, which is useful for filtering.
If False, this episode will be dropped.
dict: a dictionary containing the training sample,
{
"state": ndarray, # state[:], (T, STATE_DIM).
"action": ndarray, # action[:], (T, STATE_DIM).
} or None if the episode is invalid.
"""
with h5py.File(file_path, 'r') as f:
qpos = f['observations']['qpos'][:]
num_steps = qpos.shape[0]
# [Optional] We drop too-short episode
if num_steps < 128:
return False, None
# [Optional] We skip the first few still steps
EPS = 1e-2
# Get the idx of the first qpos whose delta exceeds the threshold
qpos_delta = np.abs(qpos - qpos[0:1])
indices = np.where(np.any(qpos_delta > EPS, axis=1))[0]
if len(indices) > 0:
first_idx = indices[0]
else:
raise ValueError("Found no qpos that exceeds the threshold.")
# Rescale gripper to [0, 1]
# 同上处理
qpos = qpos / np.array(
[[1, 1, 1, 1, 1, 1, 4.7908, 1, 1, 1, 1, 1, 1, 4.7888]]
)
target_qpos = f['action'][:] / np.array(
[[1, 1, 1, 1, 1, 1, 11.8997, 1, 1, 1, 1, 1, 1, 13.9231]]
)
# Parse the state and action
state = qpos[first_idx-1:]
action = target_qpos[first_idx-1:]
# Fill the state/action into the unified vector
def fill_in_state(values):
# Target indices corresponding to your state space
# In this example: 6 joints + 1 gripper for each arm
#同上处理
UNI_STATE_INDICES = [
STATE_VEC_IDX_MAPPING[f"left_arm_joint_{i}_pos"] for i in range(6)
] + [
STATE_VEC_IDX_MAPPING["left_gripper_open"]
] + [
STATE_VEC_IDX_MAPPING[f"right_arm_joint_{i}_pos"] for i in range(6)
] + [
STATE_VEC_IDX_MAPPING["right_gripper_open"]
]
uni_vec = np.zeros(values.shape[:-1] + (self.STATE_DIM,))
uni_vec[..., UNI_STATE_INDICES] = values
return uni_vec
state = fill_in_state(state)
action = fill_in_state(action)
# Return the resulting sample
return True, {
"state": state,
"action": action
}
if __name__ == "__main__":
ds = HDF5VLADataset()
for i in range(len(ds)):
print(f"Processing episode {i}/{len(ds)}...")
ds.get_item(i)
如果一切顺利,我们可以在主目录下运行下面代码:
# 删掉已经存在的文件,因为我这运行后不会覆盖
sudo rm configs/dataset_stat.json
python -m data.compute_dataset_stat_hdf5
然后得到一个新的configs/dataset_stat.json
微调模型
微调需要注意几个点:
- 是单机多卡/多机多卡
- 你的机械臂的运动频率是多少
如果是单机多卡,那就用accelerate launch main.py
如果是多机就修改hostfile.txt的配置
根据你机器的频率,在configs/dataset_control_freq.json添加数据集对应的器械臂的控制频率:
{
"agilex": 10, # 我的机械臂是10Hz
然后就是按扎自己的需求修改RDT的finetune.sh代码了:
export NCCL_IB_HCA=mlx5_0:1,mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1,mlx5_7:1,mlx5_8:1,mlx5_9:1
export NCCL_IB_DISABLE=0
export NCCL_SOCKET_IFNAME=bond0
export NCCL_DEBUG=INFO
export NCCL_NVLS_ENABLE=0
export TEXT_ENCODER_NAME="google/t5-v1_1-xxl"
export VISION_ENCODER_NAME="google/siglip-so400m-patch14-384"
export OUTPUT_DIR="./checkpoints/rdt-finetune-1b"
export CFLAGS="-I/usr/include"
export LDFLAGS="-L/usr/lib/x86_64-linux-gnu"
export CUTLASS_PATH="/path/to/cutlass"
export WANDB_PROJECT="robotics_diffusion_transformer"
if [ ! -d "$OUTPUT_DIR" ]; then
mkdir "$OUTPUT_DIR"
echo "Folder '$OUTPUT_DIR' created"
else
echo "Folder '$OUTPUT_DIR' already exists"
fi
# For run in a single node/machine
# accelerate launch main.py \
# --deepspeed="./configs/zero2.json" \
# ...
deepspeed --hostfile=hostfile.txt main.py \ #我是单机就用accelerate launch main.py \
--deepspeed="./configs/zero2.json" \
--pretrained_model_name_or_path="robotics-diffusion-transformer/rdt-1b" \
--pretrained_text_encoder_name_or_path=$TEXT_ENCODER_NAME \
--pretrained_vision_encoder_name_or_path=$VISION_ENCODER_NAME \
--output_dir=$OUTPUT_DIR \
--train_batch_size=32 \
--sample_batch_size=64 \
--max_train_steps=200000 \
--checkpointing_period=1000 \
--sample_period=500 \
--checkpoints_total_limit=40 \
--lr_scheduler="constant" \
--learning_rate=1e-4 \
--mixed_precision="bf16" \
--dataloader_num_workers=8 \
--image_aug \
--dataset_type="finetune" \
--state_noise_snr=40 \
--load_from_hdf5 \
--report_to=wandb
# Use this to resume training from some previous checkpoint
# --resume_from_checkpoint="checkpoint-36000" \
# Use this to load from saved lanuage instruction embeddings,
# instead of calculating it during training
# --precomp_lang_embed \
如果你的显存实在不够,可以先把instruction编码了,可以小点内存占用,不过我没做过这一步。
部署测试
由于我的机械臂不是aloha,并且我不熟悉ros控制,因此使用的是我机械臂自己的python代码接口,我在这为大家重构了原有的inference函数,只需要按照要求修改成自己的机械臂就行。
scripts/agilex_model.py
由于我这里是单臂的,因此要修改这里model对应数据的后处理部分,我使用的是EEF,如果不是EEF或者是双臂,需要在这里面修改对应数据。
修改了AGILEX_STATE_INDICES后,还有一些前/后处理的rescale操作,直接搜索Rescale基本就能找出。
import os
import numpy as np
import torch
from PIL import Image
from torchvision import transforms
from configs.state_vec import STATE_VEC_IDX_MAPPING
from models.multimodal_encoder.siglip_encoder import SiglipVisionTower
from models.multimodal_encoder.t5_encoder import T5Embedder
from models.rdt_runner import RDTRunner
# The indices that the raw vector should be mapped to in the unified action vector
# 改成你自己的数据格式,单臂是默认右臂作为主臂
AGILEX_STATE_INDICES = [
STATE_VEC_IDX_MAPPING[f"right_arm_joint_{i}_pos"] for i in range(6)
] + [
STATE_VEC_IDX_MAPPING[f"right_gripper_open"]
]
# Create the RDT model
def create_model(args, **kwargs):
model = RoboticDiffusionTransformerModel(args, **kwargs)
pretrained = kwargs.get("pretrained", None)
if (
pretrained is not None
and os.path.isfile(pretrained)
):
model.load_pretrained_weights(pretrained)
return model
class RoboticDiffusionTransformerModel(object):
"""A wrapper for the RDT model, which handles
1. Model initialization
2. Encodings of instructions
3. Model inference
"""
def __init__(
self, args,
device='cuda',
dtype=torch.bfloat16,
image_size=None,
control_frequency=10,
pretrained=None,
pretrained_vision_encoder_name_or_path=None,
):
self.args = args
self.dtype = dtype
self.image_size = image_size
self.device = device
self.control_frequency = control_frequency
# We do not use the text encoder due to limited GPU memory
# self.text_tokenizer, self.text_model = self.get_text_encoder(pretrained_text_encoder_name_or_path)
self.image_processor, self.vision_model = self.get_vision_encoder(pretrained_vision_encoder_name_or_path)
self.policy = self.get_policy(pretrained)
self.reset()
def get_policy(self, pretrained):
"""Initialize the model."""
# Initialize model with arguments
if (
pretrained is None
or os.path.isfile(pretrained)
):
img_cond_len = (self.args["common"]["img_history_size"]
* self.args["common"]["num_cameras"]
* self.vision_model.num_patches)
_model = RDTRunner(
action_dim=self.args["common"]["state_dim"],
pred_horizon=self.args["common"]["action_chunk_size"],
config=self.args["model"],
lang_token_dim=self.args["model"]["lang_token_dim"],
img_token_dim=self.args["model"]["img_token_dim"],
state_token_dim=self.args["model"]["state_token_dim"],
max_lang_cond_len=self.args["dataset"]["tokenizer_max_length"],
img_cond_len=img_cond_len,
img_pos_embed_config=[
# No initial pos embed in the last grid size
# since we've already done in ViT
("image", (self.args["common"]["img_history_size"],
self.args["common"]["num_cameras"],
-self.vision_model.num_patches)),
],
lang_pos_embed_config=[
# Similarly, no initial pos embed for language
("lang", -self.args["dataset"]["tokenizer_max_length"]),
],
dtype=self.dtype,
)
else:
_model = RDTRunner.from_pretrained(pretrained)
return _model
def get_text_encoder(self, pretrained_text_encoder_name_or_path):
text_embedder = T5Embedder(from_pretrained=pretrained_text_encoder_name_or_path,
model_max_length=self.args["dataset"]["tokenizer_max_length"],
device=self.device)
tokenizer, text_encoder = text_embedder.tokenizer, text_embedder.model
return tokenizer, text_encoder
def get_vision_encoder(self, pretrained_vision_encoder_name_or_path):
vision_encoder = SiglipVisionTower(vision_tower=pretrained_vision_encoder_name_or_path, args=None)
image_processor = vision_encoder.image_processor
return image_processor, vision_encoder
def reset(self):
"""Set model to evaluation mode.
"""
device = self.device
weight_dtype = self.dtype
self.policy.eval()
# self.text_model.eval()
self.vision_model.eval()
self.policy = self.policy.to(device, dtype=weight_dtype)
# self.text_model = self.text_model.to(device, dtype=weight_dtype)
self.vision_model = self.vision_model.to(device, dtype=weight_dtype)
def load_pretrained_weights(self, pretrained=None):
if pretrained is None:
return
print(f'Loading weights from {pretrained}')
filename = os.path.basename(pretrained)
if filename.endswith('.pt'):
checkpoint = torch.load(pretrained)
self.policy.load_state_dict(checkpoint["module"])
elif filename.endswith('.safetensors'):
from safetensors.torch import load_model
load_model(self.policy, pretrained)
else:
raise NotImplementedError(f"Unknown checkpoint format: {pretrained}")
def encode_instruction(self, instruction, device="cuda"):
"""Encode string instruction to latent embeddings.
Args:
instruction: a string of instruction
device: a string of device
Returns:
pred: a tensor of latent embeddings of shape (text_max_length, 512)
"""
tokens = self.text_tokenizer(
instruction, return_tensors="pt",
padding="longest",
truncation=True
)["input_ids"].to(device)
tokens = tokens.view(1, -1)
with torch.no_grad():
pred = self.text_model(tokens).last_hidden_state.detach()
return pred
def _format_joint_to_state(self, joints):
"""
Format the joint proprioception into the unified action vector.
Args:
joints (torch.Tensor): The joint proprioception to be formatted.
qpos ([B, N, 14]).
Returns:
state (torch.Tensor): The formatted vector for RDT ([B, N, 128]).
"""
# Rescale the gripper to the range of [0, 1]
joints = joints / torch.tensor(
[[[1, 1, 1, 1, 1, 1, 1]]],
device=joints.device, dtype=joints.dtype
)
B, N, _ = joints.shape
state = torch.zeros(
(B, N, self.args["model"]["state_token_dim"]),
device=joints.device, dtype=joints.dtype
)
# Fill into the unified state vector
state[:, :, AGILEX_STATE_INDICES] = joints
# Assemble the mask indicating each dimension's availability
state_elem_mask = torch.zeros(
(B, self.args["model"]["state_token_dim"]),
device=joints.device, dtype=joints.dtype
)
state_elem_mask[:, AGILEX_STATE_INDICES] = 1
return state, state_elem_mask
def _unformat_action_to_joint(self, action):
"""
Unformat the unified action vector into the joint action to be executed.
Args:
action (torch.Tensor): The unified action vector to be unformatted.
([B, N, 128])
Returns:
joints (torch.Tensor): The unformatted robot joint action.
qpos ([B, N, 14]).
"""
action_indices = AGILEX_STATE_INDICES
joints = action[:, :, action_indices]
# Rescale the gripper back to the action range
# Note that the action range and proprioception range are different
# for Mobile ALOHA robotPublished Step
joints = joints * torch.tensor(
[[[1, 1, 1, 1, 1, 1, 1]]],
device=joints.device, dtype=joints.dtype
)
return joints
@torch.no_grad()
def step(self, proprio, images, text_embeds):
"""
Predict the next action chunk given the
proprioceptive states, images, and instruction embeddings.
Args:
proprio: proprioceptive states
images: RGB images, the order should be
[ext_{t-1}, right_wrist_{t-1}, left_wrist_{t-1},
ext_{t}, right_wrist_{t}, left_wrist_{t}]
text_embeds: instruction embeddings
Returns:
action: predicted action
"""
device = self.device
dtype = self.dtype
# The background image used for padding
background_color = np.array([
int(x*255) for x in self.image_processor.image_mean
], dtype=np.uint8).reshape(1, 1, 3)
background_image = np.ones((
self.image_processor.size["height"],
self.image_processor.size["width"], 3), dtype=np.uint8
) * background_color
# Preprocess the images by order and encode them
image_tensor_list = []
for image in images:
if image is None:
# Replace it with the background image
image = Image.fromarray(background_image)
if self.image_size is not None:
image = transforms.Resize(self.data_args.image_size)(image)
if self.args["dataset"].get("auto_adjust_image_brightness", False):
pixel_values = list(image.getdata())
average_brightness = sum(sum(pixel) for pixel in pixel_values) / (len(pixel_values) * 255.0 * 3)
if average_brightness <= 0.15:
image = transforms.ColorJitter(brightness=(1.75,1.75))(image)
if self.args["dataset"].get("image_aspect_ratio", "pad") == 'pad':
def expand2square(pil_img, background_color):
width, height = pil_img.size
if width == height:
return pil_img
elif width > height:
result = Image.new(pil_img.mode, (width, width), background_color)
result.paste(pil_img, (0, (width - height) // 2))
return result
else:
result = Image.new(pil_img.mode, (height, height), background_color)
result.paste(pil_img, ((height - width) // 2, 0))
return result
image = expand2square(image, tuple(int(x*255) for x in self.image_processor.image_mean))
image = self.image_processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
image_tensor_list.append(image)
image_tensor = torch.stack(image_tensor_list, dim=0).to(device, dtype=dtype)
image_embeds = self.vision_model(image_tensor).detach()
image_embeds = image_embeds.reshape(-1, self.vision_model.hidden_size).unsqueeze(0)
# Prepare the proprioception states and the control frequency
joints = proprio.to(device).unsqueeze(0) # (1, 1, 14)
states, state_elem_mask = self._format_joint_to_state(joints) # (1, 1, 128), (1, 128)
states, state_elem_mask = states.to(device, dtype=dtype), state_elem_mask.to(device, dtype=dtype)
states = states[:, -1:, :] # (1, 1, 128)
ctrl_freqs = torch.tensor([self.control_frequency]).to(device)
text_embeds = text_embeds.to(device, dtype=dtype)
# Predict the next action chunk given the inputs
trajectory = self.policy.predict_action(
lang_tokens=text_embeds,
lang_attn_mask=torch.ones(
text_embeds.shape[:2], dtype=torch.bool,
device=text_embeds.device),
img_tokens=image_embeds,
state_tokens=states,
action_mask=state_elem_mask.unsqueeze(1),
ctrl_freqs=ctrl_freqs
)
trajectory = self._unformat_action_to_joint(trajectory).to(torch.float32)
return trajectory
编写自己的inference代码:scripts/my_inference.py
#!/home/lin/software/miniconda3/envs/aloha/bin/python
# -- coding: UTF-8
"""
#!/usr/bin/python3
"""
import argparse
import sys
import threading
import time
import yaml
from collections import deque
import numpy as np
import torch
from PIL import Image as PImage
import cv2
from scripts.agilex_model import create_model
from Robotic_Arm.rm_robot_interface import *
import pyrealsense2 as rs
import pdb
# sys.path.append("./")
# 不用修改,因为可以直接把左臂相机图片设置为None
CAMERA_NAMES = ['cam_high', 'cam_right_wrist', 'cam_left_wrist']
observation_window = None
lang_embeddings = None
# debug
preload_images = None
class RM_controller:
# 建立与机械臂的连接,替换成你自己的,操作放在self.arm_controller
#双臂的话就在下面的Controller多申请一个左臂就行
def __init__(self):
self.arm_controller = RoboticArm(rm_thread_mode_e.RM_TRIPLE_MODE_E)
handle = self.arm_controller.rm_create_robot_arm("192.168.1.18", 8080)
# 这是用来获得对应坐标+夹爪张合度的
def get_qpos(self):
succ, gripper_state = self.arm_controller.rm_get_gripper_state()
gripper = gripper_state["actpos"]/1000
qpos = self.arm_controller.rm_get_current_arm_state()[1]['pose']
qpos.append(gripper)
print(qpos)
return qpos
# 控制机械臂运动
def move(self, d_action):
action1 = [d_action[0], d_action[1], d_action[2], d_action[3], d_action[4], d_action[5]]
action1 = [float(num) for num in action1]
# 我们的机械臂有运动精度要求
# 将科学计数法表示 的数字转换为小数形式并保留指定的位数
action1 = [round(num, 4) if idx < 3 else round(num, 3) for idx, num in enumerate(action1)]
print("delta_move:",action1)
# 获取位置
position = self.arm_controller.rm_get_current_arm_state()[1]['pose']
# 模型输出的是变化,我们机械臂只支持运动绝对位置,不支持相对距离
position[0] = position[0] + action1[0]
position[1] = position[1] + action1[1]
position[2] = position[2] + action1[2]
position[3] = position[3] + action1[3]
position[4] = position[4] + action1[4]
position[5] = position[5] + action1[5]
position = [float(num) for num in position]
# 我们夹爪只能张/合,所以按照阈值来控制张合
if d_action[6]<0.9:
self.arm_controller.rm_set_gripper_pick_on(300, 500, True, 1)
else:
self.arm_controller.rm_set_gripper_release(300, True, 1)
#控制机械臂运动到制定位置
self.arm_controller.rm_movej_p(position, 30, 0, 0, 1)
# 用来控制图像获取的
class Img_controller:
# 我们这一个是D435,另一个是usb摄像机,因此建立连接的操作不同,环城自己的建立连接方式
def __init__(self):
self.front = cv2.VideoCapture(0)
self.right = rs.pipeline()
config = rs.config()
config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)
self.right.start(config)
# 这个self.t可以不要,是用来imwrite的
self.t = 0
def get_img(self):
ret, front_image = self.front.read()
front_image =cv2.resize(front_image, (640, 480))
front_image = PImage.fromarray(cv2.cvtColor(front_image, cv2.COLOR_BGR2RGB))
# # 对PIL图像进行左右翻转
front_image = front_image.transpose(PImage.FLIP_LEFT_RIGHT)
front_image = np.array(front_image)
front_image = front_image[..., [2, 1, 0]] # 将BGR转为RGB
frames = self.right.wait_for_frames()
color_frame = frames.get_color_frame()
# 转换为numpy数组
right_image = np.asanyarray(color_frame.get_data())
right_image = right_image[..., [2, 1, 0]]
# 可以不要,这个是为了ffmpeg帧合成生成demo的
cv2.imwrite(f"./demo/right_{self.t}.jpeg",right_image)
cv2.imwrite(f"./demo/front_{self.t}.jpeg",front_image)
self.t += 1
return front_image, right_image
# 主控制器
class Controller:
# 建立连接
def __init__(self):
self.right_arm_controller = RM_controller()
self.img_controller = Img_controller()
# Initialize the model
def make_policy(args):
with open(args.config_path, "r") as fp:
config = yaml.safe_load(fp)
args.config = config
# pretrained_text_encoder_name_or_path = "google/t5-v1_1-xxl"
pretrained_vision_encoder_name_or_path = "google/siglip-so400m-patch14-384"
model = create_model(
args=args.config,
dtype=torch.bfloat16,
pretrained=args.pretrained_model_name_or_path,
# pretrained_text_encoder_name_or_path=pretrained_text_encoder_name_or_path,
pretrained_vision_encoder_name_or_path=pretrained_vision_encoder_name_or_path,
control_frequency=args.ctrl_freq,
)
return model
def set_seed(seed):
torch.manual_seed(seed)
np.random.seed(seed)
# Interpolate the actions to make the robot move smoothly
def interpolate_action(args, prev_action, cur_action):
steps = np.concatenate((np.array(args.arm_steps_length), np.array(args.arm_steps_length)), axis=0)
diff = np.abs(cur_action - prev_action)
step = np.ceil(diff / steps).astype(int)
step = np.max(step)
if step <= 1:
return cur_action[np.newaxis, :]
new_actions = np.linspace(prev_action, cur_action, step + 1)
return new_actions[1:]
def get_config(args):
config = {
'episode_len': args.max_publish_step,
'state_dim': 7,
'chunk_size': args.chunk_size,
'camera_names': CAMERA_NAMES,
}
return config
# Get the observation from the ROS topic
def get_RM_observation(args, controller):
puppet_arm_right = controller.right_arm_controller.get_qpos()
img_front, img_right = controller.img_controller.get_img()
return img_front, img_right, puppet_arm_right
# Update the observation window buffer
def update_observation_window(args, config, controller):
# JPEG transformation
# Align with training
def jpeg_mapping(img):
img = cv2.imencode('.jpg', img)[1].tobytes()
img = cv2.imdecode(np.frombuffer(img, np.uint8), cv2.IMREAD_COLOR)
return img
global observation_window
if observation_window is None:
observation_window = deque(maxlen=2)
# Append the first dummy image
observation_window.append(
{
'qpos': None,
'images':
{
config["camera_names"][0]: None,
config["camera_names"][1]: None,
config["camera_names"][2]: None,
},
}
)
img_front, img_right, puppet_arm_right = get_RM_observation(args, controller)
img_front = jpeg_mapping(img_front)
img_left = None
img_right = jpeg_mapping(img_right)
qpos = np.array(puppet_arm_right)
qpos = torch.from_numpy(qpos).float().cuda()
observation_window.append(
{
'qpos': qpos,
'images':
{
config["camera_names"][0]: img_front,
config["camera_names"][1]: img_right,
config["camera_names"][2]: img_left,
},
}
)
# RDT inference
def inference_fn(args, config, policy, t):
global observation_window
global lang_embeddings
# print(f"Start inference_thread_fn: t={t}")
while True:
time1 = time.time()
# fetch images in sequence [front, right, left]
image_arrs = [
observation_window[-2]['images'][config['camera_names'][0]],
observation_window[-2]['images'][config['camera_names'][1]],
observation_window[-2]['images'][config['camera_names'][2]],
observation_window[-1]['images'][config['camera_names'][0]],
observation_window[-1]['images'][config['camera_names'][1]],
observation_window[-1]['images'][config['camera_names'][2]]
]
# fetch debug images in sequence [front, right, left]
# image_arrs = [
# preload_images[config['camera_names'][0]][max(t - 1, 0)],
# preload_images[config['camera_names'][2]][max(t - 1, 0)],
# preload_images[config['camera_names'][1]][max(t - 1, 0)],
# preload_images[config['camera_names'][0]][t],
# preload_images[config['camera_names'][2]][t],
# preload_images[config['camera_names'][1]][t]
# ]
# # encode the images
# for i in range(len(image_arrs)):
# image_arrs[i] = cv2.imdecode(np.frombuffer(image_arrs[i], np.uint8), cv2.IMREAD_COLOR)
# proprio = torch.from_numpy(preload_images['qpos'][t]).float().cuda()
images = [PImage.fromarray(arr) if arr is not None else None
for arr in image_arrs]
# for i, pos in enumerate(['f', 'r', 'l'] * 2):
# images[i].save(f'{t}-{i}-{pos}.png')
# get last qpos in shape [7, ]
proprio = observation_window[-1]['qpos']
# unsqueeze to [1, 7]
proprio = proprio.unsqueeze(0)
# actions shaped as [1, 64, 14] in format [left, right]
actions = policy.step(
proprio=proprio,
images=images,
text_embeds=lang_embeddings
).squeeze(0).cpu().numpy()
# print(f"inference_actions: {actions.squeeze()}")
print(f"Model inference time: {time.time() - time1} s")
# print(f"Finish inference_thread_fn: t={t}")
return actions
# Main loop for the manipulation task
def model_inference(args, config, controller):
global lang_embeddings
# Load rdt model
policy = make_policy(args)
lang_dict = torch.load(args.lang_embeddings_path)
print(f"Running with instruction: \"{lang_dict['instruction']}\" from \"{lang_dict['name']}\"")
lang_embeddings = lang_dict["embeddings"]
max_publish_step = config['episode_len']
chunk_size = config['chunk_size']
# Initialize the previous action to be the initial robot state
# 运动切片,我没用到,可以直接删掉下面这两行
pre_action = np.zeros(config['state_dim'])
pre_action[:7] = np.array(
[-0.00133514404296875, 0.00209808349609375, 0.01583099365234375, -0.032616615295410156, -0.00286102294921875,
0.00095367431640625, -0.3393220901489258]
)
action = None
ptr = 0
# 这里的chun_size表示取前n步推理,超过就重新推理,因为我之前忘修改控制频率了,导致推理步骤太多
chunk_size = 4
# Inference loop
with torch.inference_mode():
while True:
# The current time step
t = 0
action_buffer = np.zeros([chunk_size, config['state_dim']])
while t < max_publish_step:
# Update observation window
update_observation_window(args, config, controller)
# When coming to the end of the action chunk
if t % chunk_size == 0:
# Start inference
action_buffer = inference_fn(args, config, policy, t).copy()
# print("action_buffer:")
# print(action_buffer)
raw_action = action_buffer[t % chunk_size]
# raw_action = np.zeros(7)
# for i in range(4):
# raw_action+=action_buffer[ptr]
# ptr+= 1
action = raw_action
# print("raw action:")
# print(action)
# Interpolate the original action sequence
if args.use_actions_interpolation:
# print(f"Time {t}, pre {pre_action}, act {action}")
interp_actions = interpolate_action(args, pre_action, action)
else:
interp_actions = action[np.newaxis, :]
# Execute the interpolated actions one by one
for act in interp_actions:
right_arm_action = act[:7]
# pdb.set_trace()
controller.right_arm_controller.move(right_arm_action)
# print(f"doing action: {act}")
time.sleep(0.1)
t += 1
print("Published Step", t)
pre_action = action.copy()
def get_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--max_publish_step', action='store', type=int,
help='Maximum number of action publishing steps', default=10000, required=False)
parser.add_argument('--seed', action='store', type=int,
help='Random seed', default=None, required=False)
parser.add_argument('--img_front_topic', action='store', type=str, help='img_front_topic',
default='/camera_f/color/image_raw', required=False)
parser.add_argument('--img_left_topic', action='store', type=str, help='img_left_topic',
default='/camera_l/color/image_raw', required=False)
parser.add_argument('--img_right_topic', action='store', type=str, help='img_right_topic',
default='/camera_r/color/image_raw', required=False)
parser.add_argument('--img_front_depth_topic', action='store', type=str, help='img_front_depth_topic',
default='/camera_f/depth/image_raw', required=False)
parser.add_argument('--img_left_depth_topic', action='store', type=str, help='img_left_depth_topic',
default='/camera_l/depth/image_raw', required=False)
parser.add_argument('--img_right_depth_topic', action='store', type=str, help='img_right_depth_topic',
default='/camera_r/depth/image_raw', required=False)
parser.add_argument('--puppet_arm_left_cmd_topic', action='store', type=str, help='puppet_arm_left_cmd_topic',
default='/master/joint_left', required=False)
parser.add_argument('--puppet_arm_right_cmd_topic', action='store', type=str, help='puppet_arm_right_cmd_topic',
default='/master/joint_right', required=False)
parser.add_argument('--puppet_arm_left_topic', action='store', type=str, help='puppet_arm_left_topic',
default='/puppet/joint_left', required=False)
parser.add_argument('--puppet_arm_right_topic', action='store', type=str, help='puppet_arm_right_topic',
default='/puppet/joint_right', required=False)
parser.add_argument('--robot_base_topic', action='store', type=str, help='robot_base_topic',
default='/odom_raw', required=False)
parser.add_argument('--robot_base_cmd_topic', action='store', type=str, help='robot_base_topic',
default='/cmd_vel', required=False)
parser.add_argument('--use_robot_base', action='store_true',
help='Whether to use the robot base to move around',
default=False, required=False)
parser.add_argument('--publish_rate', action='store', type=int,
help='The rate at which to publish the actions',
default=30, required=False)
parser.add_argument('--ctrl_freq', action='store', type=int,
help='The control frequency of the robot',
default=25, required=False)
parser.add_argument('--chunk_size', action='store', type=int,
help='Action chunk size',
default=64, required=False)
parser.add_argument('--arm_steps_length', action='store', type=float,
help='The maximum change allowed for each joint per timestep',
default=[0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.2], required=False)
parser.add_argument('--use_actions_interpolation', action='store_true',
help='Whether to interpolate the actions if the difference is too large',
default=False, required=False)
parser.add_argument('--use_depth_image', action='store_true',
help='Whether to use depth images',
default=False, required=False)
parser.add_argument('--disable_puppet_arm', action='store_true',
help='Whether to disable the puppet arm. This is useful for safely debugging', default=False)
parser.add_argument('--config_path', type=str, default="configs/base.yaml",
help='Path to the config file')
# parser.add_argument('--cfg_scale', type=float, default=2.0,
# help='the scaling factor used to modify the magnitude of the control features during denoising')
parser.add_argument('--pretrained_model_name_or_path', type=str, required=True,
help='Name or path to the pretrained model')
parser.add_argument('--lang_embeddings_path', type=str, required=True,
help='Path to the pre-encoded language instruction embeddings')
args = parser.parse_args()
return args
def main():
args = get_arguments()
controller = Controller()
if args.seed is not None:
set_seed(args.seed)
config = get_config(args)
model_inference(args, config, controller)
if __name__ == '__main__':
main()
如果一切顺利,那么你就能运行:
python -m scripts.my_inference --pretrained_model_name_or_path=checkpoints/checkpoint-6000/pytorch_model/mp_rank_00_model_states.pt --lang_embeddings_path=outs/Pick_on_caton.pt --ctrl_freq=10
这里的pretrained_model_name_or_path改为你自己的模型位置,lang_embeddings_path是因为我提前对输入的语言指令作了编码,我也推荐在运行前去scripts/encode_lang.py编码下自己的指令。
scripts/encode_lang.py
import os
import torch
import yaml
from models.multimodal_encoder.t5_encoder import T5Embedder
GPU = 0
# 建议本地这个模型,太大了,网络load半天
MODEL_PATH = "google/t5-v1_1-xxl"
CONFIG_PATH = "configs/base.yaml"
SAVE_DIR = "outs/"
# Modify this to your task name and instruction
# 你编码后文件存储的名字
TASK_NAME = "Pick_on_caton"
# 你的instruction
INSTRUCTION = "Put up the bottle on the carton."
# Note: if your GPU VRAM is less than 24GB,
# it is recommended to enable offloading by specifying an offload directory.
OFFLOAD_DIR = None # Specify your offload directory here, ensuring the directory exists.
def main():
with open(CONFIG_PATH, "r") as fp:
config = yaml.safe_load(fp)
device = torch.device(f"cuda:{GPU}")
text_embedder = T5Embedder(
from_pretrained=MODEL_PATH,
model_max_length=config["dataset"]["tokenizer_max_length"],
device=device,
use_offload_folder=OFFLOAD_DIR
)
tokenizer, text_encoder = text_embedder.tokenizer, text_embedder.model
tokens = tokenizer(
INSTRUCTION, return_tensors="pt",
padding="longest",
truncation=True
)["input_ids"].to(device)
tokens = tokens.view(1, -1)
with torch.no_grad():
pred = text_encoder(tokens).last_hidden_state.detach().cpu()
save_path = os.path.join(SAVE_DIR, f"{TASK_NAME}.pt")
# We save the embeddings in a dictionary format
torch.save({
"name": TASK_NAME,
"instruction": INSTRUCTION,
"embeddings": pred
}, save_path
)
print(f'\"{INSTRUCTION}\" from \"{TASK_NAME}\" is encoded by \"{MODEL_PATH}\" into shape {pred.shape} and saved to \"{save_path}\"')
if __name__ == "__main__":
main()
放个demo(手臂的相机因为是PIL格式,所以RGB格式会导致红蓝反了):

















 9387
9387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









