







近期arXiv公开了关于具身智能(Embodied AI)中的视觉-语言-动作模型(Vision-Language-Action Models,简称VLAs)的综合综述论文。介绍了VLAs的概念,它们是为了处理多模态输入而设计的模型,包括视觉、语言和动作模态。这些模型对于具身AI至关重要,因为它们需要理解和执行指令、感知环境并生成适当的动作。
文章讨论了单模态模型的发展,包括计算机视觉、自然语言处理和强化学习中的里程碑模型。强调了多模态模型的出现,这些模型结合了单模态模型的进展,以处理如视觉问答、图像描述和语音识别等任务。
详细介绍了VLA模型的不同组件,包括预训练的视觉表示、动态学习、世界模型和控制策略。讨论了VLA模型的分类,包括基于预训练的模型、基于Transformer的模型和基于大型语言模型(LLM)的模型。探讨了高级任务规划器,这些规划器能够将长期任务分解为可执行的子任务。
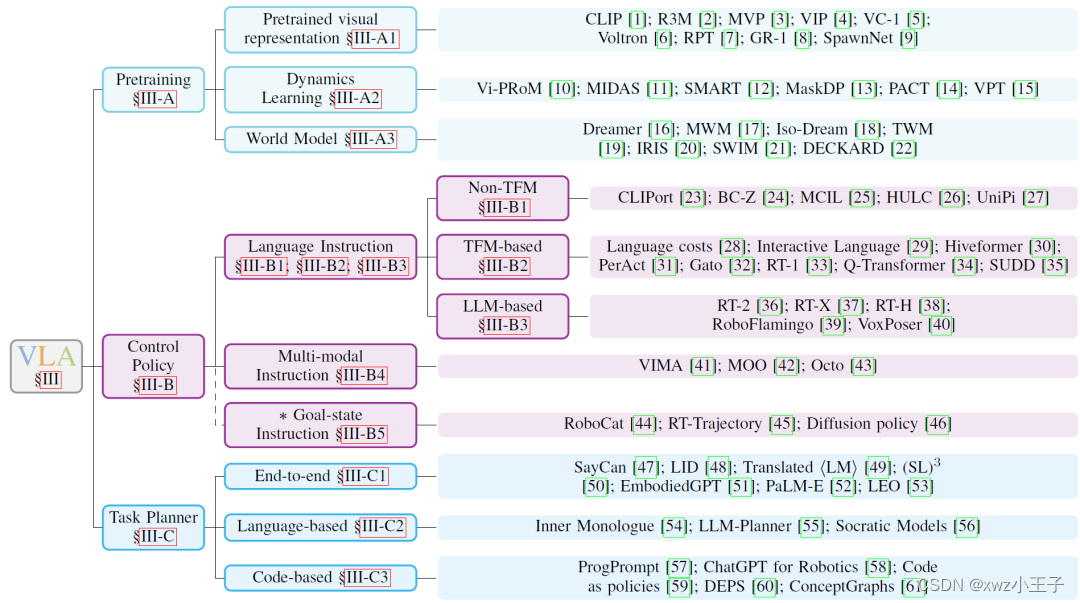
虽然目前还没有专门针对VLAs的综述,但相关领域的现有综述为VLA研究提供了有价值的见解。提供了对新兴VLA模型的全面回顾,涵盖了架构、训练目标和机器人任务等多个方面。提出了一个包括预训练、控制策略和任务规划器三个主要组成部分的层次结构分类法。提供了训练和评估VLA模型所需的资源概述,包括最近引入的数据集和模拟器。
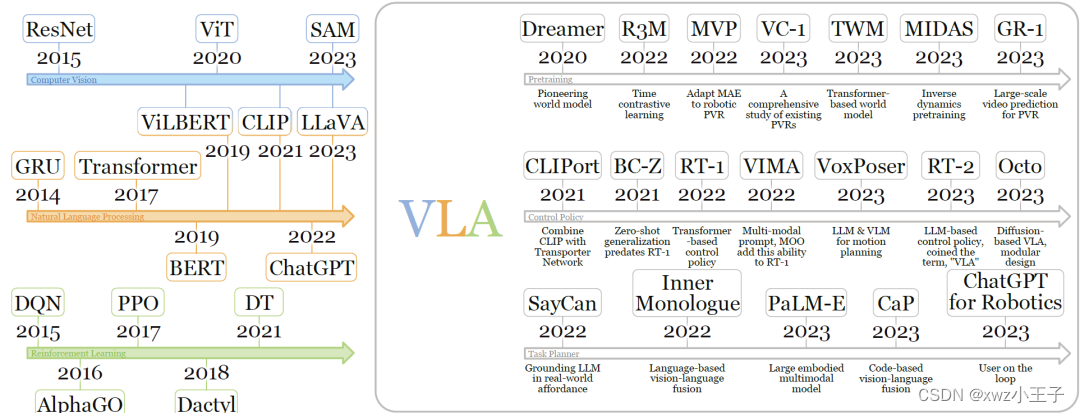
概述了当前的挑战和未来的机遇,如解决数据稀缺问题、提高机器人的灵活性、实现跨不同任务、
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









