







ssd的核心思想是把坐标预测当做回归问题
目录
1.1 网络结构

ssd的基础网络和vgg16是一样的不过全连接层换成了conv6+relu+conv7+relu.其后的层称为extra layer以得到更多不同尺寸的feature map. 并且对网络中conv4_3, conv7,conv8_2,conv9_2,conv10_2,conv11_2这六个layer的feature map再做卷积,得到类别和位置信息.
具体操作为:分别用2组3 x 3的卷积核去做卷积,一个负责预测类别,一个负责预测位置.卷积核的个数分别为boxnum x clasess_num,boxnum x 4(坐标由4个参数,中心坐标,box宽高即可确定).
class SSD(nn.Module):
'''
Args:
phase: string, 可选"train" 和 "test"
size: 输入网络的图片大小
base: VGG16的网络层(修改fc后的)
extras: 用于多尺度增加的网络
head: 包含了各个分支的loc和conf
num_classes: 类别数
return:
output: List, 返回loc, conf 和 候选框
'''
def __init__(self, phase, size, base, extras, head, num_classes):
super(SSD, self).__init__()
self.phase = phase
self.size = size
self.num_classes = num_classes
# 配置config
self.cfg = (coco, voc)[num_classes == 21]
# 初始化先验框
self.priorbox = PriorBox(self.cfg)
self.priors = self.priorbox.forward()
# basebone 网络
self.vgg = nn.ModuleList(base)
# conv4_3后面的网络,L2 正则化
self.L2Norm = L2Norm(512, 20)
self.extras = nn.ModuleList(extras)
# 回归和分类网络
self.loc = nn.ModuleList(head[0])
self.conf = nn.ModuleList(head[1])
if phase == 'test':
'''
# 预测使用
self.softmax = nn.Softmax(dim=-1)
self.detect = Detect(num_classes, 200, 0.01, 0.045)
'''
pass
def forward(self, x):
sources, loc ,conf = [], [], []
# vgg网络到conv4_3
for i in range(23):
x = self.vgg[i](x)
# l2 正则化
s = self.L2Norm(x)
sources.append(s)
# conv4_3 到 fc
for i in range(23, len(self.vgg)):
x = self.vgg[i](x)
sources.append(x)
# extras 网络
for k,v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
# 把需要进行多尺度的网络输出存入 sources
if k%2 == 1:
sources.append(x)
# 多尺度回归和分类网络
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == 'test':
'''
# 预测使用
output = self.detect(
# loc 预测
loc.view(loc.size(0), -1, 4),
# conf 预测
self.softmax(conf.view(conf.size(0), -1, self.num_classes)),
# default box
self.priors.type(type(x.data)),
)
'''
pass
else:
output = (
# loc的输出,size:(batch, 8732, 4)
loc.view(loc.size(0), -1 ,4),
# conf的输出,size:(batch, 8732, 21)
conf.view(conf.size(0), -1, self.num_classes),
# 生成所有的候选框 size([8732, 4])
self.priors,
)
# print(type(x.data))
# print((self.priors.type(type(x.data))).shape)
return outputssd模型类 输出: loc的输出,size:(batch, 8732, 4) 、conf的输出,size:(batch, 8732, 21)、priors:候选框 size([8732, 4])
注意:
1)priors并没有参与运算,conv4_3 后接了L2nomal,因为conv4_3特征图大小38x38,网络层靠前,norm较大,需要加一个L2 Normalization,以保证和后面的检测层差异不是很大。
1.2 先验框
1.2.1 先验框priorbox的生成
SSD从Conv4_3开始,一共提取了6个特征图,其大小分别为 (38,38),(19,19),(10,10),(5,5),(3,3),(1,1),但是每个特征图上设置的先验框数量不同。
先验框的设置,包括尺度(或者说大小)和长宽比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加:
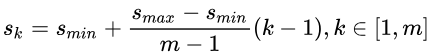

1)先验框尺度
对于第一个特征图,它的先验框尺度比例设置为 Smin / 2 = 0.1,则其尺度为 300*0.1 = 30
对于后面的特征图,先验框尺度按照上面公式线性增加,但是为了方便计算,先将尺度比例先扩大100倍,此时增长步长为:
![]() 有
有 ![]() 得
得 ![]() 将上面的值除以100,然后再乘回原图的大小300,再综合第一个特征图的先验框尺寸,则可得各个特征图的先验框尺寸为:
将上面的值除以100,然后再乘回原图的大小300,再综合第一个特征图的先验框尺寸,则可得各个特征图的先验框尺寸为:
![]()
2)先验框长宽计算
先验框的长宽比一般设置为:![]() ,根据面积和长宽比可得先验框的宽度和高度:
,根据面积和长宽比可得先验框的宽度和高度:![]()
默认情况下,每个特征图会有一个![]() 且尺度为
且尺度为![]() 的先验框,除此之外,还会设置一个尺度为
的先验框,除此之外,还会设置一个尺度为![]() 且
且![]() 的先验框,这样每个特征图都设置了两个长宽比为1但大小不同的正方形先验框; 最后一个特征图需要参考一个虚拟
的先验框,这样每个特征图都设置了两个长宽比为1但大小不同的正方形先验框; 最后一个特征图需要参考一个虚拟![]() = 300*(88+17)/100 = 315 来计算
= 300*(88+17)/100 = 315 来计算
3) 先验框数量
每个特征图一共有 6 个先验框 ![]() 但是在实现时,Conv4_3,Conv10_2和Conv11_2层仅使用4个先验框,它们不使用长宽比为 3 、1/3的先验框;
但是在实现时,Conv4_3,Conv10_2和Conv11_2层仅使用4个先验框,它们不使用长宽比为 3 、1/3的先验框;
4)先验框中心
每个单元的先验框的中心点分布在各个单元的中心,即: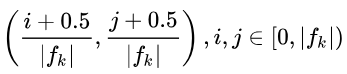 ,其中fk为特征图大小
,其中fk为特征图大小
class PriorBox(object):
"""
1、计算先验框,根据feature map的每个像素生成box;
2、框的中个数为: 38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732
3、 cfg: SSD的参数配置,字典类型
"""
def __init__(self, cfg):
super(PriorBox, self).__init__()
self.img_size = cfg['img_size']
self.feature_maps = cfg['feature_maps']
self.min_sizes = cfg['min_sizes']
self.max_sizes = cfg['max_sizes']
self.steps = cfg['steps']
self.aspect_ratios = cfg['aspect_ratios']
self.clip = cfg['clip']
self.version = cfg['name']
self.variance = cfg['variance']
def forward(self):
mean = [] #用来存放 box的参数
# 遍多尺度的 map: [38, 19, 10, 5, 3, 1]
for k, f in enumerate(self.feature_maps):
# 遍历每个像素
for i, j in product(range(f), repeat=2):
# k-th 层的feature map 大小
f_k = self.img_size/self.steps[k]
# 每个框的中心坐标
cx = (i+0.5)/f_k
cy = (j+0.5)/f_k
'''
当 ratio==1的时候,会产生两个 box
'''
# r==1, size = s_k, 正方形
s_k = self.min_sizes[k]/self.img_size
mean += [cx, cy, s_k, s_k]
# r==1, size = sqrt(s_k * s_(k+1)), 正方形
s_k_plus = self.max_sizes[k]/self.img_size
s_k_prime = sqrt(s_k * s_k_plus)
mean += [cx, cy, s_k_prime, s_k_prime]
'''
当 ratio != 1 的时候,产生的box为矩形
'''
for r in self.aspect_ratios[k]:
mean += [cx, cy, s_k * sqrt(r), s_k / sqrt(r)]
mean += [cx, cy, s_k / sqrt(r), s_k * sqrt(r)]
# 转化为 torch
boxes = torch.tensor(mean).view(-1, 4)
# 归一化,把输出设置在 [0,1]
if self.clip:
boxes.clamp_(max=1, min=0)
return boxes1.2.2 先验框的匹配
✔️ 在训练过程中,首先需要确定训练图片中的 ground truth 与哪一个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。
✔️ SSD的先验框和ground truth匹配原则主要两点: 1. 对于图片中的每个gt,找到与其IOU最大的先验框,该先验框与其匹配,这样可以保证每个gt一定与某个prior匹配。 2. 对于剩余未匹配的priors,若某个gt的IOU大于某个阈值(一般0.5),那么该prior与这个gt匹配。有一个问题困扰了我好久,第二步不是包含第一步吗,直到某天豁然开朗,可能所有的prior box与gt box的iou都<阈值,第一步就是为了保证至少有一个prior box与gt box对应
注意点:
1) 通常称与gt匹配的prior为正样本,反之,若某一个prior没有与任何一个gt匹配,则为负样本。
2) 某个gt可以和多个prior匹配,而每个prior只能和一个gt进行匹配。
3) 如果多个gt和某一个prior的IOU均大于阈值,那么prior只与IOU最大的那个进行匹配。
def match(threshold, truths, priors, variances, labels, loc_t, conf_t, idx):
'''
Target:
把和每个prior box 有最大的IOU的ground truth box进行匹配,
同时,编码包围框,返回匹配的索引,对应的置信度和位置
Args:
threshold: IOU阈值,小于阈值设为bg
truths: ground truth boxes, shape[N,4]
priors: 先验框, shape[M,4]
variances: prior的方差, list(float)
labels: 图片的所有类别,shape[num_obj]
loc_t: 用于填充encoded loc 目标张量
conf_t: 用于填充encoded conf 目标张量
idx: 现在的batch index
'''
overlaps = iou(truths, point_form(priors))
# [1,num_objects] 和每个ground truth box 交集最大的 prior box
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
# [1,num_priors] 和每个prior box 交集最大的 ground truth box
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
# squeeze shape
best_prior_idx.squeeze_(1) #(N)
best_prior_overlap.squeeze_(1) #(N)
best_truth_idx.squeeze_(0) #(M)
best_truth_overlap.squeeze_(0) #(M)
# 保证每个ground truth box 与某一个prior box 匹配,固定值为 2 > threshold
best_truth_overlap.index_fill_(0, best_prior_idx, 2) # ensure best prior
# 保证每一个ground truth 匹配它的都是具有最大IOU的prior
# 根据 best_prior_dix 锁定 best_truth_idx里面的最大IOU prior
# 通过重新给 best_truth_idx[下标] 赋值,下标为 best_prior_idx[j] 即最大IOU prior
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
# 提取出所有匹配的ground truth box, Shape: [M,4]
matches = truths[best_truth_idx]
# 提取出所有GT框的类别, Shape:[M]
conf = labels[best_truth_idx] + 1
# 把 iou < threshold 的框类别设置为 bg,即为0
conf[best_truth_overlap < threshold] = 0
# 编码包围框
loc = encode(matches, priors, variances)
# 保存匹配好的loc和conf到loc_t和conf_t中
loc_t[idx] = loc # [M,4] encoded offsets to learn
conf_t[idx] = conf # [M] top class label for each prior
1.3 预选框的生成
每一个feature_map卷积后可得一个m x m x 4的tensor.其中4是(t_x,t_y,t_w,t_h),这时候我们需要用这些数在default box的基础上去得到我们的预测框的坐标.可以认为神经网络预测得到的是相对参考框的偏移. 这也是所谓的把坐标预测当做回归问题的含义.box=anchor_box x 形变矩阵,我们回归的就是这个形变矩阵的参数,即(t_x,t_y,t_w,t_h),即
b_center_x = t_x * p_width + p_center_x
b_center_y = t_y * p_height + p_center_y
b_width = exp(t_w) * p_width
b_height = exp(t_h) * p_height
其中p_*代表的是default box. b_*才是我们最终预测的box的坐标.
这时候我们得到了很多很多(8732)个box.我们要从这些box中筛选出我们最终给出的box.
伪代码为
for every conv box:
for every class :
if class_prob < theshold:
continue
predict_box = decode(convbox)
nms(predict_box) #去除非常接近的框
class Detect(Function):
def forward(self, loc_data, conf_data, prior_data):
##loc_data [batch,8732,4]
##conf_data [batch,8732,1+class]
##prior_data [8732,4]
num = loc_data.size(0) # batch size
num_priors = prior_data.size(0)
output = torch.zeros(num, self.num_classes, self.top_k, 5)
conf_preds = conf_data.view(num, num_priors,
self.num_classes).transpose(2, 1)
# Decode predictions into bboxes.
for i in range(num):
decoded_boxes = decode(loc_data[i], prior_data, self.variance)
# For each class, perform nms
conf_scores = conf_preds[i].clone()
for cl in range(1, self.num_classes):
c_mask = conf_scores[cl].gt(self.conf_thresh)
scores = conf_scores[cl][c_mask]
if scores.size(0) == 0:
continue
l_mask = c_mask.unsqueeze(1).expand_as(decoded_boxes)
boxes = decoded_boxes[l_mask].view(-1, 4)
# idx of highest scoring and non-overlapping boxes per class
ids, count = nms(boxes, scores, self.nms_thresh, self.top_k)
output[i, cl, :count] = \
torch.cat((scores[ids[:count]].unsqueeze(1),
boxes[ids[:count]]), 1)
flt = output.contiguous().view(num, -1, 5)
_, idx = flt[:, :, 0].sort(1, descending=True)
_, rank = idx.sort(1)
flt[(rank < self.top_k).unsqueeze(-1).expand_as(flt)].fill_(0)
return output
1.3.1 decode 和 encode
在match中将gt box encode 在detect中将 pre box decode



def encode(matched, priors, variances):
'''
将来至于priorbox的差异编码到ground truth box中
Args:
matched: 每个prior box 所匹配的ground truth,
Shape[M,4],坐标(xmin,ymin,xmax,ymax)
priors: 先验框box, shape[M,4],坐标(cx, cy, w, h)
variances: 方差,list(float)
'''
# 编码中心坐标cx, cy
g_cxcy = (matched[:, :2] + matched[:, 2:])/2 -priors[:, :2]
g_cxcy /= (priors[:, 2:] * variances[0]) #shape[M,2]
# 防止出现log出现负数,从而使loss为 nan
eps = 1e-5
# 编码宽高w, h
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh + eps) / variances[1] #shape[M,2]
return torch.cat([g_cxcy, g_wh], 1) #shape[M,4]
def decode(loc, priors, variances):
'''
对应encode,解码预测的位置信息
'''
boxes = torch.cat((priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])),1)
# 转化坐标为 (xmin, ymin, xmax, ymax)类型
boxes = point_form(boxes)
return boxes1.4 loss计算
伪代码可以表述为
#根据匹配策略得到每个prior box对应的gt box
#根据iou筛选出positive prior box
#计算conf loss
#筛选出loss靠前的xx个negative prior box.保证neg:pos=3:1
#计算交叉熵
#归一化处理
坐标偏移的loss
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4) #预测得到的偏移量
loc_t = loc_t[pos_idx].view(-1, 4) #真实的偏移量
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False) #我们回归的就是相对default box的偏移
用smooth_l1_loss. 代码比较简单,不多讲了.
Hard negative mining
在匹配default box和gt box以后,必然是有大量的default box是没有匹配上的.即只有少量正样本,有大量负样本.对每个default box,我们按照confidence loss从高到低排序.我们只取排在前列的一些default box去计算loss,负样本使我们学到背景信息,正样本使我们学到目标信息.所以二者都需要,并且使得负样本:正样本在3:1. 这样可以使得模型更加快地优化,训练更稳定.
class MultiBoxLoss(nn.Module):
def __init__(self, num_classes, overlap_thresh, neg_pos, use_gpu=False):
super(MultiBoxLoss, self).__init__()
self.use_gpu = use_gpu
self.num_classes = num_classes
self.threshold = overlap_thresh
self.negpos_ratio = neg_pos
self.variance = voc['variance']
def forward(self, pred, targets):
'''
Args:
pred: A tuple, 包含 loc(编码钱的位置信息), conf(类别), priors(先验框);
loc_data: shape[b,M,4];
conf_data: shape[b,M,num_classes];
priors: shape[M,4];
targets: 真实的boxes和labels,shape[b,num_objs,5];
'''
loc_data, conf_data, priors = pred
batch = loc_data.size(0) #batch
num_priors = priors[:loc_data.size(1), :].size(0) # 先验框个数
# 获取匹配每个prior box的 ground truth
# 创建 loc_t 和 conf_t 保存真实box的位置和类别
loc_t = torch.Tensor(batch, num_priors, 4)
conf_t = torch.LongTensor(batch, num_priors)
for idx in range(batch):
truths = targets[idx][:, :-1].detach() # ground truth box信息
labels = targets[idx][:, -1].detach() # ground truth conf信息
defaults = priors.detach() # priors的 box 信息
# 匹配 ground truth
match(self.threshold, truths, defaults,
self.variance, labels, loc_t, conf_t, idx)
# use gpu
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
pos = conf_t > 0 # 匹配中所有的正样本mask,shape[b,M]
# Localization Loss,使用 Smooth L1
# shape[b,M]-->shape[b,M,4]
pos_idx = pos.unsqueeze(2).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1,4) # 预测的正样本box信息
loc_t = loc_t[pos_idx].view(-1,4) # 真实的正样本box信息
loss_l = F.smooth_l1_loss(loc_p, loc_t) # Smooth L1 损失
'''
Target;
下面进行hard negative mining
过程:
1、 针对所有batch的conf,按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列;
2、 负样本的label全是背景,那么利用log softmax 计算出logP,
logP越大,则背景概率越低,误差越大;
3、 选取误差交大的top_k作为负样本,保证正负样本比例接近1:3;
'''
# shape[b*M,num_classes]
batch_conf = conf_data.view(-1, self.num_classes)
# 使用logsoftmax,计算置信度,shape[b*M, 1]
conf_logP = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# hard Negative Mining
conf_logP = conf_logP.view(batch, -1) # shape[b, M]
conf_logP[pos] = 0 # 把正样本排除,剩下的就全是负样本,可以进行抽样
# 两次sort排序,能够得到每个元素在降序排列中的位置idx_rank
_, index = conf_logP.sort(1, descending=True)
_, idx_rank = index.sort(1)
# 抽取负样本
# 每个batch中正样本的数目,shape[b,1]
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio*num_pos, max= pos.size(1)-1)
neg = idx_rank < num_neg # 抽取前top_k个负样本,shape[b, M]
# shape[b,M] --> shape[b,M,num_classes]
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
# 提取出所有筛选好的正负样本(预测的和真实的)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
conf_target = conf_t[(pos+neg).gt(0)]
# 计算conf交叉熵
loss_c = F.cross_entropy(conf_p, conf_target)
# 正样本个数
N = num_pos.detach().sum().float()
loss_l /= N
loss_c /= N
return loss_l, loss_c
# 调试代码使用
if __name__ == "__main__":
loss = MultiBoxLoss(21, 0.5, 3)
p = (torch.randn(1,100,4), torch.randn(1,100,21), torch.randn(100,4))
t = torch.randn(1, 10, 4)
tt = torch.randint(20, (1,10,1))
t = torch.cat((t,tt.float()), dim=2)
l, c = loss(p, t)
# 随机randn,会导致g_wh出现负数,此时结果会变成 nan
print('loc loss:', l)
print('conf loss:', c)注意:
1) 两次sort排序的作用是 求矩阵的升序或降序元素的位置

2) hard negative mining
将正负样本按照 1:3 的比例把负样本抽样出来,抽样的方法是:针对所有batch的confidence,按照置信度误差进行降序排列,取出前top_k个负样本。
batch_conf = conf_data.view(-1, self.num_classes) # Reshape所有batch中的conf
把所有conf进行logsoftmax处理(均为负值),预测的置信度越小,则logsoftmax越小,取绝对值,则|logsoftmax|越大,降序排列-logsoftmax,取前 top_k 的负样本,这里借用logsoftmax的思想:

上述变换的关键在于,我们引入了一个不牵涉log或exp函数的常数项c。现在我们只需为 c 选择一个在所有情形下有效的良好的值,结果发现,$max(x_1…x_n)$很不错,c取x.max()。由此我们可以构建对数softmax的新表达式:

logSumExp的表示为:
def log_sum_exp(x):
"""Utility function for computing log_sum_exp while determining
This will be used to determine unaveraged confidence loss across
all examples in a batch.
Args:
x (Variable(tensor)): conf_preds from conf layers
"""
x_max = x.data.max()
return torch.log(torch.sum(torch.exp(x-x_max), 1, keepdim=True)) + x_max这里用到了一个trick.参考。为了避免e的n次幂太大或者太小而无法计算,常常在计算softmax时使用这个trick.
这个函数严重影响了我对loss_c的理解,实际上,你可以把上述函数中的x_max移除.那这个函数 那么loss_c就变为了 :
loss_c = torch.log(torch.sum(torch.exp(batch_conf), 1, keepdim=True)) - batch_conf.gather(1, conf_t.view(-1, 1)) 就好理解多了. conf_t的列方向是相应的label的index. batch_conf.gather(1, conf_t.view(-1, 1))得到一个[batch*8732,1]的tensor,即只保留prior box对应的label的概率预测信息.那总体的loss即为 : 所有类别的loss之和减去这个prior box应该负责的label的loss.
参考















 6240
6240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









