









 本文介绍了实例分割的几种方法,包括基于轮廓的DeepSnake,实时分割的YOLACT,极坐标建模的PolarMask,以及后处理优化的SegFix。这些方法分别通过优化初始轮廓、并行处理、极坐标表示和边界细化来提高分割效果。此外,文章还探讨了语义分割中的边界处理和多尺度信息融合策略,如DecoupleSegNets和SemanticFlow,强调了在分割任务中处理边界像素和融合不同分辨率特征的重要性。
本文介绍了实例分割的几种方法,包括基于轮廓的DeepSnake,实时分割的YOLACT,极坐标建模的PolarMask,以及后处理优化的SegFix。这些方法分别通过优化初始轮廓、并行处理、极坐标表示和边界细化来提高分割效果。此外,文章还探讨了语义分割中的边界处理和多尺度信息融合策略,如DecoupleSegNets和SemanticFlow,强调了在分割任务中处理边界像素和融合不同分辨率特征的重要性。
1.2 实例分割思路
当前做instance segmentation的大多数工作采用了Mask R-CNN [1] 的Pipeline。
- 在矩形框中做逐像素分割会受限于矩形框的准确度。如果矩形框本来就不准,比如没有完全覆盖物体,那就算框中的分割做的再好,也无法得到正确的instance mask。
- 逐像素分割计算量其实很大,后续处理计算量也大。因为逐像素分割计算量大,所以网络一般将矩形框区域downsample为28x28的网格,然后进行分割,之后再把分割结果upsample到原图大小。这个upsample根据Mask R-CNN论文里的统计是有15ms的,比较费时。还有个问题是,在28x28网格上做分割会损失精度。即使28x28的网格上的分割结果完全正确,upsample到原图的mask仍然是很粗糙的。
- 逐像素分割不适用于一些物体,比如细胞和文本。
目前 instance 的分割结果应该是最好的,但是其通常依赖于boundingbox的预测,或者使用某种方式对mask进行建模,以减少错误检测,但是现在的情况是 一般不会对路面进行 实例分割,也就是说开源的数据集中,基本是没有路面作为前景的分割数据标签
计划从全景分割的项目中寻找数据,,
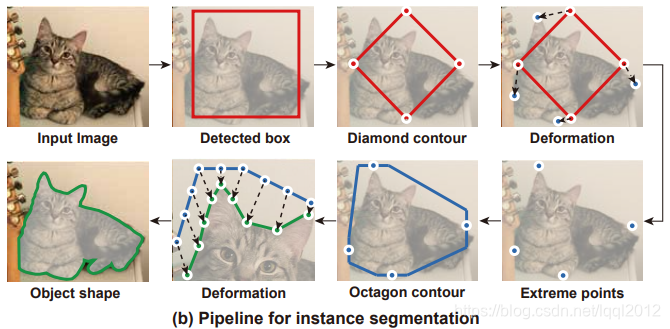
1.2.1 Deep Snake for Real-Time Instance Segmentation
考虑到逐像素分割有诸多限制,我们的工作选择用contour来表示物体的shape。Contour是一组有序的点,而且是首尾相连的。Contour相对于用稠密像素表示物体有两大优势:
- 参数量远小于稠密像素,更接近于box的参数量。这样使得instance segmentation的速度上限更高,也能更廉价地使用分割结果。这里举个例子就是tracking。现在tracking主要还是使用box做跟踪,用物体的dense pixels做tracking计算量会很大。如果把dense pixel换成用contour做tracking就会好很多。
- Contour更适用于细胞、文字这些物体的分割。
引入Circular convolution来处理contour
1)Snakes: Active contour models
传统的图像分割领域一直都有用Contour做分割。有一个很经典很有名的工作是Snakes:Active contour models. [2]。我们的工作叫做Deep Snake,其实就是用深度学习的方法实现了传统snake。传统snake做图像分割的时候要求先给定一个initial contour。这个contour大概围绕着目标物体。
Active contour models将节点坐标作为变量,通过最小化目标函数来优化节点坐标。这个目标函数一般由两个部分组成,一个是image term,用来将contour拉向图像中的目标位置。一个是contour term,用于约束contour的形状,比如让contour保持一定的smoothness,节点之间不要交叉。
传统snake的一个很大问题是他的目标函数和optimization都是handcrafted的,对数据的噪声比较敏感,容易收敛到局部最优点。为了解决这个问题,Deep Snake用deep learning来做这个优化过程。
问题1: 如何得到Initial contour
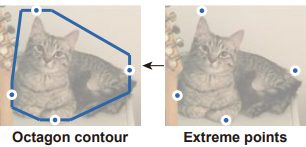
传统的active contour models要求有一个比较准确的initial contour才能比变形得比较好,所以initial contour对后续的变形挺重要的。受到ExtremeNet [4] 的启发,我们用物体extreme points来构造initial contour。物体的extreme point是物体在图片中最上边、最左边、最下边和最右边的点。我们在每个点上延伸出一条线段,然后将线段连接起来,得到一个八边形,把这个八边形作为initial contour。
问题2: 怎么处理fragmented instances
因为遮挡的原因,图片中的物体可能会分成多段。比如图中的车,因为柱子的遮挡,就分成了不连续的三段。要分割这辆车,就需要分别分割它的三段part,也就需要三个contour。但是根据前面的pipeline,一个矩形框只会出一个contour,所以无法处理fragmented instances。
为了解决这个问题,我们提出了Multi-component detection。给定一个物体矩形框,我们在矩形框里做二次检测,用于检测出物体的各个不连续的part。这里的检测器可以用已有的任意的detector,我们用的是CenterNet [5]。
实例分割新思路: Deep Snake (CVPR20'Oral Paper)
1.2.2 YOLACT: Real-time Instance Segmentation
该项目我实际测试过,效果不错,对细节分割较好
YOLACT将问题分解为两个并行的部分,利用 fc层(擅长产生语义向量)和 conv层(擅长产生空间相干掩模)来分别产生“掩模系数”和“原型掩模” 。 然后,因为原型和掩模系数可以独立地计算,所以 backbone 检测器的计算开销主要来自合成(assembly)步骤,其可以实现为单个矩阵乘法。 通过这种方式,我们可以在特征空间中保持空间一致性,同时仍然是一阶段和快速的
注意:为了能够通过线性组合来得到最终想要的mask,能够从最终的mask中减去原型mask是很重要的。换言之就是,mask系数必须有正有负。所以,在mask系数预测时使用了tanh函数进行非线性激活,因为tanh函数的值域是(-1,1).
补充1:为什么YOLACT使用Convs预测proto masks,而使用FC来预测mask系数?
因为mask天然存在空间相关性,Convs可以利用这种相关性,而FC不行,FC更适合做一些数值回归和概率预测等。因此,YOLACT中使用Convs来产生原型mask,而使用FC来预测对应的mask系数。
补充2:为什么增加protonet中产生的原型mask的数量(k)不一定有益于提高mAP?
因为一方面,预测一组系数向量本身是一个比较困难的问题;另一方面,在作mask合并时,即使只有一个系数预测的偏差较大,可能也会严重影响最终合成出的mask质量。所以,单方面增加k不一定奏效,考虑到分解研究中提到的各原型mask的作用可扩展,k的大小设置合理即可。
加州大学提出:实时实例分割算法YOLACT,可达33 FPS/30mAP!现已开源!
1.2.3 PolarMask: Single Shot Instance Segmentation with Polar Representation
不同于 Mask RCNN 等网络 先检测再分割,PolarMask提出了一种新的instance segmentation建模方式,通过寻找物体的contour建模,
两种实例分割的建模方式:
1、像素级建模 类似于图b,在检测框中对每个pixel分类(如 Mask RCNN等);
2、轮廓建模 类似于图c和图d,其中,图c是基于直角坐标系建模轮廓,图d是基于极坐标系建模轮廓。
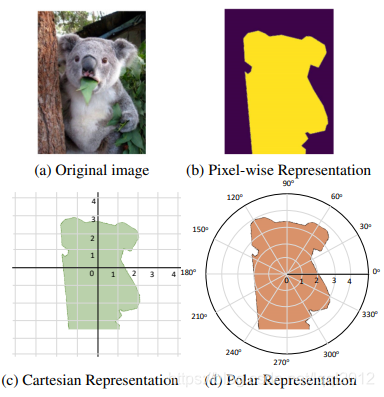
基于极坐标系的方式已经将固定角度设为先验,网络只需回归固定角度的长度即可,简化了问题的难度。PolarMask 基于极坐标系建模轮廓,把实例分割问题转化为实例中心点分类(instance center classification)问题和密集距离回归(dense distance regression)问题。
同时,我们还提出了两个有效的方法,用来优化high-quality正样本采样和dense distance regression的损失函数优化,分别是Polar CenterNess和 Polar IoU Loss。
PolarMask的特点:
- anchor free and bbox free,不需要出检测框
- fully convolutional network, 相比FCOS把4根射线散发到36根射线,将instance segmentation和object detection用同一种建模方式来表达。
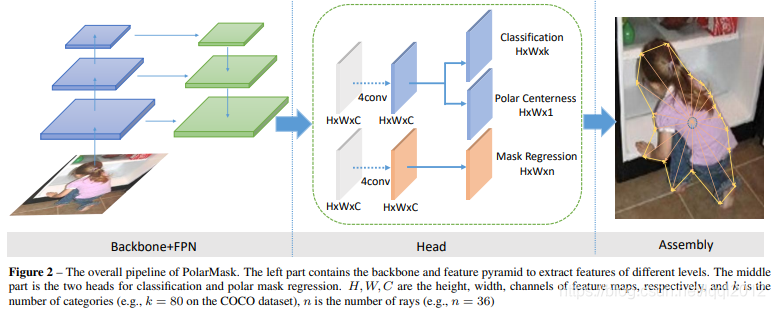
1) Polar Segmentation建模
首先,输入一张原图,经过网络可以得到中心点的位置和n(n=36 is best in our setting)根射线的距离,其次,根据角度和长度计算出轮廓上的这些点的坐标,从0°开始连接这些点,最后把联通区域内的区域当做实例分割的结果。
在实验中,我们以重心为基准,assign到feature map上,会在重心周围采样,作为正样本,别的地方当做负样本,训练方式和FCOS保持一致,采用Focal Loss, 在此,我们提出Polar CenterNess,用来选择出高质量的正样本,给低质量的正样本降低权重。
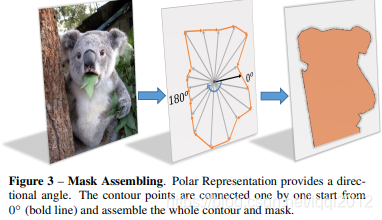
2) Polar CenterNess
如何在Polar Coordinate下定义高质量的正样本?我们通过如下公式定义
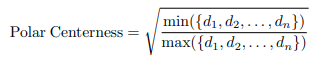
其中 d1 d2....dn指的是36根射线的长度,最好的正样本必须具备dmin ——> dmax.实质就是最短的射线和最长的射线之比,应该是力求center位于对象的中心吧) 用一张图举例:

以看到中间的图,会出现长度回归差别很大的问题,而右边的图中心点位置就较为合适,到所有轮廓的长度回归就较为接近,36根射线的距离会比较均衡。Polar Centerness 可以给右边图的点较高的centerness分数,给中间图的点降低centerness分数,这样在infernece的时候右边图的点分数较高。根据消融实验,Polar Centerness可以有效提高1.4的性能,同时不增加网络复杂度
3) Polar IoU Loss
在PolarMask中,需要回归k(k=36)根射线的距离,这相比目标检测更为复杂,如何监督regression branch是一个问题。我们提出Polar IoU Loss近似计算出predict mask和gt mask的iou,通过Iou Loss 更好的优化mask的回归。通过实验证明,Polar IoU Loss相比Smooth L1loss可以明显提高2.6个点,同时Smooth L1loss还面临和其他loss不均衡的问题,需要精心调整权重,这是十分低效的,Polar IoU loss不需要调整权重就可以使mask分支快速且稳定收敛
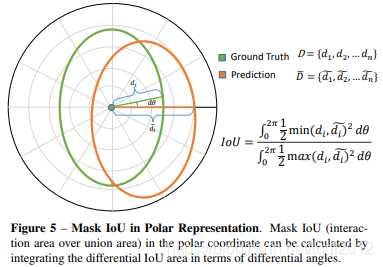
可以看到 两个mask的Iou可以简化为在dθ下的三角形面积iou问题并对无数个三角形求和,最终可以推导到如下形式:
掩膜IoU的计算如下:(这里IoU是根据定义进行计算的,对于每个微分角度 Δθ 而言,相交的扇形面积可以近似为![]() ,相并的面积同理,最后用积分求和就行)
,相并的面积同理,最后用积分求和就行)
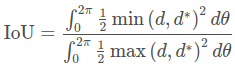
其中回归目标d 和预测 d^{∗} 是射线的长度,角度为θ。 然后我们将其转换为离散形式: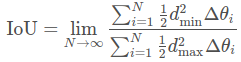
当N接近无穷大时,离散形式等于连续形式。 我们假设射线是均匀发射的,所以 ![]() ,这进一步简化了表达式。 根据我们的经验,平方形式对性能几乎没有影响(±0.1 mAP差异),如果可以舍弃并简化为以下形式:
,这进一步简化了表达式。 根据我们的经验,平方形式对性能几乎没有影响(±0.1 mAP差异),如果可以舍弃并简化为以下形式:
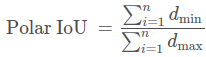
Polar IoU损失是Polar IoU的二进制交叉熵(BCE)损失。 由于最佳IoU始终为1,损失实际上是Polar IoU的负对数

我们提出的Polar IoU损失具有两个有利的特性:
(1)可微分,实现反向传播; 而且很容易实现并行计算,从而促进了快速的训练过程。
(2)整体预测回归目标。 与我们的实验中显示的“ ![]() ”损失相比,它大大提高了整体性能。
”损失相比,它大大提高了整体性能。
(3)另外,Polar IoU损失能够自动保持分类损失与密集距离预测的回归损失之间的平衡。 我们将在实验中对其进行详细讨论
PolarMask:将实例分割统一到FCN,有望在工业界大规模应用
1.2.4 PointRend
采用了 grid_sample 操作,这个tensor 操作移动端基本上不支持,需要更换
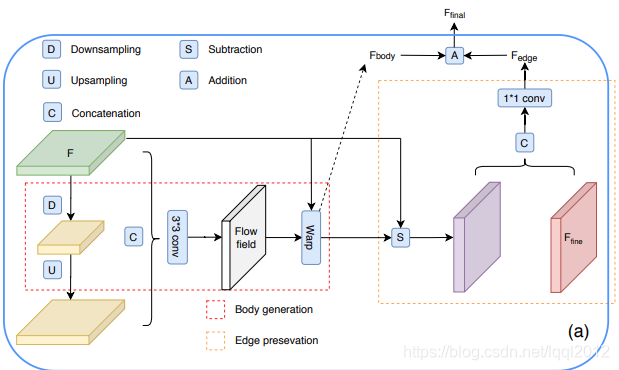
1.2.5 DecoupleSegNets : Improving Semantic Segmentation via Decoupled Body and Edge Supervision
语义分割方法需要明确地建模目标对象的主体(body)和边缘(edge),这对应于图像的高频和低频信息。为此,本文首先通过warp图像特征来学习 flow field 使目标对象主体部分更加一致。在解耦监督下,通过对不同部分(主体或边缘)像素进行显式采样,进一步优化产生的主体特征和残余边缘特征;
第一是建模物体内部语义信息的一致性,第二个是如何尽可能保留细节信息,提升边缘分割的效果。针对第一个问题,目前主流的方法都是去建模更好的上下文信息。比如图 1 中的 PSPnet,Deeplab 系列,还有近期比较火的基于 non-local 模型的一些网络 CCnet 和 EMAnet,以及近期使用 Graph Convolution Network 建模上下文的 DGMNet。针对第二个问题,现有的一些解决方案是把较低层特征经过融合的方式来提升小物体和边缘的分割效果。比如 Gated-SCNN 和 GFFnet。
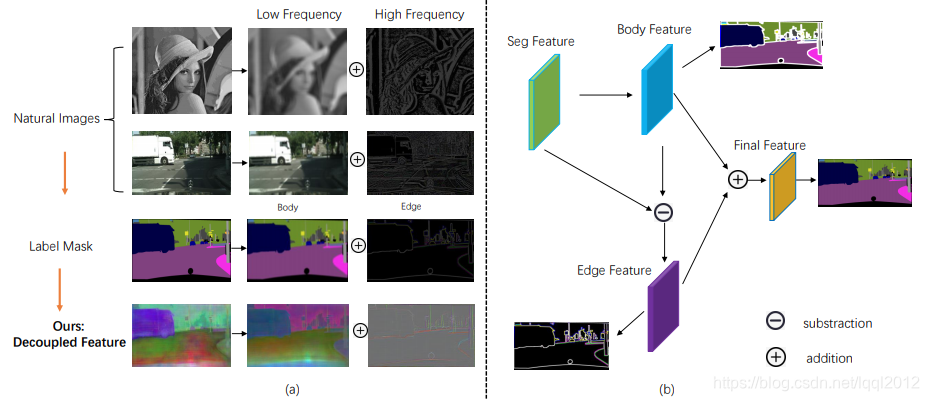
思考是否有一种统一的方法来同时做到这两件事情。在传统的图像处理方式中,一张自然图片可以被分解成高低频率项,其中低频项中包括粗糙的模糊化的信息,而高频项中包含更多细节信息,比如边缘。我们进一步对分割的监督 mask 进行如此操作,可以观察到相同的现象,边缘信息可以通过对把原始的主体部分减去得到,并且更加明显
如上图所示,首先将分割特征分为 body 特征和 edge 特征,然后对这两部分进行专门设计的损耗监督。 然后合并两个改进的功能以进行最终预测。
1)解耦的语义分割框架
给定一个特征图H×W×C,其中C表示通道尺寸,H×W表示空间分辨率,所提出的模块输出具有相同大小的细化特征图。特征图可以分解为body主体部分和edge边缘部分。在本文中,假设它们满足加法规则,这意味着特征图F:F = F_body + F_edge。本文模型目标是设计具有特定监督权的组件,分别处理每个部分。
因此,首先通过执行Body部分,然后通过显式减法获得边缘部分。主体生成模块旨在聚集对象内部的上下文信息并为每个对象形成清晰的主体对象。边缘保留模块用来保留更多的边缘信息,学习到更好的边缘特征。这两个模块采用不同的损失函数进行监督训练
2)主体生成模块
主体生成模块负责为同一对象内的像素生成更一致的特征表示。因为物体内部的像素彼此相似,而沿边界的像素则显示出差异,因此可以显式地学习主体和边缘特征表示,为此,我们采用学习流场的方式(flow field),并使用 flow field 对原始特征图进行 warp 以获得显式的主体特征表示。该模块包含两个部分:flow field 生成和特征差值。
- Flow field generation 流场生成
为了生成主要指向对象内部的流场,突出对象中心部分的特征作为显性引导是一种合理的方法。一般来说,低分辨率的特征图(或粗表示)往往包含低频项。低空间频率项捕捉了图像的总和,低分辨率特征图代表了最突出的部分,在这里我们将其视为伪中心位置或种子点的集合。如下图所示,我们采用了编码器-解码器的设计,编码器将特征图下采样为低分辨率表示,并有较低的空间频率部分,这里我们采用三次连续的 3×3 深度卷积来实现。对于 flow field 的生成,与 FlowNet-S 中做法一样。我们首先将低频特征图上采样插值到与原始特征图相同的大小,然后将它们连在一起,并应用 3×3 卷积层来预测流场。由于我们得模型都是基于带孔型的主干网络,因此这里 3×3 的卷积核足够大,在大多数情况下可以获取到像素之间的长距离依赖关系。

- Feature warping 特征差值
我们使用可微分的双线性采样机制进行插值生成主体部分的每个点, 其过程如下面公式所示:
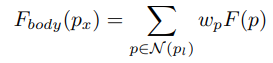
其中,从Flow特征图δ计算出的wp代表了扭曲空间网格上的双线性核权重。N代表所涉及的相邻像素。经过特征差值后,得到了主体部分的特征表示
- Edge Preservation Module边缘保留模块
![]()
边缘保留模块旨在处理高频项。它还包括两个步骤:
- 从原始特征图F中减去主体特征图;
- 添加更精细的细节信息的低级特征作为补充。
首先,从原始输入特征图F中减去主体特征,添加了额外的低级特征输入,以补充缺少的细节信息,以增强主体特征中的高频项。
最后,将两者连接起来,并采用1×1卷积层进行融合。该模块可以用下面等式表示,其中γ是卷积层并且表示级联运算。
- Decoupled body and edge supervision解耦的损失函数
![]()
其中: ˆs 表示 ground-truth (GT) 语义标签, ˆb i是通过 ˆs 产生的 GT 二值mask
针对主体部分,采用边缘松弛的损失函数,即忽略掉边缘部分的像素,只优化主体部分(公式3的第一项)。
针对边缘部分,首先用边缘保留模块的特征去预测边缘的二值mask。其次通过这个预测的Mask采用困难样本挖掘的策略,在最后特征预测的结果上进行进行loss的计算,最后用优化后的主体和边缘特征相加后的特征进行最后的特征表示
问题:对于语义分割,大多数最难分类的像素位于对象类之间的边界上。 此外,当可能有一半或更多的输入上下文可能是新类别时,对接受区域的中心像素进行分类并不容易
为了解决这个问题,我们建议在处理边界像素之前使用这种边缘,并在训练过程中以给定的边缘阈值tb进行在线困难样本挖掘。 总 loss 包含两个条件:Lbce是边界像素分类的二进制交叉熵损失,而Lce表示场景边缘部分的交叉熵损失
![]()
设置 λ4= 25和λ5= 1设置为平衡边缘上的像素数量。
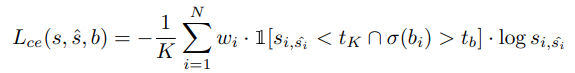
![]() tb = 0.8
tb = 0.8
σ代表Sigmoid函数,指示s是否在边界上
1.2.6 SegFix: Model-Agnostic Boundary Refinement for Segmentation
本文提出了一种模型无关的后处理方案,即用内部像素的预测代替原来不可靠的边界像素预测,以提高由任何现有分割模型生成的分割结果的边界质量。该方法仅对输入图像进行两步处理:(i) 定位边界像素;(ii) 识别每个边界像素对应的内部像素(通过学习从边界像素到内部像素的方向来建立对应关系)
动机分析:现有的分割模型大多不能很好地处理边界上的误差预测。作者对比了三个模型的直方图误差统计,如图2(错误像素数到物体边缘的距离的统计)可以看到,距离越大的像素越有可能被很好地分类,并且有很多误差分布在沿边界约为5像素的范围内

所以首要的问题在于:
- 如何确定边缘像素?
- 如何关联边缘像素与内部像素?
这里主要借助于一个边缘预测分支和一个方向预测分支来完成。在获得良好的边界和方向预测之后,就可以直接拿来优化现有方法预测的分割图了。所以另一个问题在于,如何将现有的针对边缘的关联方向的预测应用到实际的预测优化上。这主要借助于一个坐标偏移分支
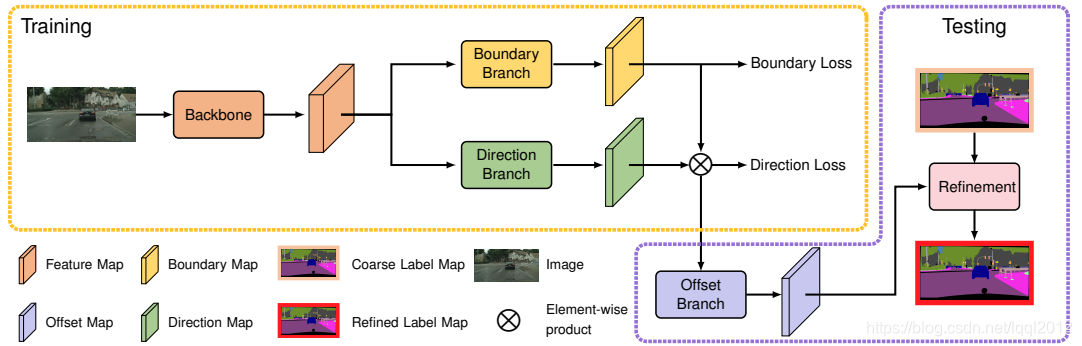
具体方法:在训练阶段,我们首先将图像输入到主干网络中来预测特征图,然后应用边界分支预测二值边界图和应用方向分支预测方向图,我们将边界损失和方向损失分别应用到预测的边界图和方向图上。在测试阶段,我们首先将模型执行到图像上,以生成偏移量映射,然后根据偏移量图对现有方法的分割结果进行细化
1.2.7 Semantic Flow for Fast and Accurate Scene Parsing
问题:
空间信息 以及 语义信息。一般来说,高分辨率的特征图对应着丰富的空间细节信息,但同时会带来过大的计算量;与之相反的是,具有强语义信息的特征图一般分辨率较小,但会缺乏足够的空间细节信息,不利于目标的精确定位。这两者通常来说是互相制约的
常用方法:
通常来说,提高语义分割性能的一种方法是获得具有强语义代表性的高分辨率特征图。有两种方法被广泛采用——空洞卷积以及特征金字塔融合,第一种需要较大的计算量,第二种不够高效
本文方法:
作者提出了一种FAM(Flow Alignment Module),即流对齐模块的方法来学习相邻尺度特征图之间的语义流。通过结合FPN结构,实现了快速又精确的结果。即通过预测流场(flow field)来对齐两个相邻层级的特征图
语义分割一般有两种框架:
第一种范式是类似于DeepLab和PSPNet之类的网络,利用一个强大的Backbone作为主要的特征提取,在网络的后半部分保留较高的分辨率,然后利用各自提取的模块来获取不同尺度的目标信息,最后再直接多倍上采样回去输出最终的分割图。
第二种范式是基于Encoder-Decoder结构。同样的,编码层利用一个带预训练的权重作为主要的特征提取,然后借助Skip Connection操作,在解码层中逐步恢复原始图像的空间分辨率。这里最主要的步骤便是Skip Connection,说白了就是一个高低级特征的融合问题。这方面每年也有相当多的研究,比如U-Net就是直接将相邻层级的特征Concat起来;Link-Net则是将其Add起来;ICNet提出一个级联特征融合CFF将其Fusion起来;另外还有很多利用注意力机制将其结合起来的,如将高低级特征结合起来,然后利用一系列的注意力操作来生成相应的权重图用于修正原来的低级特征图,最后再将两者融合起来等。
主流的框Encoder-Decoder架构,在编码层阶段通常是利用插值算法来恢复图像的分辨率,但是这种方法对会造成语义的不对齐的问题。此外,由于残差连接所引入的不对齐问题则更加复杂。因此,需要明确地建立特征映射之间的对应关系,以解决它们的误对齐。为了缓解这一问题,作者建议学习不同分辨率层之间的语义流(Semantic Flow
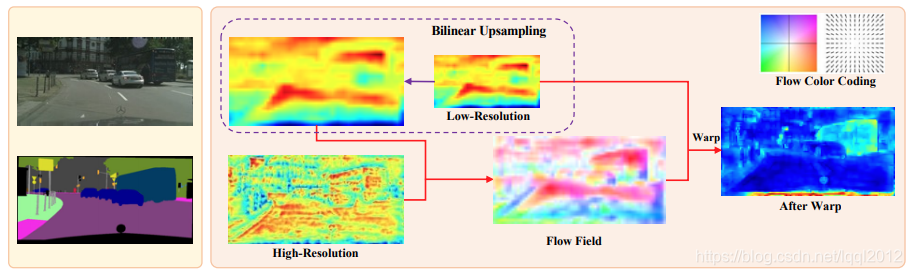
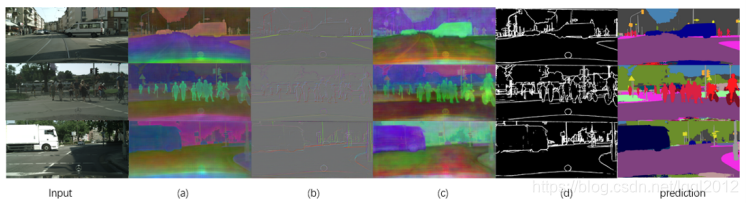
以上为中间可视化结果图,这里是通过基于通道对所有的特征图进行一个取平均操作所获得的。颜色越深代表预测概率值越大,反之亦然。
从结果图可以看出,经过FAM模块(最右手边)所获得的特征图比直接双线性上采样(中间左上角那幅图)更具有结构性,极大的减小了类内的差异性。
class AlignModule(nn.Module):
def __init__(self, inplane, outplane):
super(AlignModule, self).__init__()
self.down_h = nn.Conv2d(inplane, outplane, 1, bias=False)
self.down_l = nn.Conv2d(inplane, outplane, 1, bias=False)
self.flow_make = nn.Conv2d(outplane * 2, 2, kernel_size=3, padding=1, bias=False)
def forward(self, x):
low_feature, h_feature = x # low_feature 对应分辨率较高的特征图,h_feature即为低分辨率的high-level feature
h_feature_orign = h_feature
h, w = low_feature.size()[2:]
size = (h, w)
# 将high-level 和 low-level feature分别通过两个1x1卷积进行压缩
low_feature = self.down_l(low_feature)
h_feature = self.down_h(h_feature)
# 将high-level feature进行双线性上采样
h_feature = F.interpolate(h_feature, size=size, mode="bilinear", align_corners=False)
# 预测语义流场 === 其实就是输入一个3x3的卷积
flow = self.flow_make(torch.cat([h_feature, low_feature], 1))
# 将Flow Field warp 到当前的 high-level feature中
h_feature = self.flow_warp(h_feature_orign, flow, size=size)
return h_feature
@staticmethod
def flow_warp(inputs, flow, size):
out_h, out_w = size # 对应高分辨率的low-level feature的特征图尺寸
n, c, h, w = inputs.size() # 对应低分辨率的high-level feature的4个输入维度
norm = torch.tensor([[[[out_w, out_h]]]]).type_as(inputs).to(inputs.device)
# 从-1到1等距离生成out_h个点,每一行重复out_w个点,最终生成(out_h, out_w)的像素点
w = torch.linspace(-1.0, 1.0, out_h).view(-1, 1).repeat(1, out_w)
# 生成w的转置矩阵
h = torch.linspace(-1.0, 1.0, out_w).repeat(out_h, 1)
# 展开后进行合并,grid的大小指定了输出大小
grid = torch.cat((h.unsqueeze(2), w.unsqueeze(2)), 2)
grid = grid.repeat(n, 1, 1, 1).type_as(inputs).to(inputs.device)
grid = grid + flow.permute(0, 2, 3, 1) / norm
# grid指定由input空间维度归一化的采样像素位置,其大部分值应该在[ -1, 1]的范围内
# 如x=-1,y=-1是input的左上角像素,x=1,y=1是input的右下角像素。
# 具体可以参考《Spatial Transformer Networks》,下方参考文献[2]
output = F.grid_sample(inputs, grid)
return output上述代码中 是将低分辨率的特征图,通过grid_sample插值放大和加上 flow
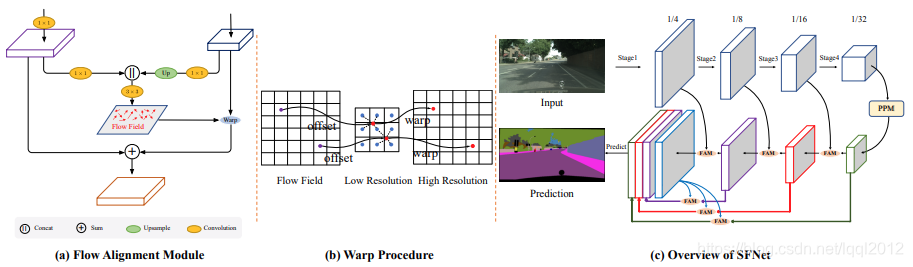
流对齐模块的细节图。 我们将变换后的高分辨率特征图和低分辨率特征图相结合,生成语义流场,用于将低分辨率特征图warp到高分辨率特征图。(b) 流对齐模块的Warp操作。高分辨率特征图的值是低分辨率特征图中相邻像素之间的双线性插值,其中根据学习的语义流场(即偏移量)来定义邻域。
1.3 语义分割思路
顶会顶刊paper看来看去真没啥突破:
(1)手动设计网络结构 -> NAS搜索;
(2)固定感受野 -> 引入空间注意力做感受野自动调节;
(3)效果提升不上去 -> 换个思路做实时分割来对比结果;
(4)自监督太热门 -> 引入弱监督 (GAN, 知识蒸馏, ...) + trick = 差不多的score;
(5)DNN太枯燥,融入点传统视觉的方法搞成end-to-end训练;
(6)CNN太单调,配合GCN搞点悬念;
(7)嫌2D太low逼,转3D点云分割;
链接:https://www.zhihu.com/question/390783647/answer/1221984335
A-注意力机制:SE ~ Non-local ~ CcNet ~ GC-Net ~ Gate ~ CBAM ~ Dual Attention ~ Spatial Attention ~ Channel Attention ~ ... 【只要你能熟练的掌握加法、乘法、并行、串行四大法则,外加知道一点基本矩阵运算规则(如:HW * WH = HH)和sigmoid/softmax操作,那么你就能随意的生成很多种注意力机制】
B-卷积结构:Residual block ~ Bottle-neck block ~ Split-Attention block ~ Depthwise separable convolution ~ Recurrent convolution ~ Group convolution ~ Dilated convolution ~ Octave convolution ~ Ghost convolution ~ ...【直接替换掉原始卷积块就完事了】
C-多尺度模块:ASPP ~ PPM ~ DCM ~ DenseASPP ~ FPA ~ OCNet ~ MPM... 【好好把ASPP和PPM这两个模块理解一下,搞多/减少几条分支,并联改成串联或者串并联结合,每个分支搞点加权,再结合点注意力或者替换卷积又可以组装上百种新结构出来了】
D-损失函数:Focal loss ~ Dice loss ~ BCE loss ~ Wetight loss ~ Boundary loss ~ Lovász-Softmax loss ~ TopK loss ~ Hausdorff distance(HD) loss ~ Sensitivity-Specificity (SS) loss ~ Distance penalized CE loss ~ Colour-aware Loss...
E-池化结构:Max pooling ~ Average pooling ~ Random pooling ~ Strip Pooling ~ Mixed Pooling ~...
F-归一化模块:Batch Normalization ~Layer Normalization ~ Instance Normalization ~ Group Normalization ~ Switchable Normalization ~ Filter Response Normalization...
G-学习衰减策略:StepLR ~ MultiStepLR ~ ExponentialLR ~ CosineAnnealingLR ~ ReduceLROnPlateau ~...
H-优化算法:BGD ~ SGD ~ Adam ~ RMSProp ~ Lookahead ~...
I-数据增强:水平翻转、垂直翻转、旋转、平移、缩放、裁剪、擦除、反射变换 ~ 亮度、对比度、饱和度、色彩抖动、对比度变换 ~ 锐化、直方图均衡、Gamma增强、PCA白化、高斯噪声、GAN ~ Mixup
J-骨干网络:LeNet ~ ResNet ~ DenseNet ~ VGGNet ~ GoogLeNet ~ Res2Net ~ ResNeXt ~ InceptionNet ~ SqueezeNet ~ ShuffleNet ~ SENet ~ DPNet ~ MobileNet ~NasNet ~ DetNet ~ EfficientNet ~ ...


















 2156
2156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









