






文章目录
- Linux
- Python
- 菜鸟教程
- 索引
- input
- format()
- 算术运算符
- 比较运算符
- 赋值运算符
- 逻辑运算符
- if
- 循环
- 取整
- Python获取int最大值和float最大值
- 排序
- ASCII
- enumerate()
- int()
- map()
- 进制转换
- list&string转换
- datatime
- Python 中re.split()方法
- Python 集合set()使用
- bin(num).count('1')
- num.bit_length()
- collections.Counter
- sort()
- ListNode
- List
- 判断是否为整数
- 取余
- itertools之排列组合迭代器(Combinatoric Iterators)
- String
- 位运算
- 进制表示
- Python 里面的reduce函数和lambda
Linux
- ls: 查看目录
- cd / :表示进入根目录,它是一切目录的父目录
- cd …:可以回到上一级目录,类似 Windows 的「向上」
- cd - :表示回到上一次所在的目录,类似 Windows 的「后退」
- cd ~:表示回到当前用户的主目录,类似 Windows 的「回到桌面」
- tree :列出一个文件夹下的所有子文件夹和文件(以树形结构来进行列出)
- pwd :获取当前目录的绝对路径
- mkdir:创建目录
- mkdir
后加入-p参数,一次性创建多级目录 - touch :新建文件
- cp :(Copy)复制文件到指定目录下
- cp:还可复制目录,eg. cp -r 目录名 目标目录名
- rm:删除文件
- mv :移动文件或目录,eg. mv 文件名 目录名
- mv:还可用来重命名,如mv test1 test2, 会把test1重命名为 test2
- cat:将文件中的内容打印到屏幕上,使用方法是 cat 文件路径
- cat -n:带行号地打印文件内容
Python
python3:进入环境(Linux)
快捷键Ctrl+D/输入exit():退出环境(Linux)
\:转义字符 \n:回车
#:注释
‘’’ ‘’':多行注释
菜鸟教程
https://www.runoob.com/python/python-tutorial.html
索引
位置的编号,从0开始计数
索引可以是负数,表示倒数第几个,例如最后一个字符索引为-1
input
输入代码:
age = input('My age is :')
执行代码后,弹出「My age is :」,在后面输入年龄,再按回车,age获得输入的值
format()
format()是专门用来 格式化字符串 的函数,它最常用的功能就是「插入数据」和「数字格式化」
插入数据:
输入姓名和年龄,用 name 和 age 变量接收数据
name = input('请输入姓名:')
age = input('请输入年龄')
打印 “你叫 xxx,今年 x 岁了
第一种:用 + 号串联打印的内容,虽然可行,但是比较麻烦,而且有局限性:
print('你叫'+name+',今年' + age + '岁了')
第二种:用format() 函数,实现插入效果:
print('你叫{},今年{}岁了'.format(name,age))
{} 为占位符,我先把这个位置占住,具体数据在后面导入。

数字格式化:
format() 的第二种常用功能,是格式化数字,比如要输出圆周率,但只保留两位小数,可以这么写:
print("{:.2f}".format(3.1415926))
如果要保留三位,则改成 {:.3f};不带小数,则改成 {:.0f},依次类推。
算术运算符
| 运算符 | 名称 | 描述 |
|---|---|---|
| + | 加 | 两个对象相加 |
| - | 减 | 得到负数或是一个数减去另一个数 |
| * | 乘 | 两个数相乘或是返回一个被重复若干次的字符串 |
| / | 除 | x 除以 y |
| % | 取模 | 返回除法的余数 |
| ** | 幂 | 返回 x 的 y 次幂 |
| // | 取整除 | 返回商的整数部分(向下取整) |
比较运算符
返回True、False,通常用于程序执行 循环和判断 中:
| 运算符 | 描述 |
|---|---|
| == | 等于:比较对象是否相等 |
| != | 不等于:比较两个对象是否不相等 |
| > | 大于:返回 x 是否大于 y |
| < | 小于:返回 x 是否小于 y |
| >= | 大于等于:返回 x 是否大于等于 y |
| <= | 小于等于:返回 x 是否小于等于 y |
赋值运算符
主要是为了简写
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 赋值运算符 | c = a + b :将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a :等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a :等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a :等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a :等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a :等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a :等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a :等效于 c = c // a |
逻辑运算符
即高中数学中的「 且、或、非 」,Python 中用 and、or、not 表示这三种逻辑。
| 运算符 | 逻辑表达式 | 结果 |
|---|---|---|
| and(逻辑与) | a and b | 当 a、b 都为 True 时,返回 True;否则返回 False |
| or(逻辑或) | a or b | 当 a、b 任意一个为 True,就返回 True |
| not(逻辑非) | not a | 当 a 为 True 时,返回 False;反之亦然 |
if
if 判断条件1: #判断
if 判断条件2 and 判断条件3: #嵌套判断,同时满足条件2,3
执行1
else:
执行2
elif 判断条件4: #另一个条件,else if
if 判断条件5 or 判断条件6: #嵌套判断,满足条件5,6中一个
执行3
else:
执行4
else: # 不在提出的if条件内的其他情况
pass #跳过这个代码块,继续执行后面的代码
循环
for循环
for循环主要用于对一个范围内的每个元素进行指定操作。
语法如下:
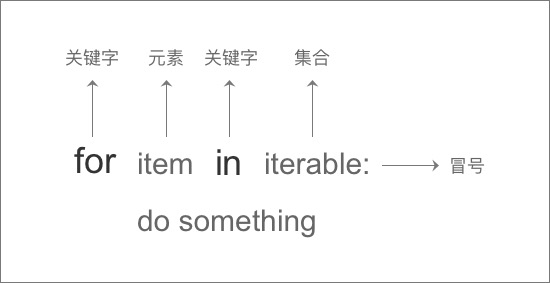
range() 函数
如果需要处理一组数字列表,并且数字列表满足一定的规律,可以使用 Python 的内置函数 range()(范围)。
range(x)函数:生成一个从 0 到 x-1 的整数序列
range(a,b):取区间[a,b-1]的数
while循环
for 循环 适用于 已知循环次数 的循环,所以后面跟的是次数或区间,到达指定次数就停止。
while 循环 适用于 未知循环次数 的循环,后面跟的是一个条件,只要条件满足,这个循环就会一直进行下去。
具体语法如下:

break 表示停止当前循环
continue 表示跳过当前循环轮次,去执行下一轮循环
取整
math.ceil()
向上取整,小数都是向着数值更大的方向取整,不论正负数
import math
math.ceil(-0.5)
>>>0
math.ceil(0.3)
>>>1
round()
四舍五入:
round()当不传入第二个参数时默认取整,具体就是按照四舍五入来。
PS:小数末尾为5时:5前为奇:向绝对值更大取整(如-1.5、1.5);5前为偶:去尾取整(如-2.5,-0.5,0.5,2.5)。
round(-2.5)
>>>-2
round(-1.5)
>>>-2
round(-0.5)
>>>0
round(0.5)
>>>0
round(1.5)
>>>2
round(2.5)
>>>2
math.floor()
简单且忠实地向下取整
math.floor(-0.3)
>>> -1
math.floor(0.9)
>>> 0
int()
向0取整,取整方向总是让结果比小数的绝对值更小
int(-0.5)
>>> 0
int(-0.9)
>>> 0
int(0.5)
>>> 0
int(0.9)
>>> 0
// 向下取整
向下取整,与math.floor()处理结果一样
(-1) // 2 # -0.5
>>> -1
(-3) // 2 # -1.5
>>> -2
1 // 2 # 0.5
>>> 0
3 // 2 # 1.5
>>> 1
Python获取int最大值和float最大值
int型
import sys
MAX_INT=sys.maxsize
print(MAX_INT)
float型
max_float=float('inf')
最大的浮点数就是这个 inf
排序
list的sort()函数
list.sort(key=None, reverse=Falsee)
- sort()函数没有返回值
- key表示排序依据的函数
- reverse表示需不需要反转列表,默认为False表示升序,True表示降序。
key的设置:
from functools import cmp_to_key
key = None #不使用key
key = lamda x : x * (-1) #匿名函数,lambda :f(x) = -x
key = abs #系统内置函数或自定义函数
key = cmp_to_key(cmp) #通过cmp_to_key函数将传统cmp函数转成key
sorted()
sorted(iterable, *, key=None, reverse=False)
- sorted()返回值类型为List
- 参数列表iterable表示可迭代对象
- *表示位置参数就此终结,后面的参数必须用关键字来指定
- key和reverse用法同sort()
dic = {'a':2, 'b':3, 'c':0, 'd':1}
L = sorted(dic.keys(), key = lambda x : x[1])
print(L)
>>>['c', 'd', 'a', 'b']
ASCII

ord(a) #字符a对应ASCII值
chr(i) #ASCII值对应字符
enumerate()
将一个可遍历的数据对象组合成一个索引序列,同时列出数据和数据下标,一般用在for循环中。
enumerate(sequence, [start=0])
- sequence为一个序列、迭代器或其他支持迭代的对象
- start为下标起始位置
for i, item in enumerate(items):
print i, item
int()
class int(x,base = 10)
- x 字符串或者数字
- base-进制数,默认十进制
map()
map(function, iterable, ...)
- function函数
- iterable一个或多个序列
- 输出Python3.x返回迭代器,Python3.x返回列表
a_list = list(map(int,input().split()))
'''
input输入:1 2 3 4
map(int,input().split()
函数:int
序列:input().split()
输出:<map object at 0x100d3d550> 返回迭代器
list() 转换成列表
'''
进制转换
9进制(3021)转10进制:1*9^0 + 2*9^1 + 0*9^2 + 3*9^3 = 2206
10进制(2206)转9进制:2206/9=245…1 245/9=27…2 27/9=3…0 9进制即为3021
list&string转换
s = 'asdfghjklkjhgfds' #字符串
l = list(s) #字符串转列表
s = ''.join(l) #列表转字符串
ll = ['a', 'b', 'c']
s1 = ''.join(l) #>>>"abc"
s2 = ' '.join(l) #>>>"a b c"
s3 = ','.join(l) #>>>"a,b,c"
datatime
begin = datetime.date(2022, 1, 1)
end = datetime.date(2022, 12, 31)
day = datetime.timedelta(days=1)
Python 中re.split()方法
re.split()切割功能非常强大
>>> import re
>>> line = 'aaa bbb ccc;ddd eee,fff'
>>> line
'aaa bbb ccc;ddd eee,fff'
单字符切割
>>> re.split(r';',line)
['aaa bbb ccc', 'ddd\teee,fff']
两个字符以上切割需要放在 [ ] 中
>>> re.split(r'[;,]',line)
['aaa bbb ccc', 'ddd\teee', 'fff']
所有空白字符切割
>>> re.split(r'[;,\s]',line)
['aaa', 'bbb', 'ccc', 'ddd', 'eee', 'fff']
使用括号捕获分组,默认保留分割符
>>> re.split(r'([;])',line)
['aaa bbb ccc', ';', 'ddd\teee,fff']
不想保留分隔符,以(?: …)的形式指定
>>> re.split(r'(?:[;])',line)
['aaa bbb ccc', 'ddd\teee,fff']
Python 集合set()使用
在python3中按数据类型的可变与不可变大致分为如下几种类型:
不可变数据(3个):Number(数字)、String(字符串)、Tuple(元组);
可变数据(3个):List(列表)、Dictionary(字典)、Set(集合)。
1.集合的特点
无序不重复没有重复的元素,且元素无序存放(故集合没有下标和切片),set的只要作用就是用来给数据去重。
使用时为 { },与字典区分:当花括号里的元素不是键值对的时候为集合。
集合的底层其实是通过字典来封装的
2.set的建立
可以使用大括号 { } 或者 set() 函数创建集合,但是注意如果创建一个空集合必须用 set() 而不是 { },因为{}是用来表示空字典类型的。
1.用set()函数创建set集合
person2 = set(("hello","jerry",133,11,133,"jerru"))
#只能传入一个参数,可以是list,tuple等 类型
print(len(person2))
print(person2)
'''
5
{133, 'jerry', 11, 'jerru', 'hello'}
'''
2.add()
a=set()
a.add("a")
a.add("b")
print(a)
3.用{}创建set集合。空set集合用set()函数表示,不可a={}。
person ={"student","teacher","babe",123,321,123} #同样各种类型嵌套,可以赋值重复数据,但是存储会去重
print(len(person)) #存放了6个数据,长度显示是5,存储是自动去重
print(person) #但是显示出来则是去重的
'''
5
{321, 'teacher', 'student', 'babe', 123}
'''
#空set集合用set()函数表示
person1 = set() #表示空set,不能用person1={}
print(len(person1))
print(person1)
'''
0
set()
'''
4.set集合的转化
a=["awe","weg","dawqgg"]
c=set(a)
print(c)
b="chenshuagege"
d=set(b)
print(d)
al=("233","34455")
aw=set(al)
print(al)
3.常见使用注意事项
#set对字符串也会去重,因为字符串属于序列。
str1 = set("abcdefgabcdefghi")
str2 = set("abcdefgabcdefgh")
print(str1,str2)
print(str1 - str2) #-号可以求差集
print(str2 - str1) #空值
#print(str1 + str2) #set里不能使用+号
====================================================================
{'d', 'i', 'e', 'f', 'a', 'g', 'b', 'h', 'c'} {'d', 'e', 'f', 'a', 'g', 'b', 'h', 'c'}
{'i'}
set()
4.set的常用方法
4.1 set集合的增删改查操作
- add 用于加入元素
- update 用于集合的合并
- remove 当移除一个集合里没有的元素时,报错
- discard 当移除一个集合里没有的元素时,不会报错
- del 仅可对集合本身使用,不可用于元素,因为元素在集合里为混乱排放,无下标
- clear 清空集合,留下空集合
- pop 随机删除集合里的一个元素
#1.给set集合增加数据
person ={"student","teacher","babe",123,321,123}
person.add("student") #如果元素已经存在,则不报错,也不会添加,不会将字符串拆分成多个元素,区别update
print(person)
person.add((1,23,"hello")) #可以添加元组,但不能是list
print(person)
'''
{321, 'babe', 'teacher', 'student', 123}
{(1, 23, 'hello'), 321, 'babe', 'teacher', 'student', 123, 1, 3}
'''
# update用于集合的合并,可以把多个集合添加到一个集合里面。可以iterar的数据都可以添加成set集合
person.update("abc")#使用update不能添加字符串,会拆分
print(person) #会将字符串拆分成a,b,c三个元素
'''
{321, 1, 3, 'b', 'c', 'teacher', (1, 23, 'hello'), 'a', 'babe', 'student', 123}
'''
set1 = set()
set1.add('武动乾坤')
set2 = {'jsy', '稻香', '爱的代价', '大碗宽面'}
set2.update(set1)
print(set2)
'''
{'大碗宽面', 'jsy', '爱的代价', '稻香', '武动乾坤'}
'''
#2.从set里删除数据
person.remove("student")#按元素去删除
print(person)
#print("student")如果不存在 ,会报错。
'''
{321, 1, 3, 'c', 'b', (1, 23, 'hello'), 'teacher', 'babe', 'a', 123}
'''
person.discard("student")#功能和remove一样,好处是没有的话,不会报错
ret = person.pop() #在list里默认删除最后一个,在set里随机删除一个。
print(person)
print(ret) #pop()返回的是被删除掉的那一项
'''
{1, 3, (1, 23, 'hello'), 'teacher', 'b', 'a', 'babe', 123, 'c'}
'''
#3.更新set中某个元素,因为是无序的,所以不能用角标
#所以一般更新都是使用remove,然后在add
#4.查询是否存在,无法返回索引,使用in判断
if "teacher" in person:
print("true")
else:
print("不存在")
'''
true
'''
#5.终极大招:直接清空set
print(person)
person.clear()
print(person)
'''
set()
'''
4.2 其它用法
交 并 差集操作,可用运算符表示交集,并集,差集
交集 intersection 或 &
并集 union 或 |
差集 difference 或 -
#取两者的交集
b={1,23}
a={23,5}
ret=b.intersection(a)
print(ret)
#取两者的交集,intersection_update会改变b的内容
b={1,23}
a={23,5}
b.intersection_update(a)
print(b)
#union是把两个set集合合起来
a={"a","b","c"}
b={"a","wa"}
wt=a.union(b)
print(wt)
#difference表示的意思是a中的内容b是没有的,但是这个不会修改a自身的值,而是付给ret了
a={"12","14","234"}
b={"12","23"}
ret=a.difference(b)
print(ret)
#difference_update表示的意思是a中的内容b是没有的,执行完,会修改a的内容
a={"12","14","234"}
b={"12","23"}
a.difference_update(b)
print(a)
#symmetric_difference为把两个set集合里相同的内容当作边然后取这边两边的内容
a={"a","b","c"}
b={"a","wa"}
ret=a.symmetric_difference(b)
print(ret)
a.symmetric_difference(b)
print(a)
#可用运算符表示交集,并集,差集
set2 = {1, 2, 3, 4, 5}
set3 = {3, 4, 5, 6, 7, 8, 9}
print(set2 & set3) # 交集符号 &
print(set2 | set3) # 并集符号 |
print(set2 - set3) # 差集符号 -
b={1,23}
a={23,5}
#如果a与b有集合的话,就返回false;如果没有集合的话,就返回true
ret=b.isdisjoint(a)
print(ret)
b={1,23,5}
a={23,5}
#issuperset说明b是否是a的父亲,如果是就输出true,如果不是输出false
ret=b.issuperset(a)
print(ret)
b={1,23,5}
a={23,5}
#b是否是a的子,如果是就输出true,如果不是就输出false
ret=b.issubset(a)
print(ret)
5.列表,元组,字典,集合 总结
list: 允许重复,有序,有下标,可切片
tuple: 允许重复,里面元素不能进行增删改,只能查看
dict: 字典里的元素以键值对的形式存在 键:唯一性 值:可以重复
set: 元素不允许重复,且具有无序性
5.1 它们之间的类型转换
- 列表,元组,集合,此三者均可相互转
list----->tuple,set 列表转集合时,注意不能有重复元素,否则长度改变
tuple----->list,set
set----->list,tuple - 当字典参与的转换时,需特殊对待
dict----->list,tuple 仅能将字典的键转换,不能将值转换
list----->dict 列表内必须是列表或是元组,且其中只有两个元素时,可转
list = [['a', {1}], ('', 2), ('c', 3)]
print(dict(list))
'''
{‘a’: {1}, ‘’: 2, ‘c’: 3}
'''
输出:
{‘a’: {1}, ‘’: 2, ‘c’: 3}
| 转换 | 代码 | 转换 | 代码 | |
|---|---|---|---|---|
| list转array | a1 = np.array(l1) | array转list | l1 = a1.tolist() | |
| list转set | s1 = set(l1) | set转list | l1 = list(s1) | |
| list转tuple | t1 = tuple(l1) | tupel转list | l1 = list(t1) | |
| array转set | s1 = set(a1) | set转array | a1 = np.array(s1) | |
| array转tuple | t1 = tuple(a1) | tuple转array | a1 = np.array(t) | |
| set转tuple | t1 = tuple(s1) | tuple转set | s1 = set(t1) |
5.2 集合和列表方法上的区别
正是由于集合的无序性,没有下标,故在方法上与列表有些差异。
- append(添加元素) extend(实现列表的拼接) insert(在某一下标插入元素) ----->list
- add(添加元素) update(两个集合的合并) ---->set
bin(num).count(‘1’)
bin(num).count('1')
# bin()函数得到num的2进制数
# .count('1')得到2进制数中1的个数
num.bit_length()
num.bit_length()
# 得到num 2进制数的长度
collections.Counter
哈希表在python中可以用collections.Counter计数来体现。
该方法用于统计某序列中每个元素出现的次数,以键值对的方式存在字典中。但类型其实是Counter。
nums = [1, 2, 3, 1, 2, 1]
counts = collections.Counter(nums)
print(counts)
## Counter({1: 3, 2: 2, 3: 1})
凭借这个结构,可以计算出某个序列中出现次数最多的某个元素。也即在得到了counts之后求max即可。但这个max需要给依据索引。
print(max(counts)) # 3,这里只是求得最大的键值
print(max(counts.keys(), key=counts.get)) # 1,这里是按照key方法求最大
这里max是两个参数,前一个代表要max的是什么,也就是要返回最大键,后面的key代表要返回的最大的依据是什么,默认是本身,但这里给了key方法,count.get也就是求值,所以该方法就是说返回一个最大键,但这个最大的依据是值。如果某个键值对的值是最大的,那就返回其键。
这里max是两个参数,前一个代表要max的是什么,也就是要返回最大键,后面的key代表要返回的最大的依据是什么,默认是本身,但这里给了key方法,count.get也就是求值,所以该方法就是说返回一个最大键,但这个最大的依据是值。如果某个键值对的值是最大的,那就返回其键。
sort()
正序排序
a=[2,6,3,8,1,34,88]
a.sort(reverse=False)
print(a)
# >>> [1,2,3,6,8,34,88]
降序排序
a=[2,6,3,8,1,34,88]
a.sort(reverse=True)
print(a)
# >>> [88,34,8,6,3,2,1]
ListNode
Leetcode官方定义的链表:
# Definition for singly-linked list.
class ListNode(object):
def __init__(self, val=0, next=None):
self.val = val
self.next = next
创建一个链表
可以使用如下方式:
head = None
for i in [4,3,2,1,0]:
head = ListNode(i,head)
首先让表头(最终会是最后一个元素)指向None,然后利用for循环依次添加这个链结的前一个元素。因此,最终获得的链表会是这样的:
遍历一个链表
这里使用一个列表来保存链表中元素的值。在每次获取head的值之后,向前移一位。由于是单链表,所以通过定义head2来保留链表的头部。否则,while循环遍历后将无法访问链表的元素。
value = []
head2 = head
while head:
value.append(head2.val)
head2 = head2.next
这里使用一个列表来保存链表中元素的值。在每次获取head的值之后,向前移一位。由于是单链表,所以通过定义head2来保留链表的头部。否则,while循环遍历后将无法访问链表的元素。
List
list = [1,2,3,4,5]
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| [‘Hi!’] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print x, | 1 2 3 | 迭代 |
| list[2]3 | 3 | 列表下标为2的值 |
| list[2:] | [3,4,5] | 列表下标为2的值开始到列表结尾 |
| list[:2] | [1,2] | 列表开头到第2个值 |
| list[-2]4 | 4 | 列表倒数第二个值 |
Python list包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2)比较两个列表的元素 |
| 2 | len(list)列表元素个数 |
| 3 | max(list)返回列表元素最大值 |
| 4 | min(list)返回列表元素最小值 |
| 5 | list(seq)将元组转换为列表 |
Python list包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq)列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj)从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj)移除列表中某个值的第一个匹配项 |
| 8 | list.reverse()反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False)对原列表进行排序 |
**PS:**列表不能单纯的list1=list2,这样list2变化时list1也会变,用list.extend(seq)。
反转列表:
class Solution(object):
def reverseString(self, s):
"""
:type s: List[str]
:rtype: None Do not return anything, modify s in-place instead.
"""
# l = len(s)
# for i in range(int(l/2)):
# s[i], s[l - i - 1] = s[l - i - 1], s[i]
#s.reverse()
s[:] = s[::-1] #PS:也可以用于字符串的反转
# l ,r = 0, len(s) - 1
# while l < r:
# s[l], s[r] = s[r], s[l]
# l, r = l + 1, r - 1
判断是否为整数
isinstance(a, int)
# 判断a是否是int整数
# 返回True or False
取余
d, mod = divmod(a, b) # 返回除数和余数
d = a//b # 取整
mod = a % b # 取余
itertools之排列组合迭代器(Combinatoric Iterators)
一、itertools.product
语法:itertools.product(iterables, repeat=1)
理解:product是乘积的意思,以笛卡尔乘积的形式去组合多个iterable对象里面的元素,并以元组的形式输出。
例子:
for i in itertools.product('ABC', 'xy'):
print(i)
time.sleep(0.5)
# 输出结果:
('A', 'x')
('A', 'y')
('B', 'x')
('B', 'y')
('C', 'x')
('C', 'y')
# 如果将第一行代码改为:for i in itertools.product('AB', repeat=3)那么输出的结果为:
('A', 'A', 'A')
('A', 'A', 'B')
('A', 'B', 'A')
('A', 'B', 'B')
('B', 'A', 'A')
('B', 'A', 'B')
('B', 'B', 'A')
('B', 'B', 'B')
二、itertools.permutations
语法:itertools.permutations(iterable, r=None)
理解:这个方法能将传入的iterable对象里面的元素以r的长度进行排列组合,特点是,每个元素不会与自身进行排列组合。
例子:
for i in itertools.permutations('ABC', 2):
print(i)
time.sleep(0.5)
# 输出结果为:
('A', 'B')
('A', 'C')
('B', 'A')
('B', 'C')
('C', 'A')
('C', 'B')
三、itertools.combinations
语法:itertools.combinations(iterable, r)
理解:输出iterable对象里长度为r的子序列,返回的子序列中的项按输入iterable中的顺序排序 (不带重复)
例子:
for i in itertools.combinations('ABC', 2):
print(i)
time.sleep(0.5)
# 输出结果为:
('A', 'B')
('A', 'C')
('B', 'C')
# 如果将第一行代码改为:for i in itertools.combinations('AAC', 2)则输出结果为:
('A', 'A')
('A', 'C')
('A', 'C')
四、itertools.combinations_with_replacement
语法:itertools.combinations_with_replacement(iterable, r)
理解:此处类似于itertools.combinations,但是唯一的区别在于这个方法允许元素自身和自身形成排列组合。
例子:
for i in itertools.combinations_with_replacement('ABC', 2):
print(i)
time.sleep(0.5)
# 结果输出为:
('A', 'A')
('A', 'B')
('A', 'C')
('B', 'B')
('B', 'C')
('C', 'C')
String
python用[]来截取字符串
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WVRGC4XL-1680883606962)(null)]
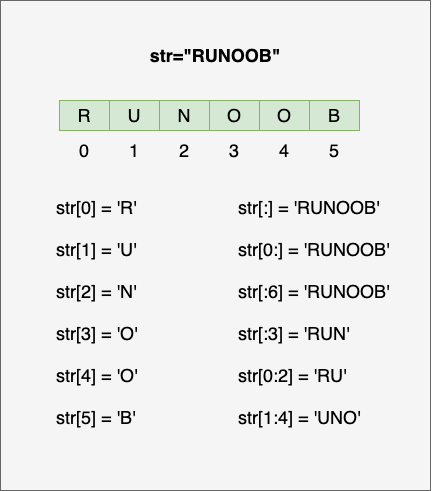
Python 字符串运算符
下表实例变量 a 值为字符串 “Hello”,b 变量值为 “Python”:
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| * | 重复输出字符串 | a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 ell |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | ‘H’ in a 输出结果 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | ‘M’ not in a 输出结果 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | print( r'\n' ) print( R'\n' )>>>\n |
Python 转义字符
在需要在字符中使用特殊字符时,python 用反斜杠 ** 转义字符。如下表:
| 转义字符 | 描述 | 实例 |
|---|---|---|
| (在行尾时) | 续行符 | >>> print("line1 \ ... line2 \ ... line3") line1 line2 line3 >>> |
| \ | 反斜杠符号 | >>> print("\\") \ |
| ’ | 单引号 | >>> print('\'') ' |
| " | 双引号 | >>> print("\"") " |
| \a | 响铃 | >>> print("\a")执行后电脑有响声。 |
| \b | 退格(Backspace) | >>> print("Hello \b World!") Hello World! |
| \000 | 空 | >>> print("\000") >>> |
| \n | 换行 | >>> print("\n") >>> |
| \v | 纵向制表符 | >>> print("Hello \v World!") Hello World! >>> |
| \t | 横向制表符 | >>> print("Hello \t World!") Hello World! >>> |
| \r | 回车,将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 | >>> print("Hello\rWorld!") World! >>> print('google runoob taobao\r123456') 123456 runoob taobao |
| \f | 换页 | >>> print("Hello \f World!") Hello World! >>> |
| \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 | >>> print("\110\145\154\154\157\40\127\157\162\154\144\41") Hello World! |
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | >>> print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21") Hello World! |
| \other | 其它的字符以普通格式输出 |
python字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
print ("我叫 %s 今年 %d 岁!" % ('小明', 10))
>>>我叫 小明 今年 10 岁!
Python 的字符串内建函数
| 序号 | 方法及描述 |
|---|---|
| 1 | capitalize() 将字符串的第一个字符转换为大写 |
| 2 | center(width, fillchar)返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| 3 | count(str, beg= 0,end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| 4 | bytes.decode(encoding=“utf-8”, errors=“strict”) Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
| 5 | encode(encoding=‘UTF-8’,errors=‘strict’) 以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| 6 | endswith(suffix, beg=0, end=len(string)) 检查字符串是否以 suffix 结束,如果 beg 或者 end 指定则检查指定的范围内是否以 suffix 结束,如果是,返回 True,否则返回 False。 |
| 7 | expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
| 8 | find(str, beg=0, end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| 9 | index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常。 |
| 10 | isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| 11 | isalpha() 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False |
| 12 | isdigit() 如果字符串只包含数字则返回 True 否则返回 False… |
| 13 | islower() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| 14 | isnumeric() 如果字符串中只包含数字字符,则返回 True,否则返回 False |
| 15 | isspace() 如果字符串中只包含空白,则返回 True,否则返回 False. |
| 16 | istitle() 如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| 17 | isupper() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| 18 | join(seq) 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| 19 | len(string) 返回字符串长度 |
| 20 | ljust(width[, fillchar])返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| 21 | lower() 转换字符串中所有大写字符为小写. |
| 22 | lstrip() 截掉字符串左边的空格或指定字符。 |
| 23 | maketrans() 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| 24 | max(str) 返回字符串 str 中最大的字母。 |
| 25 | min(str) 返回字符串 str 中最小的字母。 |
| 26 | replace(old, new [, max])把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 |
| 27 | rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找. |
| 28 | rindex( str, beg=0, end=len(string)) 类似于 index(),不过是从右边开始. |
| 29 | rjust(width,[, fillchar])返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| 30 | rstrip() 删除字符串末尾的空格或指定字符。 |
| 31 | split(str=“”, num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串 |
| 32 | splitlines([keepends])按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| 33 | startswith(substr, beg=0,end=len(string)) 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
| 34 | strip([chars])在字符串上执行 lstrip()和 rstrip() |
| 35 | swapcase() 将字符串中大写转换为小写,小写转换为大写 |
| 36 | title() 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| 37 | translate(table, deletechars=“”) 根据 table 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| 38 | upper() 转换字符串中的小写字母为大写 |
| 39 | zfill (width) 返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| 40 | isdecimal() 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |
位运算
位运算就是对二进制位的操作
| 位运算符 | 说明 |
|---|---|
| << | 按位左移,左移n位相当于乘以2的n次方 |
| >> | 按位右移 ,左移n位相当于除以2的n次方 |
| & | 按位与,二进制位数同且为1结果位为1 |
| l | 按位或 ,二进制位数或有1结果位为1 |
| ^ | 按位异或 ,二进制位数不同结果位为1 |
| ~ | 按位取反,二进制位0和1结果位互换 |
a=11
b=a<<3 # 将 a 左移三位
print(a)
print(b) # b=a*(2**3)
>>> 11
>>> 88
print(bin(a)[2:]) # 切片,去掉前面的:0b
print(bin(b)[2:]) # 二进制右边补上三个000
>>> 1011
>>> 1011000
进制表示
二进制,八进制,十进制,十六进制的表示方法
>>> 0b10 # 以0b开头表示的是二进制
2
>>> 0o10 # 以0o开头表示的是八进制
8
>>> 0x10 # 以0x开头表示的是十六进制
16
>>> 10 # 正常输入表示的是十进制
10
将其他进制的字符转换为二进制,使用函数bin()
>>> bin(10) # 十进制转换为二进制
'0b1010'
>>> bin(0b11) # 二进制转化为二进制
'0b11'
>>> bin(0o23) # 八进制转换为二进制
'0b10011'
>>> bin(0x2a) # 十六进制转换为二进制
'0b101010'
转为八进制使用oct()函数,转为十六进制使用hex()函数
获取ascII码使用ord()函数
Python 里面的reduce函数和lambda
a = [2,22,222]
Sn = reduce(lambda x,y:x+y,a)
其中reduce函数是python中的一个二元内建函数,它可以通过传给reduce中的函数(必须是二元函数)依次对数据集中的数据进行操作。例如上述代码传给reduce的函数是做加法,数据集是a,那么reduce函数的作用就是将数据集中的数据依次相加,最后打印出的结果就是246。
函数语法: reduce(function, iterable[,initializer])
函数参数含义如下:
1、function 需要带两个参数,1个是用于保存操作的结果,另一个是每次迭代的元素。
2、iterable 待迭代处理的集合
3、initializer 初始值,可以没有。
reduce函数的运作过程是,当调用reduce方法时:
1、如果存在initializer参数,会先从iterable中取出第一个元素值,然后initializer和元素值会传给function处理;
接着再从iterable中取出第二个元素值,与function函数的返回值 再一起传给function处理,以此迭代处理完所有元素。最后一次处理的function返回值就是reduce函数的返回值。
2、如果不存在initializer参数,会先从iterable中取出第一个元素值作为initializer值,然后以此从iterable取第二个元素及以后的元素进行处理。特殊情况下,如果集合只有一个元素,则无论function如何处理,reduce返回的都是第一个元素的值。
看例子:
reduce(lambda re,x:re+x,[2,4,6])
>>> 12
这里我们用的是lambda表达式(匿名函数),带两个参数,re就是指的是每次操作后的返回值,这里没带initializer参数,参数x就是代表集合中的元素。
第一轮操作时,re的初始值为第一个元素为2,x为第二个元素4, 运算后re的结果是6.
第二轮操作时,re的值就是上次的结果6,x的值为6,这样结果为12.
因为只有三个元素,又没有initializer参数,所以只会执行两轮。
reduce(lambda re,x:re+x,[2,4,6],10)
>>> 22.
这个例子传入了初始化参数10 ,这样re的初始化值为10.
有三个元素,需要操作三轮,结果就是22了
凡是要对一个集合进行操作的,并且要有一个统计结果的,能够用循环或者递归方式解决的问题,一般情况下都可以用reduce方式实现。在python 3.0.0.0以后, reduce已经不在built-in function里了, 要用它就得from functools import reduce。
而其中的lambd表达式是一种精简函数的表达方法,省略了函数的定义,命名等问题。
lambda表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
如下函数,定义了一个lambda的表达式,求三个数的和:
f = lambda x,y,z:x+y+x
print f(1,2,3)
>>> 4
f = lambda x,y,z:x+y+z
print f(1,2,3)
>>> 6
用lambda表达式求n的阶乘:
n = 5
print reduce(lambda x,y:x*y,range(1,n+1))
>>> 120
lambda表达式也可以用在def函数中:
def action(x):
return lambda y:x+y
a = action(2)
print a(22)
>>> 24
这里定义了一个action函数,返回了一个lambda表达式。其中lambda表达式获取到了上层def作用域的变量名x的值。
a是action函数的返回值,a(22),即是调用了action返回的lambda表达式。
这里也可以把def直接写成lambda形式。如下:
b = lambda x:lambda y:x+y
a = b(2)
print a(22)#print (b(2))(22)
>>> 24
取出第一个元素值作为initializer值,然后以此从iterable取第二个元素及以后的元素进行处理。特殊情况下,如果集合只有一个元素,则无论function如何处理,reduce返回的都是第一个元素的值。
看例子:
reduce(lambda re,x:re+x,[2,4,6])
>>> 12
这里我们用的是lambda表达式(匿名函数),带两个参数,re就是指的是每次操作后的返回值,这里没带initializer参数,参数x就是代表集合中的元素。
第一轮操作时,re的初始值为第一个元素为2,x为第二个元素4, 运算后re的结果是6.
第二轮操作时,re的值就是上次的结果6,x的值为6,这样结果为12.
因为只有三个元素,又没有initializer参数,所以只会执行两轮。
reduce(lambda re,x:re+x,[2,4,6],10)
>>> 22.
这个例子传入了初始化参数10 ,这样re的初始化值为10.
有三个元素,需要操作三轮,结果就是22了
凡是要对一个集合进行操作的,并且要有一个统计结果的,能够用循环或者递归方式解决的问题,一般情况下都可以用reduce方式实现。在python 3.0.0.0以后, reduce已经不在built-in function里了, 要用它就得from functools import reduce。
而其中的lambd表达式是一种精简函数的表达方法,省略了函数的定义,命名等问题。
lambda表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
如下函数,定义了一个lambda的表达式,求三个数的和:
f = lambda x,y,z:x+y+x
print f(1,2,3)
>>> 4
f = lambda x,y,z:x+y+z
print f(1,2,3)
>>> 6
用lambda表达式求n的阶乘:
n = 5
print reduce(lambda x,y:x*y,range(1,n+1))
>>> 120
lambda表达式也可以用在def函数中:
def action(x):
return lambda y:x+y
a = action(2)
print a(22)
>>> 24
这里定义了一个action函数,返回了一个lambda表达式。其中lambda表达式获取到了上层def作用域的变量名x的值。
a是action函数的返回值,a(22),即是调用了action返回的lambda表达式。
这里也可以把def直接写成lambda形式。如下:
b = lambda x:lambda y:x+y
a = b(2)
print a(22)#print (b(2))(22)
>>> 24














 63万+
63万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









