









转载请注明出处:勿在浮沙筑高台http://blog.csdn.net/luoshixian099/article/details/51821460
无约束优化问题是机器学习中最普遍、最简单的优化问题。
1.梯度下降
梯度下降是最简单的迭代优化算法,每一次迭代需求解一次梯度方向。函数的负梯度方向代表使函数值减小最快的方向。它的思想是沿着函数负梯度方向移动逐步逼近函数极小值点。选择适当的初始值
x(0)
,不断迭代,沿负梯度方法更新
x
值,直到收敛。具体的:
固定学习率
梯度下降伪代码(固定学习率):
1. 取初始值 x(0) ,令k=0,学习率 α ,容忍度 ϵ ;
2. 计算梯度 gk=▽x(k) ,若 |gk|<ϵ ,则停止迭代,返回 x∗=x(k) ;
3. 更新 x(k+1)=x(k)−αgk ,若 |x(k+1)−x(k)|<ϵ 或者 |f(x(k+1))−f(x(k))|<ϵ ,则停止迭代,返回 x∗=x(k+1)
4. k=k+1,转到步骤2
值得一提的是梯度下降算法与下面介绍的几种算法都不能保证函数能降低到全局最小值附近,有可能是局部最小值附近。如果目标函数 f(x) 是凸函数,局部最小值即为全局最小值。
下图是二维函数
f(x)=0.5(x21−x22)+0.5(x1−1)2
在固定学习率的情况下,两种不同的学习率分别迭代20次的结果,起始点
(x1,x2)=(0,0)
,最小值点
(x1,x2)=(1,1)
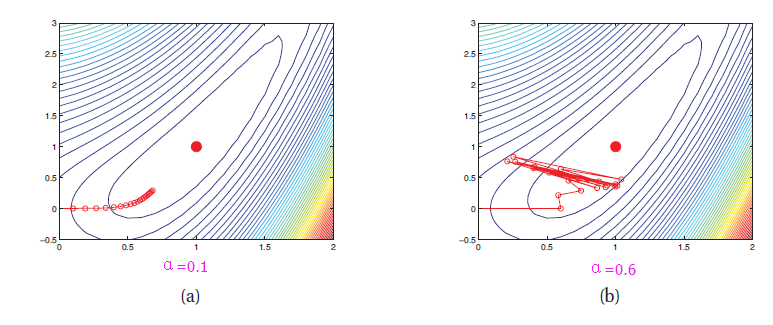
上图中学习率
α=0.1
时,随着迭代次数的增加,每次移动的步长越来越小,甚至很难逼近最优值,表明学习率
α
太小;当
α=0.6
时,移动的轨迹在某值附近开始震荡,表明学习率
α
太大;由此可见,固定学习率的算法太大或者太小都不好。下面介绍一种可变学习率的算法,采用线性搜索的方案,每次迭代前寻找最优的
α
值,再进行迭代;
线性搜索
固定学习率中每一迭代更新
x(k+1)=x(k)−αgk
。在线性搜索中我们设函数
h(α)=f(xk−αgk)
,即看成是关于
α
的函数,解
αk=minαh(α)=minα f(x(k)−αgk)
,然后迭代更新
x(k+1)=x(k)−αkgk
;这样可以保证x向函数下降方法移动,并收敛到局部最优值。
梯度下降伪代码(线性搜索):
1. 取初始值 x(0) ,令k=0,学习率 α ,容忍度 ϵ ;
2. 计算梯度 gk=▽x(k) ,若 |gk|<ϵ ,则停止迭代,返回 x∗=x(k) ;
3. 计算 αk=minαh(α)=minα f(xk−αgk)
4.更新 x(k+1)=x(k)−αkgk ,若 |x(k+1)−x(k)|<ϵ 或者 |f(x(k+1))−f(x(k))|<ϵ ,则停止迭代,返回 x∗=x(k+1)
5. k=k+1,转到步骤2
采用线性搜索:
f(x)=0.5(x21−x22)+0.5(x1−1)2
,如下图(a)发现函数值下降很快并接近最优值。

注意到线性搜索的迭代相邻轨迹垂直,如图(b)。这是由于取
αk=minαh(α)
,必然有
h′(αk)=0
;而由链式求导得
h′(α)=dTg
,其中
g=f(x)
表示迭代前
x
位置梯度,
一种减弱上述相互垂直轨迹的方法是添加一个动量项(momentum term):
2.牛顿法
假设f(x)具有二阶连续偏导数,在
x(k)
处附近二阶泰勒展开:
其中 gk 表示f(x)在 x(k) 的梯度, Hk 表示f(x)的Hessian矩阵在点 x(k) 处的值。
牛顿法利用极小点的必要条件 ▽f(x)=0 ;从 x(k) 处迭代到 x(k+1) 处时,假设 ▽f(x(k+1))=0 ;则
▽f(x)=gk+Hk(x−x(k))=0
▽f(x(k+1))=gk+Hk(x(k+1)−x(k))=0
化简得:
伪代码:

实际上可以把f(x)在 x(k) 处的二阶泰勒展开式看成是关于x的二次函数(一维的情形),然后取极值点的过程如图(a)(严格的凸函数);图(b)中f(x)是一个非凸函数,采用牛顿法则失效。
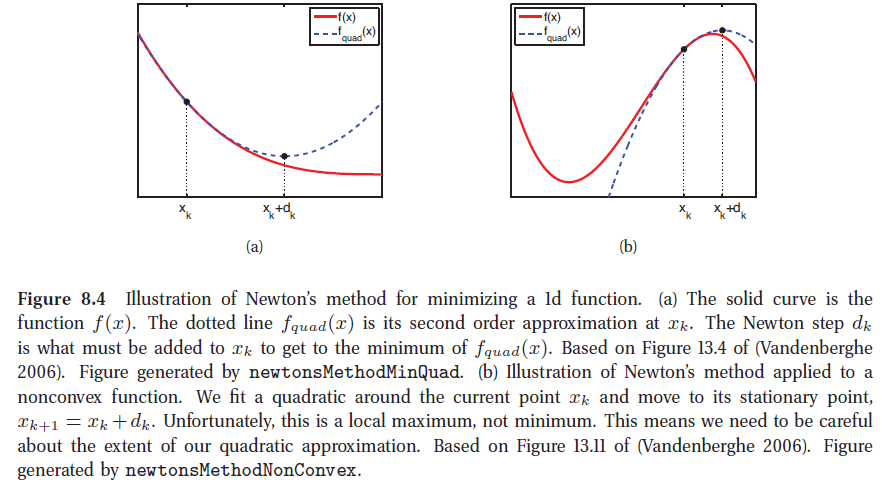
牛顿法一个问题是 Hk 可能不是正定矩阵(f(x)非凸),计算出的 pk 牛顿方向错误,图(b)的情况。
针对图(b)的非凸函数,可以采用梯度下降与牛顿法结合使用,即当牛顿方向与负梯度方向夹角小于90度时,采用牛顿方向,否则采用负梯度方向。
3.拟牛顿法
牛顿法中需要计算Hessian矩阵的逆,往往计算量非常大,所以提出拟牛顿方法采用矩阵近似 H−1(x) 。拟牛顿法的原理请参考李航的《统计学习方法》。一种常用的拟牛顿法BFGS算法:
采用一个不断迭代的矩阵
Bk
来近似
Hk
,初始化
B0
为正定矩阵,通常选择
B0=I
,每一步迭代循环的最后更新:
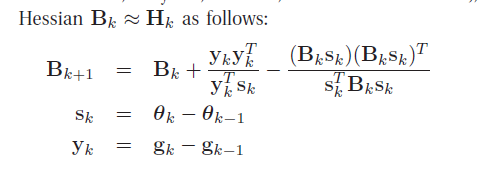
BFGS伪代码:
1. 取初始值 x(0) ,令k=0,学习率 α ,容忍度 ϵ,B0=I ;
2. 计算梯度 gk=▽x(k) ,若 |gk|<ϵ ,则停止迭代,返回 x∗=x(k) ;
3. 由 Bkpk=−gk ,计算出拟牛顿方向 pk ;
3. 计算 αk=minαh(α)=minα f(xk+αpk) ;
4. 更新 x(k+1)=x(k)−αkpk 与 Bk+1 ,若 |x(k+1)−x(k)|<ϵ 或者 |f(x(k+1))−f(x(k))|<ϵ ,则停止迭代,返回 x∗=x(k+1) ;
5. k=k+1,转到步骤2
Reference:
统计学习方法.李航
Machine Learning A Probabilistic Perspective.Kevin P. Murphy

















 2222
2222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









