






概述
当前人工智能领域快速发展,大语言模型(Large Language Models,LLM)无疑是最闪亮的星,其核心的特点是能够理解和生成自然语言文本,具备强大的语言处理能力和广泛的应用潜力。LLM比较关键的是模型训练和模型推理,模型训练阶段十分复杂,而且投入成本极高,因此这里只关注模型推理阶段即将训练好的模型应用于实际任务。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
llama.cpp
LLaMA是Meta公司的预训练开源语言模型,其最新的Llama-3在多个基准测试中实现了全面领先,性能优于业界同类最先进的模型。
llama.cpp 是一个开源的 C++ 库, 它用原始 C++ 重写了 LLaMA 的推理代码,是一种推理框架,用于加载和运行 LLaMA 语言模型。

llama
下载llama.cpp源码,如下:
git clone https://github.com/ggerganov/llama.cpp
然后编译,如下:
cd llama.cpp cmake -B build cmake --build build --config Release -j8
编译完成的可执行应用位于llama.cpp/build/bin/下面。
如果需要编译Dedug版本:
cd llama.cpp cmake -B build -DCMAKE_BUILD_TYPE=Debug cmake --build build -j8
模型获取
模型选择阿里开源的qwen2系列模型,这里选择通义千问2-7B-Instruct-GGUF,其提供了GGUF格式的fp16模型和量化模型,包括q5_0、q5_k_m、q6_k和q8_0。
这里下载体积比较小的hqwen2-7b-instruct-q2_k.gguf,只有3GB左右。
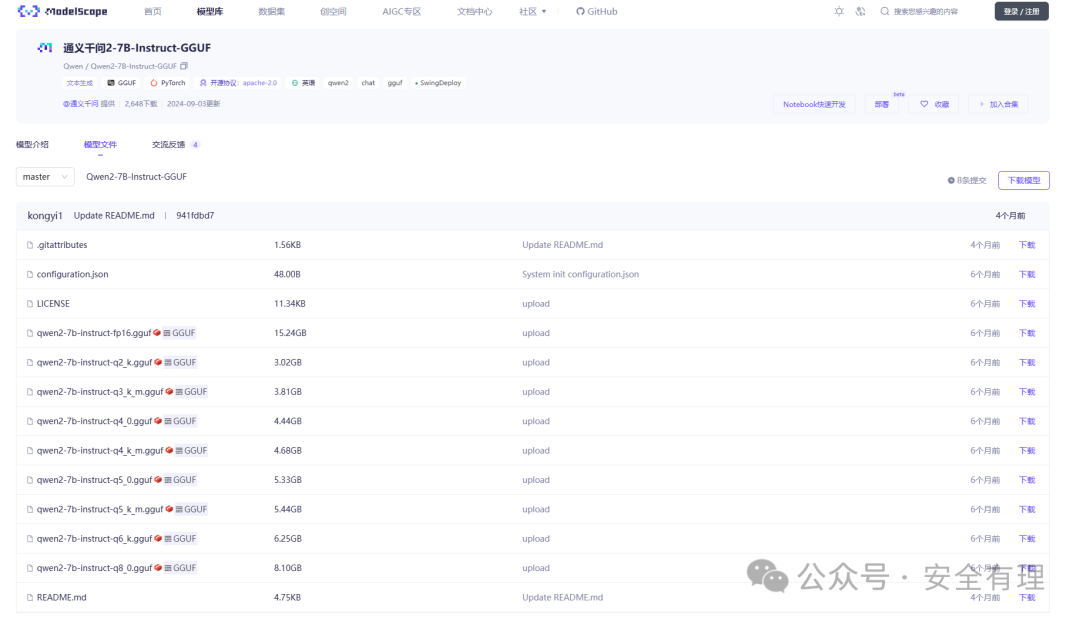
通义千问2模型
模型推理
llama.cpp提供了两种方式进行模型推理:llama-cli和llama-server。
unsetunsetllama-cliunsetunset
llama-cli是一个简单的命令行工具。使用示例如下:
# text generation ./llama.cpp/build/bin/llama-cli -m your_model.gguf -p "I believe the meaning of life is" -n 128 # chat (conversation) ./llama.cpp/build/bin/llama-cli -m your_model.gguf -p "You are a helpful assistant" -cnv
简单的文本方式
$ ./llama.cpp/build/bin/llama-cli -m qwen2-7b-instruct-q2_k.gguf -p "推荐成都的景点" -n 256 build: 4319 (83ed24a9) with cc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0 for x86_64-linux-gnu main: llama backend init main: load the model and apply lora adapter, if any llama_model_loader: loaded meta data with 26 key-value pairs and 339 tensors from qwen2-7b-instruct-q2_k.gguf (version GGUF V3 (latest)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. ...... system_info: n_threads = 8 (n_threads_batch = 8) / 16 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 | sampler seed: 3601414821 sampler params: repeat_last_n = 64, repeat_penalty = 1.000, frequency_penalty = 0.000, presence_penalty = 0.000 dry_multiplier = 0.000, dry_base = 1.750, dry_allowed_length = 2, dry_penalty_last_n = -1 top_k = 40, top_p = 0.950, min_p = 0.050, xtc_probability = 0.000, xtc_threshold = 0.100, typical_p = 1.000, temp = 0.800 mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000 sampler chain: logits -> logit-bias -> penalties -> dry -> top-k -> typical -> top-p -> min-p -> xtc -> temp-ext -> dist generate: n_ctx = 4096, n_batch = 2048, n_predict = 256, n_keep = 0 推荐成都的景点和美食,为旅游提供指南。 成都是一个充满文化和美食的城市,以下是一些推荐的景点和美食: 景点: 成都博物馆:了解这座城市的历史和文化。 锦里古镇:体验传统四川文化,欣赏手工艺品,品尝特色小吃。 武侯祠:了解三国历史,祭祀诸葛亮。 熊猫基地:观赏可爱的熊猫宝宝和成年熊猫。 美食: 麻婆豆腐:麻辣味浓郁,口感香滑。 夫妻肺片:用牛肺和猪肺切成薄片,用特制酱料调味。 担担面:辣味适中,口感鲜美。 串串香:各种肉类和蔬菜串在竹签上,烤制后蘸上酱料食用。 鸡汁肥肠:用猪肠熬制的汤底,加入鸡肉和蔬菜,味道鲜美。 成都的美食种类丰富,每种美食都有其独特的地方特色,可以尝试不同的美食以了解这座城市的文化和历史。此外,成都还拥有许多其他景点,如锦江公园、人民公园、太古里等,可以结合个人兴趣和时间安排进行游览和体验。 希望这份指南能帮助你了解成都,并体验这座城市丰富的文化和美食。祝你旅途愉快! [end of text] llama_perf_sampler_print: sampling time = 23.19 ms / 254 runs ( 0.09 ms per token, 10952.52 tokens per second) llama_perf_context_print: load time = 547.66 ms llama_perf_context_print: prompt eval time = 239.98 ms / 4 tokens ( 60.00 ms per token, 16.67 tokens per second) llama_perf_context_print: eval time = 34742.06 ms / 249 runs ( 139.53 ms per token, 7.17 tokens per second) llama_perf_context_print: total time = 35068.02 ms / 253 tokens
对话交互方式
$ ./llama.cpp/build/bin/llama-cli -m qwen2-7b-instruct-q2_k.gguf -p "你是一个数学家" -cnv build: 4319 (83ed24a9) with cc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0 for x86_64-linux-gnu main: llama backend init main: load the model and apply lora adapter, if any ...... common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable) main: llama threadpool init, n_threads = 8 main: chat template example: <|im_start|>system You are a helpful assistant<|im_end|> <|im_start|>user Hello<|im_end|> <|im_start|>assistant Hi there<|im_end|> <|im_start|>user How are you?<|im_end|> <|im_start|>assistant system_info: n_threads = 8 (n_threads_batch = 8) / 16 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 | main: interactive mode on. sampler seed: 1845629703 sampler params: repeat_last_n = 64, repeat_penalty = 1.000, frequency_penalty = 0.000, presence_penalty = 0.000 dry_multiplier = 0.000, dry_base = 1.750, dry_allowed_length = 2, dry_penalty_last_n = -1 top_k = 40, top_p = 0.950, min_p = 0.050, xtc_probability = 0.000, xtc_threshold = 0.100, typical_p = 1.000, temp = 0.800 mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000 sampler chain: logits -> logit-bias -> penalties -> dry -> top-k -> typical -> top-p -> min-p -> xtc -> temp-ext -> dist generate: n_ctx = 4096, n_batch = 2048, n_predict = -1, n_keep = 0 == Running in interactive mode. == - Press Ctrl+C to interject at any time. - Press Return to return control to the AI. - To return control without starting a new line, end your input with '/'. - If you want to submit another line, end your input with '\'. system 你是一个数学家 > 20以内的素数 在数学中,素数是指只有两个正因数(即1和它本身)的自然数。以下是小于20的素数: \[2, 3, 5, 7, 11, 13, 17, 19\] 这些数字只能被1和它们自身整除。注意,素数的定义通常不包括数字1,因为它只有一个正因数。 >
unsetunsetllama-serverunsetunset
llama-server提供一个轻量级的HTTP服务,与OpenAI API兼容。
$ ./llama.cpp/build/bin/llama-server -m qwen2-7b-instruct-q2_k.gguf --host 172.30.203.237 --port 8080 build: 4319 (83ed24a9) with cc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0 for x86_64-linux-gnu system info: n_threads = 8, n_threads_batch = 8, total_threads = 16 system_info: n_threads = 8 (n_threads_batch = 8) / 16 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 | main: HTTP server is listening, hostname: 172.30.203.237, port: 8080, http threads: 15 main: loading model srv load_model: loading model 'qwen2-7b-instruct-q2_k.gguf' ...... common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable) srv init: initializing slots, n_slots = 1 slot init: id 0 | task -1 | new slot n_ctx_slot = 4096 main: model loaded main: chat template, built_in: 1, chat_example: '<|im_start|>system You are a helpful assistant<|im_end|> <|im_start|>user Hello<|im_end|> <|im_start|>assistant Hi there<|im_end|> <|im_start|>user How are you?<|im_end|> <|im_start|>assistant ' main: server is listening on http://172.30.203.237:8080 - starting the main loop srv update_slots: all slots are idle request: GET / 172.30.192.1 200 request: GET /favicon.ico 172.30.192.1 404 slot launch_slot_: id 0 | task 0 | processing task slot update_slots: id 0 | task 0 | new prompt, n_ctx_slot = 4096, n_keep = 0, n_prompt_tokens = 21 slot update_slots: id 0 | task 0 | kv cache rm [0, end) slot update_slots: id 0 | task 0 | prompt processing progress, n_past = 21, n_tokens = 21, progress = 1.000000 slot update_slots: id 0 | task 0 | prompt done, n_past = 21, n_tokens = 21 slot release: id 0 | task 0 | stop processing: n_past = 37, truncated = 0 slot print_timing: id 0 | task 0 | prompt eval time = 1010.85 ms / 21 tokens ( 48.14 ms per token, 20.77 tokens per second) eval time = 2316.87 ms / 17 tokens ( 136.29 ms per token, 7.34 tokens per second) total time = 3327.71 ms / 38 tokens srv update_slots: all slots are idle request: POST /v1/chat/completions 172.30.192.1 200
然后可以在浏览器中输入:
http://172.30.203.237:8080
然后即可进行提问和对话:
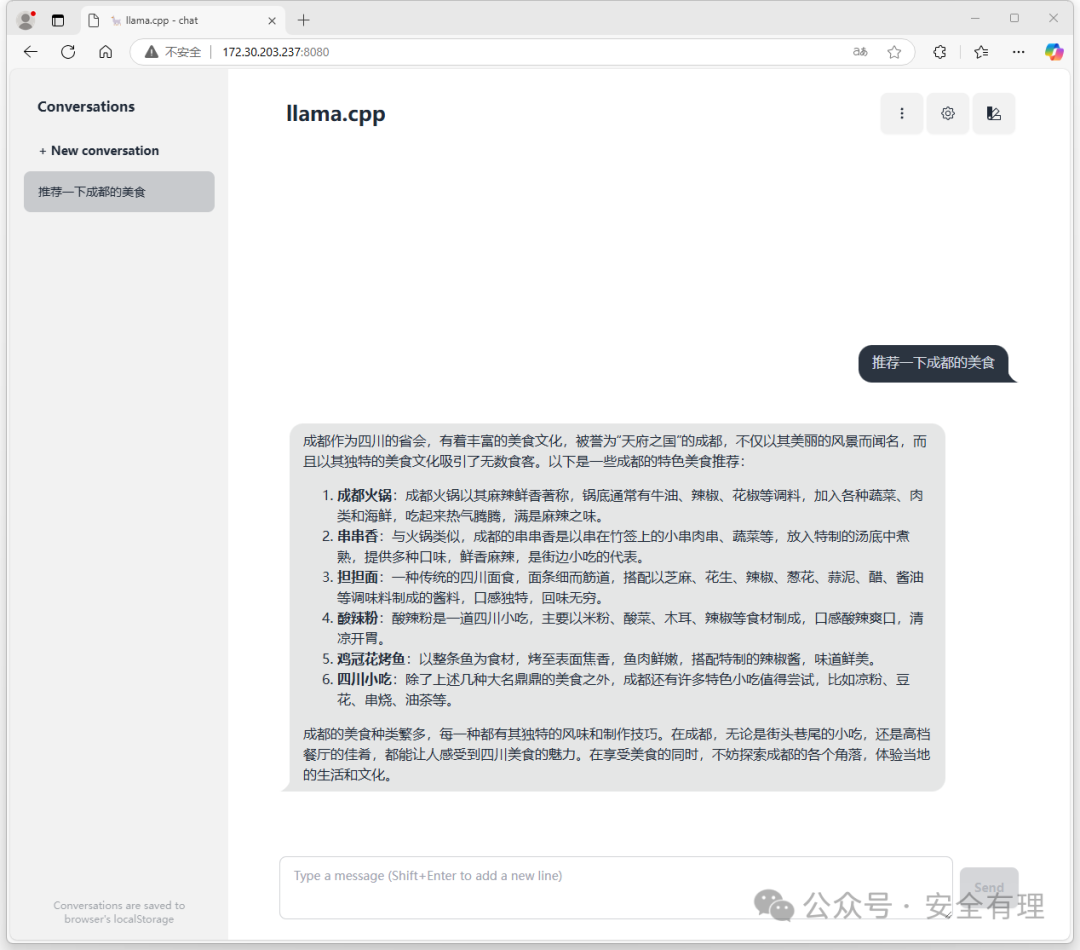
llama.cpp-chat.png
Ollama
前面使用llama.cpp部署运行大模型还是比较繁琐,Ollama是一个大模型运行框架,可以帮助用户快速在本地运行大模型,其利用了llama.cpp提供的底层能力。
unsetunset运行Ollamaunsetunset
以Windows平台为例,下载Ollama,下载完成点击OllamaSetup.exe安装即可。
Ollama下载
Ollama支持当前主流的开源大模型,如llama3,qwen和mistral等,这里还是选择阿里开源的qwen2系列模型。
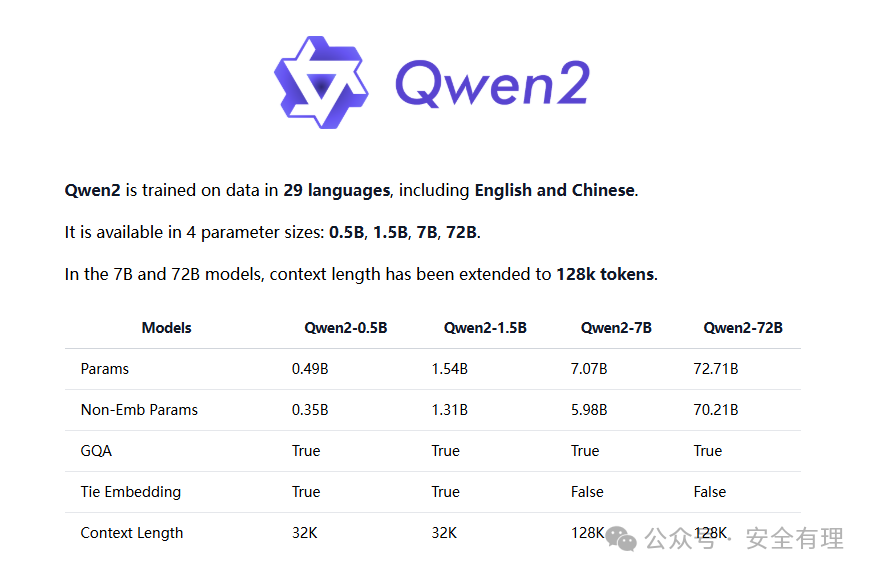
ollama-qwen2
打开Powershell终端,输入命令:
PS E:\OllamaModels> ollama run qwen2:7b pulling manifest pulling 43f7a214e532... 100% ▕███████████████████████████████████████████████████████████▏ 4.4 GB pulling 77c91b422cc9... 100% ▕███████████████████████████████████████████████████████████▏ 1.4 KB pulling c156170b718e... 100% ▕███████████████████████████████████████████████████████████▏ 11 KB pulling f02dd72bb242... 100% ▕███████████████████████████████████████████████████████████▏ 59 B pulling 75357d685f23... 100% ▕███████████████████████████████████████████████████████████▏ 28 B pulling 648f809ced2b... 100% ▕███████████████████████████████████████████████████████████▏ 485 B verifying sha256 digest writing manifest success
下载成功后就可以开启对话,输入你的prompt,如**“推荐成都的景点”**:
>>> 推荐成都的景点
成都作为四川省省会,不仅有悠久的历史和丰富的文化遗产,还有独特的美食文化。以下是一些值得一游的著名景点:
1. **武侯祠** :位于成都市区,是中国现存最早的三国遗迹博物馆之一,主要纪念三国时期的蜀汉丞相诸葛亮。
2. **锦里古街**:这是一个充满四川特色的商业步行街,汇集了众多传统的手工艺品、小吃和茶馆。在这里可以体验到地道的成都生活
氛围。
3. **杜甫草堂**:位于成都市区,是唐代伟大诗人杜甫流寓蜀地时居住的地方。这里不仅有丰富的历史文化价值,还有清新的园林景观
。
4. **都江堰水利工程**:距离成都市区较远,但值得一游。这是中国现存最早的大型水利工程之一,对成都平原的农业发展起到了至关
重要的作用。
5. **峨眉山**:是中国四大佛教名山之一,位于四川省中西部,以雄、秀、奇、险的自然风光和深厚的佛教文化而闻名。登顶可以欣赏
到云海、佛光等壮观景象。
6. **乐山大佛**:与峨眉山相邻,是世界最大的石刻佛像,也是中国四大名胜之一。它坐落在凌云山上,俯瞰着岷江、青衣江和大渡河
的汇流处。
7. **大熊猫繁育研究基地**:位于成都郊区,是中国唯一的以保护大熊猫为主的科学研究机构,提供了近距离观察这些可爱动物的机会
。
8. **宽窄巷子**:这是一组历史街区,融合了清代和民国时期的传统建筑风格。在这里可以漫步于古色古香的街道上,体验传统的成都
生活。
9. **熊猫基地**(与2中重复,这里是纠正后的表述):
除了上述景点外,成都有着丰富的美食文化,“四川麻辣”是其最著名的特色之一,如火锅、串串香等。如果你对文化和历史有兴趣,
那么这些地方将提供丰富多样的体验;如果你热爱自然和动物保护,那么去到峨眉山或大熊猫基地一定会让你大开眼界。
在计划行程时,请注意根据个人兴趣和时间安排来选择合适的景点,并做好旅行前的准备,如了解天气情况、携带必需品(如舒适的鞋
子、防晒用品等)。
>>> Send a message (/? forhelp)
可以看出使用Ollama部署运行大模型非常便捷,对于新手来说体验十分友好。
unsetunsetOpen WebUIunsetunset
不过,上面Ollama部署的大模型只能在命令行中使用,不像ChatGPT那样直观,交互体验较差。Open WebUI是一个可扩展、功能丰富、用户友好的自托管WebUI,旨在完全离线操作。它支持各种LLM运行程序,包括Ollama和OpenAI兼容的API。
首先需要安装Docker,链接如下:
https://docs.docker.com/desktop/setup/install/windows-install/
下载完成进行安装,安装完成会自动重启电脑,然后打开桌面上的Docker,如下:
docker
由于我的Ollama和Open WebUI位于同一台电脑上,根据官方的指导,输入命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
安装完成,如下图所示:
PS C:\Users\DELL> docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main Unable to find image 'ghcr.io/open-webui/open-webui:main' locally main: Pulling from open-webui/open-webui bc0965b23a04: Downloading 16.73MB 3a75594a45d1: Download complete 51e2bd9c4b08: Download complete bc0965b23a04: Pull complete 3a75594a45d1: Pull complete 51e2bd9c4b08: Pull complete 5f20101c4b63: Pull complete 1a708694ac94: Pull complete 4f4fb700ef54: Pull complete e082a382846c: Pull complete 42f342095124: Pull complete f515806d7e30: Pull complete c96909b985fb: Pull complete b3e4176e46ef: Pull complete 0812c78076c0: Pull complete 7ec0f8d7c357: Pull complete 51f1db63be85: Pull complete e4fc70f66913: Pull complete Digest: sha256:ee76db7339ab326fb3822ca22fd5de9b81b165c270d465fbca8fca3b80471db0 Status: Downloaded newer image for ghcr.io/open-webui/open-webui:main 634de3c799ae86fec801dd40114d89cf39c48b22eef41497389f6f423af69d2d
在docker界面中,可以看到Open WebUI已经在运行:
Open WebUI-docker
打开浏览器,输入web界面地址:
https://localhost:3000
第一次会进行账号注册,注册成功后会跳转到类似ChatGPT界面了,点击左上角选择一个已安装的模型,然后就可以提问了:
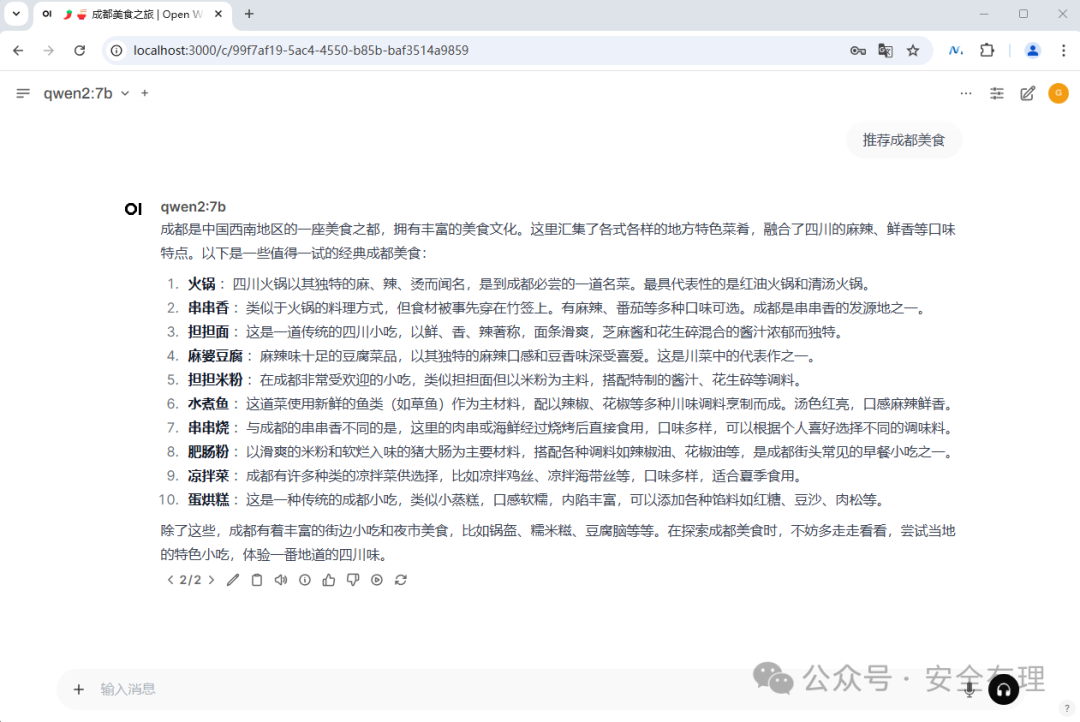
Open WebUI
至此,作为一名小白,实际体验了一把大语言模型的使用,但LLM还有许多深奥的技术,深入掌握任重道远。
All in AI
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

















 5198
5198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









