







引:stereo伤不起,样本要自己造,怎么才能做出有效的逼真的让模型很牛的样本呢?
对于分开的数据集分阶段的训练要比光训练一个或者混起来一起训练效果要好
通过特别复杂的光线使得数据集看起来更加的现实。这样效果并不是很好,除非测试数据也是超现实光照~
在训练的时候模拟该相机的缺点,将会提升网络测试该相机中图像的性能。

以上就是所有的数据,可见虚拟数据多,真实数据少

以上就是这些数据的样子,一般用的比较多的是flythings3d,monkee,kitti什么的

这种虚拟构造数据啊~总共分为两波,一波叫做Randomized modeling of data,这个数据呢,前景跟背景是独立分开的,然后前景往背景上面去贴,当然,前景要经过各种变化啊~什么尺度,旋转各种任意的变化。目前比较成熟的有flythingchar以及flythings3d,一个的前景是2维的一个是3维的。上图就是飞行的椅子,可以发现前景与背景都要进行随机变化,这样子生成的样本才会更加丰富嘛~
还有一波叫做mannel modeling
这个就厉害了,主要是从一个三维的空间里面去提取的,需要专业的3维绘图人员方可操作完成,monkee以及driving都是这么做出来的。driving虽然是虚拟数据,可是它的性能可是要比肩kitti的哦~
数据增益:数据增益主要分为颜色增益以及几何增益。
该论文用的算法就是dispnet-c

试验

看下这个表,对于Kitti来说,driving的数据集表现最好,因为像,sintel的还凑合,不过量太少了,所以效果不咋地,令人惊讶的是flythingchars的效果竟然比monkee和flythings3d的要好。所以究竟什么样的样本最好呢?
2.1 物体的形状与位移


非范性形变对于Sintel和Kitti效果比较好,但是对于FlythingChair效果不太好。然后空洞对KITTI和Sintel影响较小。
由表中可以发现,对于KITTI数据集,旋转貌似对它的影响不大,而scale对它比较有效果。在物体中添加空洞没啥用,毕竟测试集中孔洞很少。物体与前景的非刚性形变能够产生一个较好的结果哟。
可是对于FlythingChairs来说,旋转比较有效果。因为KITTI当中主要的变化是相机的远近导致的前景尺度大小上的变化,因此,在KITTI当中,scale比较有效。非刚性的2D形变比如3D前景的旋转可以近似于光流的模式。因此,这种旋转对于Sintel很有效果。结论就是,什么样的训练集最好呢,是与目标域有关的训练集是最好的。不好的就是,没有一个最厉害的训练集。也就是说拍照样本,前景只需要scale就好了,横竖就好了,舍去rotate。
2.2纹理

试验下来,Flickr对于Sintel的效果最好,所以结论就是训练样本的纹理需要有多样性。所以monkee样本,虽然具有很强的目标和动作样本,但是缺少丰富的纹理色彩所以效果也不咋地。

2.3 视差分布

视差的统计,flythings3d中的小视差好少啊~Sintel与Flythingchars的样本视差分布最为接近。

结果表明,与测试的视差范围最匹配的训练样本效果最好,差别越大,性能越差~不是越大越好哦~所以自己制作的样本的视差范围应当于测试样本的视差范围匹配。

对于小视差,flything3d效果真的差
总结就是,训练集的视差范围需要与测试集的视差范围保持一致。
2.4光照
现实生活中的光照与物体的关系产生了反射,高亮以及阴影。这对于视觉算法来说是非常具有挑战性的。尤其对于高亮以及阴影,就好像个物体存在,然而实际上却是不存在的。不过,deeplearning可以解决的哦~

这个是三种不同的光源设置,动态,静态,无纹理,无纹理其实是有点困难的,因为只能提取物体的形状信息。无纹理只简单的具有单一扁平的颜色信息,根本就没有任何光照的影响。
静态光照物体是有来自单一方向的环境光照照射,每个物体的阴影纹理都是固定的,而当物体以及光源移动的时候,这些阴影也不会改变。
dynamic是最难的,非常的真实,网络必须学习在不同光照下的不同物体,还得学习光照位置的改变。总之有点太过于复杂。

看得出来静态光源的网络取得最好的效果,动态的太多复杂了。因为测试集Sintel基本上都是单一的光源,没有那么复杂。dynamic的太复杂了,网络还得多学习不同光源下的物体来充分区分光源的影响。这样就使得网络要学习的内容过于复杂,然而样本的数量又比较少,所以就学不好。
2.5 Data augmentation
数据增益主要分为色彩的增益以及形态的增益。
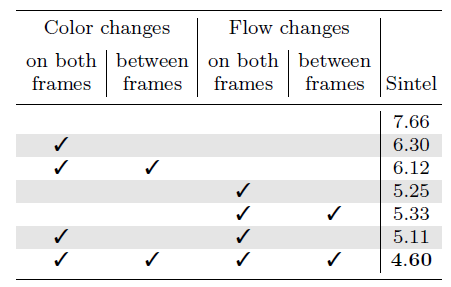
特效全加,效果最好。就是说原本的数据如果颜色变化够多,再加颜色变化特效影响不大,加形变特效比较好。所以就是说良好的数据需要具备色彩多样性以及形状多样性。
2.6 训练样本的数量
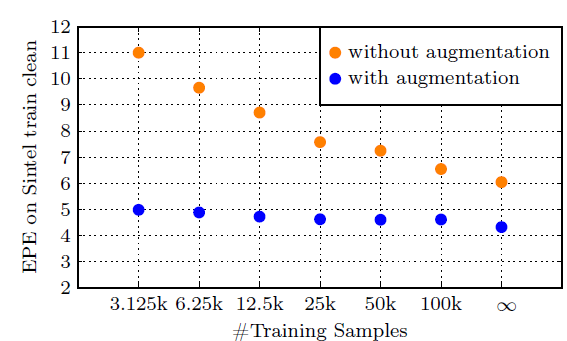
也就是说只要数据增益的效果到位,其实绝对数量并不是那么重要~
所以要想数据好,我们即需要绝对的样本数量也需要数据增益。
3 Learning schedule with multiple datasets
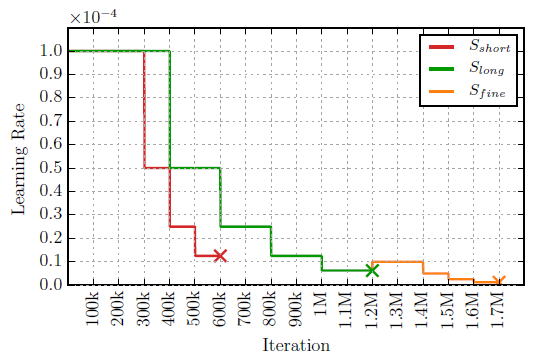
所以要采用Slong与Sfine啊~学习率都是这种multi-step的。下次也试一下子
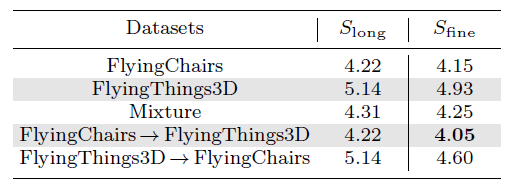
看起来分开训练比混在一起要好很多啊~可能原因就是先通过简单的flythingchar来学习大概的视差没必要太早被3D视角所干扰。
4. 模拟真实图像样本的缺点
4.1 Lens distortion and blur

这个其实间接的说明要数据增益,因为真实场景比较暗,所以暗一点就比较好
















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









