






AAAI 2022
Background
目前的多模态匹配问题:大多为稀疏匹配,需要明确的变换规则;具体某一种模态的匹配;传统方法效率和鲁棒性存在问题
多模态图像匹配通常被认为是专用任务而不是通用
目前的光流算法有弱监督和强监督,目前的数据集全是合成的,弱监督时通常有亮度一致性假设,平滑约束,cencus变换(将图像像素灰度值编码为二进制),而在这方区域不满足亮度一致性假设
Motivation
Idea
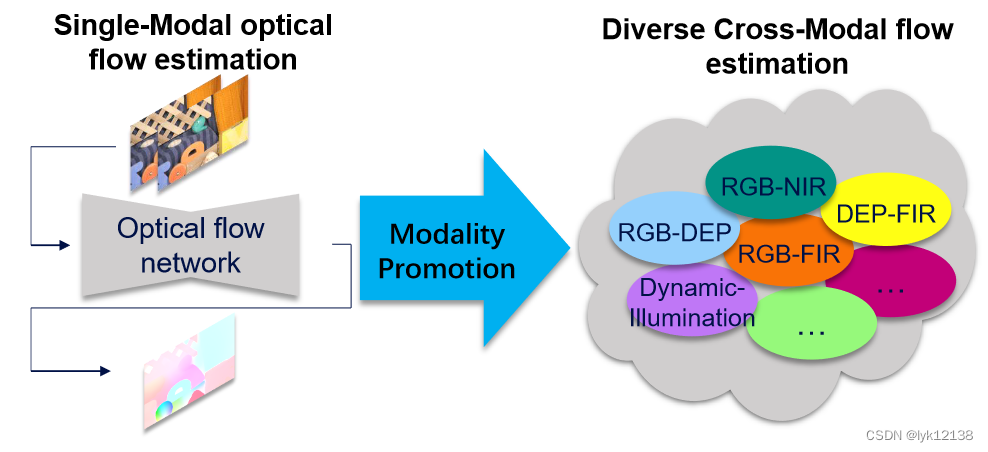
利用这些现在的高精度光流算法到多模态图像匹配中去
将RGB图像转为各种模态的帧
利用现成的光流算法构建自监督框架
Method
利用现有的光流算法,使用Modality promotion framework,然后使用cross mode adapter
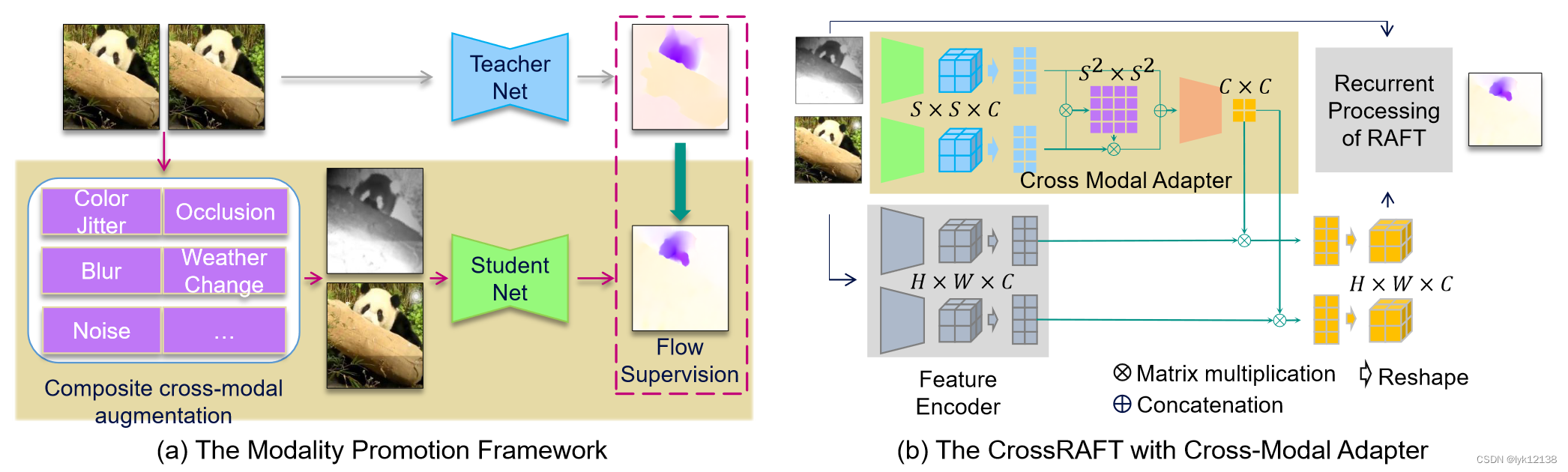
Modality Promotion Framework
先使用老师去生成伪标签,然后学生去训练多模态的光流,其中输入帧使用模态增强处理输出任意的模态
计算老师和学生的误差值:
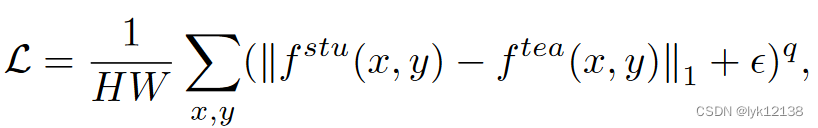
当学生网络是RAFT或者crossRAFT时,使用一个序列损失,其中r=0.8
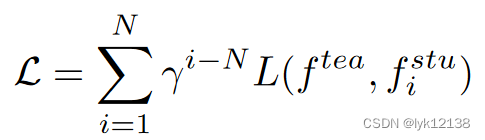
Composite Cross-modal Augmentation
当训练数据集有更多模态的场景时,在未见过的新模态中估计光流更准确
Cross Modal Adapter
不同模态的图像应该使用不同的特征提取器。首相对两幅图提特征,然后scale到固定的尺度,然后reshape特征维度,计算attention矩阵M,使用计算得到的Ms粗对齐特征,对齐的特征输入到小的自适应生成网络G
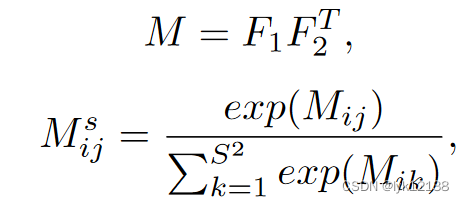
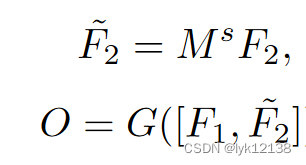
其中O是希望得到的自适应矩阵,利用得到的O增强特征的提取
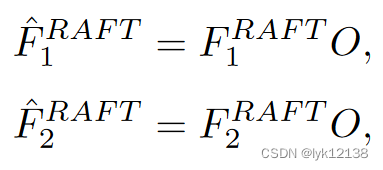
也就是该模块生成1×1的卷积对原特征图进行滤波
Experiment
Teacher--RAFT
student的权重初始化是老师的预训练模型
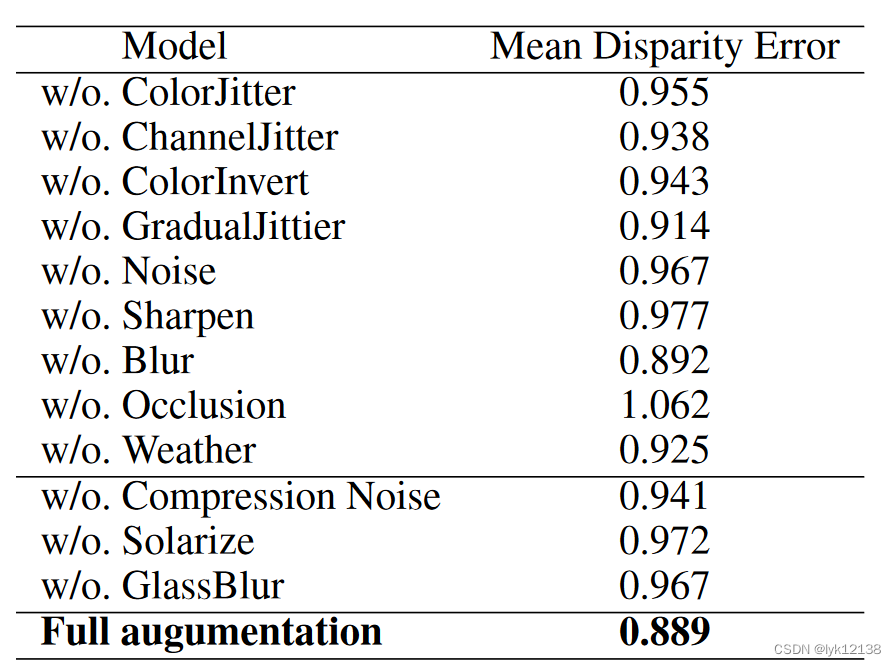
数据增强是使用Albunebtations















 1571
1571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









