






一、结论写在前面
论文标题:A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B
论文链接:https://arxiv.org/pdf/2409.11055
在人工智能快速发展的今天,大语言模型(LLMs)的应用越来越广泛。然而,这些模型的庞大规模也带来了存储和计算资源的巨大消耗。如何在保持模型性能的同时降低资源需求?最新研究为我们揭示了答案。
一项涵盖从7B到405B参数的LLMs量化研究,对比了GPTQ、AWQ、SmoothQuant和FP8等多种量化方法。研究团队通过13个基准测试,评估了六大类任务,包括常识问答、知识理解、指令遵循等。这种全面的评估方法,为我们提供了前所未有的洞察。
研究发现,量化后的大型模型在大多数任务中表现优异,甚至超越了较小的全精度模型。例如,4位量化的Llama-2-13B模型在多项任务中胜过了原始的Llama-2-7B。这一发现颠覆了我们对模型大小和性能关系的传统认知,为资源受限环境下的AI应用开辟了新的可能。
然而,研究也揭示了量化的复杂性。不同的量化方法、模型大小和精度级别会导致性能差异。特别是在405B级别的超大模型中,仅量化权重的方法表现更佳。这些发现不仅为研究人员提供了宝贵的指导,也为工业界在选择和应用量化模型时提供了重要参考。
二、论文的简单介绍
2.1 论文的背景
LLMs的量化方法大致分为量化感知训练(Quantization Aware Training, QAT)和训练后量化(Post-Training Quantization, PTQ)。尽管PTQ可能会降低准确性,但由于QAT需要大规模的再训练过程,对于参数庞大的LLMs来说负担沉重,因此PTQ在LLMs中被广泛采用。然而,现有关于量化算法的研究主要使用有限的指标(如困惑度)进行评估。许多模型未被考虑,尽管指令微调模型在实践中被广泛使用,但评估主要在预训练模型上进行。
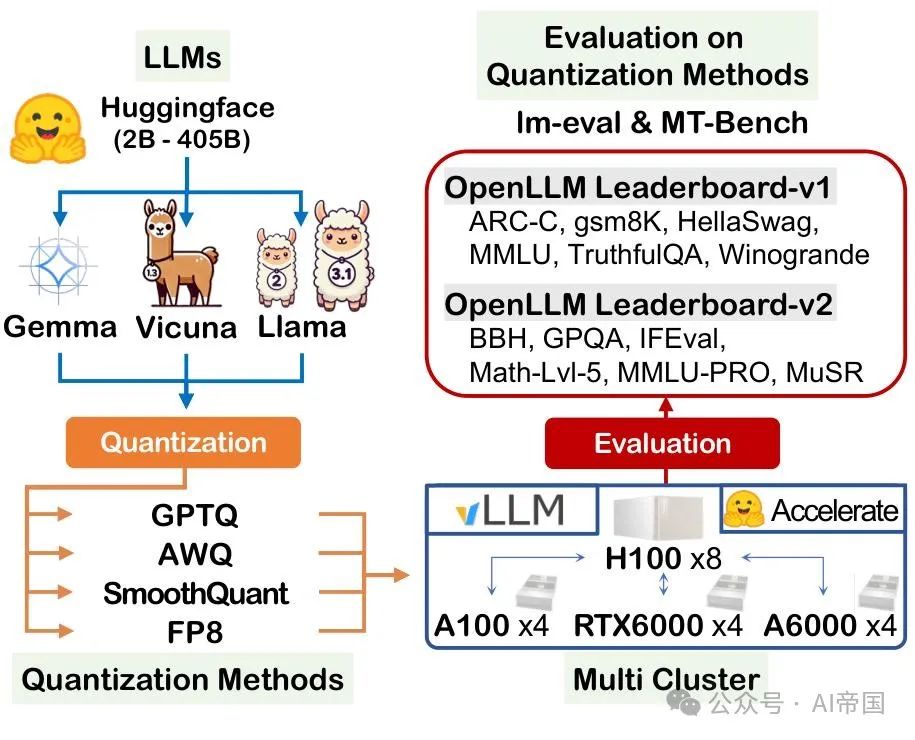
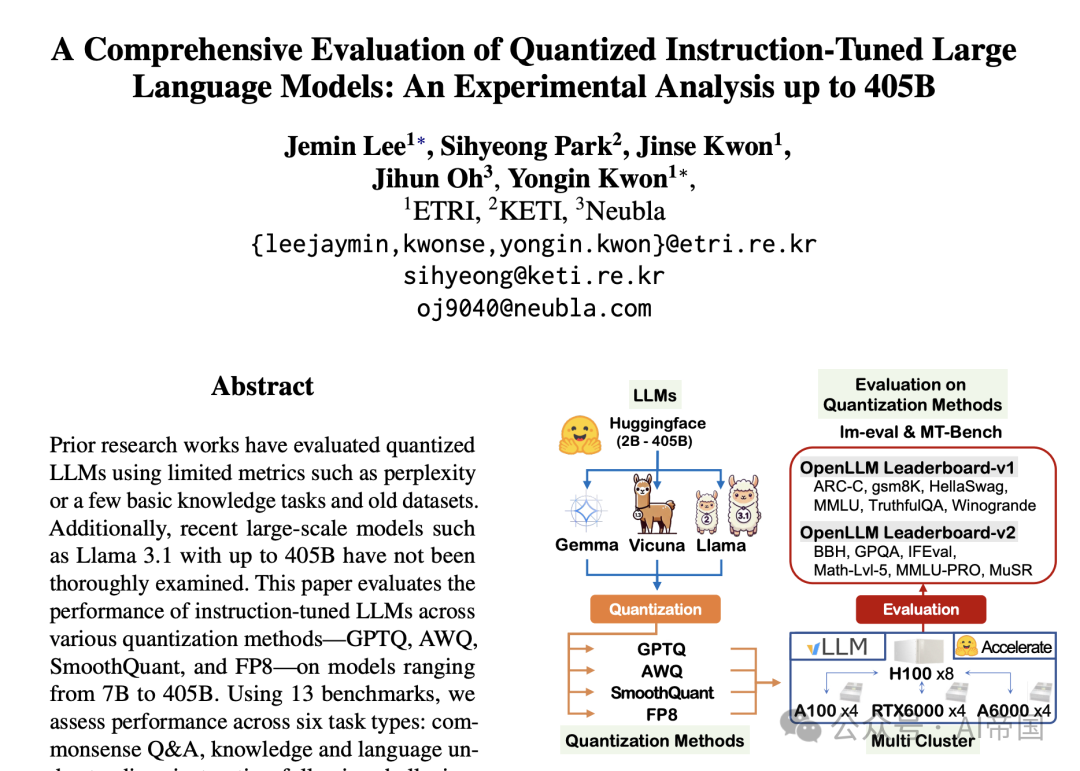
图1:量化大型语言模型(LLMs)的整体评估流程。该流程评估了指令微调的LLMs,包括Vicuna、Gemma和Llama系列,规模从2B到405B不等。模型使用GPTQ、AWQ、SmoothQuant和FP8方法进行量化,并在13个基准测试中进行评估,这些基准测试旨在测试复杂知识、语言理解、真实性、涌现能力和自由文本生成的质量。多节点集群分布式推理环境由四台服务器(H100-80Gx8、A100-80Gx4、RTX 6000-48Gx4和A6000-48Gx4)组成,利用huggingface加速库和vLLM进行快速、可靠的评估。
为了正确利用这些量化方法,理解不同量化技术在各种数据集上所能达到的准确性水平至关重要。换句话说,论文应该能够回答以下问题:1)在特定任务上应使用哪种量化算法以达到可接受的性能?2)应如何设置量化位数?以及3)量化对LLMs的影响如何随模型大小和是否应用指令微调而变化?
最近的研究试图全面评估模型量化对LLM性能的影响。然而,这些先前的研究存在以下局限性:(1)它们主要依赖于2-3年前的数据集,如ARC、HellaSwag、Winogrande和MMLU,以评估涌现能力,但这些任务对于最近的LLMs来说已经变得过于简单,难以进行有意义的分析。此外,在新模型的训练过程中存在数据污染的高风险。(2)最近的一些模型,如Llama 3.1,并未被考虑在内,因此,大小超过180B的LLMs被忽视,导致对Llama-3.1等前沿LLMs以及高达405B的模型缺乏深入了解。
论文全面评估了指令调优的大型语言模型(LLMs)在量化后的性能变化。为了进行这一评估,论文使用了13个基准测试,其中包括五个未在先前研究中涉及的数据集——Math-Lv1-5、MuSR、IFE-val、GPQA和MMLU-PRO——以评估复杂知识、数学和涌现能力,包括思维链(Chain-of-Thought, CoT)、上下文学习(In-Context Learning, ICL)和指令跟随(Instruction Following, IF)。所考虑的量化方法包括GPTQ、AWQ、SmoothQuant和FP8。这些方法应用于从7B到405B的模型,包括Vicuna、Gemma和Llama家族。
2.2 评估流程
为了处理无法在单个服务器上处理的LLM,并确保快速可靠的评估,论文基于多节点集群设置开发了一个结构化的评估管道。图1展示了用于评估量化LLM的实施管道概述。评估的LLM包括Vicuna、Gemma和Llama系列,大小从2B到405B不等。每个模型都使用GPTQ、AWQ、SmoothQuant和FP8方法进行量化。评估使用lm-eval ( v 0.4.4} )和MT-Bench ( v0.2.36})等基准测试工具进行。用于评估的多节点集群使用vLLM(v0.5.4)实现,并由四台服务器组成:1I100-80Gx8、A100-80Gx4、RTX 6000-48Gx4和A6000-48Gx4。此外,Huggingface库被集成到管道中以支持模型托管和基准测试。评估分布在多集群环境中,以确保全面的性能评估。如果无法使用vLLM进行处理,论文改用Huggingface Accelerate库(v0.33.0),虽然速度较慢,但显示出更好的可比性。
2.3 实验设置
2.3.1 量化LLM的数据集
论文在广泛使用的数据集和基准测试上评估了量化LLM,以确保全面的分析。表1列出了13个选定的数据集。首先,ARC、HellaSwag和Wino-grande数据集属于CommonSenseQA类型。这些数据集用于评估人类显而易见的知识,但对AI来说难以区分,以及小学水平的基本知识。对于ARC,论文仅考虑挑战集,专注于更难的问题以确保严格的评估。
接下来,论文利用MMLU、GPQA、MMLU-PRO、BBH和MuSR数据集来评估复杂知识和语言理解能力。MMLU包含跨57个学科的多项选择题,涵盖从STEM领域到人文科学。MMLU-PRO通过将多项选择题的选项从四个扩展到十个来增加难度,并涵盖14个学科。GPQA由专家创建的博士级别问题组成,对普通公众来说回答具有挑战性。BBH包含23个学科,并提出需要人类级别语言理解的问题,涵盖多步骤算术、算法推理和讽刺。MuSR包含三个任务:谋杀谜题、物体放置和团队分配。解决MuSR数据集中的问题需要LLMs运用链式思维(CoT)能力来分析长篇上下文,进行逐步推理并整合结果。
IFEval旨在评估模型是否精确遵循给定的指令,而不考虑内容生成。当提供诸如“写超过400字”的指令时,模型应满足该指令,无论生成什么内容。论文使用Truth-fulQA数据集来评估模型响应的真实性,作为幻觉倾向的衡量标准。论文还利用GSM8K和MATH-Lvl-5来评估数学推理能力。GSM8K包含需要多步骤推理的小学数学问题。MATH-Lvl-5包含七个学科的高中竞赛级别问题,生成的答案必须符合特定格式,使用LaTeX编写公式,使用Asymptote绘制图形。
最后,论文使用MT-Bench评估自由形式对话质量。在此评估中,GPT-4作为单答案评分选项的评判员,对多轮对话的质量进行了评估,涵盖了写作、角色扮演、推理等八个类别。
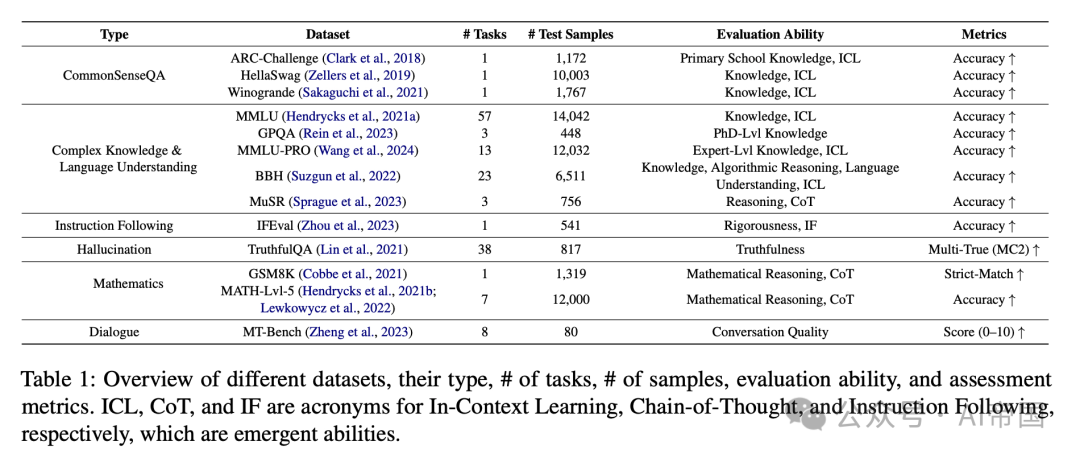
表1:不同数据集的概览,包括其类型、任务数、样本数、评估能力和评估指标。上下文学习(ICL)、链式思维(CoT)和指令遵循(IF)是涌现能力的缩写。
所选的12个基准测试与Huggingface的OpenLLM Leaderboard-v1(从2023年4月至2024年6月)和OpenLLM Leaderboard-v2(于2024年6月26日启动)相一致。为了进一步与这些排行榜进行比较,论文将所有少样本设置的上下文学习(ICL)配置为与排行榜中使用的设置相同,并相应地进行了实验。这种方法使论文能够理解量化对模型上下文学习能力的影响。
2.3.2 量化方法
为了评估量化模型的性能,论文应用了多种量化技术,包括GPTQ、AWQ、SmoothQuant和FP8。所考虑的量化方法属于训练后量化(PTQ)类别,其中GPTQ和AWQ是仅权重量化技术。GPTQ采用逐层量化,并利用逆Hessian信息更新权重,以减轻精度损失。论文使用了AutoGPTQ和lmcompressor工具来对LLMs应用GPTQ,因为这两种工具都支持这种方法。这使论文能够进一步分析由于每种工具中GPTQ算法的实现而导致的精度差异。两种工具中用于GPTQ量化的组大小为128。
激活感知权重量化(Activation-Aware Weight Quantization,AWQ)旨在有效量化大型语言模型(LLMs),同时保留最关键权重的精度。论文使用了AutoAWQ(contributors, 2024a),这是AWQ的扩展实现,旨在使其更易于应用,配置的组大小为128。
SmoothQuant 提出了一种逐通道缩放方法,将高精度量化的复杂性从激活转移到权重。这使得在大型语言模型(LLMs)中可以对权重和激活进行 8 位量化。在 SmoothQuant 的情况下,论文使用 llmcompressor将其应用于 LLMs。对于 FP8 量化,论文也使用了 llmcompressor,并采用 E4M3 格式实现。FP8 E4M3 格式直接受到 NVIDIA 的 Hopper 和 Ada Lovelace 架构支持,并且与 vLM 库兼容。
2.3.3 模型
考虑到指令微调模型在实践中被广泛使用,论文将量化技术应用于以下指令微调的开源 LLM 系列:Vicuna、Gemma和 Llama 系列,总计九个模型。
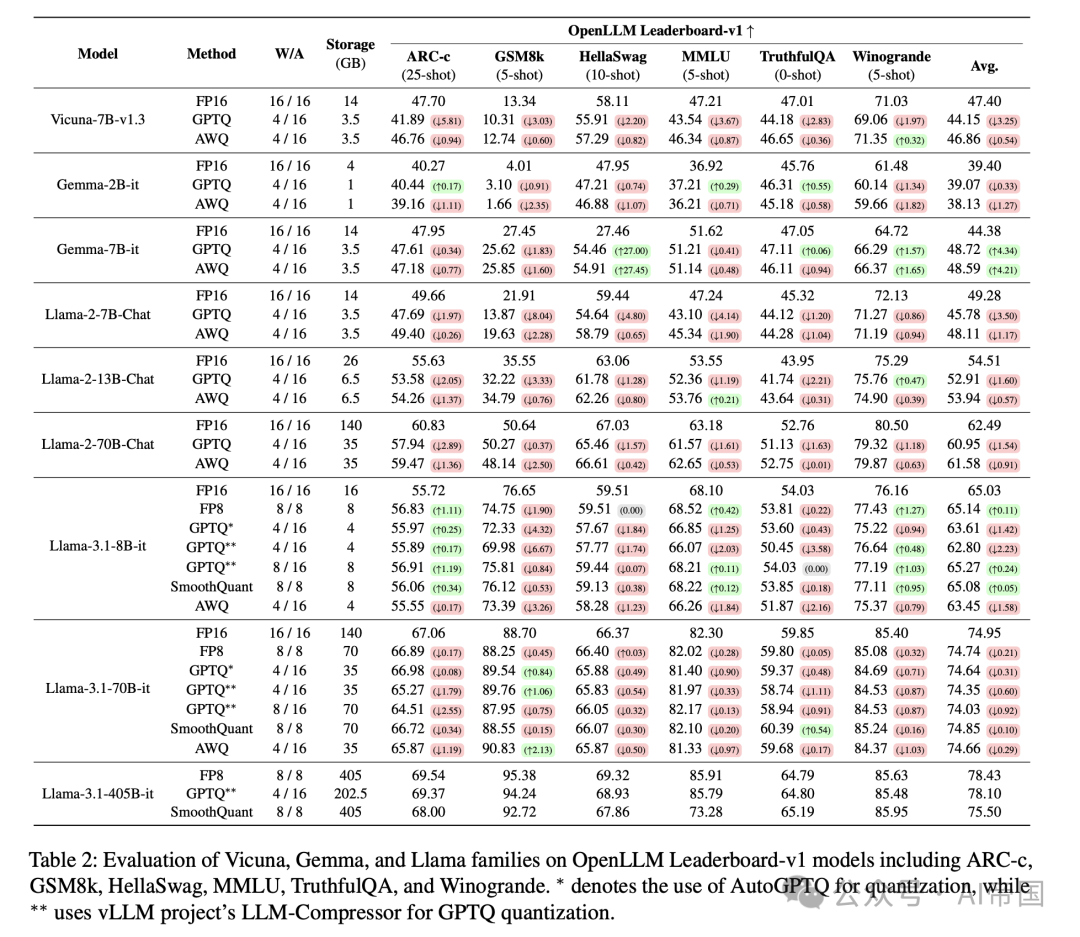
表 2:Vicuna、Gemma 和 Llama 系列在 OpenLLM Leaderboard-v1 模型上的评估,包括 ARC-c、GSM8k、HellaSwag、MMLU、TruthfulQA 和 Winogrande。 表示使用 AutoGPTQ 进行量化,而 * 使用 vLM 项目的 LLM-Compressor 进行 GPTQ 量化。
2.4 实验结果
实验结果如表2、表3和表4所示,分别表示三个不同大小的模型家族在13个数据集上的量化性能变化。总体而言,结果突显了四个关键要点。具体观察如下:
量化后的LLM在大多数基准测试中通常优于小型LLM,除了幻觉和指令跟随任务。在13个基准测试中,使用更大的量化LLM始终比直接使用较小的模型带来更好的性能。特别是,4比特量化的Llama-2-13B(有效减少到6.5 GB)在大多数基准测试中优于FP16的Llama-2-7B(14 GB),尽管其尺寸更小。具体来说,4比特压缩的Llama-2-13B(6.5GB)在Open-LLM Leaderboard-vl数据集上准确率提高了4.66%,在OpenLLM Leaderboard-v2数据集上准确率提高了1.16%,优于FP16的Llama-2-7B(14GB)。然而,在测试幻觉的TruthfulQA基准测试中,FP16的Llama-2-7B显示出比量化后的Llama-2-13B更好的准确性。同样,在指令跟随任务IFEval中,FP16的Llama-2-7B优于4比特量化的Llama-2-13B。
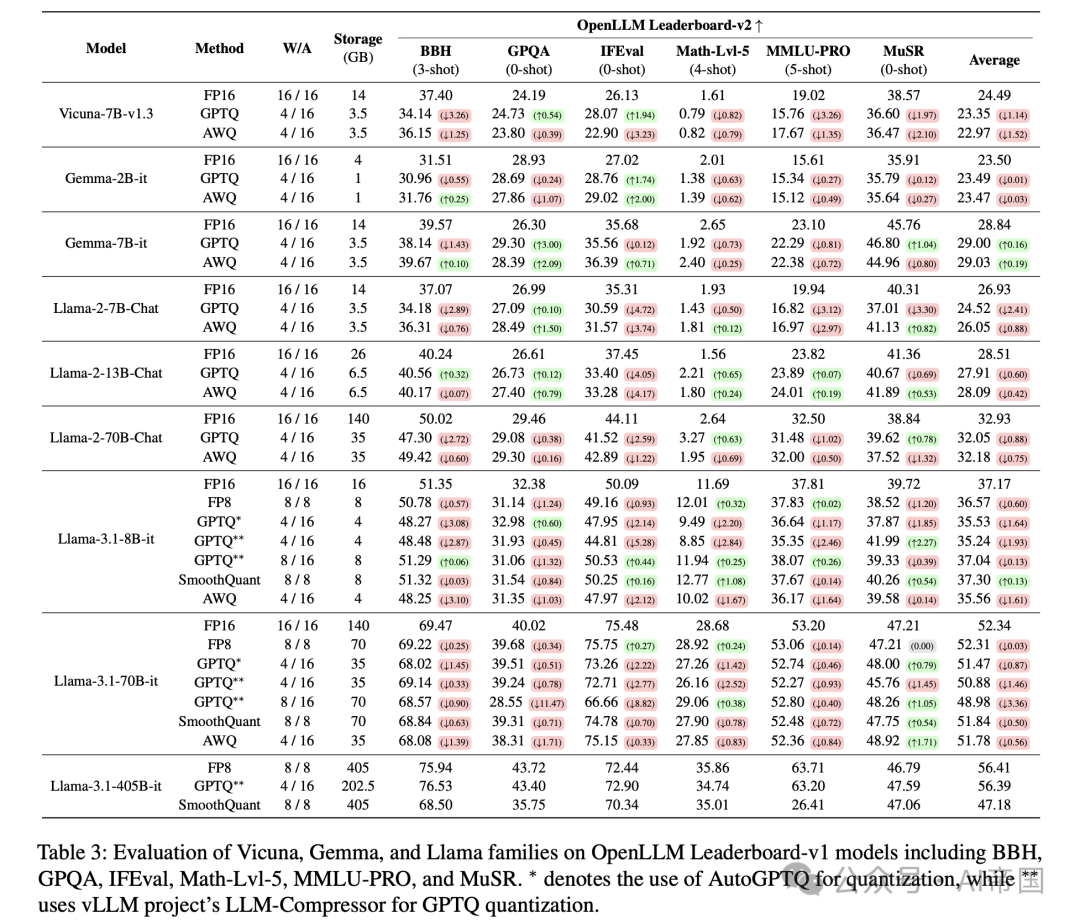
表3:Vicuna、Gemma 和 Llama 家族在 OpenLLM Leaderboard-v1 上的评估,包括 BBH、GPQA、IFEval、Math-Lvl-5、MMLU-PRO 和 MuSR。 表示使用 AutoGPTQ 进行量化,而 使用 vLLM 项目的 LLM-Compressor 进行 GPTQ 量化。
当Llama-3.1-405B被量化到4位时,其大小达到202.5GB,并且在大多数数据集上优于FP16的Llama-3.1-70B(140GB)。具体而言,4位量化的Llama-3.1-405B在OpenLLM Leaderboard-vl数据集上平均准确率提高了3.15%,在OpenLLM Leaderboard-v2数据集上提高了4.07%,相比FP16的Llama-3.1-70B。然而,在IFEval数据集中,尽管4位GPTQ量化的Llama-3.1-405B模型更大,但其表现却不如FP16的Llama-3.1-70B模型。这是因为量化似乎破坏了严格遵循指令的能力,影响了对齐。
量化方法和精度的比较。在大多数情况下,权重仅量化(GPTQ和AWQ)和激活量化(SmoothQuant)之间的差异不大。然而,对于Llama-3.1-405B这样的超大规模模型,执行激活量化的SmoothQuant导致了显著的准确率下降。具体来说,在Llama-3.1-405B中,SmoothQuant量化方法在OpenLLM Leaderboard-v1和OpenLLM Leaderboard-v2数据集上分别导致高达-2.93%和-9.23%的平均准确率下降,相比FP8。这归因于SmoothQuant设计用于补偿OPT-175B规模模型中观察到的高激活范围。因此,Llama-3.1-405B等更大模型中的高激活范围并未得到有效缓解。在权重仅量化方法的比较中,AWQ在各种LLM的总体基准评分上始终优于GPTQ。当比较GPTQ的不同实现,如AutoGPTQ和llmcompressor时,存在显著的性能差异。
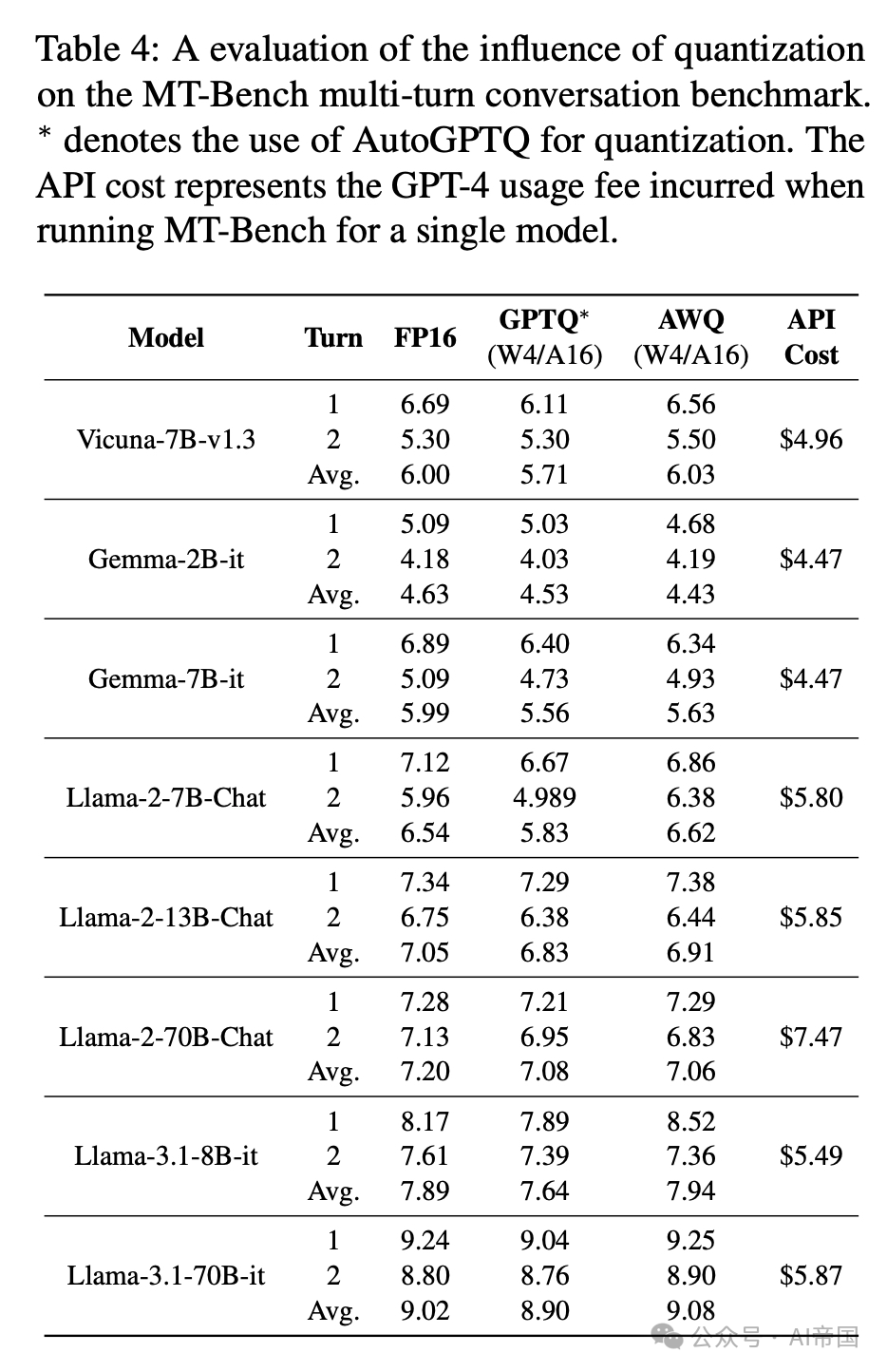
表4:量化对MT-Bench多轮对话基准影响的评估。表示使用AutoGPTQ进行量化。API成本代表运行MT-Bench对单个模型产生的GPT-4使用费。
量化导致的精度下降程度因模型大小而异。在GPTQ论文中,精度性能下降仅通过困惑度(PPL)进行测量,这似乎对4-bit量化是安全的。然而,本研究在13个数据集上评估了GPTQ,并发现了显著的精度下降情况。具体来说,对于较小的模型如llama-3.1-8B,应用8-bit的GPTQ量化在12个基准数据集上实现了比4-bit更高的精度,不包括GPQA和MuSR。然而,对于较大的模型如Llama-3.1-70B,8-bit和4-bit量化之间的精度差异在12个数据集上几乎可以忽略不计。实际上,在Open-LLM Leaderboard-vl和OpenLLM Leaderboard-v2数据集上,GPTQ 4-bit分别实现了比8-bit高0.32%和1.9%的平均精度。最终,合适的量化比特精度取决于数据集和模型大小。
当需要在8位进行权重量化和激活量化时,FP8表现良好,即使在Open-LLM Leaderboard-v2的困难任务和最近的LLMs如Llama-3.1-405B上也是如此。因此,FP8比SmoothQuant更稳定,并且在支持FP8的硬件如NVIDIA H100 GPU和RTX6000Ada上使用FP8是有优势的,因为它在延迟和吞吐量方面都有优势。此外,将FP8应用于权重和激活可以减少一半的KV缓存大小,这在LLM解码阶段中,I/O瓶颈是一个关注点时,非常有利。此FP8 KV缓存功能由vLLM支持。
任务难度与数据集和量化导致的精度下降程度之间的关系并不显著。对于像MuSR这样因难以达到比随机模型更好的精度而著名的困难数据集,即使是Llama-3.1-405B也无法超过50分。关于评估数学能力的Math-Lvl-5数据集——LLMs通常表现不佳的领域——Llama-3.1-405B也没有超过40分。截至2023年,大多数LLMs在这些困难任务中只能达到1-2的精度。尽管如此,对于这些困难数据集,量化后的LLMs并未观察到显著的额外精度下降。相反,对于2024年7月发布的最新模型Llama-3.1-70B,在三年前的数据集GSM8K上达到了88分的高精度。即使在最新的LLMs达到高精度的情况下,量化对精度的影响仍然很小。因此,量化导致的精度下降程度与数据集任务的难度之间没有显著关系。
较大的模型在量化后会经历更显著的准确性损失,特别是在多轮评估的第二轮中,MT-Bench难以区分近期的大型语言模型(LLMs),因为它们的表现接近GPT-4。如表4所示,对于较小的模型如2B、7B和8B,量化后的LLMs在多轮平均得分上有所提升。然而,对于较大的模型如13B和70B,量化后的LLMs性能相比原始模型有所下降。换句话说,量化导致的准确性下降在较大的模型中更为明显。此外,第二轮的准确性下降比第一轮更大。在GPTQ和AWQ方法的比较中,AWQ通常优于GPTQ,这与12个数据集的结果一致。
近期的模型如Llama-3.1在MT-Bench上得分很高,该基准使用GPT-4进行评估,因为它们在性能上接近GPT-4。因此,很难完全信任这些结果作为绝对标准。量化后的LLMs在这个基准测试中也取得了高分。在成本方面,所有模型产生的费用在 $4和$7之间。论文在MT-Bench实验中总共花费了约150美元用于GPT-4 API调用。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









